# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
谷歌作为全球领先的科技公司,在 AI 领域拥有深厚的积累和卓越的创新能力,在谷歌眼里,生成式 AI 带来了哪些机会?Google AI 是如何在谷歌产品中落地的?Google Cloud 提供了一系列工具和平台,如何帮助开发者构建和部署自己的专属 LLM 和 Agent?负责任的 AI 为企业带来哪些价值?
伴随着这些思考,在 AGI Playground 2024 上,Google Cloud 中国架构团队总监赵霏分享了谷歌在 AI 上的布局和实践经验,让大家更完整了解 Google AI 背后的产品矩阵。

在生成式 AI 如此火爆的当下,模型之外我们讨论的更火热的一个话题是,大模型到底怎么落地?我们到底怎么应用它?
今天举几个例子,希望通过这些例子给大家一些启发和思考。
谷歌的产品 Google Workspace,是包括 Gmail,Google Meet,Google Chat 等在内的一整套办公软件。Gemini 大模型被成功应用于 Google Workspace 办公套件中,展现了其强大的落地应用能力,为用户带来了更加智能、高效的办公体验:
Document AI 是一款基于大模型的智能文档处理工具。区别于传统的 OCR 识别、OpenCV 识别,利用大模型的方式识别我们上传的各种文件,包括各种图像文件,比如海关报备的税单、税表、交易文件,一切都不需要专门去做定制模版,Document AI 识别的同时还能帮助我们在很多文档里进行快速搜索,而且还能用自然语言搜索。一份英文文档传到 Document AI 里,可以用中文搜索。为什么?其实是把能力变成向量,通过自然语言的方式,用中文搜索英文文档。
除了文生图,大家翘首期盼的文生视频也即将上线 Google Cloud。谷歌迄今为止最强大的视频生成模型 veo,可以生成超过一分钟的高质量、1080p 分辨率的视频,并拥有广泛的电影和视觉风格。如果是想现在就体验 veo 的用户,可以到 Google Labs 平台注册加入 VideoFX 的 waitlist,对 veo 的能力先睹为快。
同时,Google DeepMind 近日发表了一个新的模型,叫「video-to-audio (V2A)」, 该模型可以根据视频自动生成匹配的音乐,并支持用户自定义音乐风格。通过生成视频和 V2A 技术,我们可能以后就能生成完整的短片了。
讲到谷歌离不开搜索,搜索到底用 AI 加强了什么?
现在的搜索,通过 Gemini 可以实现包括多步推理规划和多模态。以前我们搜索一家餐厅,如要想实现「5 公里之内人均消费 120 块钱中餐,然后环境要好,10 人包厢」,得用关键词一步一步搜索。现在用谷歌搜索,您无需将问题分成多个搜索,而是可以一次性提出最复杂的问题,包括您心中所有的细微差别和注意事项。
Gemini 可以理解用户复杂的搜索意图,并根据多个步骤进行推理,最终找到最符合用户需求的搜索结果。
其实在 2016 年,我们的 CEO Sundar 就说过,我们是一家以 AI 为主导的公司,这个理念造就了谷歌多年来在 AI 研究领域的创新。

今天谈到大模型,大家都会谈到一个词叫 Transformer。2017 年,谷歌发布了 Transformer 的论文。那么 Transformer 是用来做什么的呢?其实是为了解决谷歌的一个产品——谷歌翻译所面临的问题。谷歌翻译每天会处理 1000 亿个单词。在 Transformer 出来之前,最常见翻译的神经网络是 RNN,主流是逐字来处理翻译。 而 Transformer 的核心要素就是当我们翻译一个单词的时候,要考虑他在一句话中间的位置,与其他单词的关系,与上下文结合来推测语义。
然而在这种架构下,它实现了对模型的并行训练,而不是逐字。那么这种并行训练就允许我们通过横向扩容的方式来处理多几个数量级的数据,而为大语言模型奠基。2018 年,根据 Transformer 的 encoder 模型,我们建立了一个新的模型叫 BERT。这是第一个真正做到 NLP 的模型。后续我们还开发了多任务的模型 T5,对话模型 Lamda。2022 年我们推出了大语言模型 PaLM。2023 年,我们又推出了多模态原生大模型 Gemini。
很多创业者这一段时间都开始听说 Gemini 了,Gemini 在几个方面与其他模型存在显著差异:
第一点,它是真正的多模态。所谓的多模态是什么?从训练的第一天开始,我们喂给模型的语料和数据就包括了视频、图片、文本、编码、音频。这种语料的输入就使得模型天然就理解所有的输入。这意味着它不仅能处理文本,还能理解和生成图像、音频等其他类型的数据。这为 Gemini 在更广泛的应用场景中提供了可能性,如图像描述、视频摘要、创意生成等。
其次 Gemini 模型大小上又分了不同的大小,以满足不同场景和延迟的需求。Gemini Ultra 是一个非常非常大的模型;Gemini Pro 是我们面向大多数用户的模型;而 Gemini Nano 是我们应用在端侧的小模型。
最后,Gemini 从设计之初就严格遵循 Google AI Principles 的理念,将安全性和合规性置于首位。Gemini 团队在开发过程中始终将这些原则融入到模型的各个方面。例如数据选择和处理,模型架构设计,模型测试和评估以及用户反馈机制等。
如今,我们已经引入 Gemini 到我们很多的产品中。Gemini for Google Cloud 可以让大家更快速地使用 Google Cloud 的能力。同时 Gemini 还可以放在我们的 Pixel,搜索,Ads,Chrome 等等。
有的开发者会问,怎么能在自己的应用中使用 Gemini 的能力呢?或者 Google Cloud 提供了什么?所有这些技术能力的交付,我们都是通过 Google Cloud 平台,这里面会分为几个部分。
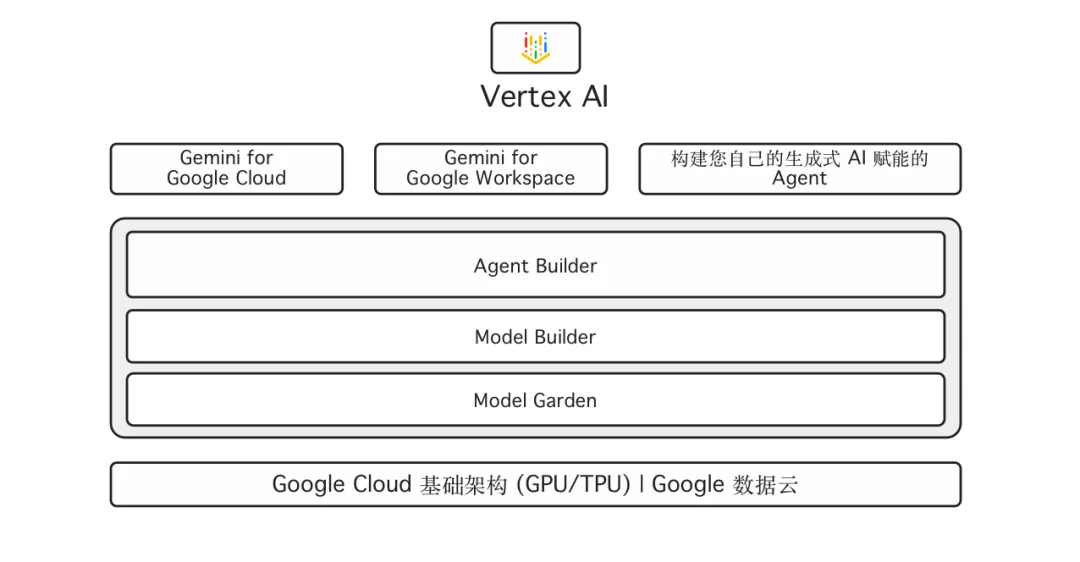
最底层提供了 Google Cloud 的算力部分,包括 GPU、TPU;然后再往上是 Vertex AI - Google Cloud 上的一站式 AI 平台,提供了从模型选择、模型构建到智能 Agent 构建的一站式服务。
谷歌有一个东西叫 TPU,大家一直很疑惑这个东西是什么。
TPU 是 谷歌定制开发的专用集成电路 (ASIC),用于加速机器学习工作负载。谷歌结合机器学习领域的丰富经验与领先优势,从零开始打造了这些 TPU。我们知道机器学习实际上就是在进行矩阵计算,而矩阵的运算都是最简单的,只有乘法和加法,但是它有非常多的矩阵单元,而 TPU 上的 MXU 有着更多的 ALU 从而可以在一个周期内完成更多次的加法和乘法计算。
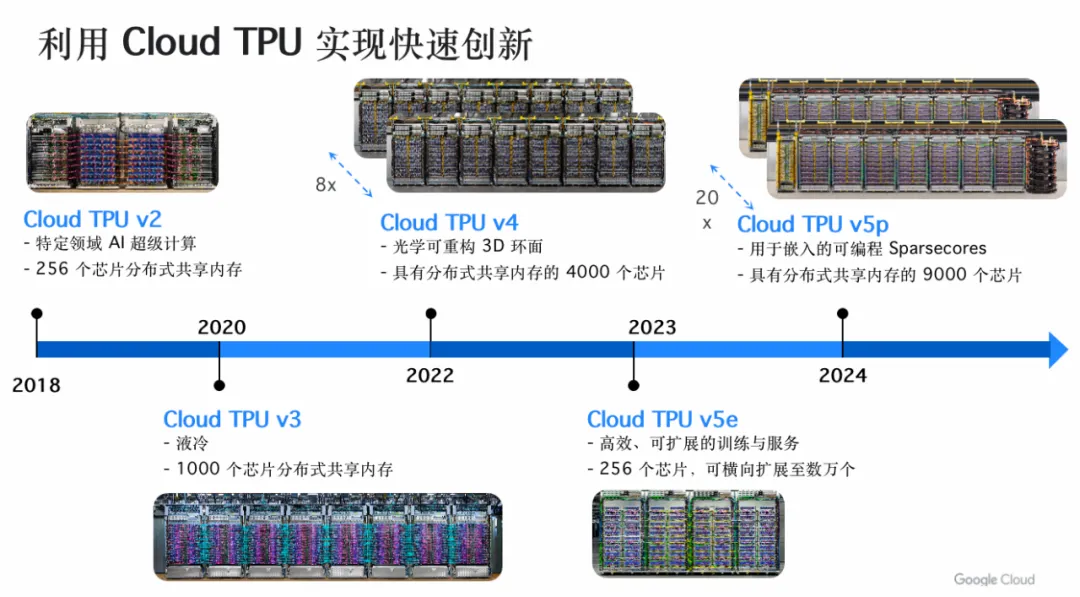
第二,在矩阵运算里面,大部分是芯片和芯片直接通信,不需要通过 CPU。而TPU 从第一天开始,就是为矩阵设计的,中间没有通过任何 CPU。并且随着 TPU 本身算力的升级,它在卡和卡之间的高速运转的带宽上也在不断地加强。

谷歌第 6 代 TPU 会带来更多算力的价值和带宽的价值
讲到模型,其实在 Google Cloud 的模型平台里面,有一个东西叫 Model Garden,至今已经包含了 130 多个模型。里面有谷歌第一方的模型 Gemini;也包括谷歌的开放模型 Gemma,开发者可以来直接来使用它;同时还有第三方的,比如这两天 Anthropic 发布的 Claude 3.5,也第一时间上线了 Model Garden。
大家如果想体验谷歌第一方的模型、开放模型和三方的模型,一个 Model Garden 就可以解决所有的事情。
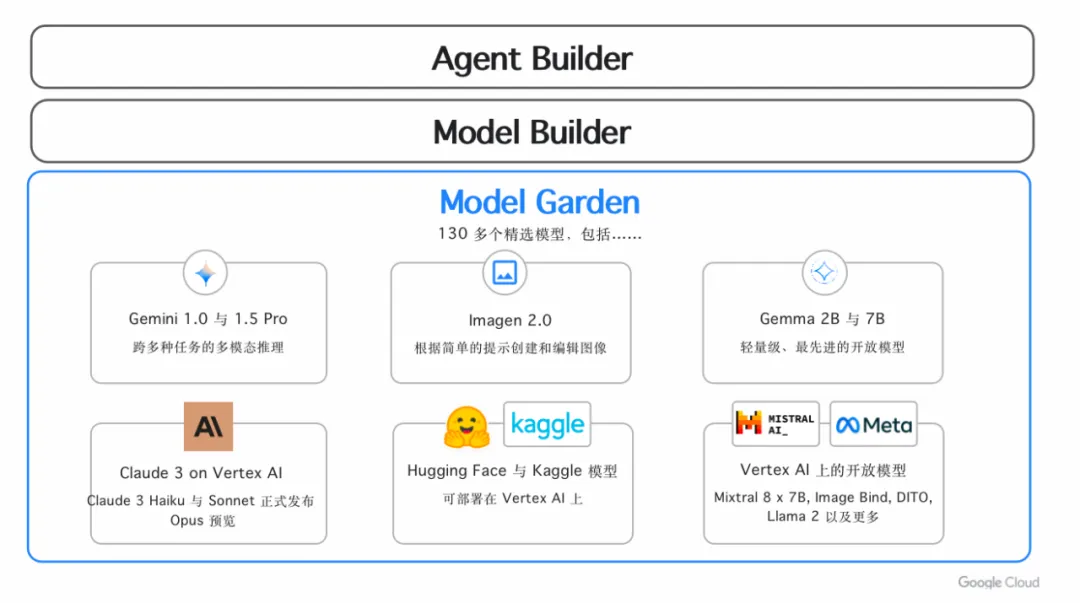
那谷歌自家的模型到底有什么特点呢?Gemini 1.5 Pro 是目前谷歌最 powerful 的模型。它是一个 MoE 架构,可以支持 200 万的上下文,相当于两个多小时的电影,几十万、一百多万字的文档。
当我提出一个非常复杂的问题或者过往很长时间的卷宗的时候,可以把所有的 input 一次性放进来。并且我可随意地问它问题;我可以让它做视频的分析,甚至把安全监控批量输入给它。
另外谷歌一直秉持着知识开源社区的理念,并推出了 Gemma,它是一系列的开放模型的家族。简单来说它就是更小的模型,并且提供更好的性能。
在基础模型之上,我们有时还需要构建模型以解决特定领域的专有问题。
因此我们提供了这样一个工具 Model Builder,它可以提供微调、优化、监控和部署。简单来说,我们提供了一系列构建自定义模型的方式,如下图所示,方法越往左边越简单。

第一种是提示词工程方法,通过对提示词的优化就可以达到特定模型的输出效果,只需要在输入的提示词种给出几个示例 few shots,让模型以后回答问题照例执行即可。
第二种是监督调整,所谓的「监督调整」就是我们日常所说的 Supervised Fine Tuning(微调)。通过向大模型输入上百个标记好的答案并进行训练后,新的模型就会按照这个理念来回答问题和进行推理。
第三种是从 Human Feedback(人工反馈)里训练模型、强化学习。现在的模型训练都会有这个环节,大模型在回答问题后,让用户帮忙选择「认可」和「不认可」,而之后把几千个这种标记的数据作为训练数据,让模型进行强化学习的训练,从而得到自定义的模型。
最后是最复杂的方法即对大模型进行蒸馏,把它蒸馏出更小的模型,做出针对某个领域或参数更少的小模型。这一切的构建模型的方法都可以在 Google Cloud 上通过 Model Builder 来实现。
接下来就是真正的应用阶段,到这里,我们通常所谈到的智能代理也就是 Agent。你可以把 Agent 想象成为一个可以自主去交谈、推理、学习和作出决策的独立智能载体。在未来的互联网上,将产生更多的互联互通生成式 AI的智能代理。这里 Google Cloud 总结了 101 个现实世界的生成式 AI 的用例,并归纳了六个不同方向,分别是客户服务、员工赋权、创意构思和制作、数据分析、代码创建、安全防护的 Agent。在 Google Cloud Agent Builder 的帮助下,不用编码或者用很少的编码就可以打造出 Agent。
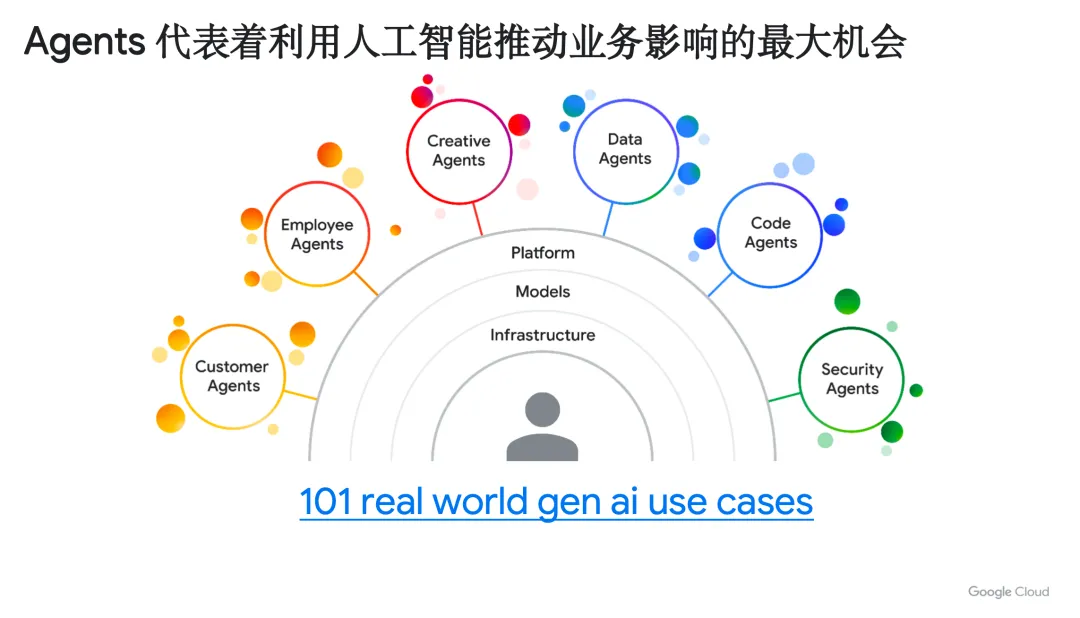
我们为什么要用它实现 Agent 呢?举个例子,大模型不知道我的企业数据,我如何把模型和企业数据相结合呢?通过 Agent Builder 做函数构建,直接引入企业搜索,我就可以把大模型和数据库直接结合。
我们知道大模型有时候会产生幻觉,为了让它给出真实可靠的答案,我们可以用网页搜索,在谷歌的 Agent Builder 里可以无缝涵盖谷歌搜索的能力。
上面我们在说怎么去做自己的模型,最后想跟大家分享一个观点:Responsible AI 等于 Successful AI。
当我们的模型拥有了生成能力后,我们需要考虑它会不会为企业带来负面的影响。在谷歌,不光是 Google Cloud,整个 谷歌都有 Google AI 原则。

Google Cloud 提供的 API 工具|Google Cloud
在 Google AI 原则之上,我们会详细规定哪些事情模型可以做,哪些事情模型不可以做。在训练时我们就会在模型里加入这些理念,同时在模型输出时会做过滤检查。
在内容审核方面,Google Cloud 也提供了 API 给开发者和创业者使用。模型生成出来的内容可以通过 API 的调用,在 16 个维度进行 16 个不同类别有害内容的分析以及打分,保证 AI 在企业和应用上的安全落地。
解决了 AI 的安全问题,大模型落地的最后一步才算是彻底打通了。
AI 时代已经到来,Google AI 正在引领着 AI 技术的发展。
总而言之,Google AI 在 AI 技术和产品方面拥有众多领先优势,包括强大的 AI 模型、高效的 AI 芯片、丰富的 AI 模型平台、易用的 AI 开发工具和负责任的 AI 理念。Google Cloud 提供了一系列工具和平台,帮助开发者轻松构建和部署自己的专属 AI 模型,助力企业快速落地 AI 应用,开启智能未来新篇章。
文章来自于微信公众号“Founder Park”,作者 “Founder Park”




【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
