# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

最近,ChatTTS 这一语音生成项目在 GitHub 上迅速获得关注。截至6月4日,6天时间已经斩获18.9千个星标????。各大网友直呼太牛!按照这样的趋势,很快会突破2万stars。
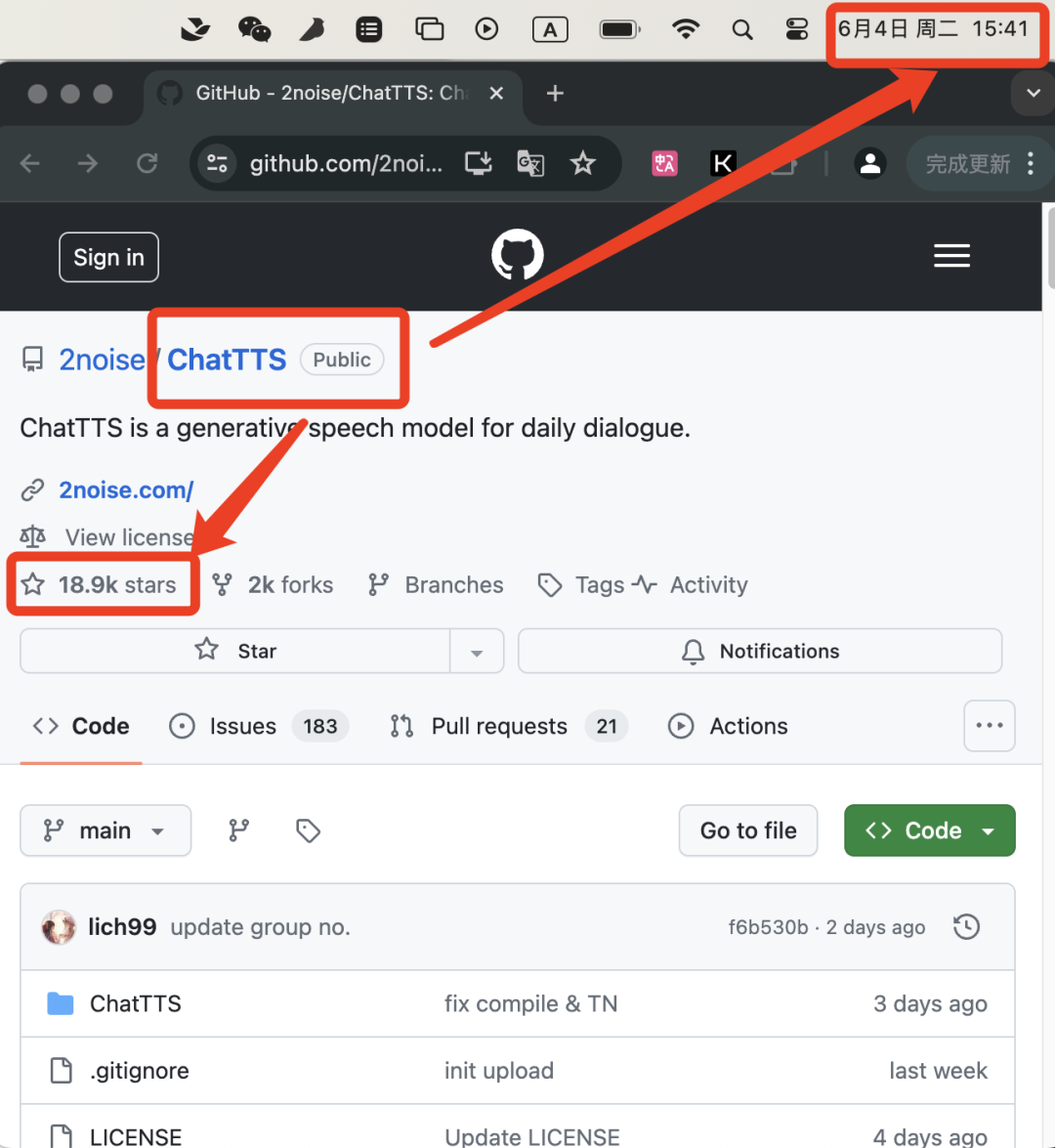
网址:https://github.com/2noise/ChatTTS
ChatTTS 是一个专门为对话场景设计的文本生成语音模型(TTS 即 Text-To-Speech),它支持多种语言,包括英语和中文,最大的模型采用了10万小时的中英文数据进行训练,在 Huggingface 中开源的版本为4万小时训练且未sft的版本。以确保声音合成的高质量和自然度。
据官方介绍,ChatTTS 有3大亮点:
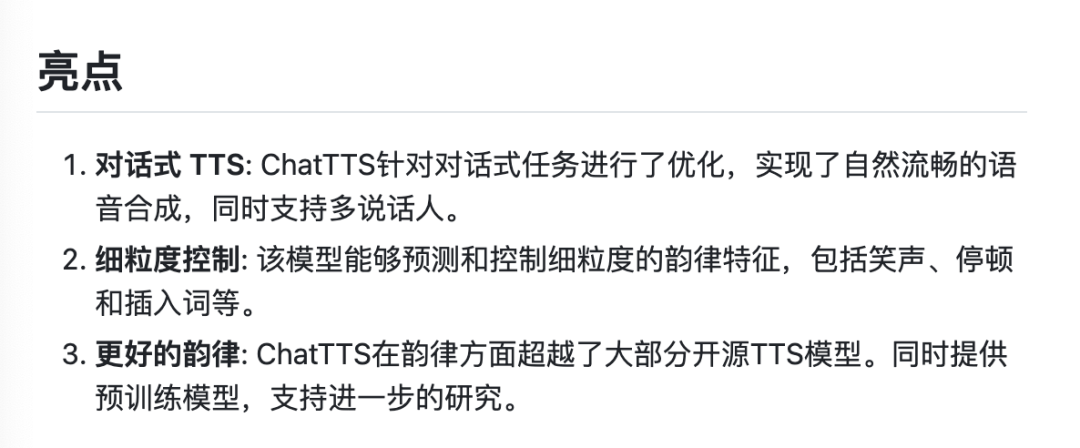
在 Github 里听完官方语音版的自我介绍,人物声音十分逼真、自然、流程,同时有停顿、笑声。
代码如下:
inputs_cn = """chat T T S 是一款强大的对话式文本转语音模型。它有中英混读和多说话人的能力。chat T T S 不仅能够生成自然流畅的语音,还能控制[laugh]笑声啊[laugh],停顿啊[uv_break]语气词啊等副语言现象[uv_break]。这个韵律超越了许多开源模型[uv_break]。请注意,chat T T S 的使用应遵守法律和伦理准则,避免滥用的安全风险。[uv_break]'""".replace('\n', '')params_refine_text = {'prompt': '[oral_2][laugh_0][break_4]'} audio_array_cn = chat.infer(inputs_cn, params_refine_text=params_refine_text)# audio_array_en = chat.infer(inputs_en, params_refine_text=params_refine_text)torchaudio.save("output3.wav", torch.from_numpy(audio_array_cn[0]), 24000)
除了上面的官方自我介绍,大家最熟悉的肯定是这几天最常见到的那段——四川美食朗读,不得不说生成的效果真的很自然、很流畅啊!
写在前面:
本文主要分为三部分,对某个板块感兴趣的小伙伴可直接跳转阅读。
ChatTTS PK 人之“七情六欲”
每个人都有七情六欲,都说 ChatTTS 生成的声音十分逼真自然,那挑战一下我们的“七情六欲”,看它有多大能耐!我们利用 ChatTTS 的文本控制标记来丰富语音的情感表现,具体如下,大家请欣赏:
利欲(Desire for Gain):
每次投资看到数字翻倍,那种兴奋的感觉就像是找到了新大陆[break_1],让人欲罢不能。
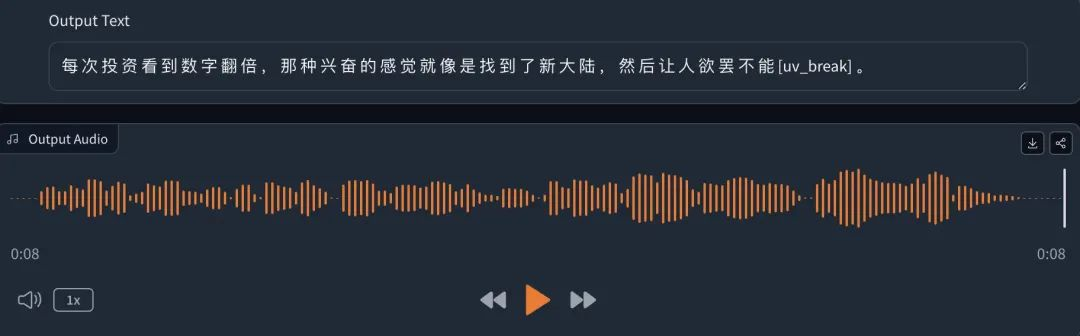
整句话自然流畅,“兴奋”二字的情绪相对比较突出。
食欲(Desire for Food):
当我看到那份丰盛的晚餐被摆上桌子,我的口水忍不住就流了下来[break_1][oral_3],每一道菜都让我垂涎欲滴。
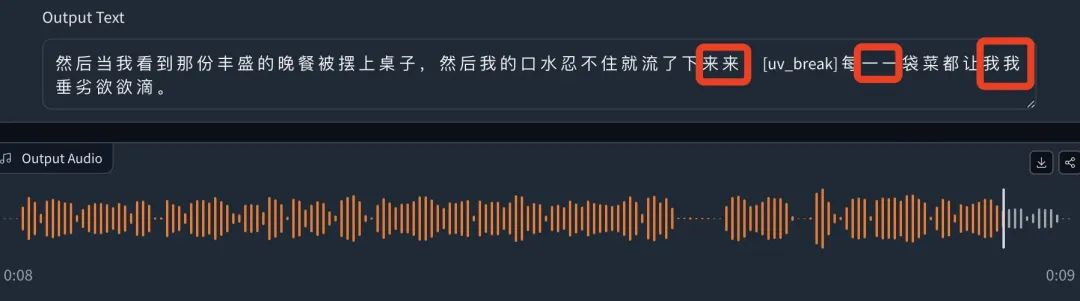
文字输出部分有部分词语重叠,结尾部分在语音中听起来含糊不清,但整体的情绪很饱满,相对来说也比较流畅。
睡欲(Desire for Sleep):
经过一整天的忙碌,我只想一头栽进软软的床上[lbreak],沉浸在甜美的梦乡中[oral_4]。
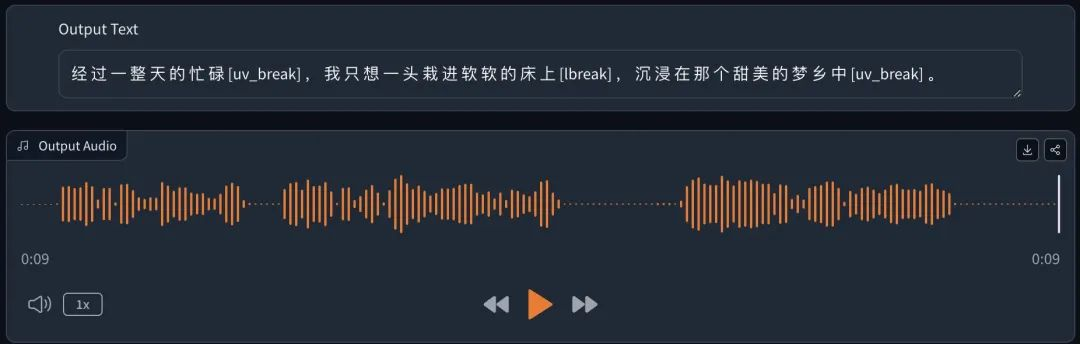
整体流畅自然,情绪也到位。
财欲(Desire for Wealth):
每次想到能中大奖的那一刻,我的心就充满了激动[laugh_2]和无限的幻想[break_2]。
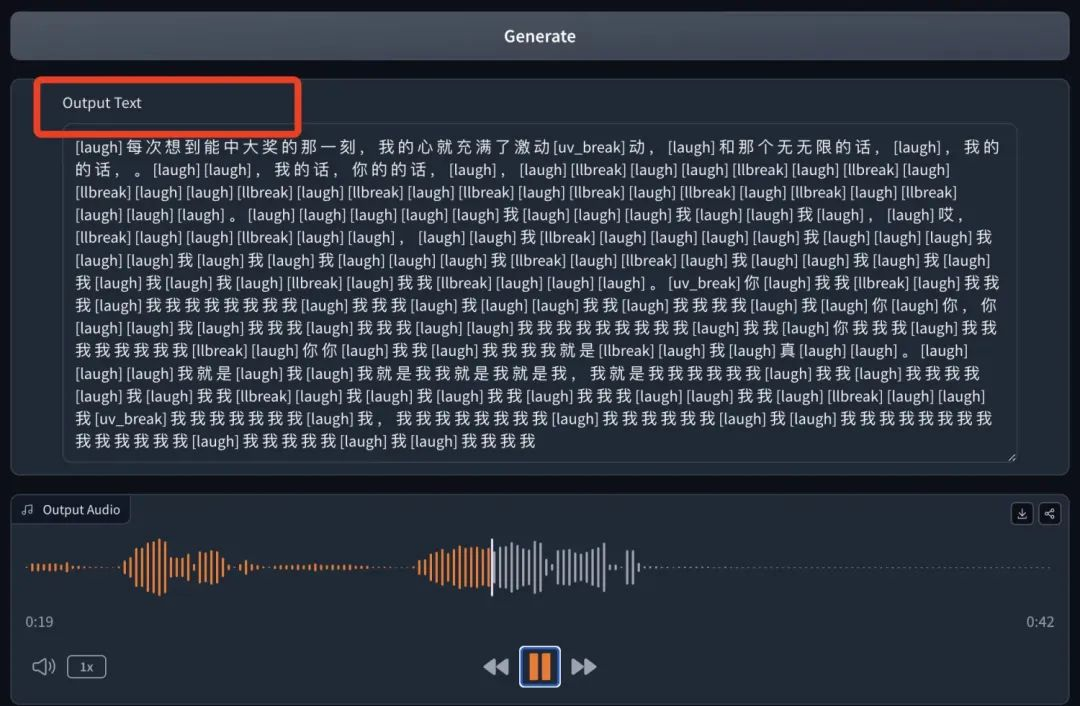
这是开始乱码了。
名欲(Desire for Fame):
站在闪光灯下的那一刻,我感觉自己就像是世界的中心[laugh_1],所有的目光都集中在我身上。
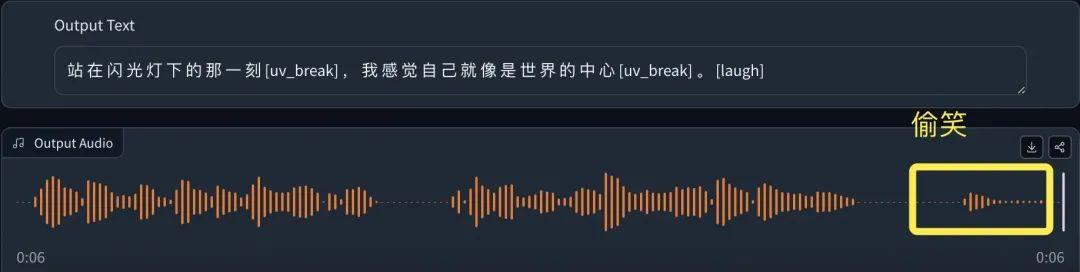
整句话特别流畅,听完就有种站在“闪光灯下”的感觉,最有意思的是结尾部分还有“偷笑”,而且还很有偷感。
色欲(Desire for Sex):
在那迷人的灯光下,我被对方那深邃的眼神深深吸引[break_3],无法自拔。
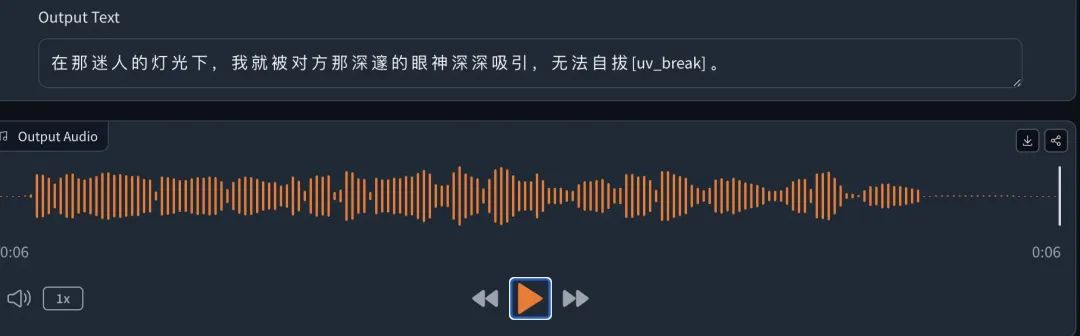
毫无情感的朗读大师,但是极其自然流畅。
还有七情
为了更好地表达“七情六欲”这一复杂的情感体系,我们同样可以通过在文本中嵌入控制标记来精细控制语音的情感表达,具体如下:
喜(Joy):
-原文:终于得到了期待已久的晋升[laugh_1],感觉像是站在世界之巅[break_2],一切努力都得到了回报。
-文字输出:开始乱码重复,很多时候需要多次生成才行。
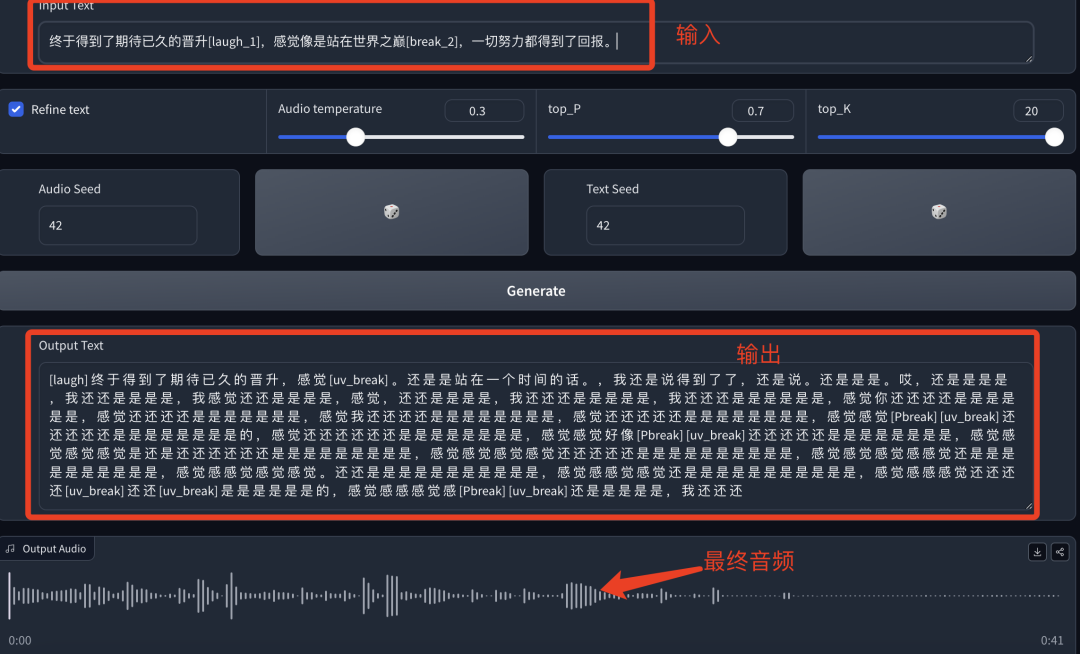
-音频输出:音频里基本没有生成完整的词语、句子能说出来,基本都是乱叫。
我们会发现,这两次的效果都在文字输出这部分就已经出问题了。
怒(Anger):
-原文:看到那不公正的报道,我简直气炸了[lbreak],怎么可以这样歪曲事实[oral_5]?
-文字输出:文字全部正确输出。
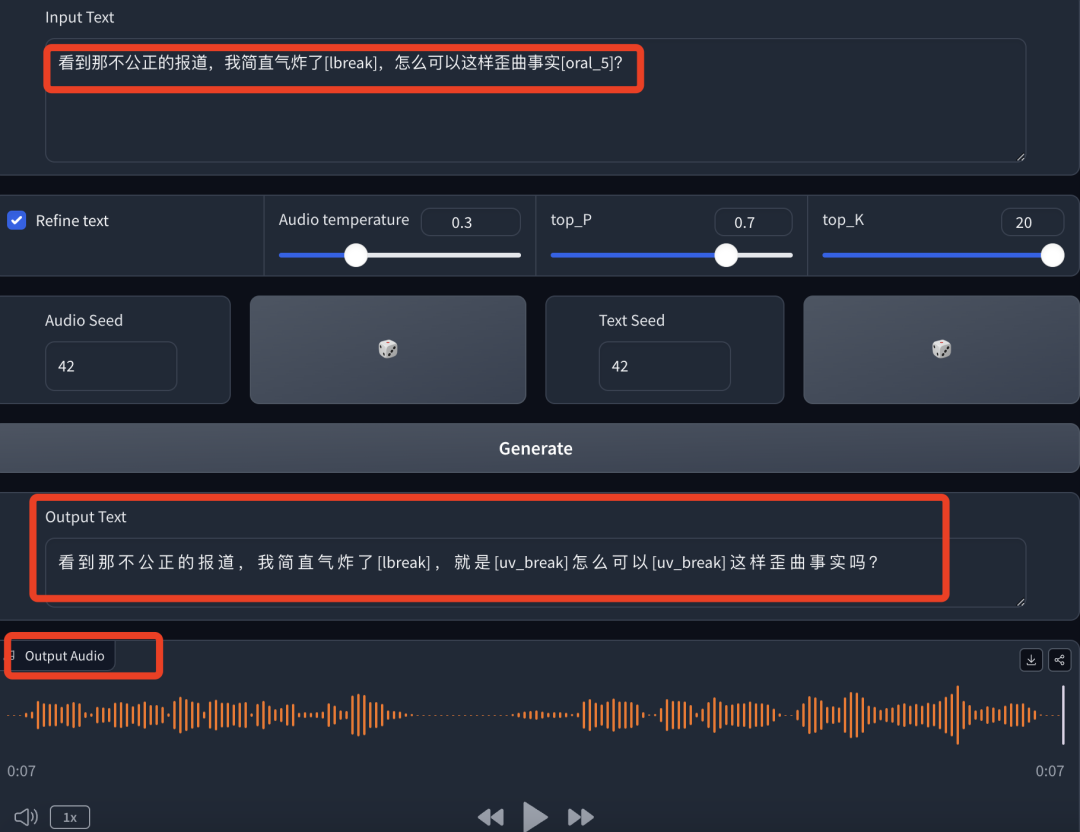
-音频输出:前半句非常平静,中间有停顿,但后半句完全听不出“怒”感,甚至略带“笑意”,不太合理。
这部分句子能完整读出来,甚至开始有了停顿,但在情绪变化傻姑娘略显青涩,基本快听不出情绪的变化。(盲猜:只有笑和停顿是最明显的。
哀(Sorrow):
-原文:告别仪式上,我试图抑制我的悲伤[break_4][oral_2],但泪水还是夺眶而出。
-文字输出:试了两次,都缺少“但泪水还是夺眶而出”的文字。
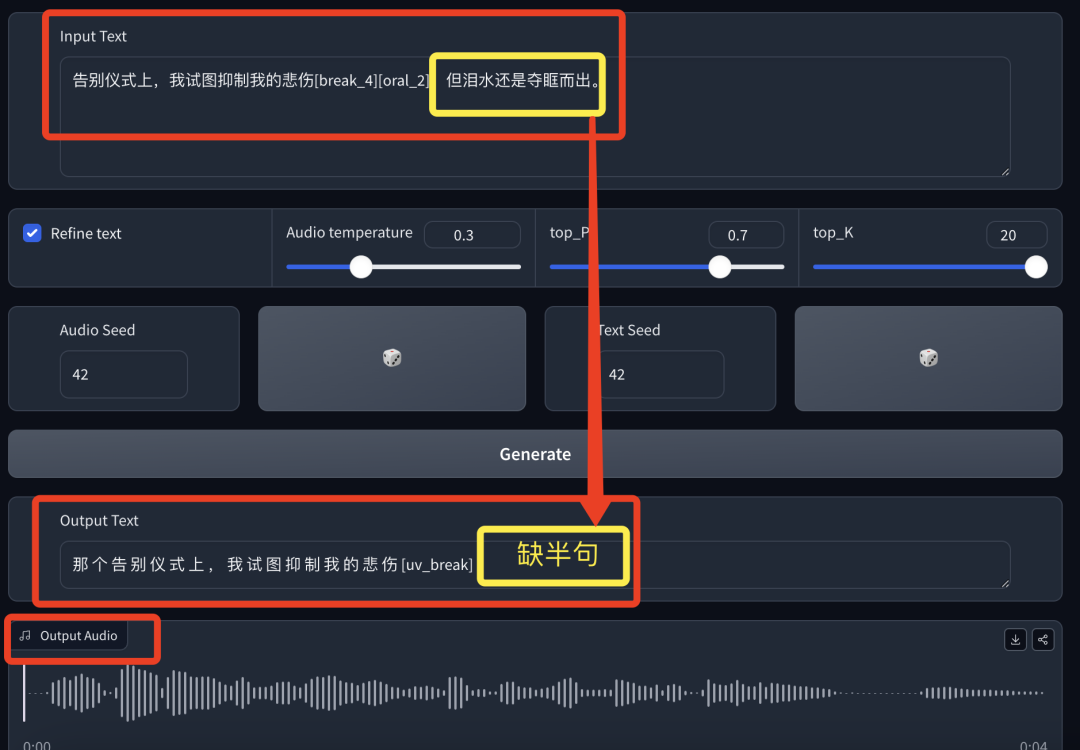
-音频输出:情感非常平静,但是有“嗯”的语气词。
第三句话在 output 文字输出部分就已经开始遗漏原始信息了,到语音部分后续半句“但泪水还是夺眶而出”直接丢失,无法生成语音。情绪上则非常地平静,不过能听出来有点儿方言的感觉。
乐(Happiness):
-原文:在朋友的婚礼上,我们一起欢笑[laugh_2],那一刻的幸福感[break_1]无与伦比。
-文字输出:文字输出一半以后开始乱码,后面基本呈结巴的状态。
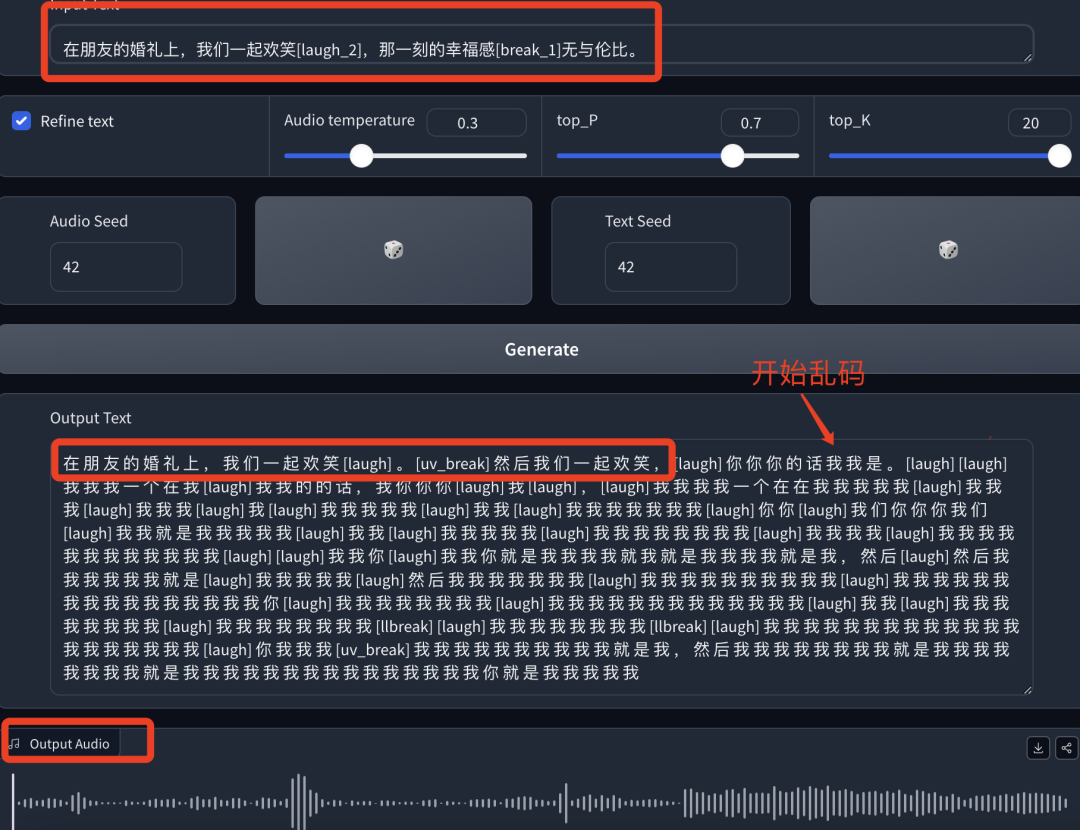
-音频输出:乐倒是挺乐的,全程基本都是结巴的状态,“我我我......”等等。
这一次跟第一次效果很像,基本没有完整的词语出现,虽然没有完整的剧字输出,但情感这点很饱满,尴尬之间藏着大笑。至于有多乐,还是耳听为实。
思(Thoughtfulness):
-原文:看着夕阳逐渐西下[break_3],我陷入了深深的思索[oral_1],思考人生的真谛。
-文字输出:文字输出前半句多了“西下”,内容上有重复。
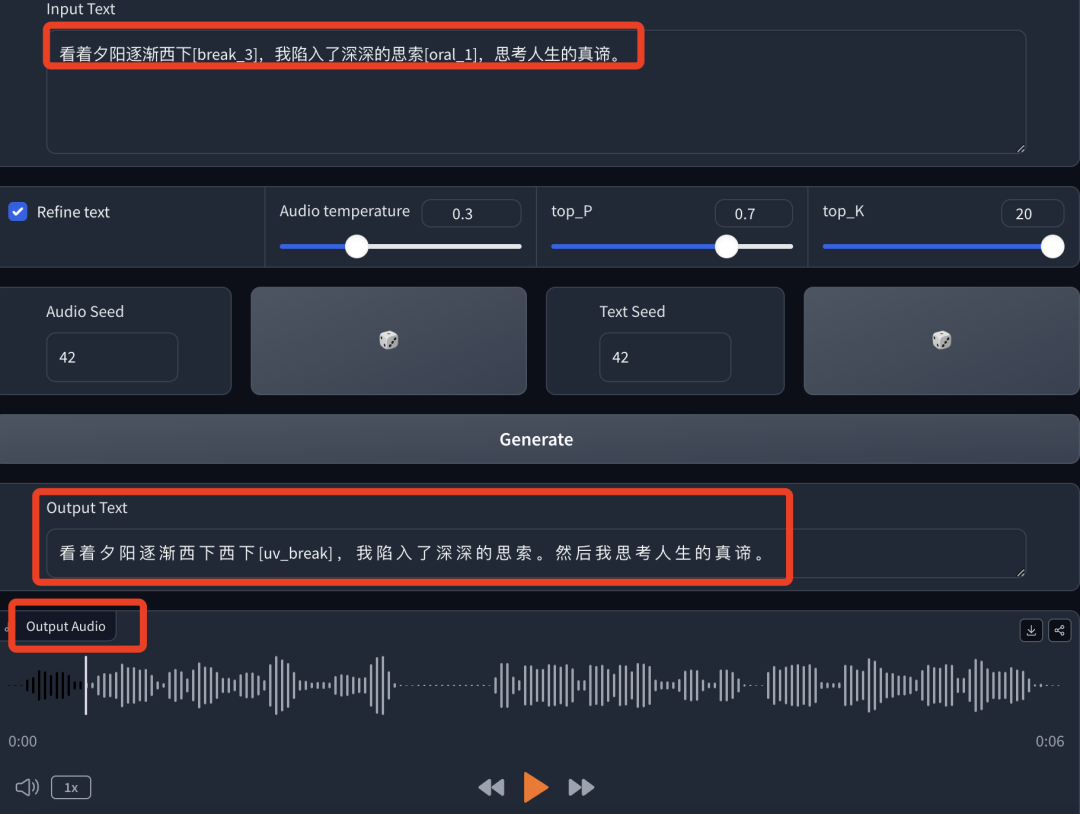
-音频输出:音频中同样也带有双“西下”,听起来怪怪的,情感上倒是特别有思考的感觉。
在文字输出部分除了时不时丢失句子以外,还会存在词语“重叠”的现象,这直接影响最后生成的语音结果,有点像抽卡,需要多次才能满意。
惊(Surprise):
-原文:当我无意间发现那份遗失的信件[lbreak],惊讶之情溢于言表[break_2]。
-文字输出:文字内容完整输出。
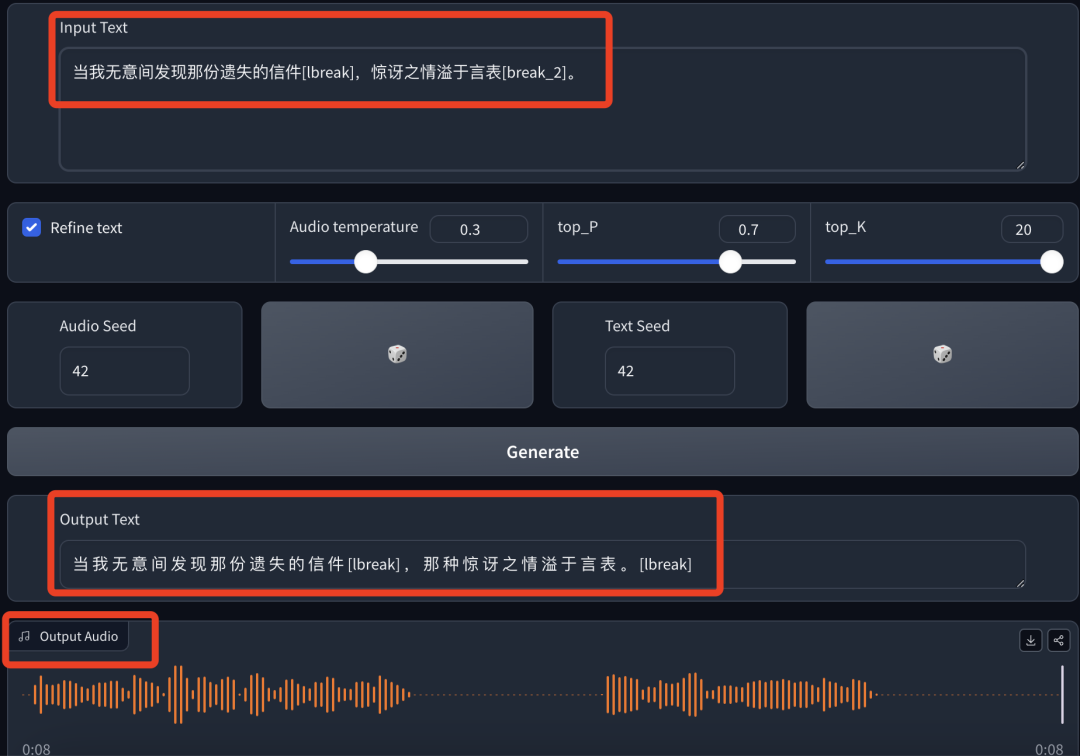
-音频输出:音频完整输出,停顿的恰到好处,读到“无意间”这几个字是有情感在的,但后半句惊讶的情绪没有体现出来。
这一次完整输出了文字和音频,情绪上有所涉及到,但波动不明显,听不出惊讶的情绪,像是平静地朗读。
恐(Fear):
-原文:夜晚的奇怪声响让我心惊肉跳[break_3][oral_8],每一个声音都让我不寒而栗。
-文字输出:文字输出效果多了一个单词 way,其他都很完整。
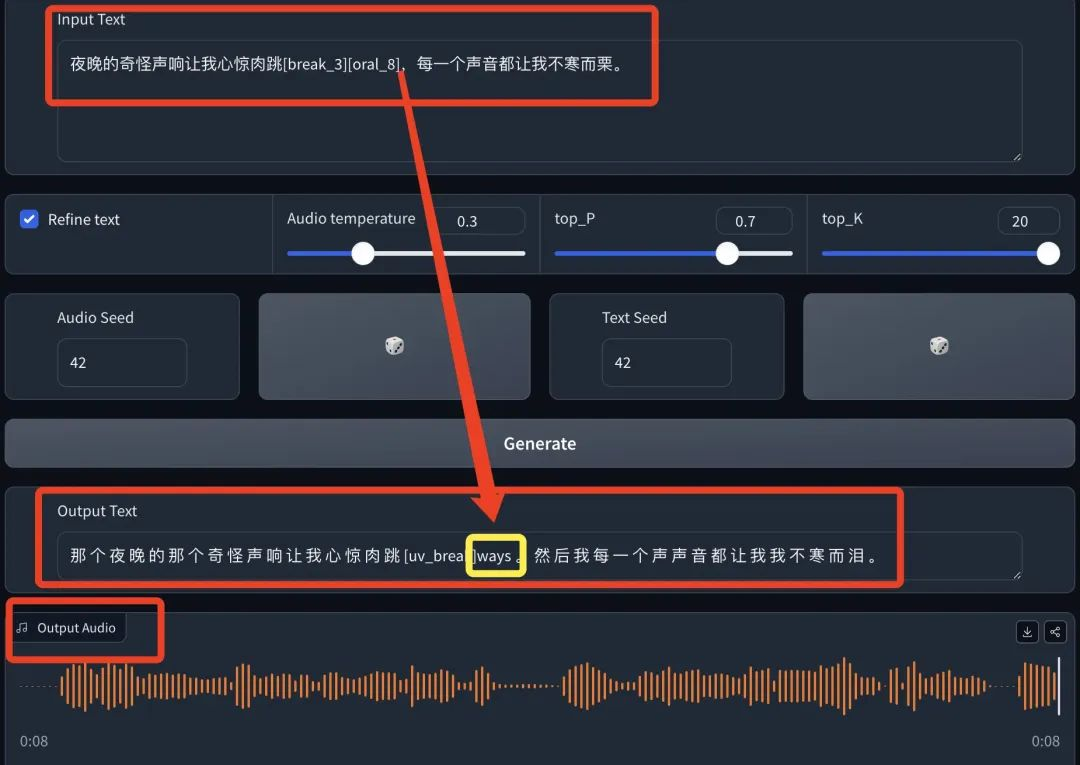
音频输出:朗读的特别自然,整个情绪也相对饱满,尤其是读到“不寒而栗”的时候,还喘口气。
这次是很完整地把 ChatTTS 的特点展现出来了,不仅流畅自然、而且情绪很到位,甚至结尾还出现了第二个人声的“嗯”,可见还有很多宝藏功能有待挖掘。
我们会发现 ChatTTS 的输出不太稳定,时而完整、时而缺胳膊少腿儿,还是那句话(重要的事情说三遍‼️):
多抽卡,多尝试!
多抽卡,多尝试!
多抽卡,多尝试!
总的来说,通过停顿、笑声和口腔特征的控制标记,ChatTTS 能够更准确地传达复杂的情感状态,提升语音内容的表现力和互动性。但相对而言,还是有一段距离要走的。
总结
其实,测评到这,ChatTTS 在 GitHub 上相当火是有原因的,比如:
但同样也存在一些问题:
我能想到的一些使用场景(当然不止这些):
如何使用 ChatTTS
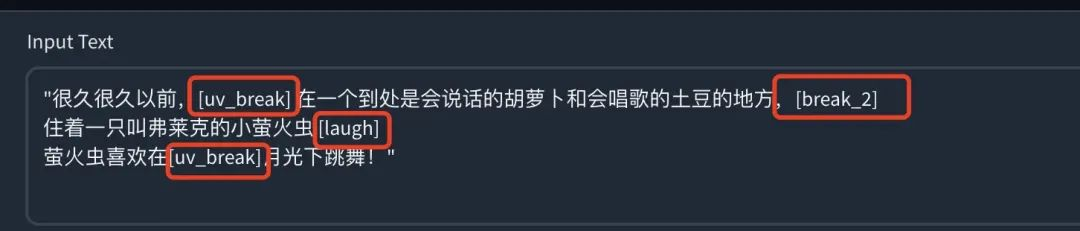
举个例子,你正在为一个儿童故事应用程序创建一个奇思妙想的 AI 角色,你可以使用 ChatTTS 创建类似这样的文本(英文绘本):
"Once upon a time, [uv_break] in a land filled with talking carrots andsinging potatoes, [break_2] lived a little firefly named Flicker. [laugh]Flicker loved to [uv_break] dance among the moonbeams!"
br
实际生成效果:英文简直就是一气呵成,而且非常好听。
举个例子,你正在为一个儿童故事应用程序创建一个奇思妙想的 AI 角色,你可以使用 ChatTTS 创建类似这样的文本(英文绘本):
"Once upon a time, [uv_break] in a land filled with talking carrots andsinging potatoes, [break_2] lived a little firefly named Flicker. [laugh]Flicker loved to [uv_break] dance among the moonbeams!"
br
通过精细化这些标记,你可以让 ChatTTS 生成一个声音,为戏剧效果停顿、温暖地笑,并把那个奇幻世界带到生活中来。
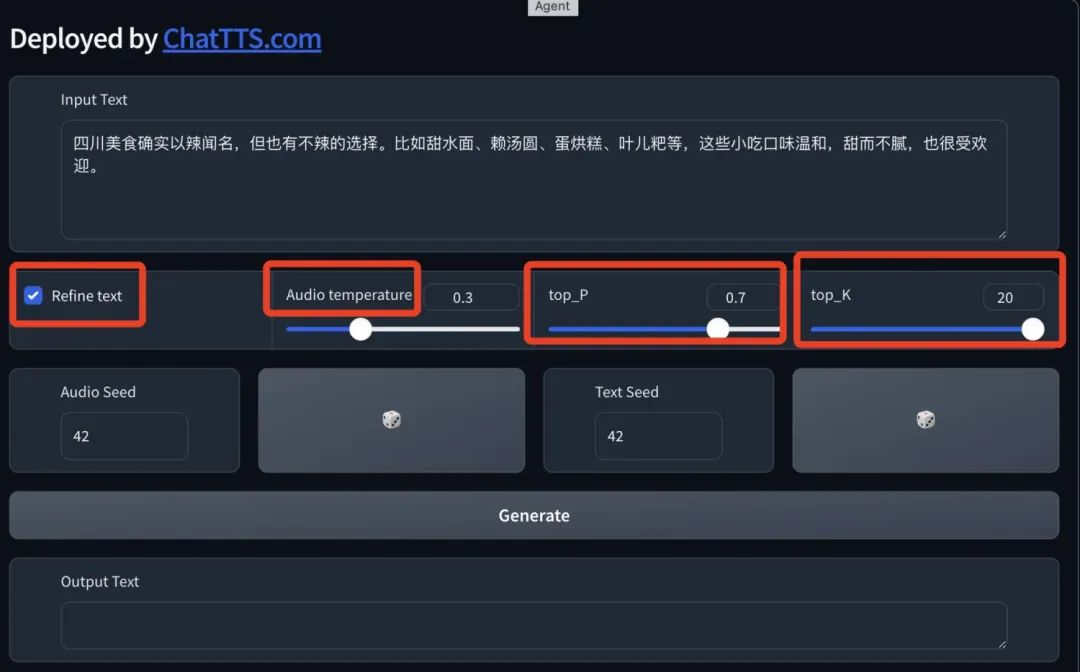
params_refine_text:这个字典主要用于句子级控制,类似于文本内部如何使用标记。
这两个层次的控制结合在一起,使合成语音具有前所未有的表现力和定制性。
注意⚠️:目前网上有很多的体验地址,但这个 https://chattts.com/ 并不是官方网站,但不需部署可直接上手体验。
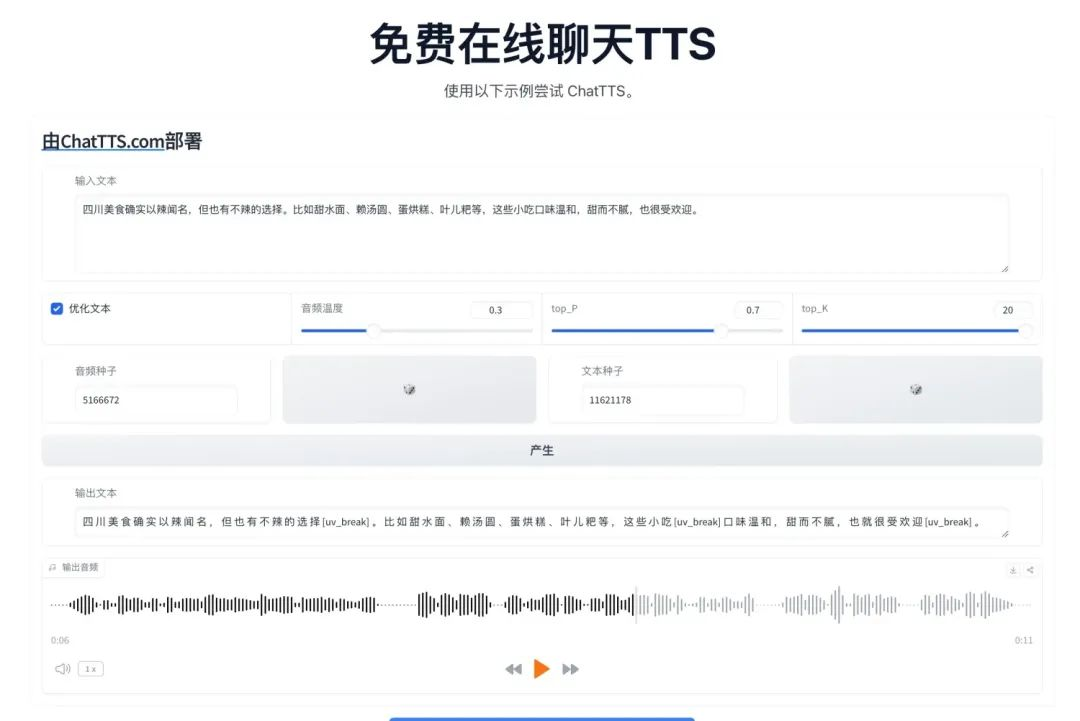

官方入口在这里:
https://github.com/2noise/ChatTTS
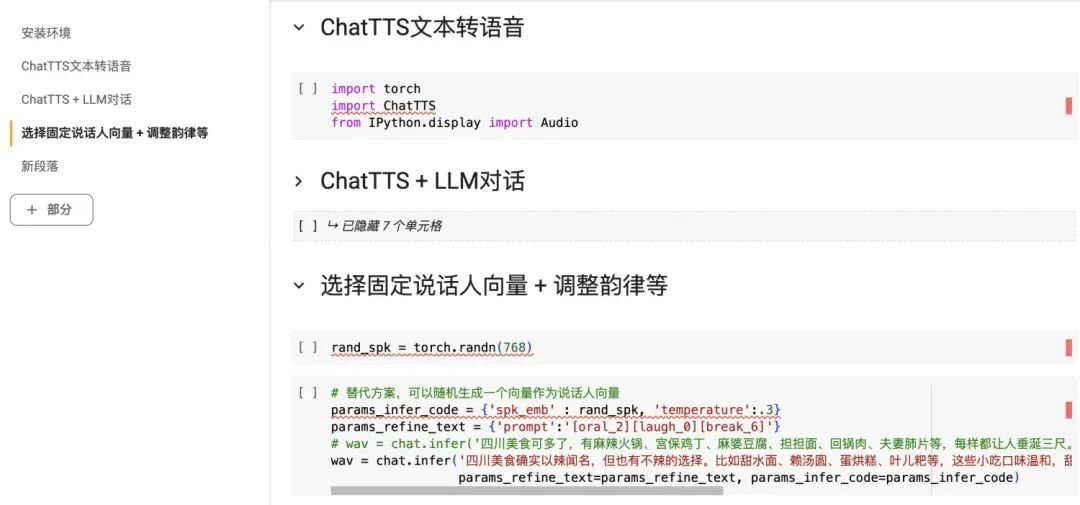
有代码基础的同学可以自己动手试试,或者使用网友已经在 colab 部署好的地址:
https://colab.research.google.com/github/Kedreamix/ChatTTS/blob/main/ChatTTS_infer.ipynb
其它开源 TTS 模型也值得关注
最后
接触过 TTS 的人知道,文本生语音效果特别生硬、断词断句明显、完全没有情感、一股机器人味儿,这还只是其中的一些问题所在。
但 ChatTTS 带给我很大的惊喜,单从生成质量来看,它的生成的质量非常像人说话的感觉,会笑、会哭、会停顿,还会大喘气。诚然它还有很多的不足,像生成时间过长、缺句子、有时候甚至无法完整生成一句话等等,但这并不会妨碍它继续往前走。
ChatTTS 项目不仅在技术上有了新的突破,还开拓了语音生成技术的应用新可能,提供的详细示例代码及文档,为开发者和技术爱好者提供了广泛的探索和实验空间。
期待未来项目能进一步提升音质并增加说话人音色的选择,为实时语音生成领域带来更多创新。
文章来源于“硅星GenAI”,作者“椒盐玉兔”




【开源免费】suno-api是一个使用监听技术实现了调用suno功能,并封装好API的AI音乐项目。
项目地址:https://github.com/gcui-art/suno-api
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
