# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
只要不到10行代码,就能让大模型数学能力(GSM8k)提升20%!
几名独立学者提出了大模型采样的改进方案,引起了开源社区的关注。
目前该方法已在Mistral-7B上取得成效,在Llama3-70B上的测试也正在进行。

这种方法叫做最小p采样(min-p sampling),目的是平衡生成文本的连贯性和多样性。
简单说就是让模型在不同场合发挥不同的特性,例如在事实问题上保持性能稳定,在写作等场景中又能发挥创意。
目前该方法已在Mistral-7B上取得成效,在Llama-70B上的测试也即将进行。
在论文中作者提到,该方法已经获得了开源社区的广泛应用。

同时作者还透露,Anthropic和谷歌等闭源模型厂商也已经或正在针对min-p进行测试。
消息也得到了谷歌方面的确认,从OpenAI跳槽到谷歌的开发者社区负责人Logan Kilpatrick已经回复说“On it”(在做了)。
微软Copilot的研究人员Abram Jackson看了后表示,这是他看到的首个有关推理过程token采样的改进,未来还有很大进步空间。

值得一提的是,这项受到广泛关注的研究,主要作者Minh Nhat Nguyen根本没系统学过CS,而是靠自学成才。
在一家名为Apart Research的AI安全研究机构帮助下,Minh和团队其他成员一起完成了该项目。

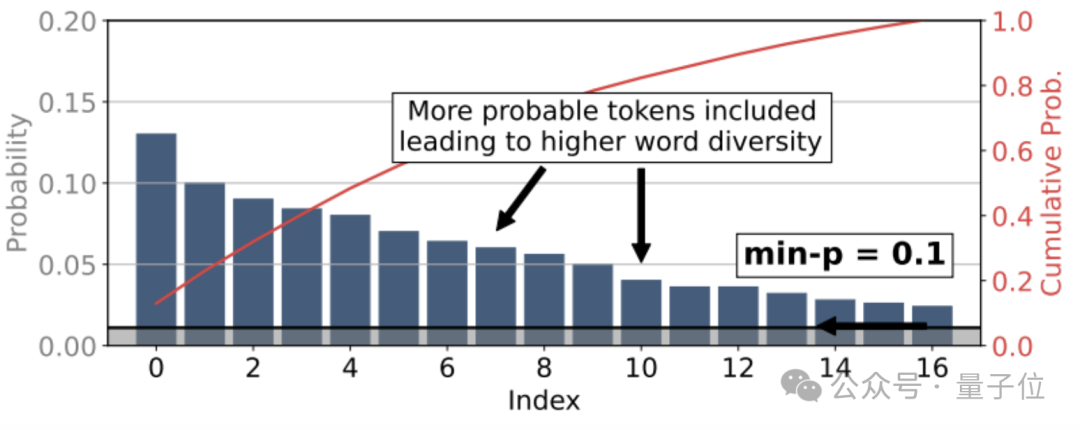
min-p是一种动态截断抽样方法,其核心是根据每一步token分布的最大概率,来缩放最小概率阈值。
这样做的目的,主要在于平衡生成文本的连贯性和多样性,特别是在temperature较高的条件下。
具体来说,min-p引入了一个基础概率阈值p_base,表示进入采样池的最低概率要求。
在每一步生成token时,min-p会将p_base与当前概率分布中最大的token概率p_max相乘,得到一个缩放后的绝对阈值p_scaled。
只有概率大于等于p_scaled的token,才能够进入采样池。
当模型对某个token的预测概率非常高(即p_max很大)时,p_scaled的值也会很高,导致采样池大幅缩小,绝大多数低概率token被过滤,只留下少数高把握的选择,确保了输出的连贯性;
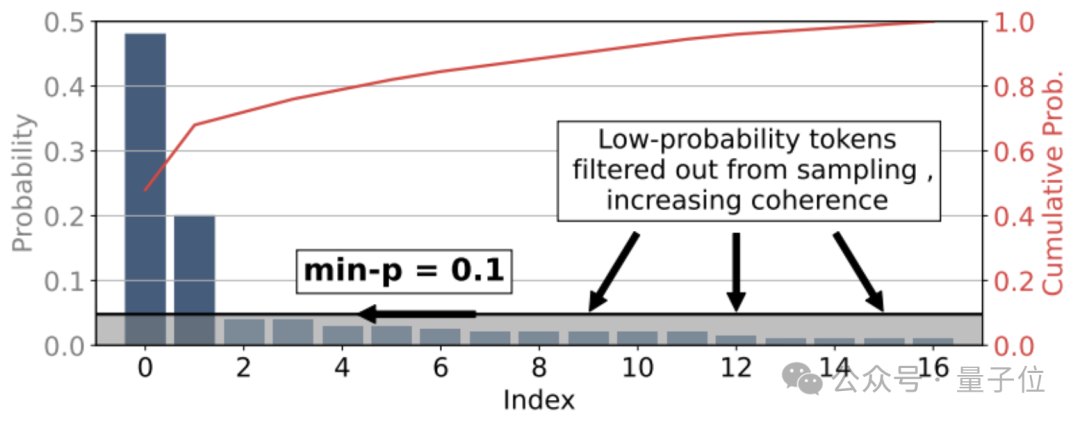
而当模型对所有token的预测概率都比较接近(p_max较低)时,p_scaled的值也会相应变低,放宽了对采样池的要求,纳入更多中等概率的token,给予模型更多发挥空间,生成更加多样化的内容。
在确定采样池后,min-p会根据temperature对token概率分布进行缩放。
它将token的对数概率除以一个温度参数τ,并进行归一化后,就得到了temperature缩放后的概率分布。
大于1的τ值会使概率分布更加平缓,增加低概率token被选中的机会;
τ小于1时则会使分布更加尖锐,强化高概率token的优势。
最后,min-p从缩放后的采样池中,按照调整后的概率分布,随机抽取下一个token。
min-p方法的效果究竟如何呢?作者使用了Mistral-7B作为基础模型进行了测试,我们来分场景看一下结果。
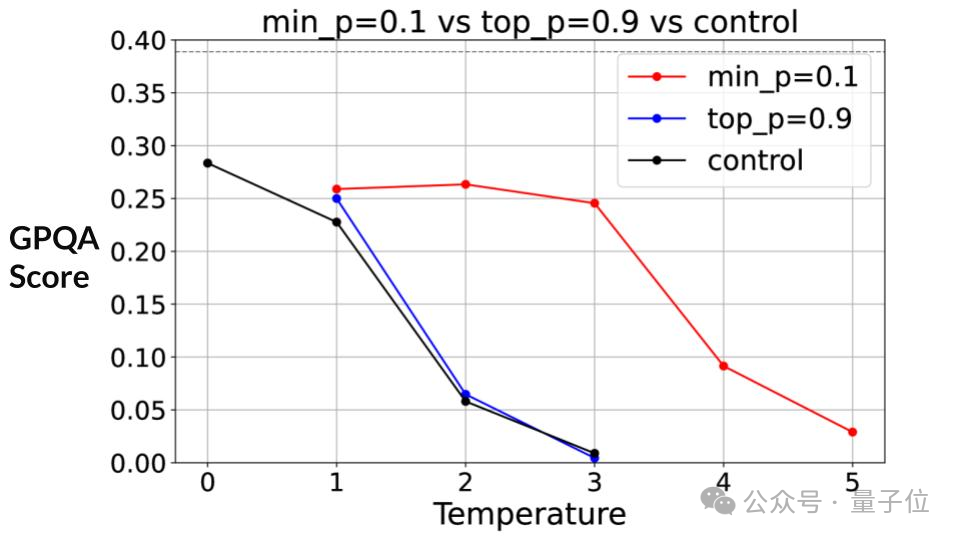
在推理任务中,作者采用了GPQA数据集。当temperature为1时,可以看到min-p相比于过去的top-p显现出了微小的优势。
随着temperature增加,GPQA得分整体上呈现出了下降趋势,但可以观察到min-p的下降明显比top-p更慢。
直到temperature达到3时min-p的下降趋势才变得明显,此时top-p的得分已接近0。
也就是说,相比于top-p,min-p在推理任务中更好地保持了所需要的稳定性。
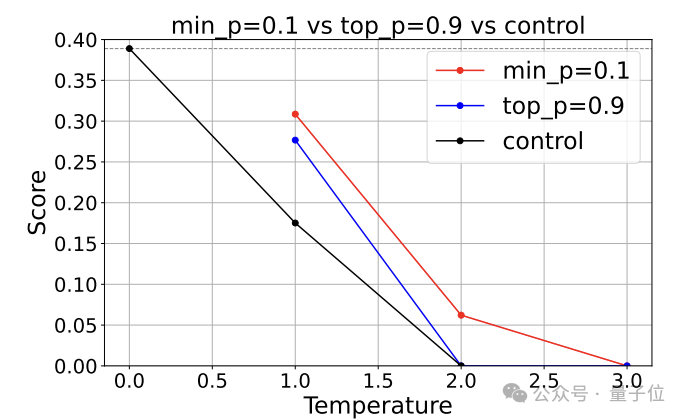
同样需要保持稳定性能的还有数学类任务,这里作者使用了GSM8K数据集进行了测试。
结果min-p所对应的分数随temperature的下降比在GPQA中更快,但仍然缓于top-p方式。
第三类任务是创意写作,这时对稳定性的要求就不是那么高了,而是需要模型发挥更多的创意。
这项测试使用AlpacaEval数据集完成,实验数据是从开源社区的一名独立评估者那里获得的。
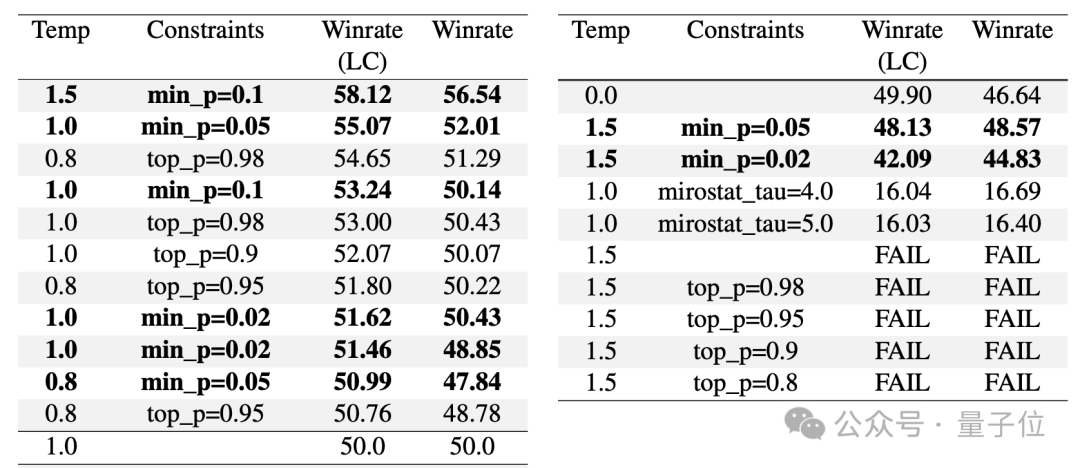
实验结果显示,在temperature=1.5、min-p=0.1的设置下,min-p的性能尤其突出,可生成top-p方法难以生成的创意写作内容。
在该参数下,min-p方法得到的文本获得了58.12%的人类评判优选率,远高于其他方法在类似设置下的表现。
文章来源于“量子位”,作者“克雷西”



