# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
OpenAI,也开始进军小模型了。
就在今天深夜,GPT-3.5退场,全新发布的GPT-4o mini,更小、性能更强,更重要的是——更便宜!

GPT-3.5,再见!
每百万个输入token 15美分,每百万个输出token 60美分,MMLU得分82%,性能超快。
CEO Sam Altman感慨道:通往智能的成本,竟是如此低廉。

是的,如火如荼的大模型价格战,OpenAI也入场了。
Altman回顾说:就在2022年,世界上最好的模型是还是text-davinci-003(GPT-3的版本)。
但如今,与这个新模型相比,text-davinci-003差得太多太多。甚至,价格要高出100倍。

相较于GPT-3.5,GPT-4o mini性能更强,价格还要便宜60%以上,成本直线下降。

大模型的成本,两年间下降了99%,等再过几年呢?简直不敢想。

以前,用OpenAI模型构建应用程序可能会产生巨额费用,没有能力对其修改的开发者,极有可能放弃它,转投更便宜的模型,比如谷歌的Gemini 1.5 Flash或者Anthropic的Claude 3 Haiku。
如今OpenAI终于等不住,出手了。
现在,所有人都可以在ChatGPT中用上GPT-4o mini了。

小模型,但对标GPT-4 Turbo
GPT-4o mini的知识更新到去年10月,语言种类和GPT-4o对齐,上下文窗口为128k。
目前在API中仅支持文本和视觉模态,未来还将扩展到视频和音频的输入/输出。
虽然没有披露参数规模,但OpenAI的官博文章表示,这是他们目前最经济、最有成本效益的小模型,微调功能也将很快上线。
神奇的是,GPT-4o mini在LMSYS排行榜上聊天偏好方面的表现甚至优于GPT-4。在总榜上,排名可以和GPT-4 Turbo匹敌。
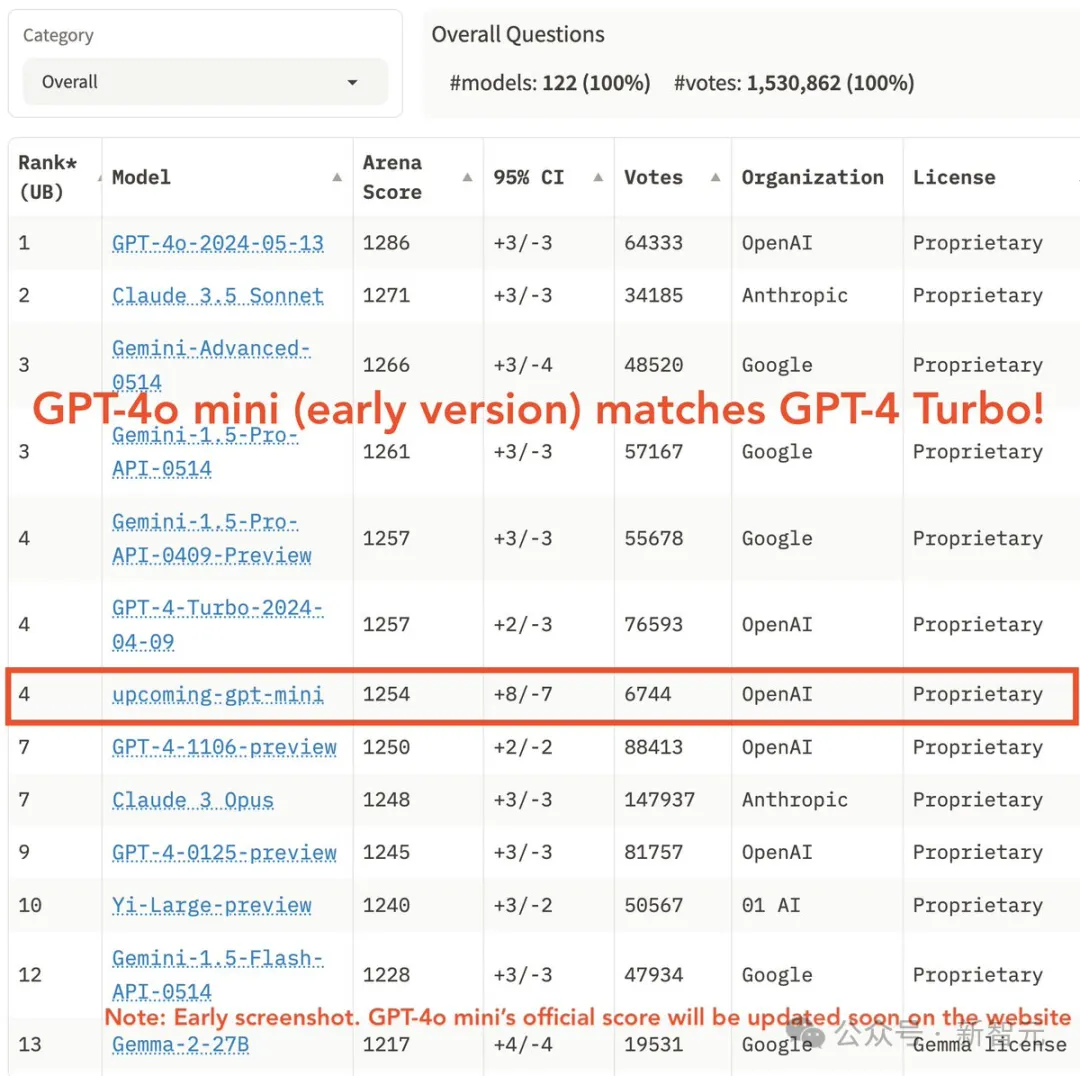
上周模型还没发布,就已经有超过6000名用户投票给早期版本「upcoming-gpt-mini」,但目前该模型的结果已经被撤下。
LMSYS在推特上宣布,正在重新收集投票,很快就会发布正式版模型的成绩。

GPT0-4o mini的发布,显然将大幅扩展AI应用的范围。
它不仅低成本、低延迟,还支持广泛的任务,比如链式或并行调用多个模型的应用(调用多个 API),向模型传递大量上下文(完整代码库或对话历史),或通过快速、实时的文本响应与客户互动(支持聊天机器人)。
并且,由于与GPT-4o共享改进的分词器(tokenizer),它处理起非英语文本会更加经济高效。
目前,GPT-4o mini在API中支持文本和视觉,未来还将支持多模态功能,包括文本、图像、视频和音频的输入和输出。
听起来,它像是功能更强大的虚拟助理,比如了解我们的旅行行程并给出建议。
在文本智能和多模态推理方面,GPT-4o mini已经超越了GPT-3.5 Turbo和其他小模型,GPT-4o支持的语言它也都支持。
长上下文处理性能上,它比起GPT-3.5 Turbo也有所改进。
在函数调用上,GPT-4o mini同样表现出色,因此开发者可以更方便地构建应用。
看一下GPT-4o mini的关键基准测试成绩。

推理任务
文本和视觉推理任务上,GPT-4o优于其他小模型。
在MMLU上,它的得分为82.0%,而Gemini Flash为77.9%,Claude Haiku为73.8%。
数学和编码能力
在数学推理和编码任务中,GPT-4o同样表现出色,优于市场上的小模型。
在MGSM上,在MGSM上,GPT-4o mini得分为87.0%,而Gemini Flash为75.5%,Claude Haiku为71.7%。
在HumanEval上,GPT-4o mini得分为87.2%,而Gemini Flash为71.5%,Claude Haiku为75.9%。
多模态推理
GPT-4o mini在MMMU上也表现强劲,得分为59.4%,而Gemini Flash为56.1%,Claude Haiku为 50.2%。

实测表明,无论是从收据文件中提取结构化数据,还是根据邮件线程生成高质量回复,GPT-4o mini在这类任务上的表现都明显比GPT-3.5 Turbo更好。
这也印证了业界一直在讨论的观点:模型的大小,并不重要。

性价比极高
在性价比方面,Artificial Analysis已经为我们整理出了详细的分析。
GPT-4o mini的定价为:输入每1M token 15美分,输出每1M token 60美分。
1M token什么概念?大致相当于2500页书。
这个价格已经卷到了头部模型的最低档,仅次于Llama 3 8B。
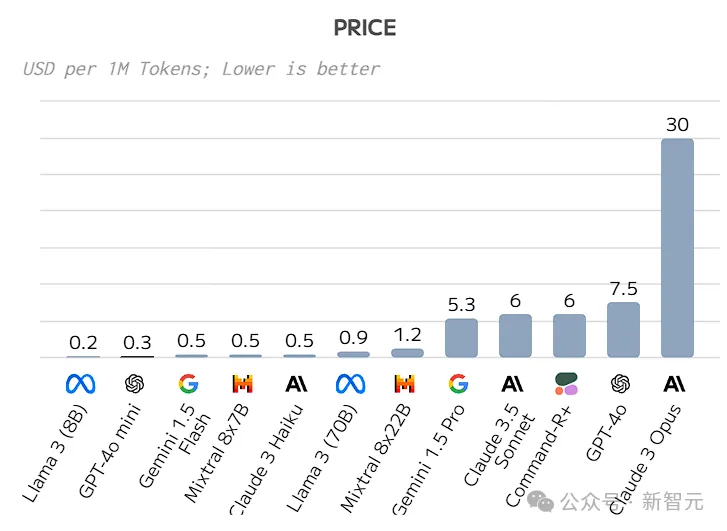
从下表中可以看到,在目前头部厂商发布的所有小模型中,GPT-4o mini超越Gemini 1.5 Flash、Llama 3 8B、Mistral 7B等众多竞品,成为性价比之最。
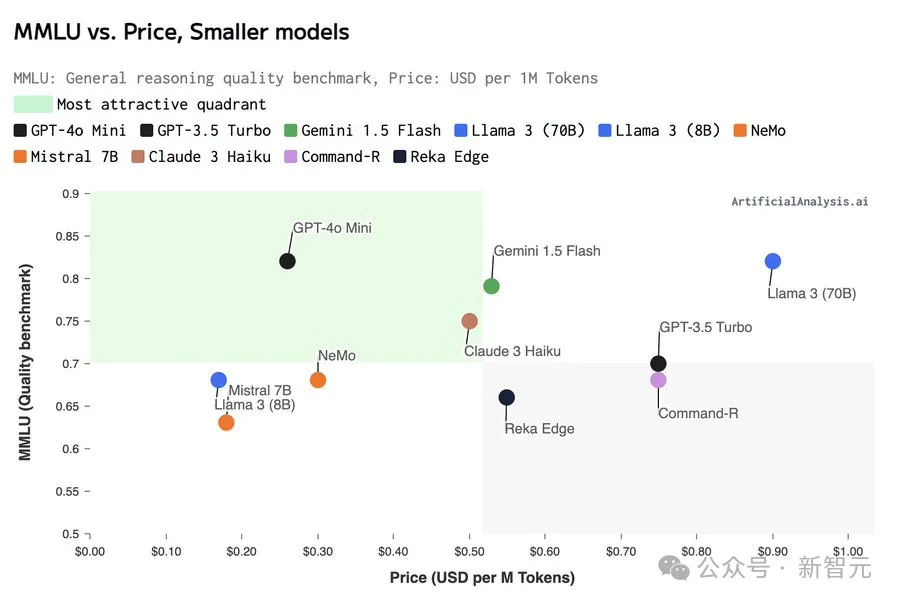
越靠近左上的模型,性价比越高
不仅是性价比最好,GPT-4o mini在输出的速度和质量上也实现了目前SOTA水平的优化权衡,甚至比GPT-4o更佳。

将质量和生成速度分开来看,效果依旧能打。
Artificial Analysis上的质量指数代表Chatbot、MMLU和MT-Bench等基准的归一化平均性能。
GPT-4o mini得分为85,和Gemini 1.5 Flash、Llama 3 70B基本处于同一水平,胜过Mixtral系列的8×22B和8×7B型号。

MMLU的得分也基本与质量指数一致,但比较亮眼的是在HumanEval编码任务上的评分。
87.2分的成绩,超过了谷歌系最强模型Gemini 1.5 Pro!

推理效率方面,183 token/s的生成让GPT-4o mini成为这个榜单上的绝对王者,相比第二名Gemini 1.5 Flash还要快18 token/s。
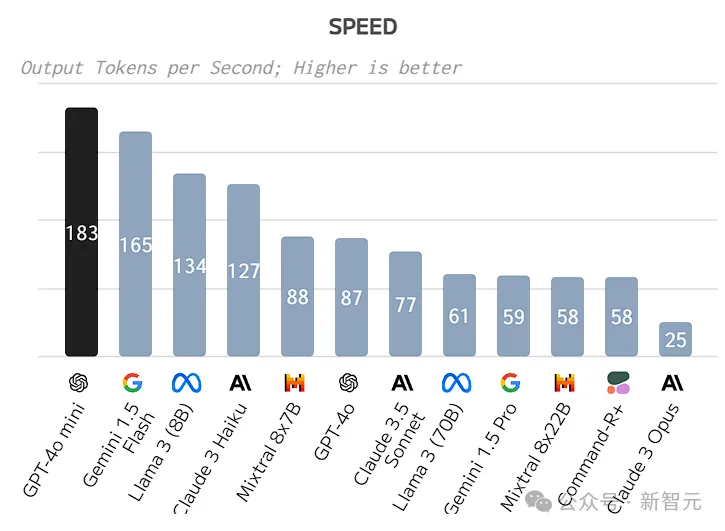
除了生成速度,目前API的响应延迟(TTFT)也算优秀,虽然没打过Phi-3、Llama 3 7B等小模型,但差距也不算太大。
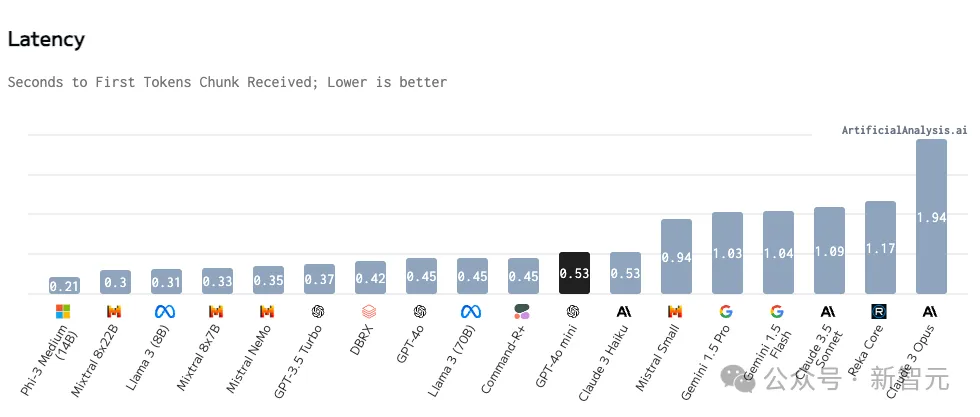
在响应延迟和token生成速度上,GPT-4o mini都有非常优秀的成绩,但需要注意的是,这两个指标与推理所用的硬件规格高度相关,而且模型仅开放API,并没有第三方进行部署后的测评。
模型发布之后,GPT-4o mini能否始终保持这样的高效率推理,更值得期待。
除了生成质量和推理效率,GPT-4o mini在上下文长度方面算是中规中矩,毕竟GPT-4o也才128k,没法和最长1M的Gemini系列抗衡。

「真正实现OpenAI使命」
「我认为GPT-4o mini真正实现了OpenAI的使命——让人们更广泛地接触AI。如果我们希望AI惠及世界每个角落、每个行业、每个应用程序,我们就必须让AI变得更便宜。」API平台产品负责人Olivier Godement这样介绍。
使用Free、Plus、Team套餐的ChatGPT用户,现在都可以使用GPT-4o mini了,企业用户也可以在下周获得访问权限。
对于ChatGPT用户,GPT-3.5已经消失,但开发者仍能通过API调用GPT-3.5。
不过,GPT-3.5也将在某一时间从API中退役,但具体时间点还不确定。

对于渴望低成本构建应用的开发者来说,GPT-4o mini来得太及时了。
金融初创公司Ramp在测试中,用它构建了提取收据上费用的工具,不必费力浏览文本框,模型就会自动对所有内容排序。
显然,OpenAI不想再让开发者流失到更便宜的Claude 3 Haiku和Gemini 1.5 Flash。
但是,OpenAI为什么花了这么久?
Godement表示,这涉及到一个「优先考虑」的问题。
此前OpenAI专注于GPT-4这样的大模型,而随着时间的推移,OpenAI终于注意到了开发者们渴望对小模型的愿景,才终于决定投入资源。
OpenAI非常有信心,GPT-4o mini一定会非常受欢迎。
网友:LLM变小,竞争加剧
Sclaing Law要卷,小模型也要卷。
一大早,不仅OpenAI放出了GPT-4o mini,另一边Mistral联手英伟达推出12B小模型Nemo,性能赶超Gema和Llama-3 8B。
Karpathy对此表示,「大模型的参数规模竞争正在加剧……但方向是相反的」!

他预测,我们将会看到非常小,但「思考」得非常好且可靠的模型。通过调整GPT-2参数,很可能存在一种特定的设置方式,因此GPT-2可能会表现的更好,以至于让大多数人认为它很聪明。
当前LLM如此庞大的原因是,我们在训练过程中非常浪费——我们要求它们记住整个互联网,令人惊讶的是,它们确实做到了,比如可以背诵常见数字的SHA哈希值,或者回忆起非常冷僻的事实。(实际上,大模型在记忆方面非常出色,质量上远胜于人类,有时只需要一次更新就能记住大量细节并保持很长时间)。
但是,想象一下,如果你要在闭卷考试中,根据前几句话背诵互联网上的任意段落。这是今天模型的标准(预)训练目标。做得更好的难点在于,在训练数据中,思考的展示与知识「交织」在一起的。因此,模型必须先变大,然后才能变小,因为我们需要它们(自动化)的帮助,将训练数据重构并塑造成理想的合成格式。
这是一个阶梯式的改进过程——一个模型帮助生成下一个模型的训练数据,直到我们拥有「完美的训练集」。当你用它训练GPT-2时,它将成为今天标准下非常强大/聪明的模型。也许MMLU会稍微低一些,因为它不能完美地记住所有的化学知识。也许它需要偶尔查阅一些东西以确保准确。
HuggingFace创始人表示,「这个星期是小模型的一周」。

OpenAI研究员Hyung Won Chung表示,「虽然我们比任何人都更喜欢训练大模型,但OpenAI也知道如何训练小模型」。

网友对当前地表最强模型的价格进行了汇总:


作为参考,如果你想对美国24小时内所说或所听到的每一个单词进行推理,仅需要花费不到20万美元。


不过,最近比较火的陷阱题——9.11和9.9究竟谁大,进化后的GPT-4o mini依然失败了。

几天前,刚完成进化后的AutoGPT,也可以正式支持GPT-4o mini。


Altman本人在评论区中,预告了GPT-4o语音功能Alpha版本将在本月末上线。

当然,所有人还是更期待GPT-5上线。


在OpenAI设想的未来里,模型将会被无缝集成到每一个应用程序和每一个网站之上。
如今,随着GPT-4o mini的推出,为开发者更高效、更经济地构建和扩展强大的AI应用铺平道路。
可以看到,AI正在变得更容易访问、可靠,并会融入到所有人的日常体验中。
而OpenAI,会继续引领这一进程。
作者介绍
GPT-4o的作者名单,也是长到让人印象深刻。
其中,项目负责人是Mianna Chen。

Mianna Chen曾在普林斯顿大学取得了学士学位。2020年,她获得了宾夕法尼亚大学沃顿商学院MBA学位。

入职OpenAI之前,她在2015年加入谷歌任职近3年,中间还跳槽至一家初创Two Sigma,随后再次入职DeepMind任职1年多产品主管。

其他负责人为Jacob Menick,Kevin Lu,Shengjia Zhao,Eric Wallace,Hongyu Ren,Haitang Hu,Nick Stathas,Felipe Petroski Such。
Kevin Lu

Kevin Lu获得了加州大学伯克利分校电子工程和计算机科学学士学位,曾与Pieter Abbeel和Igor Mordatch合作研究强化学习和序列建模。

在校期间,他还担任过助教,在伯克利人工智能研究院担任本科研究员。

目前,他已入职OpenAI,成为了一名研究员。
Shengjia Zhao

Shengjia Zhao是斯坦福大学计算机科学系的博士,本科毕业于清华大学。

获得博士学位后,Shengjia Zhao直接加入了OpenAI,担任技术研究员,至今已有2年多的时间。
目前,他主要从事大语言模型的训练和对齐工作,负责ChatGPT的研究。
Haitang Hu

Haitang Hu在霍普金斯约翰大学取得了计算机硕士学位,此前还在同济大学获得了计算机科学和技术学士学位。

本科毕业后,他加入了NS Solution公司,任职3年系统工程师。随后,进入霍普金斯约翰大学继续攻读。
2016年取得硕士学位后,Haitang Hu入职谷歌,就职7年工程师。直到23年9月,他正式加入了OpenAI。

文章来源于“新智元”,作者“新智元”



【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
