# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
使用大模型合成的数据,就能显著提升3D生成能力?
来自上海交大、香港中文大学等团队还真做到了。

他们推出Bootstrap3D框架,结合微调的具备3D感知能力的多模态大模型。这个框架能够自动生成任意数量的高质量的多视角图片数据,助力多视图扩散模型的训练。
结果表明,新的合成数据能够显著提高现有3D生成模型的生成物体的美学质量和文本prompt的控制能力。
目前,Bootstrap3D的数据集已经全面开源。
近年来,3D内容生成技术迎来了飞速发展。然而,相对于2D图片生成,生成高质量的3D物体仍面临诸多挑战。
其中核心的瓶颈即在于3D数据,尤其是高质量数据的不足。
为了解决这一问题,研究团队推出Bootstrap3D框架,通过自动生成多视图图像数据来解决3D内容生成中高质量数据不足的问题。

具体来说,这个框架采用了2D和视频扩散模型来生成多视图图像,并利用一个经过微调的3D多模态大模型对生成的数据进行质量筛选和描述重写。
通过这种方式,Bootstrap3D能够自动产生大量高质量的3D图像数据,从而“自举”出一个足够大的数据集,辅助训练更优秀的多视图扩散模型。
这里插一嘴,在计算机科学和机器学习领域,“Bootstrap”通常指的是一种通过自举方法解决问题的技术。
数据构建Pipeline
具体来说,数据构建Pipeline是本次框架的核心创新之一,旨在自动生成高质量的多视图图像数据,并附带详细的描述文本。
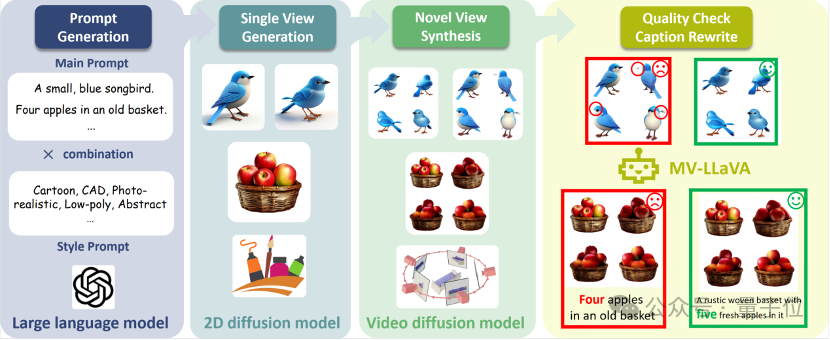
主要分为以下几个步骤:
文本提示生成:首先,使用强大的大语言模型(如GPT-4)生成大量富有创意和多样化的文本提示。这些文本提示涵盖了各种场景和物体,为后续的图像生成提供了丰富的素材。
图像生成:利用2D扩散模型和视频扩散模型,根据生成的文本提示创建单视图图像。通过结合2D和视频扩散模型的优势,生成的图像具有更高的初始质量和多样性。
多视图合成:使用视频扩散模型将单视图图像扩展为多视图图像,生成不同角度的视图。这一步骤确保了每个对象在不同视角下的一致性,解决了传统方法中视图不一致的问题。
质量筛选和描述重写:通过我们微调的3D感知模型MV-LLaVA,对生成的多视图图像进行严格的质量筛选。筛选过程不仅过滤掉低质量的数据,还重写描述文本,使其更加准确和详细。
通过这个数据构建Pipeline,Bootstrap3D能够生成大量高质量的3D图像数据,为多视图扩散模型的训练提供了坚实的基础。
这一创新不仅解决了3D数据稀缺的问题,还显著提升了模型的生成效果和对文本提示的响应能力。
训练timestep重安排(TTR)
团队还提出了一种创新的训练timestep重新安排策略(TTR),以解决多视图扩散模型训练中的图像质量和视图一致性问题。
TTR策略的核心理念是在训练过程中灵活调整合成数据和真实数据的训练时间步,从而优化去噪过程的不同阶段。
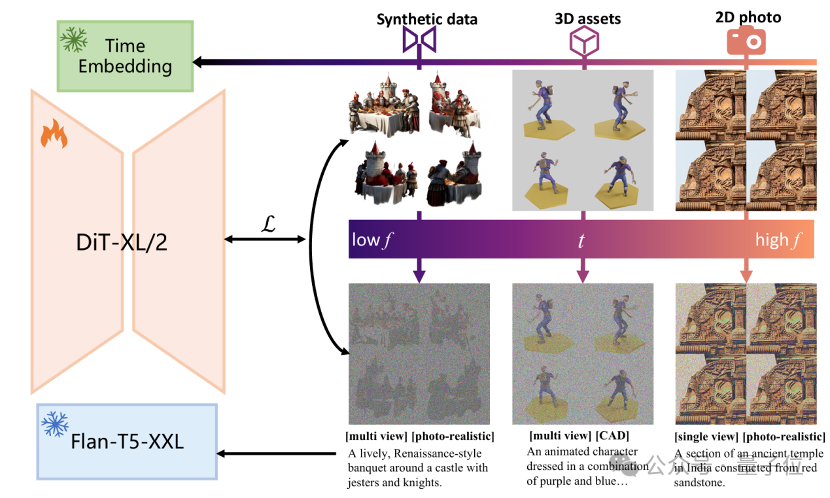
去噪过程的阶段性特征:在扩散模型中,去噪过程通常分为不同的时间步。在早期时间步,去噪过程主要关注图像的整体结构和形状(低频成分);在后期时间步,则主要生成图像的细节和纹理(高频成分)。这种阶段性特征为我们提供了调整训练策略的机会。
限制合成数据的训练时间步:由于合成数据可能存在一些模糊和失真,我们在训练时限制其时间步范围。具体来说,我们让合成数据主要参与早期的去噪阶段,确保它们对整体结构的贡献,而将后期的细节生成留给质量更高的真实数据。
分阶段训练策略:通过将合成数据限制在较大的时间步范围内(如200到1000步),我们确保这些数据在去噪过程中主要影响图像的低频成分,从而保持视图一致性。同时,真实数据则参与所有时间步的训练,以提供高频细节和真实感。这样的分阶段训练策略有效平衡了图像质量和视图一致性。
实验证明效果显著:广泛的实验结果表明,使用TTR策略的多视图扩散模型在图像-文本对齐、图像质量和视图一致性方面均表现优异。该策略不仅保留了原始2D扩散模型的优点,还显著提升了多视图生成的效果。
通过训练时间步重新安排策略(TTR),Bootstrap3D框架成功解决了合成数据质量参差不齐的问题,显著提升了多视图扩散模型的性能,为高质量3D内容生成奠定了坚实基础。
好了,Bootstrap3D生成的数据集已经全面开源,任何研究人员和开发者都可以免费访问和使用。
文章来源于“量子位”,作者“关注前沿科技”




【开源免费】LGM是一个AI建模的项目,它可以将你上传的平面图片,变成一个3D的模型。
项目地址:https://github.com/3DTopia/LGM?tab=readme-ov-file
在线使用:https://replicate.com/camenduru/lgm
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
