# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
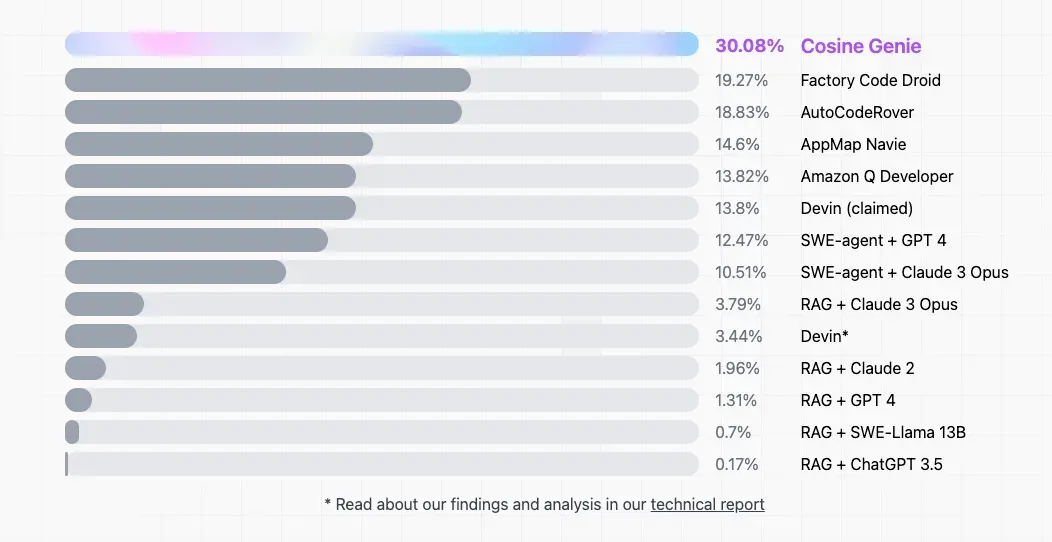
一直以来,大模型的编程能力都备受关注,超强 AI 程序员 Devin 的问世更是将「AI 能否替代程序员」这一话题推上了风口浪尖。最近,Devin 也迎来了新对手 —— 初创公司 Cosine 推出的自主 AI 程序
员 Genie。该公司表示,Genie 的表现轻松超越了 Devin,在第三方基准测试 SWE-bench 上的得分为 30%,而 Devin 的得分仅为 13.8%。
这个 SWE-Bench 是一个用于评估 LLM 解决 GitHub 上真实软件问题能力的基准测试数据集。它收集了来自 12 个流行的 Python 仓库的 2,294 个 Issue-Pull Request 对。在测试时,LLM 会拿到一个代
码库和 issue 描述,然后生成一个补丁来解决 issue 描述的问题。这个数据集在 AI 编程能力的评估中已被广泛使用。
在 AI 编程能力进化的同时,这个基准也在进化。今天凌晨,网传的 OpenAI「草莓」模型再次跳票,但 OpenAI 确实发布了新东西,就是 SWE-Bench 的改进版本 ——SWE-bench Verified。
OpenAI 指出,原始的 SWE-bench 存在一些问题,可能导致模型的自主软件工程能力被低估。因此,在改进过程中,他们与 SWE-Bench 原作者合作,进行了人工筛选和改进,确保单元测试的范围适
当且问题描述明确。
在 SWE-bench Verified 上进行的新测试中,很多 AI 编程智能体的得分都比原来要高。其中,UIUC 的无 Agent 方案 Agentless 甚至实现了得分翻倍,OpenAI 认为,这证明之前的基准确实存在低估 AI
编程能力的缺陷。
但对于蹲守「草莓」的全世界网友来说,这个发布还是过于敷衍了。有人说,「我们期待的是草莓,但他们发布的是羽衣甘蓝。」
SWE-bench 测试集中的每个示例都是根据 GitHub 上 12 个开源 Python 代码库中一个已解决的 GitHub issue 创建的。每个样本都有一个相关的拉取请求(PR),其中包括解决方案代码和用于验证代
码正确性的单元测试。这些单元测试被称为 FAIL_TO_PASS 测试,因为在 PR 中的解决方案代码添加之前它们会失败,添加之后则会通过。每个样本还包括 PASS_TO_PASS 测试,这些测试在 PR 合
并前后都会通过,用于检查 PR 是否破坏了代码库中与问题无关的其他功能。
在 SWE-bench 中,AI 智能体会获得来自 GitHub issue 的原始文本,即问题陈述,并可以访问代码库。给定这些信息,智能体必须编辑代码库中的文件以解决问题。
AI 智能体给出的编辑将通过运行 FAIL_TO_PASS 和 PASS_TO_PASS 测试来评估。如果 FAIL_TO_PASS 测试通过,这意味着编辑解决了问题。如果 PASS_TO_PASS 测试通过,则意味着编辑没有破
坏代码库中无关的部分。要完全解决原始的 GitHub 问题,两组测试都必须通过。
提高 SWE-bench 稳健性、可靠性的三个改进方向
为了提高 SWE-bench 的稳健性和可靠性。开发团队确定了三个主要的改进方向:
用于评估解决方案正确性的单元测试通常过于具体,有时甚至与问题无关。这可能导致正确的解决方案被拒绝。
许多样本的问题描述不够明确,导致对问题是什么以及应该如何解决存在歧义。
有时很难为智能体可靠地设置 SWE-bench 开发环境,这会无意中导致单元测试失败,而不管解决方案如何。在这种情况下,完全有效的解决方案可能被评为不正确。
SWE-bench Verified
为了解决这些问题,OpenAI 启动了一项由专业软件开发人员进行的人工注释活动,对 SWE-bench 测试集中的每个样本进行了筛查,以确保单元测试的范围适当,问题描述清晰明确。
他们与 SWE-bench 的作者们一起发布了 SWE-bench Verified:这是 SWE-bench 原始测试集的一个子集,包含 500 个样本,这些样本已经通过了人工注释者的验证。这个版本取代了原来的 SWE-
bench 和 SWE-bench Lite 测试集。此外,他们还在发布所有 SWE-bench 测试样本的人工注释。
他们还与 SWE-bench 的作者合作,为 SWE-bench 开发了一个新的评估工具,该工具使用容器化的 Docker 环境,使在 SWE-bench 上进行的评估变得更容易、更可靠。
工具地址:https://github.com/princeton-nlp/SWE-bench/tree/main/docs/20240627_docker
改进方法
OpenAI 与 93 位具有 Python 经验的软件开发人员合作,手动筛选 SWE-bench 样本,并对 SWE-bench 测试集中的 1699 个随机样本进行了注释,最终得到 SWE-bench Verified。
他们的方法是对 SWE-bench 测试集中的样本进行注释,以确保测试的公平性和准确性。具体来说,他们关注两个关键点:首先,评估问题描述是否足够详细,以防过于模糊的描述导致测试不公平;其
次,检查 FAIL_TO_PASS 单元测试是否会错误地筛选掉有效的解决方案。
每个注释标准都有一个标签,范围为 [0, 1, 2, 3],严重程度逐渐增加。标签 0 和 1 是次要的;标签 2 和 3 是严重的,表明样本在某些方面不充分,应该被丢弃。
此外,假设样本没有问题,OpenAI 会通过让注释者估计开发人员决定和实施解决方案需要多长时间来评估每个样本的难度。最后,OpenAI 提供了一个自由格式输入选项来标记样本的任何其他主要问
题。
为了构建 SWE-bench Verified,OpenAI 从原始测试集中过滤掉问题陈述或 FAIL_TO_PASS 单元测试严重性为 2 或以上的任何样本,并且还过滤掉所有标记有其他严重问题的样本。
注释结果
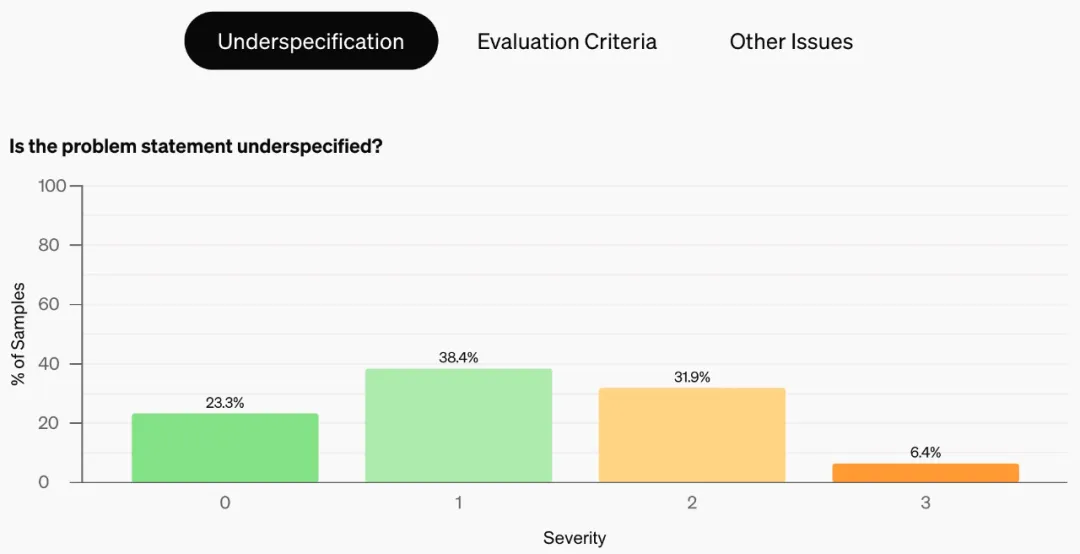
按照新的标准,原始 SWE-bench 中的样本有很大一部分是不合格的。如图所示,38.3% 的样本因为问题陈述不够明确而被标记,61.1% 的样本因为单元测试可能会不公平地将有效的解决方案错误地标
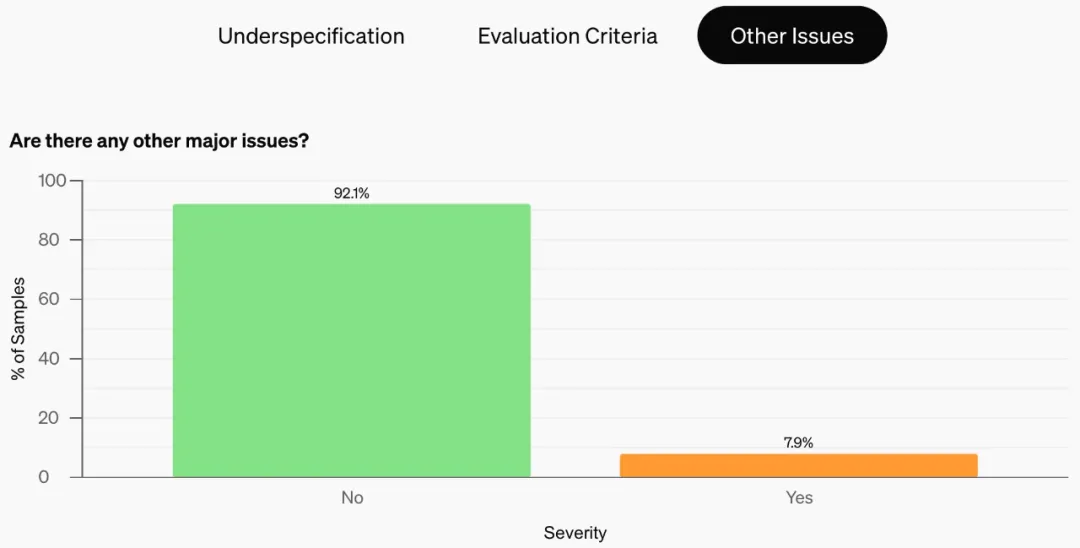
记为不正确而被标记(严重程度 2、3 两级加起来)。总体而言,他们的注释过程导致 68.3% 的 SWE-bench 样本因问题陈述不明确、单元测试不公平或其他问题而被过滤掉。

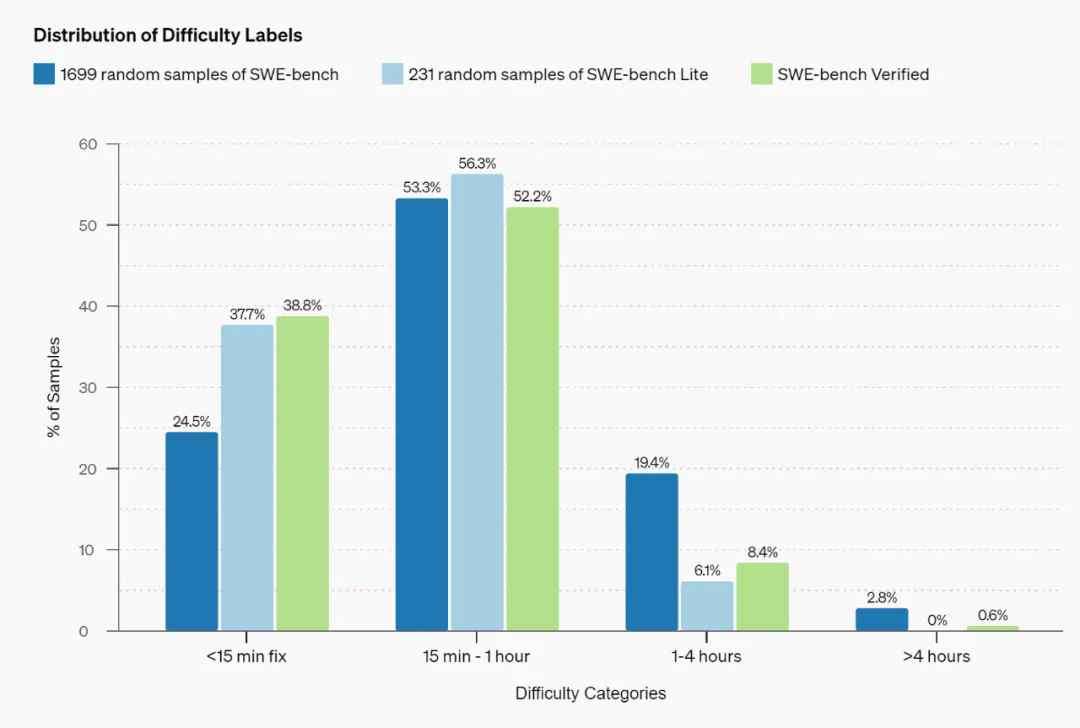
下图比较了原始 SWE-bench 数据集和新 SWE-bench Verified 数据集的难度分布。他们根据 1699 个样本的随机子集估算 SWE-bench 的难度分布。
从图上可以看出,在原始的 SWE-bench 数据集中,大多数(77.8%)样本的预计完成时间少于一个经验丰富的软件工程师一个小时的工作量。SWE-bench Lite 和新 SWE-bench Verified 数据集进一步
增加了这一比例,预计超过一个小时才能解决的问题少于 10%。然而,这种变化背后的机制有着很大的不同:SWE-bench Lite 是对原始数据集的子采样,使基准测试变得更容易,而 SWE-bench
Verified 则试图从数据集中移除不可行的样本。
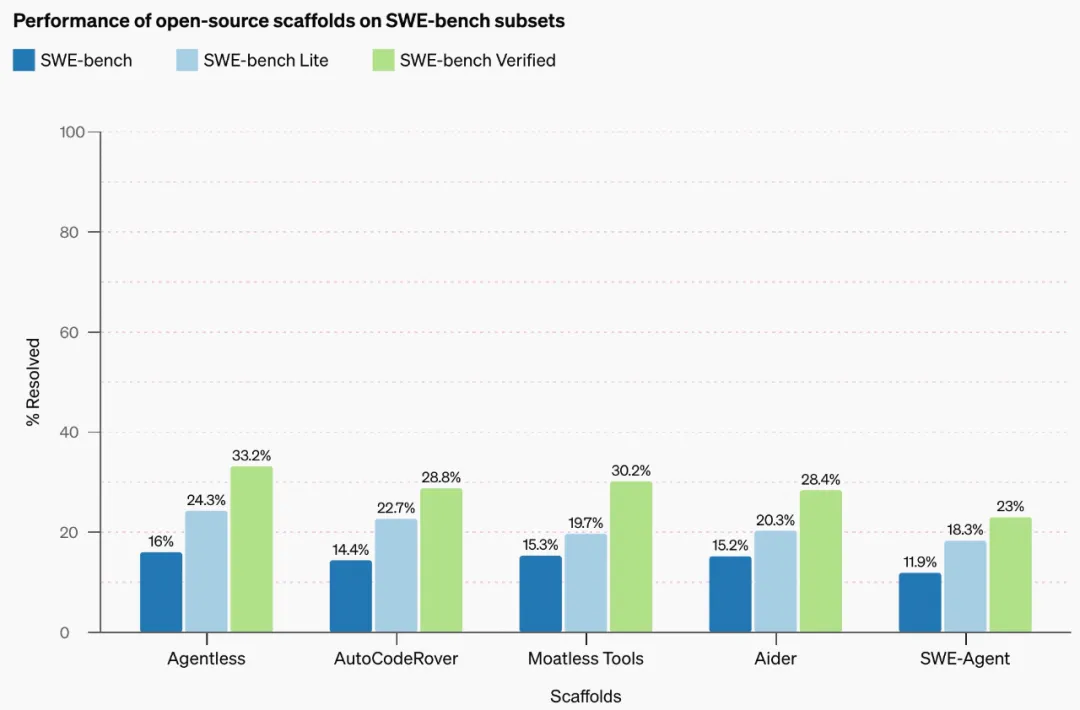
各个智能体在 SWE-bench Verified 上的性能
在新的 SWE-bench Verified 数据集上,开发团队使用多个在原始 SWE-bench 排行榜上表现良好的开源支架测试了 GPT-4o 的性能。
结果发现 GPT-4o 在性能最佳的支架上的性能在 SWE-bench Verified 上达到 33.2%,是原始 SWE-bench 上 16% 分数的两倍多。总的来说,这证实了 OpenAI 最初的怀疑,即原始 SWE-bench 低估了
智能体的能力。
值得注意的是,从 SWE-bench Lite 到 SWE-bench Verified 的跳跃并不那么明显,因为经过筛选,SWE-bench Lite 已经比完整数据集变得更容易。
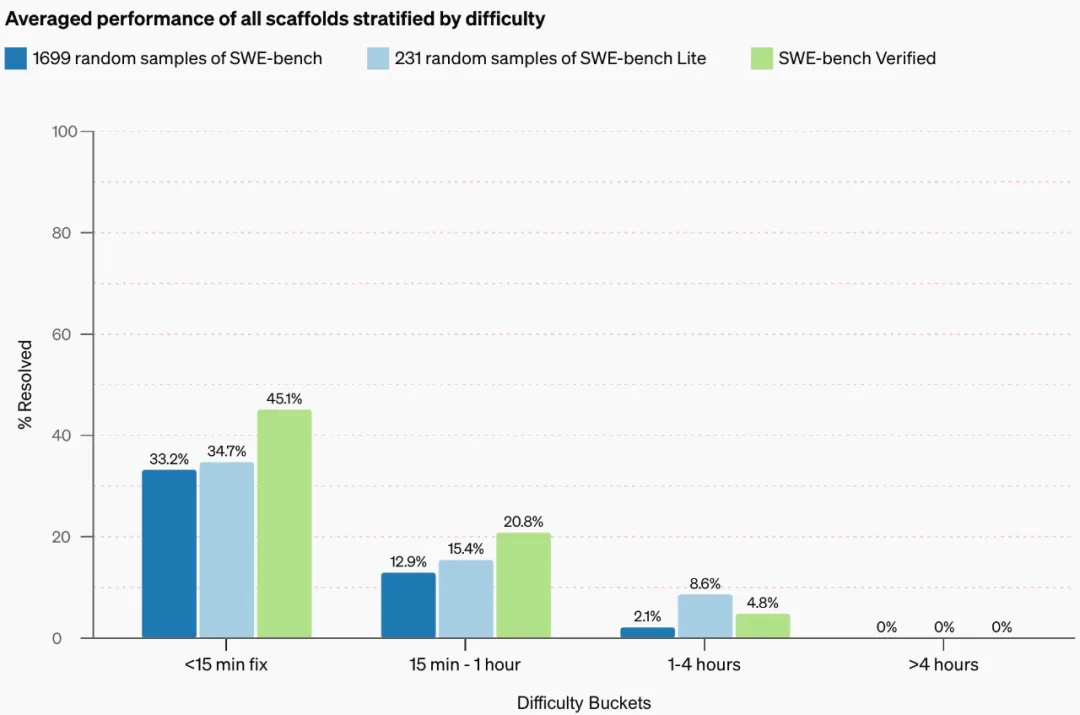
按难度分层的性能分析
在 SWE-bench Verified 上进行评估时,性能的提高可能部分是由于测试样本的分布向更简单的样本倾斜。
OpenAI 通过绘制按难度分层的性能来调查这一点。如果新数据集只是改变难度分布以包含更简单的样本,则每个类别内的分层性能不会改变,就像从原始 SWE-bench 到 SWE-bench Lite 的情况一
样。
相反,OpenAI 观察到,当转向 SWE-bench Verified 时,智能体在各个难度类别的性能均有所提高,这与预期效果一致,即从所有类别中移除不可能的样本,而不是简单地移除困难样本。
参考链接:https://openai.com/index/introducing-swe-bench-verified/
文章来自于公众号’‘机器之心’‘




【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
