# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
01.
AI视频“开源先锋”
从 AnimateDiff 开始
SENSEAI: 请戴老师介绍一下自己和主要的研究方向吧!
戴老师:我 2014 年从上海交大 ACM 班毕业后去了香港中文大学 MMLab,学习和研究的方向一直是 AIGC 相关,今年正好是我在 AIGC 这个研究领域的第十年。
在这一波生成式AI火爆之前,好几年前就开始研究多模态图像到语言描述的生成、场景图像的生成,接着往高质量动作的视频理解探索,2020 年首次将生成式先验引入了图像修复和编辑领域,再到 2022 年我们首次把神经辐射场(NeRF)做到了城市级别的重建和渲染。
去年我们的工作在文生动画、3D、动作等方向也都取得了比较全面的进展,其中 AnimateDiff 大家可能更熟悉一些。AIGC的研究方向一部分是要尽可能的把三维动态内容的重建和生成做好,在我看来 Build World Simulator 当前的关键是也是Real To Sim。
SENSEAI: 为什么 Animatediff 可以广泛应用,您是怎么思考技术和应用的结合?
戴老师:AnimateDiff 算是已经被证明的一次往产品应用上的尝试,几家头部大厂也在用它的权重去微调。最近在 GitHub 上应该接近上万 star 数,Civitai 上的下载量也有近 8 万次了。
AnimateDiff 更像是一个插件,可以与工作流中不同的部分比较好的耦合,所以它是源源不断的在创造新的形态。一年多前文生图社区火爆起来,从文生图到把图片动起来的用户需求也就呼之欲出了。所以我们开源了 AnimateDiff,用户无需特定调整就可以完成个性化文本到视频动画的制作。
从去年 7 月到 12 月发了三个版本,在 Fidelity (保真度)和 Controllability(可控性)上对模型进行了迭代。其实相关的工作还在继续,但得到更多的行业真实需求反馈后,对单纯文生视频的局限性有了比较清醒的认识,所以是一直在尝试其他的一些办法。

AnimateDiff的出圈实例
SENSEAI: 视频生成是非常火热的主题,您认为技术路径收敛还要解决哪些问题,如何理解视频生成的技术路线和技术局限?
戴老师:首先,我相信文生视频、包括最近也比较火的文生3D在巨大的关注下一定还会取得不错的进展,但是在多长时间内、多大程度上能满足用户或者行业的需求,我觉得还是要理性看待。
“可控性”是当前受到关注的焦点。语言文本的表达力是很有限的,设计更好的多模态人机交互的方式就很关键。
通过无比详细的文本提示词和不断 scale up 的视频模型,把原本视频里的各种细节都囫囵个生成出来应该不是一个好方式。我会认为这个世界上的场景、人、物本就不是粘连在一起的,有相对独立的结构和特性,更何况还要这一切符合物理规律。
OpenAI在报告里称“Scaling video generation models is a promising path towards building general purpose simulators of the physical world.” 其实 World Simulator 才是需要深入思考和提前布局的事情。
SENSEAI:后续在视频生成上,您有怎样的期待和研究兴趣,视频生成的交互和应用您如何畅想,您怎么理解视频生成对自动驾驶和具身机器人的价值?
戴老师:虽然现在文生视频很火,也没必要去按照简单粗暴的方式去follow。AnimateDiff 只是我们工作的一部分。
从世界模拟的层面来说,环境、人和物理规律是缺一不可的,所以在过去的几年我们一直在做相应的工作。比如在场景环境方向,我们通过NeRF和Scaffold-GS把城市级实景三维重建做到了极高的训练和渲染效率(书生·天际 LandMark),在人物和物理规律结合方向上,我们做了Controllable Motion Diffusion Model、Pedestrian Animation Controller in Driving Scenarios等物理感知交互(Physics-aware Interaction)相关的工作,同时通过与LLM结合等方式向更复杂的自然动态与仿真去做研究和工程尝试。我们跟CMU、Nvidia、Stanford等一些顶尖的团队,包括一些做自动驾驶、机器人相关的团队在研究上也一直有深入的探索。但我们自己暂时还不想一步踏到具身智能中去。
SENSEAI: 您的研究里,有视频生成,有3D生成,有世界模拟,能讲讲这背后的思路和终极目标吗?
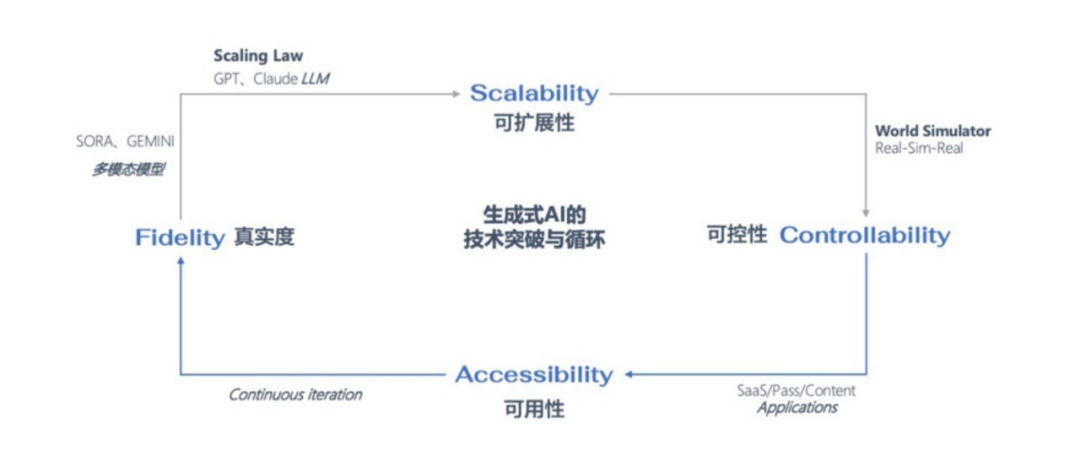
戴老师:其实我做研究的底层逻辑上,一直非常注重科学规律的指导,我们认为生成式AI的技术迭代与突破实际上是遵循 Fidelity-Scalability-Controllability-Accessibility (真实度-可扩展性-可控性-可用性)这样的一个循环。
所以近一年的时间一直在想办法解决“可控”和“可用”的问题,无论是用户操作上的还是成本层面的。无论是视频和3D生成,还是通过 Build World Simulator,都是为了更好的进行理解和仿真,利用 Real To Sim 与 Sim To Real 共同构建整个虚实结合的闭环。
Fidelity-Scalability-Controllability-Accessibility
SENSEAI: 在您眼中,生成式AI有怎样的特性和模式,transformer 和 scaling 是不是这一代技术的终极解法?
戴老师:就像我前边讲的,Fidelity-Scalability-Controllability-Accessibility这样的一个循环的科学规律,和我们在实际研究和应用中需要攻克的问题,构成了一个螺旋上升的形态,会经历多次的循环和迭代。
文本和语言只是多种模态中基础的一部份,很难说因为今天文本相关的 Chat 解决的不错了,就意味着生成式 AI 的技术路径和需要解决的问题就大致如此了。我们所看到的问题也许只是冰山一角,所以还是可以多一些耐心。Transformer当然是非常棒的突破,充分的利用好一定是可以加速很多的工作。
至于Scaling Law,如果我现在有十万张卡我愿意试一试,但我们经常会说“没有也行”,办法总比困难多嘛。在一部分恰当的步骤中利用好 Scaling Law 是比较理性的做法。
02.
Real to Sim
可能被低估了
SENSEAI:在具身智能领域,Sim to Real 是非常常见的,但您同时强调了 Real to Sim 的重要性,这套循环是怎么相互作用的?
戴老师:很显然只关注Sim To Real还不够。最近随着具身智能的火热,越来越多的人在讨论仿真,仿真使得我们可以在虚拟环境中模拟人类期望在现实环境中进行的动作和行为,并将这个过程中获取的数据、知识或者模型直接部署或使用到现实的应用和设备上,从而摆脱现实环境的种种限制,如安全性、隐私、事件发生频率、成本、时间周期等问题。
那么实现仿真的关键,是先将虚拟环境和现实环境从形象、结构和功能上完成对齐,这几乎是一个当前很难回避的问题。更为强大的Real To Sim能力,能从根源上解决 Sim To Real Gap 和诸多由此而来的瓶颈。但反过来讲,目前所能实现的 Real To Sim 也还没有那么理想,在有 Gap 的前提下如何更好的将在虚拟环境中获取的数据、知识或者模型利用起来就很关键。
Real To Sim 与 Sim To Real 共同构建了整个虚实结合的闭环,所以我们希望可以真正做到 Real to Sim to Real。由于虚拟环境和现实环境一样,是三维和动态的,Real To Sim的能力,对应的正是生成式AI中的三维及动态内容的重建及生成技术。
SENSEAI:Simulator上,英伟达有着非常大的生态优势,在您看来这个环节的重要性有多大,未来的发展趋势如何,有哪些技术可以更好的推进 simulator 的进展?
戴老师:这个问题非常好,英伟达拥有的更多是生态优势,同时 Omniverse 配备了非常强大的研究力量。在核心技术层面,我们也有一些我们的优势和侧重点,比如在 Real To Sim 和人物自然动态的仿真上。
英伟达希望通过丰富的算力资源+仿真平台的组合把大家都先集聚起来,但是最后一公里的问题依旧需要投入开发者,所以某种意义上大家应该是可以利用好Omniverse 和 Isaac 等平台去做出更加 Native 的应用。
此外,我们还可以反向思考一下,是不是如果用更优的模型+更少的算力消耗可以改变这一局面。我们近期有成果表明,的确是有办法在一些工作上实现计算资源指数级的调整。
03.
有关世界模拟和
3D内容生成的未来
SENSEAI:Sora 团队认为视频模型就是 world simulator 了,从笛卡尔的认知论角度,世界其实是我们感应器官映射后的解释,无法真的代表真实世界;那么视频模型是否可以超越我们感官颗粒度,眼见为真即为真呢?和数学驱动的世界模型,未来是取代还是共存呢?
戴老师:OpenAI 在报告里称 “Scaling video generation models is a promising path towards building general purpose simulators of the physical world.”这当中有几个问题,首先 Scaling 视频生成模型要 Scaling 到什么程度,其次这里的 视频生成模型是不是等同于今天我们看到的产品Sora。
我还是认为视频生成只是构建世界模拟的一种路径,可以看成是有益的一部份,但很难说他就是 World Simulator 或者 World Model。
SENSEAI:世界模型的意义是什么,都有哪些关键的要素,LeCun说的世界模型,李飞飞创业的空间智能,有怎样的异同?
戴老师:我们前边所说的 Real To Sim 的技术和其构建的数字世界,其实跟这些概念都有本质的联系。世界模型(World Model),几乎是一个非常大而全的概念。虽然大家对这个概念的定义不同,但大部分人描述的,正是Real To Sim所构建的虚拟世界。
世界仿真器(World Simulator),与世界模型相比,更强调仿真的结果,而非仿真的路径。所以大家也会认为视频生成可以作为世界仿真器,或者换句话说仿真不一定需要通过与现实对齐的三维、动态虚拟环境。但不同的仿真路径,在效率、效果、鲁棒性等方面可能存在天壤之别。
空间智能(Spatial Intelligence),更强调在 Real To Sim 构建的虚拟环境中通过仿真获取到的知识,实现感知、理解和交互能力。其实概念没那么重要,我们提前布局的和想做的方向现在逐步已经成为共识了,但在没有这个概念之前也并没有影响我们一直在做。
SENSEAI:我们看到 Luma、Viggle 都有基于 3D guidance 的视频生成,怎么看待3D和视频生成的关系?
戴老师:目前大家看到的一些所谓基于3D Guidance的视频生成,我不太好做过多的评判,还是以真实的效果为准。
Luma、Sora等视频生成的思路还是视频为主3D为辅,我个人觉得应该是3D为主视频为辅,更符合真正可控可用的Real To Sim的逻辑。
真实世界本来就是三维的,其实大家想在 Simulator 里完成的操作也都是3D的,比如视频的镜头转个角度、视频里移动一些元素等等操作其实细想都依赖背后的3D,Real To Sim 通过2D的视频来桥接,是不是真的必要,还是说只是因为当前阶段急需用视频来证明潜力,都值得深思。
SENSEAI:您的研究 3D 粒子系统能否讲一讲,未来可能对哪些领域有帮助,微观向宏观的指导和映射能有怎样的延展?
戴老师:您前期准备工作还挺细致的哈哈。前年的时候我们发过一篇Transformer with Implicit Edges for Particle-based Physics Simulation 的工作,最近我们也跟一些产业界的朋友在聊,发现大家都觉得这个非常重要。
这个工作的核心是探索AI在微观层面细致、复杂的物理模拟上的潜力。因为一个是因为这种微观的物理模拟背后涉及的流体力学、空气动力学本来就是物理学的重要内容,另外它也和我们的日常生活息息相关,无论是自然界中的风霜雨雪还是水,还是我们穿的衣服的柔性材料,物体爆炸产生的粒子反应等等。
从宏观的三维几何深入到微观的粒子间相互作用,AI就有机会帮助解决更多科学问题,因为很多宏观上看起来完全不相关的现象,在微观上是相似的。
SENSEAI:在您看来,3D生成的应用,需要像 visionpro 这样的空间计算和交互硬件的普及吗?或者还可能有怎样的应用?
戴老师:当然需要,未来空间计算和交互硬件的普及也许会创造全新的真实世界与数字世界的交互方式。VisionPro 发售后我第一时间买了一个,我们把自己重建和生成的一些内容已经在往这些设备上去做适配和交互。
对于终端设备大家可以有更多的耐心,同时终端的加速迭代离不开内容生态的繁荣,所以利用 AIGC 的能力把 3D 动态内容做到更高质量、更可控、更低成本是眼前更需要踏实去做的事情。
SENSEAI:可以再和大家分享一下三维动态内容的重建的研究进展吗,这部分对哪些领域的学术或者产业推动具有重要意义?我们的创新/领先之处在哪?
戴老师:三维和动态内容的重建与生成,这里边有三个关键词,三维、动态和重建与生成。三维应该比较好理解,只有在三维空间中的信息理解才能实现空间和物理的统一;强调动态,是因为只有动态的人与环境、人与物、人与人的交互被更好的呈现才能还原真实世界中的感知理解和行动规划;重建和生成,如果我们有办法无差别地将各种要素重建出来,那么生成的效果也就更有参考和依据,这也是为什么即便生成赛道这么火的同时, NeRF和高斯等相关的研究依旧被学术界和工业界十分重视。
我们算是有一些不错的进展,基本的思路还是把Real to Sim to Real中的难点解耦,场景、人、物理,把每一个部分都争取做到比较好或者说是可控和可用的水平,接下来我们就有机会再把这些部分耦合起来。
所以遵循这样的思路,首先是两年前就开始做场景的重建。通过大规模场景重建技术,为虚拟环境提供逼真的场景,比如采用全新的 Scaffold-GS 算法,可以达到既具备 3D Gaussian Splatting 的高性能渲染效率,也融合了多种经典 NeRF 表征的灵活性和高质量。这部分应该是在全球处于非常领先的水平了。在更高质量的同时,我们还往前多做了一些工作,通过对模型、系统、算子的升级,把所需的计算资源从原先的GPU降到了单张消费级显卡。
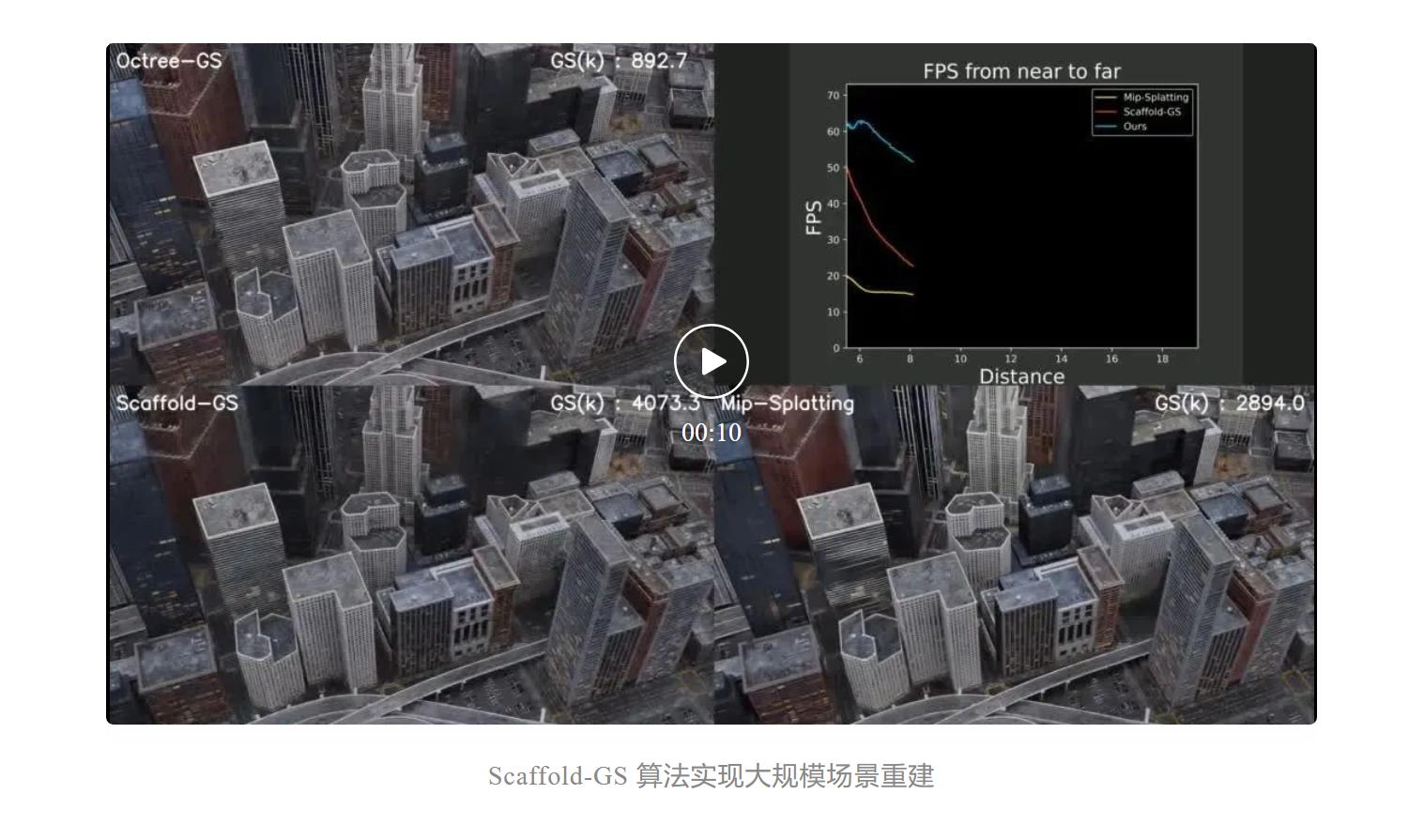
重建达到比较高的水平的同时,我们把生成的水平也提上来,所以也花了一点时间做了一些可交互的场景空间生成,从结构上向现实靠拢。几何和材质、光线等又是需要花精力认真攻克的部分,完全 Realistic 的生成还有更多研究需要做。

可控、物理可信的人体自然动态生成也是非常重要的一部分,可以为引入到虚拟环境中的真人,提供自然、实时的人体动态仿真、环境与人的交互仿真,以及多人交互仿真等能力。


当我们将这些技术组合到一起,环境、人和物理仿真,我们其实就具备了 Rea l to Sim 的可行性,并在此基础之上完成 Real to Sim to Real 的闭环。正如我前边说的,实现高保真的 Real to Sim to Real 要比我们理论推演的或者想象的难的多。
我们最近做了一个尝试,遇到了很多具体的具有挑战性的问题,包括研究和工程上的。大概目标是在一个逼真的虚拟户外场景中,尝试把人物角色耦合进去,并希望实现人物角色自发的、或通过各项指令,完成自然、多样的行为。现在做出来的 Demo 我们觉得只有二三十分的状态,但是定位到了很多值得攻克的问题,对我们来说很有意义。

SENSEAI:您想象中的终极模型是怎样的,会有怎样的性能和可能的商业价值,现有研究中有哪些已经可以进行商业应用
戴老师:想象中的终极模型未必是一个大模型,无论是一个模型还是一套系统,本质目标是要成本和可用性上都达到可控,这就需要在设计模型和考虑工程可行性的时候充分考虑产业的真实需求和想法。
结合 Nvidia 和 Meta 等在做的事情,把数字化内容做好是当前比较清晰的一个方向,真正的将3D、物理、动态通过多模态控制的方式设计好,这当中可能会涉及比较多的工程问题要解决。数字内容的生成能做好,我们就有机会向数字世界的模拟去靠近,从而实现数字世界向真实世界的映射,更好的与真实世界产生互动。无论是机器人、自动驾驶,还是更加偏向工业领域的产业落地都会被加速。
文章来源于“深思 SenseAI”,作者“ SenseAI”




【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
