# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
阿里云发布最强开源大模型Qwen2,干翻Llama 3,比闭源模型还强。
开源界最强大语言模型,Qwen2,来了!
智东西6月7日报道,今日,阿里云正式开源通义千问Qwen2系列模型,其中,Qwen2-72B成为全球性能最强的开源模型。
Qwen2有多强?一句话总结:在全球权威测评中,性能超过美国最强开源模型Llama3-70B,也超过文心4.0、豆包pro、混元pro等众多中国闭源大模型。
Qwen2缘何能打破开源大模型的性能天花板?今日,阿里云不仅将Qwen2系列模型开放免费下载,还首次披露了背后的炼模“秘籍”,相关重要技术细节即将公开。
Qwen2下载地址:https://modelscope.cn/organization/qwen
▲所有人均可在魔搭社区和Hugging Face免费下载Qwen2系列模型
本次,新开源的Qwen2系列包括五个尺寸的预训练和指令微调模型,分别是:Qwen2-0.5B、Qwen2-1.5B、Qwen2-7B、Qwen2-57B-A14B以及Qwen2-72B。
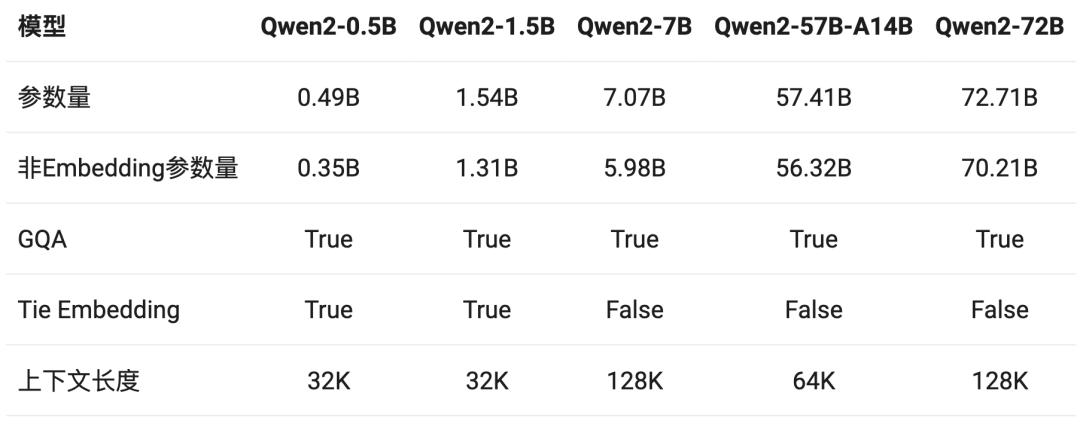
▲Qwen2系列包括五个尺寸的模型版本
相比今年2月推出的通义千问Qwen1.5,Qwen2实现了整体性能的代际飞跃。
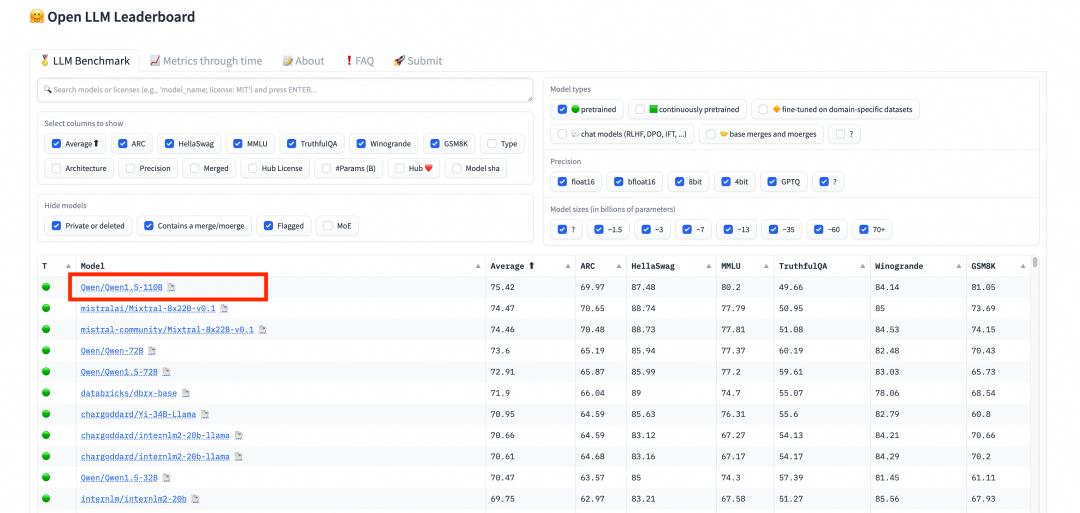
在权威模型测评榜单OpenCompass中,此前开源的Qwen1.5-110B已领先于文心4.0等一众中国闭源模型。这也意味着,刚刚开源的Qwen2-72B继续扩大与这些闭源模型的领先优势。
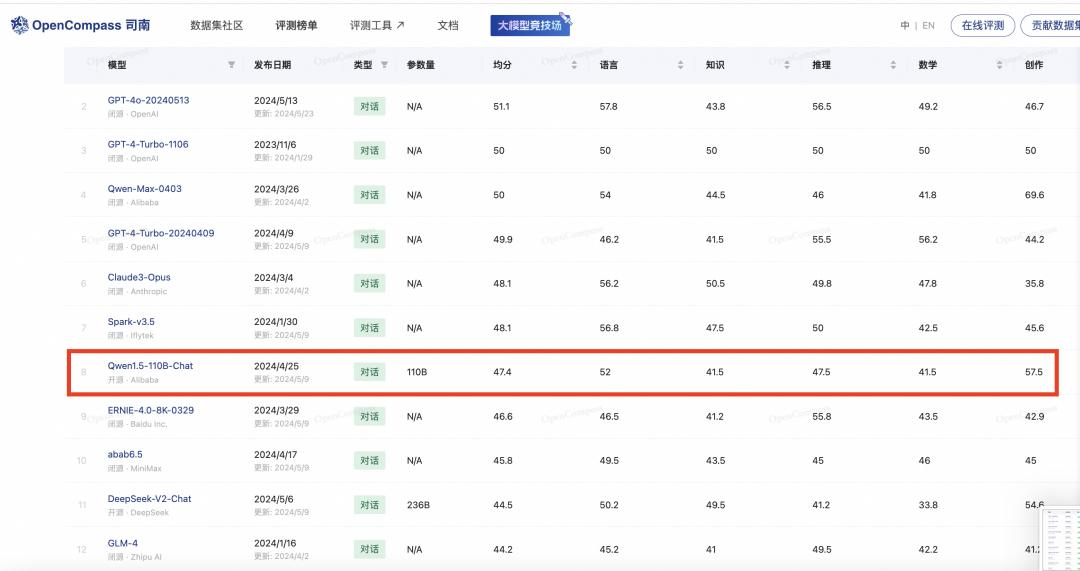
▲Qwen1.5-110B已领先于多款闭源模型
对比Llama3-70B、Mixtrl-8x22B等当前最优开源模型,Qwen2-72B的能力也实现全面超越。
而在MMLU、GPQA、HumanEval、GSM8K、BBH、MT-Bench、Arena Hard、LiveCodeBench等十几项国际权威测评中,Qwen2-72B一举斩获世界冠军,在自然语言理解、知识、代码、数学及多语言等多项能力上表现突出,毫无悬念登上全球最强开源大模型的宝座。
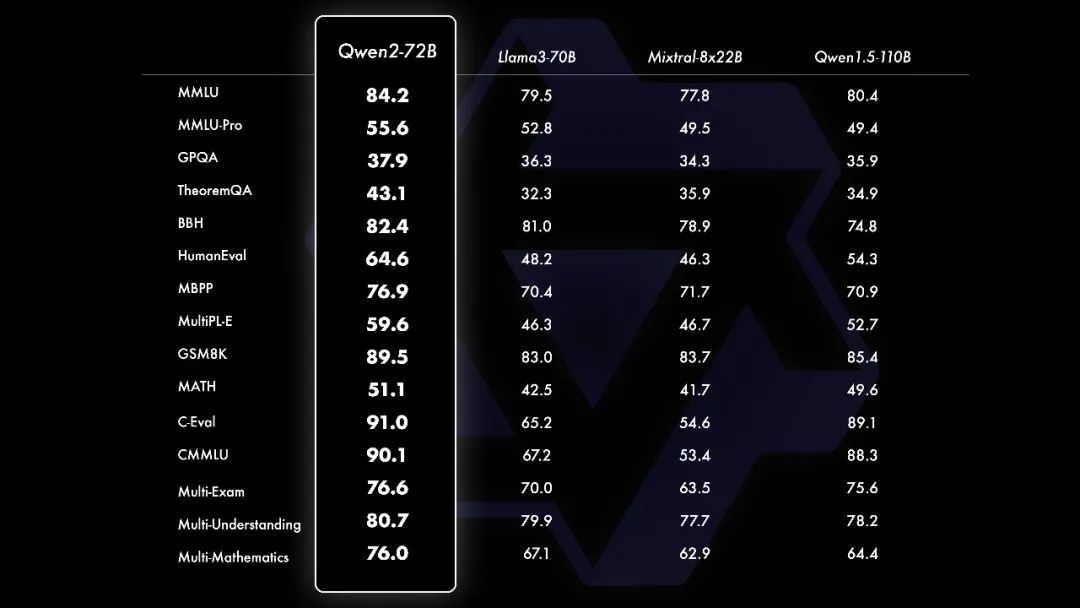
▲Qwen2-72B在十几个全球权威测试中超过当前最优开源模型
而在小模型方面,Qwen2系列模型基本能够超越同等规模的最优开源模型甚至更大规模的模型。相比近期推出的最好的模型,Qwen2-7B-Instruct依然能在多个评测上取得显著的优势,尤其是代码及中文理解上。
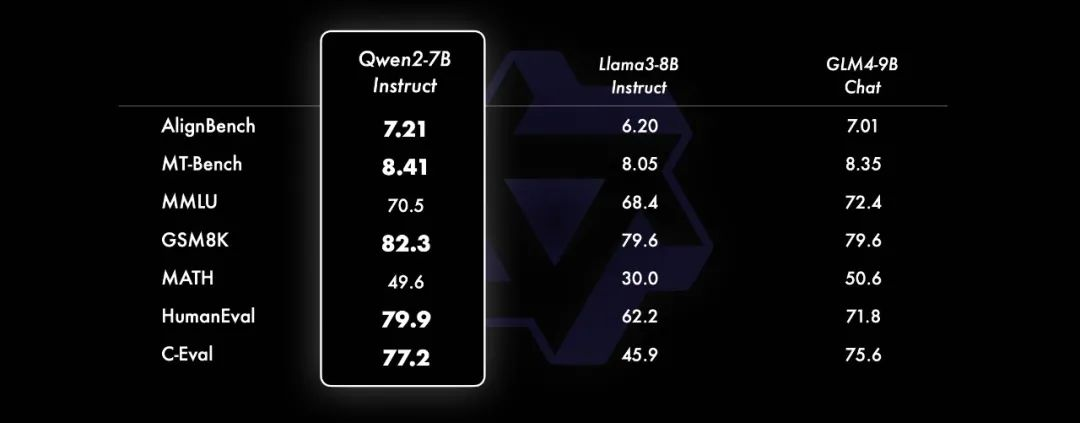
▲Qwen2-7B-Instruct在多个评测上取得显著的优势
目前,Qwen2系列已上线魔搭社区ModelScope和阿里云百炼平台,开发者可在魔搭社区体验、下载模型,或通过阿里云百炼平台调用模型API。
Qwen2的发布,距离阿里云今年2月推出Qwen1.5仅过去了三个多月。
相比上一代Qwen1.5,Qwen2逻辑推理、多语言能力、长文本处理、代码、数学等能力全面提升。
1、代码、数学能力大提升,碾压Llama 3
在代码方面,Qwen2的研发中融入了CodeQwen1.5的成功经验,实现了在多种编程语言上的显著效果提升;在数学方面,基于大规模且高质量的数据,Qwen2-72B-Instruct在多个测评中以碾压之势超过Llama 3-7B-Instruct。
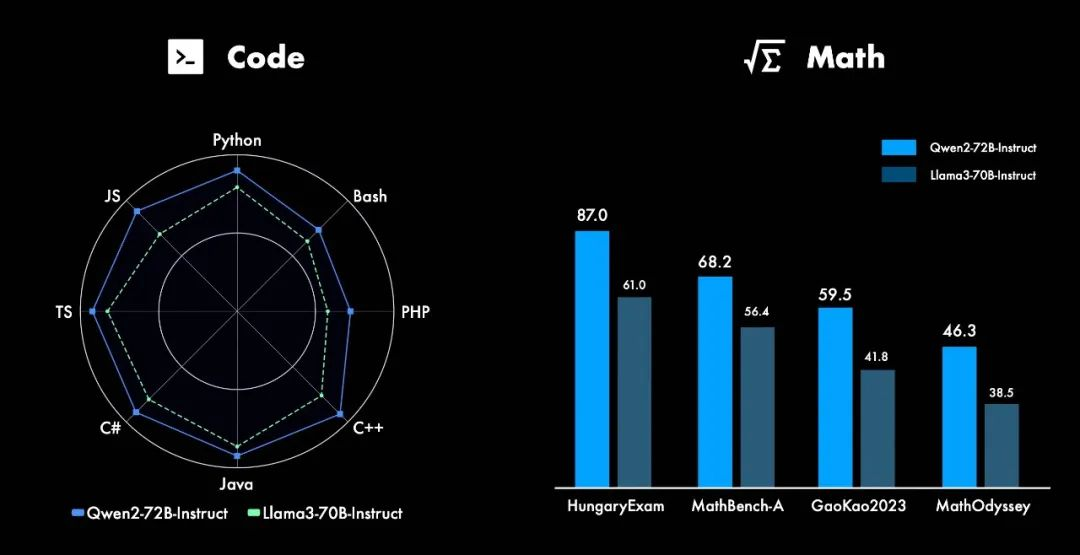
▲Qwen2在代码、数学能力大大提升
2、支持128k长文本,开源智能体方案
如下图所示,在Needle in a Haystack测试集上,Qwen2-72B-Instruct能够完美处理128k上下文长度内的信息抽取任务。
同时,Qwen2系列中的其他模型的表现也十分突出:Qwen2-7B-Instruct几乎完美地处理长达128k的上下文;Qwen2-57B-A14B-Instruct则能处理64k的上下文长度;而该系列中的两个较小模型则支持32k的上下文长度。

▲Qwen2系列在长文本方面表现突出
除了长上下文模型,阿里云本次还开源了一个智能体解决方案,用于高效处理100万tokens级别的上下文。
3、强化安全性,与GPT-4表现相当
下表展示了大型模型在四种多语言不安全查询类别,包括非法活动、欺诈、色情、隐私暴力中生成有害响应的比例。
通过显著性检验(P值),Qwen2-72B-Instruct模型在安全性方面与GPT-4的表现相当,并且显著优于Mixtral-8x22B模型。Llama 3在处理多语言提示方面表现不佳,因此没有将其纳入比较。
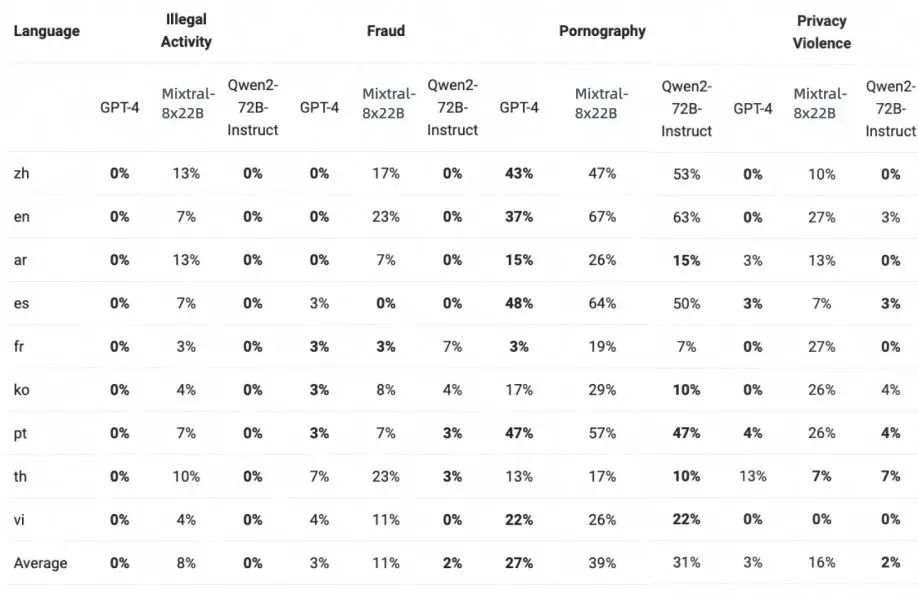
▲Qwen2-72B-Instruct在安全性方面与GPT-4表现相当
模型迭代的速度和实力,让阿里云稳坐开源大模型铁王座。
2023年8月,阿里云成为国内首个宣布开源自研模型的科技企业,推出通义千问第一代开源模型Qwen;2024年2月,1.5代开源模型Qwen1.5发布;不到4个月后,Qwen2开源,从而实现了全尺寸、全模态开源。
不到一年时间,Qwen系列的72B、110B模型多次登顶HuggingFace 的Open LLM Leaderboard等开源模型榜单。
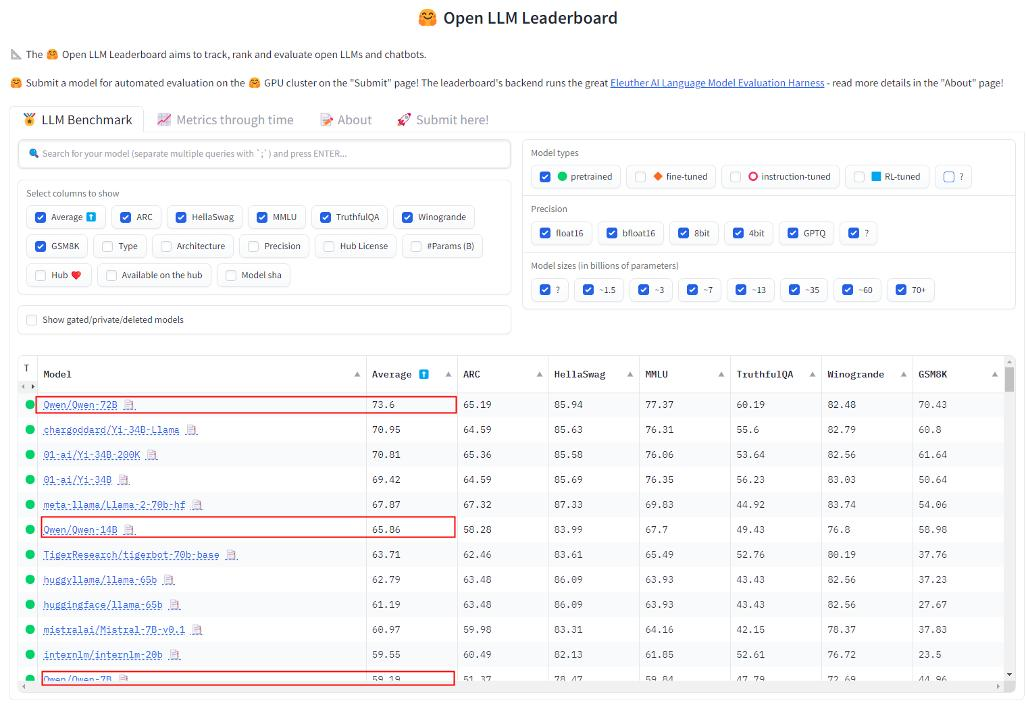
▲Qwen-72B登顶HuggingFace开源大模型排行榜
▲Qwen1.5-110B登顶HuggingFace开源大模型排行榜
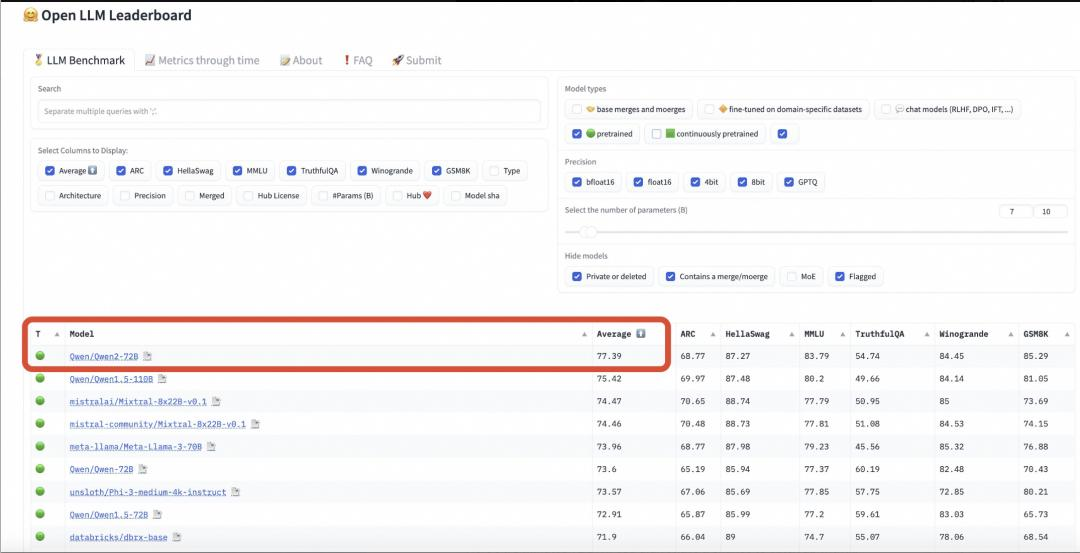
▲Qwen2-72B登顶HuggingFace开源大模型排行榜
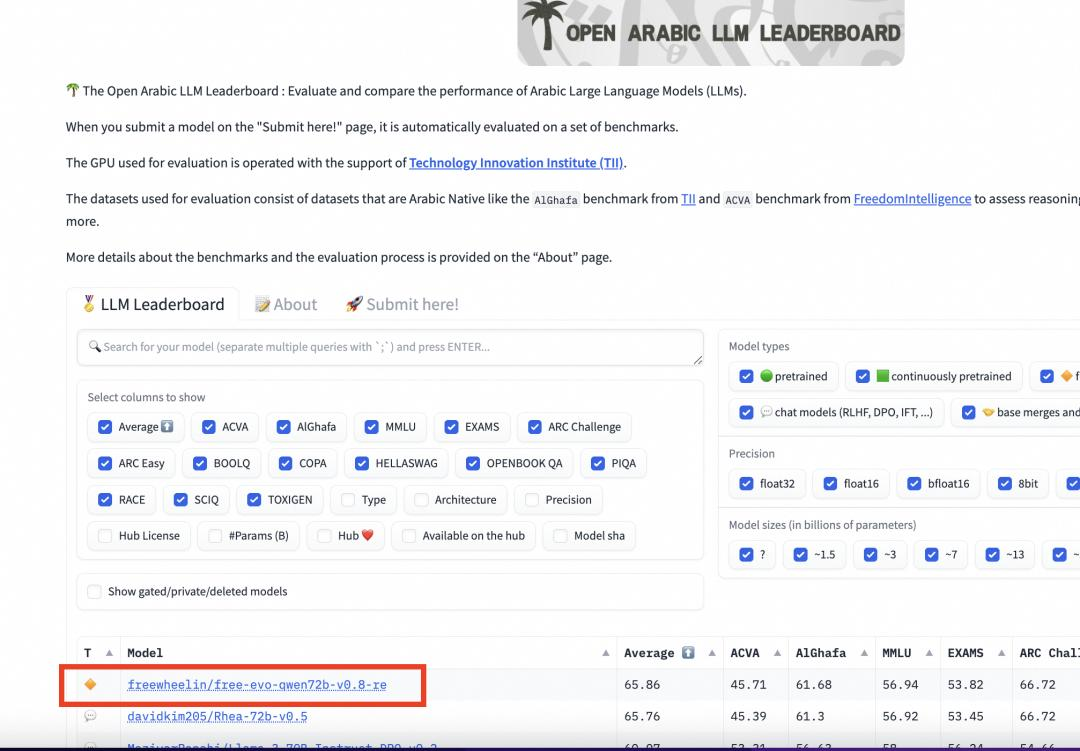
▲在阿拉伯语榜单上,Qwen2-72B稳居第一
与此同时,阿里云还首次披露Qwen2研发背后的多个创新方法。
根据通义千问技术博客,在Qwen1.5系列中,只有32B和110B的模型使用了GQA(分组查询注意力)。这一次,所有尺寸的模型都使用了GQA,从而使得模型推理大大加速,显存占用明显降低。
上下文长度方面,Qwen2系列模型均在32k上下文数据上进行训练,可支持128k上下文处理;为了提升模型的多语言能力,团队还对除中英文以外的27种语言进行了增强,并针对性地优化了语言转换问题。
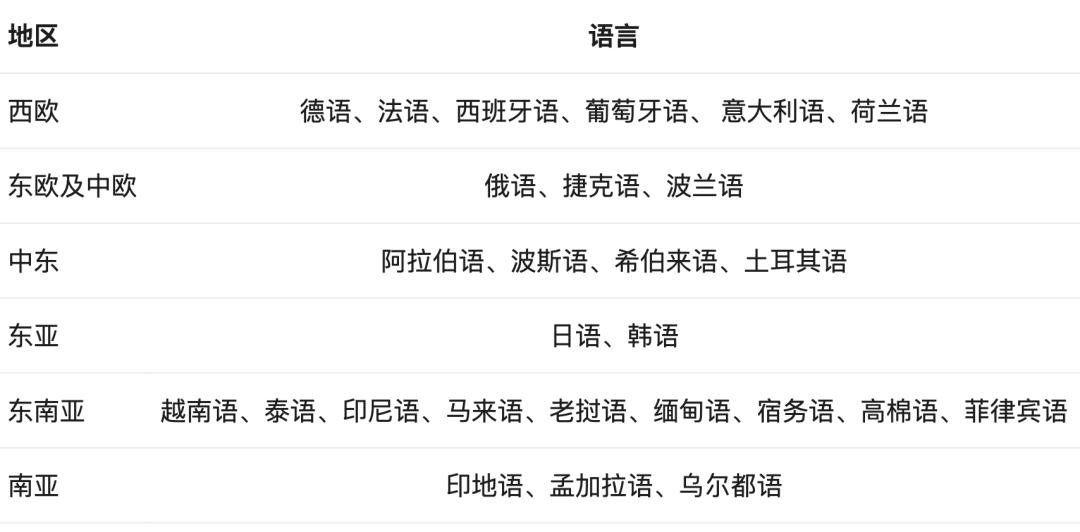
▲Qwen2对除中英文以外的27种语言进行了增强
在模型训练方面,团队结合了有监督微调、反馈模型训练以及在线DPO等方法,还采用了在线模型合并的方法减少对齐税。这些做法都大幅提升了模型的基础能力以及模型的智能水平。
在大模型后期精调过程中,通义千问团队在训练规模化的同时尽可能减少人工标注,采用自动方法获取高质量的指令和偏好数据,包括针对数学的拒绝采样、针对代码和指令遵循的代码执行反馈、针对创意写作的回译、针对角色扮演的Scalable Oversight等。
不久后,通义千问团队将推出Qwen2的完整技术报告。
尽管大模型的开闭源之争的话题仍在持续,但开源对大模型生态的积极意义已成行业共识,而这也是阿里云坚持大模型开源的核心原因。
中国信息化百人会执委、阿里云副总裁安筱鹏曾以“爬珠峰”形象地阐述了开源的价值:“生态的价值就是开源的价值,就是我派一架直升机,把你从海拔0米的地方运送到珠峰大本营5000米,剩下3000米你再爬。”
优质的开源模型,能推动大模型生态的繁荣,并让海量的开发者站在巨人的肩膀上做创新,从阿里云Qwen系列的开源社区的反馈来看,这样的生态逻辑确实在奏效。
根据阿里云官方数据,Qwen系列模型近一个月内总下载量翻倍,已突破1600万次。同时,海内外开源社区已经出现了超过1500款基于Qwen二次开发的模型和应用。
事实上,自今年2月Qwen1.5发布前后,就有大量开发者催更Qwen2。6月7日Qwen2上线后,多个重要的开源生态伙伴火速宣布支持Qwen2,包括TensorRT-LLM、OpenVINO、OpenCompass、XTuner、LLaMA-Factory、Firefly、OpenBuddy、vLLM、Ollama等。

▲Qwen系列多个重要的开源生态伙伴
从全球开源大模型竞争格局来看,除了美国Llama开源生态,通义千问Qwen系列已成为全球开发者的另一主流选项。
一年前,业内人士普遍认为开源模型和头部闭源模型之间存在较大的代差;如今,开源模型已经显示出超越最强闭源模型的势头,关于“开源大模型不如闭源大模型”的论调已然成为伪命题。
开源和闭源模型的你追我赶、节节攀升,带来的将是企业及开发者更加广泛和丰富的模型组合选择,以及更低的AI落地门槛、更好的应用效果。
最近几个月,开源大模型和闭源大模型你追我赶,这场拉锯战愈演愈烈。
先是今年4月Meta发布的Llama 3-70B赶超Gemini Pro 1.5等一众闭源模型,被当作“开源模型将一举翻越GPT-4高峰”的标志;然后是今日阿里云推出的Qwen2-72B再次屠榜,不仅赶超Llama 3-70B,还干翻了一大批头部闭源模型,进一步推动大模型生态的发展。
虽然通往通用人工智能(AGI)的大门刚刚打开,但大模型应用创新的奇点还远没有到来,正如阿里云智能集团CTO周靖人所说,大模型还有很大一部分潜力没有真正被挖掘出来,当有越来越多的开发者、企业融入这一进程,将带来翻天覆地的变化。
而坚持开源开放是加速这一进程的最佳途径。自2023年8月起,阿里云不到一年时间就陆续推出Qwen、Qwen1.5、Qwen2三代开源模型,实现了全尺寸、全模态开源,为大模型开源生态提供了强大的引擎。
开源和闭源都是大模型产业的重要力量。当开源力量高歌猛进,下一步,闭源派又将如何应对,我们拭目以待!
文章来源于“智东西”,作者“三北”



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
