# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
新架构,再次向Transformer发起挑战!
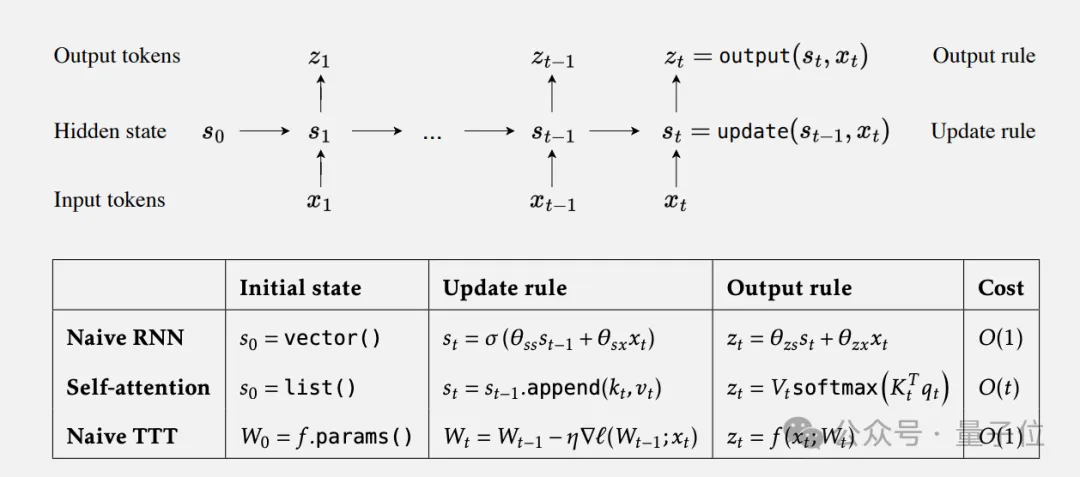
核心思想:将RNN中的隐藏状态换成可学习的模型。
甚至在测试时都可以学习,所以该方法称为TTT(Test-Time Training)。
共同一作UC伯克利的Karen Dalal表示:我相信这将从根本上改变语言模型。

一个TTT层拥有比RNN表达能力更强的隐藏状态,可以直接取代Transformer中昂贵的自注意力层。
在实验中,隐藏状态是线性模型的TTT-Linear表现超过了Transformer和Mamba,用更少的算力达到更低的困惑度(左),也能更好利用长上下文(右)。
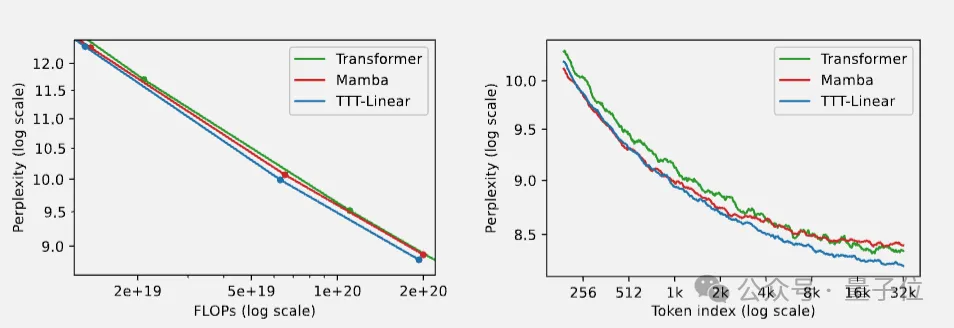
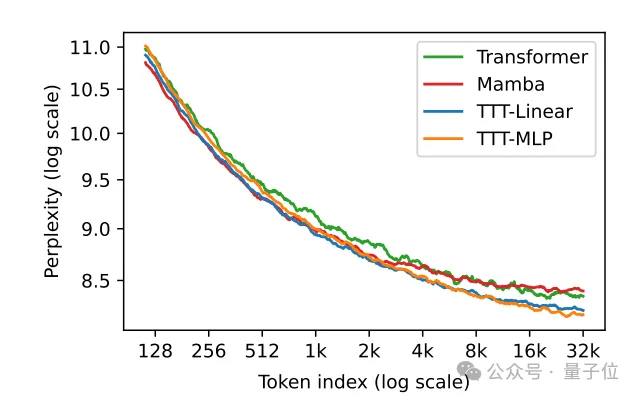
此外,隐藏状态是MLP模型的TTT-MLP在32k长上下文时表现还要更好。
Karen Dalel还指出,理论上可学习的隐藏状态可以是任意模型,对于更长上下文来说,可以是CNN、甚至可以是完整的Transformer来套娃。
目前刚刚出炉的TTT论文已经在学术界引起关注和讨论,斯坦福博士生Andrew Gao认为,这篇论文或许能成为下一篇Attention is all you need。

另外有人表示,众多新架构能否真正击败Transformer,还要看能不能扩展到更大规模。
Karen Dalel透露,马上就会推出7B模型。
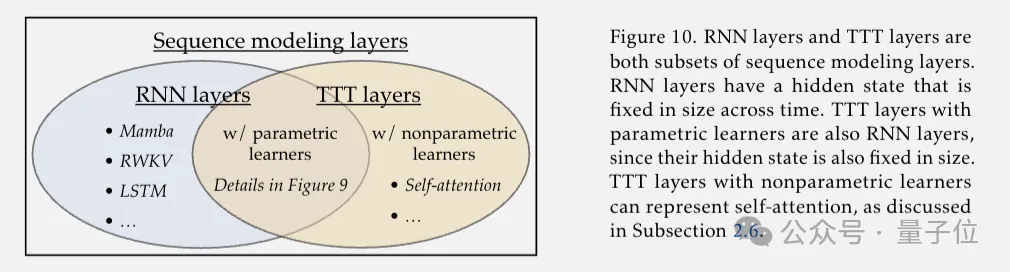
传统RNN,隐藏状态固定大小表达能力受限,也不好并行训练。
Transformer强大,但自注意力机制随上下文长度呈平方复杂度,非常昂贵。
最近一系列基于RNN的架构创新中:
RWKV,用线性注意力结合RNN和Transformer的优点,在训练时可以并行计算。
Mamba,赋予模型选择性记住或遗忘信息的能力来压缩上下文,同时设计了面向硬件的高效并行算法。
它们的表现在短上下文时追上甚至超越了Transformer,但在32k超长上下文以上,Trasformer依旧称霸。
TTT团队的想法来自于:与其让隐藏状态被动地储存信息,不如让它主动学习。
就像Transformer模型作为一个整体在压缩互联网数据到参数中一样,可学习的隐藏状态模型也在少量参数上不断缩上下文信息。
这种“隐藏状态模型”随着时间的推移仍然具有固定的大小(固定的模型参数),但表达能力更强了。
论文的联合指导UCSD助理教授王小龙认为:
Transformer显式地储存所有输入token,如果你认为个神经网络是压缩信息的好方法,那么压缩这些token也将是有意义的。

如此一来,整个框架的时间复杂度还是线性的,
至此,序列建模被拆解为两个嵌套的学习循环,外循环负责整体的语言建模,内循环通过自监督学习压缩上下文信息。
外循环的参数变成了内循环的超参数,也就是元学习的一个变种了。
标准的元学习是训练一个适应不同任务的模型,而TTT是让模型去适应每一个测试样本。单个样本虽然信息量小,但用来训练隐藏状态模型也绰绰有余。
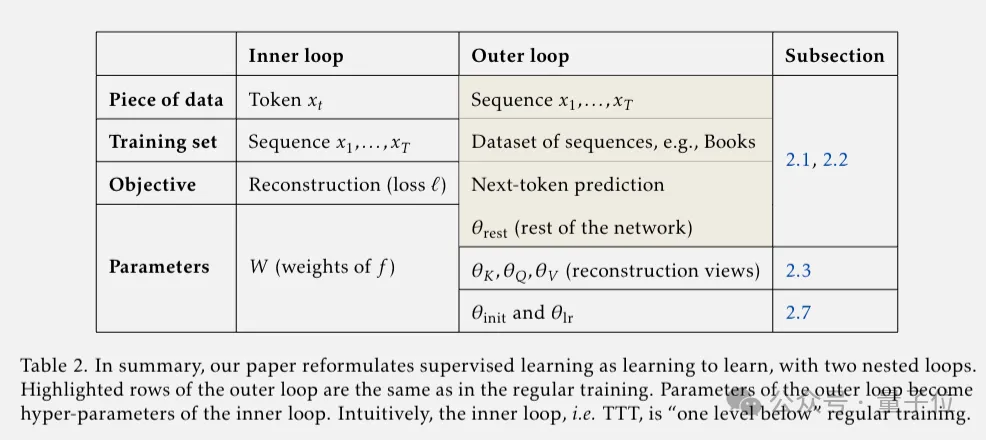
特别的,在内循环是一个线性模型时,相当于线性注意力。当内循环是一个Nadaraya-Watson estimator时,TTT等价于自注意力。

在TTT层里,使用自监督学习方法将上下文压缩到隐藏状态。
上下文就是未标记的数据集,隐藏状态不再是一个固定的向量,可以是线性模型、小型神经网络或任何机器学习模型,更新规则采用了在自监督损失上的一步梯度下降。
这样一来,隐藏状态模型可以记住产生大梯度的输入,并且可以获得比选择性遗忘机制更强的拟合和泛化能力,并且在测试时仍然为每个输入序列训练不同的参数。
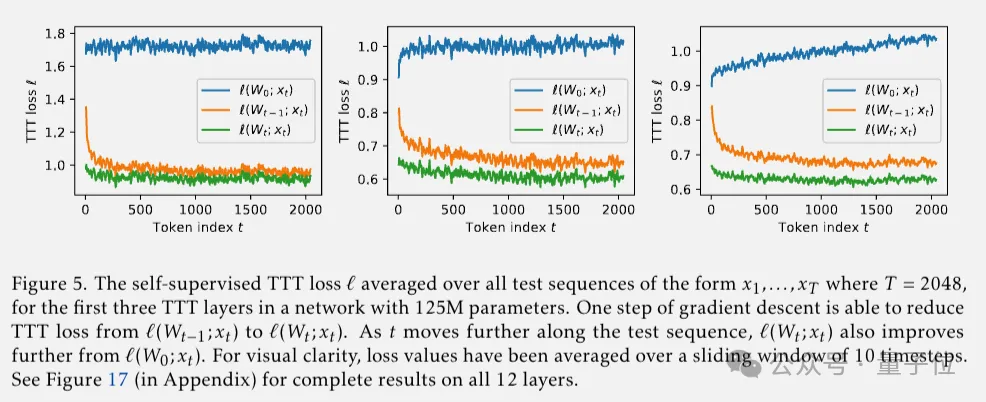
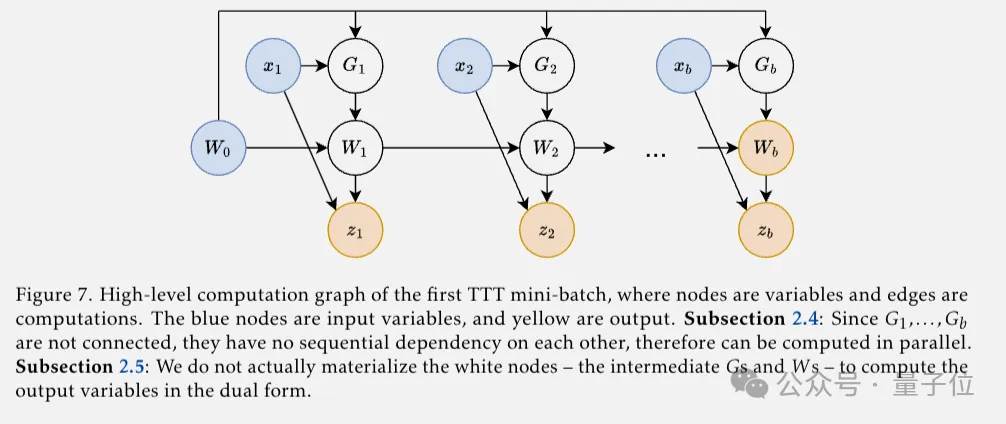
到目前为止,朴素的TTT层已经有效了,但还无法并行化。
团队提出的解决方案为mini-batch梯度下降,把一个batch内的梯度计算并行化。
再通过Dual form方法,只在mini-batch结束时计算权重以及输出token,避免冗余计算。在JAX版实现中快了5倍以上。
理论上都走的通了,那么TTT在实验中表现到底如何?
最简单干净的测试方法,应该是直接替换掉Transformer中的自注意力层。
但是在研究过程中,团队发现Mamba等现代RNN的骨干中在RNN层之前还包含时间卷积,对TTT也有帮助。
所以实验中TTT-Linear和TTT-MLP主要应用到Mamba骨干上,其他训练细节也严格遵照Mamba论文中的设置。
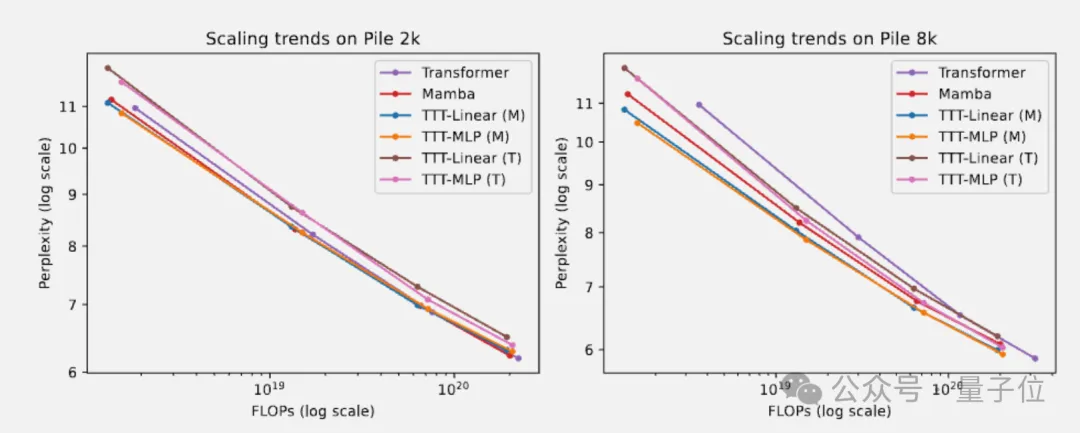
最终在Pile数据集短上下文测试中:
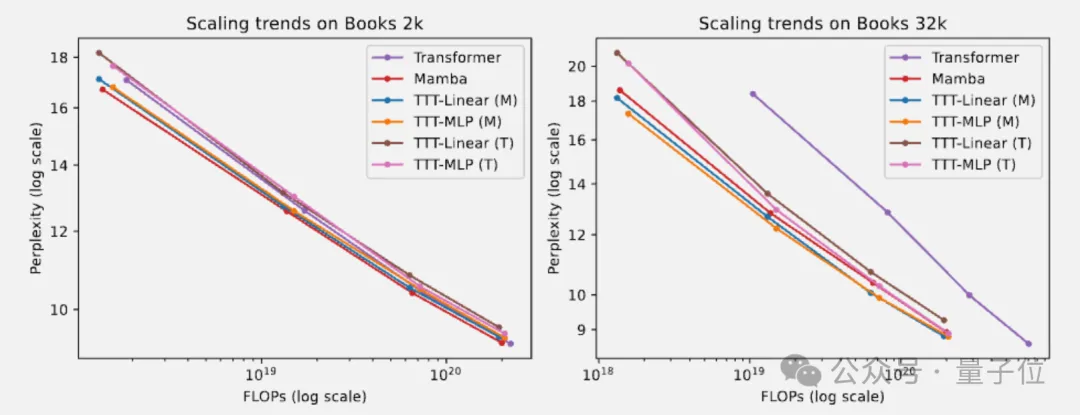
总的来说,随着上下文长度的增长,TTT层相对于Mamba的优势也会扩大。
另外团队猜测,线性模型比MLP表达能力差,因此从Mamba骨干的卷积中受益更多。
长上下文实验使用Pile的子集Books3:
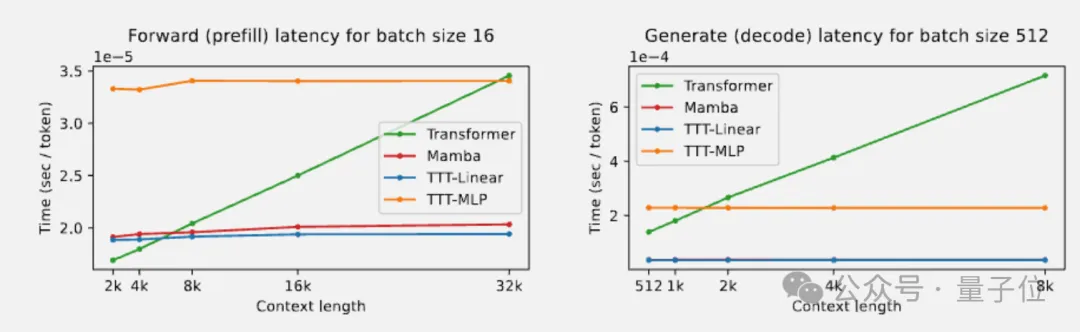
在A100上测试速度,TTT-Linear在预填充阶段比Mamba稍快,解码阶段几乎与Mamba速度相同。TTT-MLP相比Transformer整体上也有线性复杂度的优势。
共同一作Karan Dala表示:我一直被问到的一个问题是,我们是否相信TTT就是“Transformer杀手”,我仍然认为我们需要继续努力。
隐藏状态可以是任意模型,但目前的研究只涉及了线性模型和小型MLP,更复杂的还有待研究。
隐藏状态模型的学习可以用Adam代替普通的梯度下降等等。
三位共同一作中:
Yu Sun博士毕业于UC Berkeley,目前是斯坦福大学博士后。
Xinhao Li是电子科技大学校友,硕士毕业于UCSD。

Karan Dalel本科毕业于UC Berkley,正在机器人初创公司1X实习。
最后,联合指导UCSD助理教授王小龙还透露,TTT方法除了语言模型,还适用于视频。
TTT是否就是“Transformer杀手”,我仍然认为我们需要继续努力。
将来在对长视频进行建模时,我们可以密集地采样帧而不是采样1 FPS,这些密集帧对Transformer来说是一种负担,但对TTT层来说是一种福音。

论文地址:
https://arxiv.org/abs/2407.04620
参考链接:
[1]https://x.com/karansdalal/status/1810338845659131940
[2]https://x.com/xiaolonw/status/1810387662060269668
文章来自于微信公众号“量子位”,作者 “梦晨”




【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
