# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
过去十年间,AI 技术经历了巨大的飞跃,无论是在自然语言处理、图像识别,还是在更多的创新领域,AI 的影响已无所不在。
伴随着研究数量的爆炸性增长,学术界和工业界同样面临着一些挑战,其中就包括「论文复现」和「跨学科协作」的难题。特别是当我们来到了大模型时代,面对动辄百亿参数量的模型研究,开源、复现、协作变得更加重要,但难度却更上一层楼。
论文复现,首先是评判一项成果价值的重要参考因素。同时,在快速发展的 AI 领域,确保研究的可复现性将更好地推动知识的积累和技术的普及,也是维护学术诚信和促进持续创新的关键所在。面对这些问题,倡导开放科学和透明研究显得尤为重要。通过开源代码、数据和实验细节、提供更低成本的、针对复现需求的算力平台,以及提供支持快速复现的交互式程序,我们或许能够在推进科学研究的道路上,建立更加稳健和可靠的基础。
如果说「复现难」的问题,就像是为研究者之间的「对话」增添了一道高墙。那么「协作难」的问题,同时也为跨学科的合作建立了无形的屏障。
大模型时代,如何搭建一个方便的、能够降低交流和协作门槛的平台已经成为一大挑战。我们所熟悉传统的软件开发协作方式,例如基于 Git 的代码管理与版本控制,在 A I 研发这种更依赖于实验而非确定性过程的场景下可能不再适用,其复杂的实验版本管理和较高的使用、部署门槛往往阻碍了不同领域专家之间的交流与协作。当前的 AI 领域需要新的协作模式和工具,包括更直观、易于使用的版本控制和协作平台,让非技术背景的专家也能方便地参与到模型的开发、评估和演示过程中来。
换句话说,无论是科研工作者还是从业者,都希望能在知识和技术的共享基础上,实现更加高效、有深度的协作,推动 AI 领域的进一步发展。
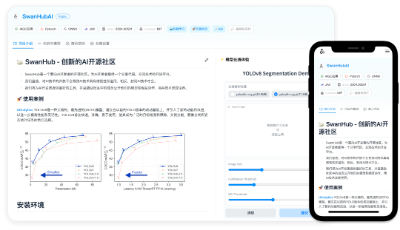
在这样的背景下,一个全新的 AI 开源社区平台「SwanHub」诞生了。
值得关注的是,SwanHub 来自西安电子科技大学的一支非常年轻的在校研究生和本科生团队。团队的四位成员均为 95 后,不仅有着丰富的 AI 研究经验,还有对开源的热情。在指导老师吴家骥教授和谭茗洲教授的带领下,他们从零开始构建了一个 AI 模型一站式协同开发、开源共享、可视化展示平台,旨在解决当前 AI 模型复现难、部署难、管理难的核心问题。
在 SwanHub 这一平台中,AI 研究者和从业者不仅可以获得丰富的开源模型和工具资源,还能够享受到协同开发的便捷与高效。目前,SwanHub 已经上线几大核心功能,包括 AI 模型托管、可视化展示等。
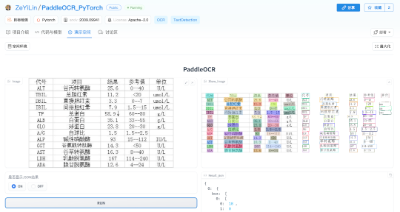
首先,AI 研究者可以将自己的代码托管到 SwanHub 上进行版本管理,像使用 Github 托管平台一样。但与 GitHub 相比,SwanHub 支持更高容量的大文件托管,研究者可将多达几十个 GB 的模型权重文件进行托管与版本管理。
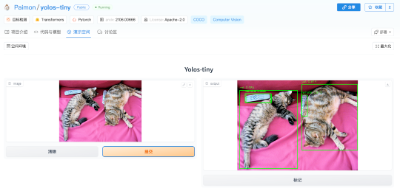
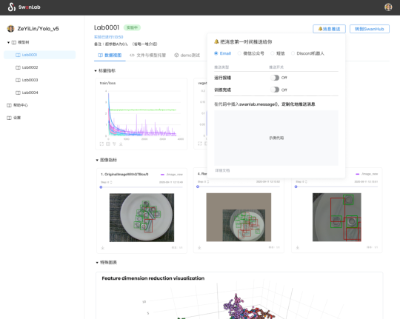
「可视化展示」也是 SwanHub 的一大亮点。很多在顶级会议和期刊上发表的研究文章都会展示漂亮的效果和创新的技术。但在实际操作中,尝试复现这些研究成果的工程师和研究人员却常常遇到困难。正因此,近年来很多学术会议不仅要求作者提交代码,也要求提交一定数量的 Demo,提供更充足的研究信息,而 SwanHub 恰好提供了这样一个公开展示成果、获取更多科研流量的平台。
如下图所示,SwanHub 平台提供了一套简易的模型 Demo 部署工作流,让用户可以通过点击几个按钮的方式,轻松地将代码和模型权重部署成一个可视化、可交互的网页 Demo,实现实时在线测试 AI 模型的推理结果,并支持分享给协作者、审稿人、同行或公开在互联网上。SwanHub 也支持主流的可视化框架如 Gradio、StreamLit 等。
SwanHub 不仅为想要分享成果的研究者提供了一个展示自己开源模型的平台,其他研究者也可以在这里轻松地访问到其他研究者的开源成果、体验 Demo,以及在讨论区进行学术讨论。
此外,团队表示,SwanHub 即将上线两项功能:第一项功能是代码一站式部署服务,让用户可以轻松地将机器学习模型部署为一个云服务 API(应用程序编程接口),并同样支持开放给全社区或私有使用。对于开放自己模型的 API 的研究者而言,可以让自己的研究成果更快地接入到各个应用场景中,提高研究的影响力;同时对于使用者而言,也能更快地让自己的应用接入各类强大的开源 AI 能力。第二项功能是模型实验管理工具 SwanLab,用户可以将自己的实验日志记录程序接入 SwanLab,即可实现在线实验日志记录和管理功能。平台不仅仅能够帮助记录训练日志和托管中间模型,还能够提供可视化训练结果、训练完成消息推送、超参数记录与推荐、模型跨版本对比等功能,便于研究人员快速试错和开发,以及提升多人协同训练的效率。
很少有人知道的是,SwanHub 开源社区平台的背后是四位年轻的「95 后」成员。
林泽毅、陈少宏、韩翔宇、雷清扬四人相识于西安电子科技大学的校园,曾出于各自对技术的兴趣组建过一个名为「光年科技工作室」的社团。后来,几个志同道合的年轻人共同创立了「极创工作室」,踏上了科技创业的旅程。
打造 SwanHub 的灵感,除了来源于团队基于当前 AI 领域对开源社区需求的洞察,其实也和他们自己的研究经历有关。
在从事 AI 研究的过程中,他们常常感受到来自内部协作和项目展示方面的需求和挑战。虽然常用的一些开源平台能够提供基本的托管功能,但往往缺乏一个基于模型的可视化协作版块,导致实验室成员之间的合力难以凝聚。
对于大部分的研究者来说,诸如此类的问题是很常见的。一方面,复杂的实验版本和多人协同带来的困难会限制研究项目的发展,另一方面,模型的部署难度较大以及训练过程的复现困难也阻碍团队的内部交流和知识积累。在日常的学术交流活动中,他们同样缺乏一个直观展示成果和积累的平台。
「这些因素进一步强化了我们搭建一个属于自己的协作和展示平台的愿望。」SwanHub 项目负责人林泽毅介绍说。「我们希望提供一个针对 AI 领域的开源社区,在论文复现、技术选型、技术分享等方面帮助更多的科研工作者与从业者。此外,我们期望这种基于模型的可见、可交互的协作模式能够提高 AI 项目的迭代速度和团队成员之间的交流效率,减少不必要的等待和沟通成本。」
因此,SwanHub 项目的最初设想是提供一套完整的 AI 工作流程,从论文到开源代码再到部署和可视化展示。通过这套工作流程,人们可以在进行实验和投稿论文的同时,轻松地搭建可视化的演示,以供同行快速复现和试验。另一方面,提供可交互 Demo 的学术项目也更容易获得更高的传播度和更好的口碑,进而获得更高的学术影响力。
同时,团队还考虑到了业界开发者的需求。与传统的软件开发不同,AI 开发是一种实验科学,特别是到了大模型时代,技术的开发和测试思路也发生了很大的变化:在实际应用中,尽管模型可能在某些客观指标上表现出色,但如何在实际场景中施展它们的「智能」,如何将它们融入到专业工作流程中,往往需要相关领域的专家进行深入的实际效果测试,而这个过程同样是挑战重重的。
对于这一点,SwanHub 项目成员陈少宏的体会比较深刻。他所在的 AI 研究团队曾经参与一家智能手机厂商视频处理算法研发的项目,当时的研究团队成员分散在全国多个城市,大部分工作需要线上协作。但从算法更新、验证、端侧部署、反馈的整个线上流程来看,每一次模型迭代需要以「1.5 个星期」为单位,显然赶不上项目原本规划的落地节奏。
为了加快算法更新效率,陈少宏推荐研究小组使用了 SwanHub,每训练完一个版本的模型,都可以在平台上快速更新 Demo,厂商各部门的人员,包括 PM、产品经理、测试、市场、其他研究人员,都可以在线试验效果,提供多样化的改进反馈,极大地提高了合作双方的沟通和协作效率,也大大提高了模型的迭代速度。
这种跨学科的协作,在此前以代码为核心的协作上是很难做到的 —— 比如让一位市场部的项目成员去安装环境、运行项目是阻力极大的事情,而以 Demo 为核心的平台让跨领域协作成为了可能。
二十年前,一本名为《开源:革命之声》的著作曾风靡科技圈。这本书深入探讨和记录了十多位开源先驱对于开源文化的理解和阐述,包括 Linux 之父 Linus Torvalds、自由软件运动创始人 Richard Stallman 等传奇人物。
比如,Linus Torvalds 一直是开源的忠实拥护者,曾公开表达:「未来的一切都是开源的(The future is open source everything)。」三十多年来,他不遗余力地为 Linux 社区注入心血,让 Linux 从一个仅有几百位用户的自由操作系统开始,逐渐成长为一个伟大而富有创造力的社区。
SwanHub 的团队成员对于开源的热情就起源于这本书籍,他们甚至尝试将此前只有英文原版的书稿译为中文,翻译的过程让他们更加深刻地认识到开源在学术交流与科技发展中所能发挥的巨大推动作用。
打造 SwanHub 开源社区的深层价值也在于此。纵观今天的 AI 领域,大部分有影响力的进展都深深植根于开放科学和开源的原则。这些原则不仅倡导知识的自由传播和共享,还实质性地推动了全球范围内的科研协作与创新。
Hugging Face 社区的「Transformers 库」便是一个经典的例子:这家成立于 2016 年的公司,凭借其易用的接口和大量的预训练模型迅速获得了 AI 社区的广泛认可和热烈欢迎。它不仅提供了一个用于发布、分享和协作的平台,还开启了一种创新的协作模式,大大降低了深度学习模型的使用门槛,从而让更多的开发者和科研工作者能够应用这些模型到实际的项目和研究中。
最重要的是,Hugging Face 社区鼓励并促进了全球范围内的协作。开发者和研究者们在此平台上分享自己开发的模型、贡献代码、提出问题,共同寻找解决方案。这种集思广益的协作方式极大推动了 AI 技术的发展,也将一些前沿的、可能原本属于封闭研究的技术开放给了公众。
Hugging Face 的成功不是偶然的,它揭示了一个开放、协作的技术社区对于科技进步起到了不可忽视的推动作用。当科研工作者有了公开分享数据、方法论、模型和工具等研究成果的渠道,他们的贡献就能成为广大研究社区的共同财富。
这种开放分享的实践允许其他研究者站在「巨人」的肩膀上,不仅能看到更远的地方,也能通过继续探索和创新。身处这样一个环境中,AI 技术的发展才能够在一个正向循环中迅速推进。
在这一点上,SwanHub 的目标和 Hugging Face 是基本一致的。关于 SwanHub 的未来,团队希望能够持续提升 SwanHub 在协同、部署、社区等方面的能力与体验,并将围绕 SwanHub 打造工具矩阵,包括大模型模块化编程工具 SwanChain、模型实验管理工具 SwanLab 等,覆盖 AI 研究的整个生命周期,并持续走开源道路。
如今,大模型风云乍起,新的成果不断涌现,谷歌和 OpenAI 这样的公司可能不会有「护城河」,而开源力量却在不断崛起和追赶,形成这一局面的因素中,也包括无数开源拥护者的共同努力。
文章来自微信公众号 “机器之心SOTA模型”,作者 机器之心


【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)