# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
百模大战,最备受期待的一位选手,终于正式亮相!
它便是来自李开复博士创办的AI 2.0公司零一万物的首款开源大模型——Yi系列大模型:
Yi-34B和Yi-6B。
虽然Yi系列大模型出道时间相对较晚,但从效果上来看,绝对称得上是后发制人。
一出手即问鼎多项全球第一:
值得注意的是,零一万物及其大模型并非是一蹴而就,而是酝酿了足足半年有余。
由此不免让人产生诸多疑问:
例如为什么要憋半年之久的大招,选择在临近岁末之际出手?
再如是如何做到一面世即能拿下如此之多的第一?
带着这些问题,我们与零一万物做了独家交流,现在就来一一揭秘。
具体来看,零一万物最新发布开源的Yi系列大模型主要有两大亮点:
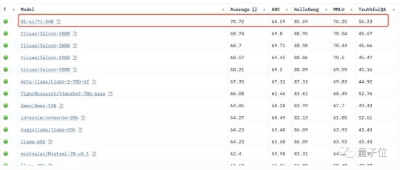
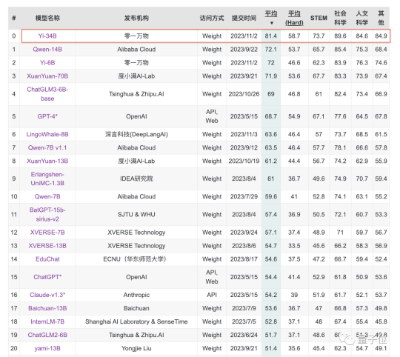
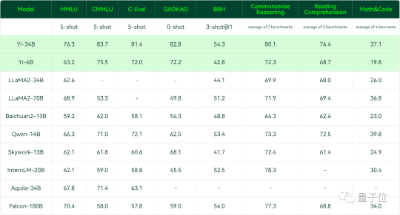
在Hugging Face英文测试公开单 Pretrained 预训练开源模型排名中,Yi-34B以70.72分数位列全球第一,超过了LLaMA-70B和Falcon-180B。
要知道,Yi-34B的参数量仅为后两者的1/2、1/5。不仅“以小博大”问鼎榜单,而且实现了跨数量级的反超,以百亿规模击败千亿级大模型。
其中在MMLU(大规模多任务语言理解)、TruthfulQA(真实性基准)两项指标中,Yi-34B都大幅超越其他大模型。
Hugging Face Open LLM Leaderboard (pretrained) 大模型排行榜,Yi-34B高居榜首(2023年11月5日)
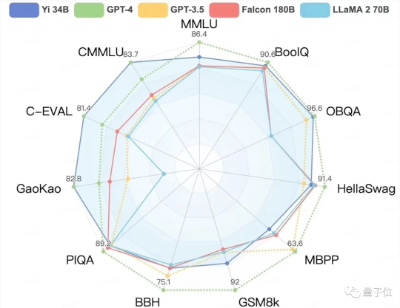
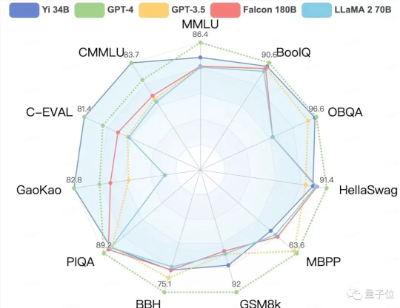
聚焦到中文能力方面,Yi-34B在C-Eval中文能力能力排行榜上超越所有开源模型。
同样开源的Yi-6B也超过了同规模所有开源模型。
在CMMLU、E-Eval、Gaokao三个主要中文指标上,明显领先于GPT-4,彰显强大的中文优势,对咱们更知根知底。
在BooIQ、OBQA两个问答指标上,和GPT-4水平相当。
另外,在大模型最关键评测指标MMLU(Massive Multitask Language Understanding,大规模多任务语言理解)、BBH等反映模型综合能力的评测集上,Yi-34B在通用能力、知识推理、阅读理解等多项指标评比中全面超越,与Hugging Face评测高度一致。
各评测集得分:Yi 模型 v.s. 其他开源模型
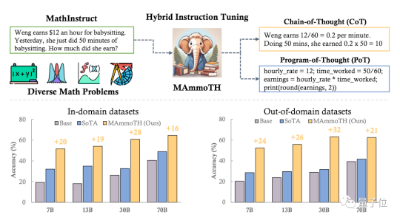
不过在发布中零一万物也表示,Yi系列模型在GSM8k、MBPP的数学和代码测评中表现还不及GPT模型。
这是因为团队希望在预训练阶段先尽可能保留模型的通用能力,所以训练数据中没有加入过多数学和代码数据。
目前团队正在针对数学方向展开研究,提出了可以解决一般数学问题的大模型MammoTH,利用CoT和PoT解决数学问题,在各个规模版本、内外部测试集上均优于SOTA模型。其中MammoTH-34B在MATH上的准确率达到44%,超过了GPT-4的CoT结果。
后续Yi系列也将推出专长代码和数学的继续训练模型。
而除了亮眼的刷榜成绩外,Yi-34B还将大模型上下文窗口长度刷新到了200K,可处理约40万汉字超长文本输入。
这相当于能一次处理两本《三体 1》小说、理解超过1000页的PDF文档,甚至能替代很多依赖于向量数据库构建外部知识库的场景。
超长上下文窗口是体现大模型实力的一个重要维度,拥有更长的上下文窗口则能处理更丰富的知识库信息,生成更连贯、准确的文本,也能支持大模型更好处理文档摘要/问答等任务。
要知道,目前大模型的诸多垂直行业应用中(如金融、法律、财务等),文档处理能力是刚需。
如GPT-4可支持32K、约2.5万汉字,Claude 2可支持100K、约20万字。
零一万物不仅刷新了业界纪录,同时也是首家将超长上下文窗口在开源社区开放的大模型公司。
所以,Yi系列是如何炼成的?
零一万物表示,Yi系列炼成的秘诀来自两方面:
如上二者结合,能让大模型训练过程更加高效、准确、自动化。在多模混战的当下,节省宝贵的时间、计算、人力成本。
它们是Yi系列大模型为何会“慢”的原因之一,但也因为有了它们,所以“慢即是快”。
首先来看模型训练部分。
这是大模型能力打基础的环节,训练数据质量和方法如何,直接关乎模型最终效果。
所以,零一万物自建了智能数据处理管线和规模化训练实验平台。
智能数据处理管线高效、自动、可评价、可扩展,团队由前Google大数据和知识图谱专家领衔。
“规模化训练实验平台”可以指导模型的设计和优化,提升模型训练效率、减少计算资源浪费。
基于这一平台,Yi-34B每个节点的预测误差都控制在0.5%以内,如数据配比、超参搜索、模型结构实验都可以在上面进行。
由此,与过往的“粗放炼丹”训练比较,Yi系列大模型的训练进阶到“训模科学”:变得更加细致、科学化,实验结果可以更加稳定,未来模型规模进一步扩大的速度也能更快。
再来看Infra部分。
AI Infra是指人工智能基础框架技术,它包含了大模型训练、部署方面的各种底层技术设施,包括处理器、操作系统、存储系统、网络基础设施、云计算平台等——是大模型领域绝对的硬技术。
如果说训练环节是为模型质量打地基,那么AI Infra则是为这一环节提供保障,让地基更加牢固,亦是直接关乎大模型底层的部分。
零一万物团队用了一个更加形象的比喻解释:
如果说大模型训练是登山,Infra的能力定义了大模型训练算法和模型的能力边界,也就是“登山高度”的天花板。
尤其在业内算力资源紧张的当下,如何更快、更稳地推进大模型研发,非常关键。
这就是为何零一万物如此重视Infra部分。
李开复也曾表示,做过大模型Infra的人,比作算法的人才还要稀缺。
而零一万物的Infra团队曾参与支持多个千亿级大模型规模化训练。
在他们的支持下,Yi-34B模型训练成本实测下降40%,模拟千亿规模训练成本可下降多达50%。实际训练完成达标时间域预测的时间误差不到1小时——要知道,一般业内都会预留几天时间作为误差。
团队表示,截至目前零一万物Infra能力实现故障预测准确率超过90%,故障提前发现率达到99.9%,无需人工参与的故障自愈率超过95%,能有力保障模型训练顺畅进行。
李开复透露,在完成Yi-34B预训练的同时,零一万物千亿级参数模型训练已正式启动。
而且暗示更大模型的面世速度,很可能超出大家预期:
零一万物的数据处理管线、算法研究、实验平台、GPU 资源和 AI Infra 都已经准备好,我们的动作会越来越快。
最后,我们来回答一下最开始我们提到的那几个问题。
零一万物之所以选择在年底搭乘“晚班车”入局,实则与它自身的目标息息相关。
正如李开复在此次发布中所述:
零一万物坚定进军全球第一梯队目标,从招的第一个人,写的第一行代码,设计的第一个模型开始,就一直抱着成为“World’s No.1”的初衷和决心。
而要做到第一,需是得能耐得住性子,潜心修炼扎实的功底,方可在出道之际做到一鸣惊人。
不仅如此,在零一万物成立之际,它的出发点便与其它大模型厂商有着本质的不同。
零一代表的是整个数字世界,从零到一,乃至宇宙万物,所谓道生一……生万物,寓意 “零一智能,万物赋能” 的雄心。
这也与李开复关于AI2.0的思考判断一以贯之,在ChatGPT带动大模型热潮之后,他就曾公开表示过:
以基座大模型为突破的AI 2.0时代,将掀起技术、平台到应用多个层面的革命。如同Windows带动了PC普及,Android催生了移动互联网的生态,AI2.0将诞生比移动互联网大十倍的平台机会,将把既有的软件、使用界面和应用重写一次,也将诞生新一批AI-first的应用,并催生由AI主导的商业模式。
理念就是AI-first,驱动力是技术愿景,背靠卓越的中国工程底蕴,突破点是基座大模型,覆盖范围包含技术、平台到应用多个层面。
为此,零一万物从成立以来选择的创业路线便是自研大模型。
虽说发布时间较晚,但在速度上绝对不算慢。
例如在头三个月的时间里,零一万物就已经实现了百亿参数规模的模型内测;而再时隔三个月,便可以用34B的参数规模解锁全球第一。
如此速度,如此高目标,定然也是离不开零一万物背后雄厚的团队实力。
零一万物由李开复博士亲自挂帅、任CEO。
在早期阶段,零一万物已经聚集起了数十名核心成员的团队,集中在大模型技术、人工智能算法、自然语言处理、系统架构、算力架构、数据安全、产品研发等领域。
其中已加入的联创团队成员包含前阿里巴巴副总裁、前百度副总裁、前谷歌中国高管、前微软/SAP/Cisco/副总裁,算法和产品团队背景均来自国内外大厂。
以算法和模型团队成员为例,有论文曾被GPT-4引用的算法大拿,有获得过微软内部研究大奖的优秀研究员,曾获得过阿里CEO特别奖的超级工程师。总计在ICLR、NeurIPS、CVPR、ICCV等知名学术会议上发表过大模型相关学术论文100余篇。
而且零一万物在成立之初便已经开始搭建实验平台,构建了个数千卡GPU集群,进行训练、调优和推理。在数据方面,主打一个提高有效参数量和使用的高质量数据密度。
由此,不难看出零一万物Yi系列大模型敢于后发制人的底气何在了。
据了解,零一万物接下来还将Yi系列大模型为基础,快速迭代开源更多量化的版本、对话模型、数学模型、代码模型和多模态模型等。
总而言之,随着零一万物这匹黑马的入局,百模大战已然变得更加激烈与热闹。
对于Yi系列大模型还将在未来颠覆多少“全球第一”,是值得期待一波了。
为什么取名“Yi” ?
命名来自“一”的拼音,“Yi”中的“Y”上下颠倒,巧妙形同汉字的 “人”,结合AI里的 i,代表 Human + AI。
零一万物相信 AI 赋能推动人类社会前行,AI 应本着以人为本的精神,为人类创造巨大的价值。
文章来自微信公众号 “ 量子位 ”,作者 金磊 明敏



【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI