# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
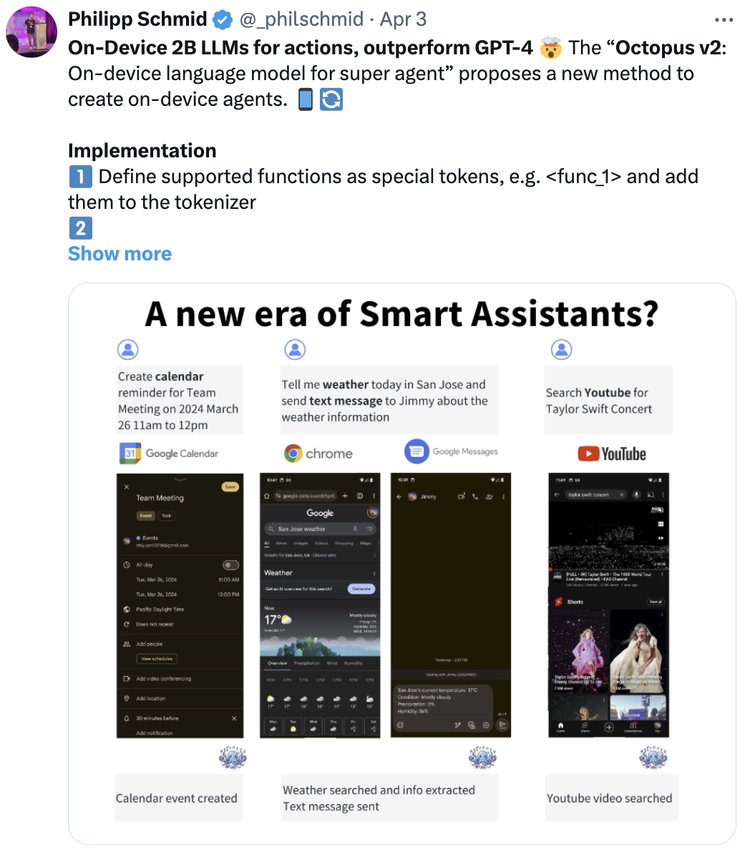
这是Nexa AI亮相时给大家带来的“冲击”。
四个月前,Nexa AI开发的5 亿参数小模型Octopus v2在硅谷AI圈子引发了广泛关注。他们开发的Functional Token技术,能实现比 GPT-4o 快 4 倍、比RAG 解决方案快 140 倍的出色推理速度,同时具备与GPT-4相当的性能,函数调用准确率高达98%以上。
上线Product Hunt当天,Octopus v2就荣获“No.1 Product of the Day”,在Hugging Face发布当月即累积1.2万次下载量。并受到Hugging Face CTO Julien
Chaumond、技术负责人Philipp Schmid、Figure AI创始人Brett Adcock等AI界权威人士的一致认证。
Nexa AI由两名年轻95后斯坦福校友Alex Chen和Zack Li共同创立,目前共有8名全职员工。斯坦福大学管理科学与工程系教授、科技风险投资项目副主任Charles(Chuck) Eesley,和斯坦福大学NLP小组教授、斯隆研究员Diyi Yang担任公司顾问。
据悉,他们已在短时间内成功签下10余家3C电子、汽车、网络安全、时尚消费等领域的头部企业客户。服务超过1000名注册用户,并于前不久完成超千万美元种子轮融资。
在Octopus v2发布后不到一个月,Nexa AI又发布了首个参数量小于10亿却能实现多模态能力的AI模型 Octopus v3。
在保持媲美 GPT-4V 和 GPT-4 的函数调用准确度同时,它可以在树莓派等各种边缘设备上高效运行,支持文本和图像输入,能理解中英文。后续还上新了能在不同领域知识中执行多步查询任务的38亿参数模型Octo-planner等产品。
而接下来,Nexa AI把“野心”延伸到整个端侧模型的市场。
最近它推出了首个端侧AI综合开发平台「Model Hub」。核心是一个专为本地部署设计和优化过的丰富AI模型库。包含自研Octopus系列、Llama 3.1、Gemma 2、Stable Diffusion和Whisper等多种先进模型。适合在各种设备上高效运行,且无需互联网连接和API费用。
搭配模型库,Model Hub还提供了一套全面的开源 SDK,支持开发者将模型部署到本地,并可根据个人需求微调定制,更具灵活性。也有大量实用示例帮用户快速上手,此外还建立了一个开发者社区。
也就是,一个端侧模型的Hugging Face。
“我们真正要打造的是一个on-device版本的Hugging Face。” Alex Chen告诉硅星人。通过整合模型、工具、资源和社区,他们正试图构建一个完整的端侧AI生态系统。
最近硅星人也与Nexa AI的两位联合创始人Alex Chen和Zack Li聊了聊他们对端侧AI的思考。
以下为对话实录:
硅星人:请Alex和Zack跟大家做个自我介绍吧。
Alex Chen:我是Alex,目前是Nexa AI的Co-founder和CEO。创建公司以前我在斯坦福大学读博,做AI和Math相关方面的研究。我和Zack是同济校友,已经认识大概有10年时间了,之前在很多学习和工作中都合作过。比如我俩都担任过斯坦福华人创业者协会的主席,在那段时间做过很多创业想法的实践,但Nexa是我们第一次正式成立一个创业公司去做。
Zack Li:我是Zack,Nexa AI的Co-founder和CTO。我从斯坦福毕业后就在业界工作,先是在 Amazon Lab126做Echo和Alexa,后面去Google做Google Assistant和Google Glass,所以积累了4年业界经验,也是从去年开始和Alex一起做 Nexa AI。因为现在做的方向和Alex的研究、以及我自己过往工作经验都很符合,所以我们不管是在模型训练,还是在客户交付、模型部署上都有比较大的优势。
硅星人:从斯坦福校园到现在创业,特别是选择了端侧小模型方向,是怎样一个过程?
Alex Chen:开始最早萌生创业想法,是因为我们俩都参加了斯坦福华人创业者协会。它比普通学生社团要正式很多,每年都有非常多的斯坦福校友从这个组织里走出去,自己真正做创业。比如真格基金合伙人尹乐,之前的金沙江合伙人张予彤,还有出门问问CEO李志飞、小红书创始人毛文超等等。我们在加入这个组织后,就会日常去认识很多创业者和投资人,也会在湾区举办创业活动。期间了解到创业的全貌大概是什么样子,就开始更倾向于自己去做一些事情。
这是最早的萌芽阶段。随着我们自身技术和创业理解的逐渐加深,就会去做一些side project,也刚好和这一轮生成式AI紧密相关。其实我们很早就注意到生成式AI的一些趋势,比如最早GPT-3出来的时候,Jasper就用GPT-3的API拿到了5千万美元revenue。于是就重点把精力放在生成式AI这一块。最开始的思路偏应用型,意思是先不去管核心技术,就用已有的技术去做一些好产品,比如通过调用GPT-3的API或者Stable Diffusion的一些开源模型直接出产品。
但到后面我们的想法就有些转变了,这里面也包含了为什么选择做端侧AI。
当时我们对整个生成式AI市场做了一个分析。首先现在应用型公司非常多,像email generation、marketing,或者AI interview这样的application,每一个垂类都可能找到大几百个相似的产品。它就变得非常臃肿,可能也不具备长期盈利能力,因为竞争者太多了,也没什么技术壁垒。
这是我们对市场的一个感知,这种非常剧烈的竞争也是促使我们改变路线的主要原因,就希望去看一些更有技术壁垒的工作。加上那个时候Zack已经做过4年 on-devise AI,积累了很深的行业见解。我们就去分析了这个领域,发现当大家追求更大的云端模型时,其实端侧有非常好的机会。
当时考虑了两个趋势:
首先随着算法不断改进,越来越多的大模型功能其实是可以通过小模型去完成的。比如GPT-3最早可能有175B参数,但现在一个7B的最新模型基本可以在很多方面追齐GPT-3。Open AI自己的模型其实也在变小,GPT-3.5据我们所知就比GPT-3要小。这个趋势是算法的精进以及数据挤压进一步完善之后的结果。
其次是端侧算力也在不断提升。比如说随着电脑手机的芯片不断进化,它们可以支持一些体积更大的模型在本地部署,所以这是两个总趋势。
后来我们也做了一些实际调研。今年1月份公司所有人都去拉斯维加斯参加了CES,在CES展上看到非常多本地AI模型部署实例,比如高通就已经在尝试把模型部署在各种各样的端侧芯片上。
硅星人:所以算法精进和算力提升,让你们觉得做小模型是有可能的。又去CES亲自看到了市场态势,最终决定把方向转到端侧AI上面。
Alex Chen:是的。
硅星人:你们觉得scaling law现在过时了吗?
Alex Chen: Scaling law还没过时,我相信对大部分人来说它还是成立的。
硅星人:那跟大模型比的话,小模型的机会在哪儿?
Alex Chen:我觉得这里问到了一个很好的问题,就是刚才提到scaling law。当我们去评估一个模型scaling law的时候,模型越大,它本身的综合能力肯定越强。但这是一种全方位的能力提升,以MMLU指标为例,大模型可能在MMLU不同的 subject下能力都很强,比如语文、数学、英语。但实际很多情况是,你并不需要它在所有层面都很强,而是只要在特定领域表现突出即可。我们公司会让小模型专注于某些特定领域,比如尤其擅长数学,或尤其擅长法律,这对于数学和法律领域的人来说就已经足够了,他不需要一个特别大的模型去完成他的问题。
另外一个点是当我们用scaling law去不断突破模型边界的时候,其实你要解决的那剩下1%特别难的问题,在日常生活中不一定会全部遇到。比如说我用万亿参数的GPT-4去回答“1+1=2”,这个问题用GPT-2就能回答得很好了,而它俩之间的参数可能相差几千到1万倍。同样的答案可以用两个截然相反的模型,那么小模型就会在速度和耗电上明显优于大模型。
总结来讲,我觉得小模型的优势是什么?首先它速度更快、更省电。与此同时,它部署在端侧基本上是完全免费的状态,因为用本地算力就可以满足。更重要的是它可以完全保证个人隐私。比如我们有一个很大的软件客户,他们的App是帮助人们处理一些ID card,包括身份证、驾照等图片信息。这种东西就没法通过云端API去做,因为涉及隐私,就必须用本地模型去实现这个过程。
硅星人:怎样才算一个好用的小模型?
Alex Chen:第一要速度快,第二要能在一些用户关心的领域和大模型相媲美,第三是能完全、轻松地部署在本地,既能保证隐私成本也非常低。
硅星人:目前NEXA整个产品框架是什么样的?
Zack Li:我来解答一下这个问题。首先我们的客户有developer和大的enterprise。对于enterprise客户,我们提供的是一个端到端的解决方案。比如以一家电商公司为例,他们给出的明确需求是,针对潜在商业合作的网红去自动化邮件的发布。那么我们的模型就可以满足这个需求,并且通过配套SDK帮他们部署,然后给到一个可以使用的产品,加入他们的工作流。不过我们的东西很通用,所以要做的定制化是比较少的。
针对developer的话,他们可以去我们的 Model Hub里找到他们想要的模型,比如针对电商场景或旅游场景的,然后通过我们的SDK去本地运行。我们除了支持Octopus,也支持一些比较经典和标准的开源端侧模型,譬如Gemma系列、Phi系列等等。
Alex Chen:我们的适用场景就是刚才提到的,大模型目前还无法解决的那1%特别难问题以外的所有问题。比如说情感陪伴、帮你去写email、润色文章等,这些都可以通过一个部署在你本地的小模型完成。所有从难度系数上来说没那么高、但基本能满足大家日常生活的语言模型use case,都是我们这个产品可以赋予大家去使用的东西。
除此之外我们能提供的强大功能点,也就是Octopus模型的最大亮点在于,它有很强的function calling(函数调用)能力。
硅星人:这也是接下来想问的,NEXA 的核心技术优势是什么?
Alex Chen:对,我们的独特之处就是可以用一个本地部署的很小模型,去和很大模型的function calling相媲美。它能把用户的自然语言转换成可执行的命令。比如说你想去Amazon买一款三星手机,直接在对话框里面输入购买需求,它就会自动打开Amazon,并且输入三星手机的描述,帮你节省大量图形操作界面流程。相当于Octopus可以把很多图形操作交互转换成自然语言交互。
硅星人:你们论文中提出了一个创新的Functional Token概念,能解释一下吗?以及它是如何优化AI推理过程的?
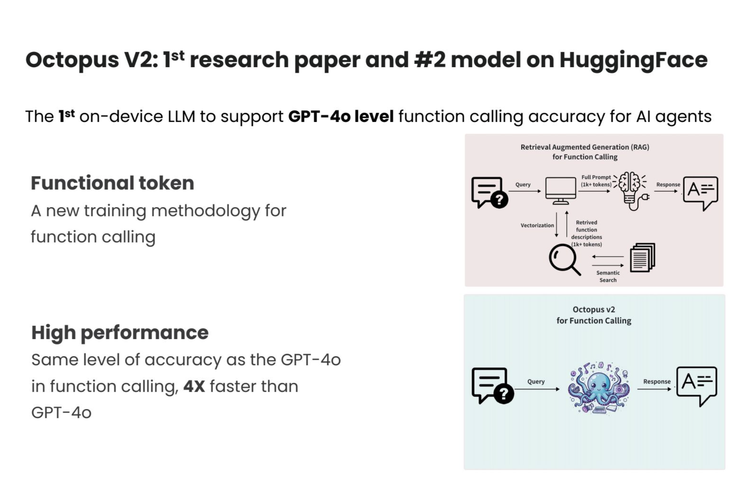
Zack Li:过去的方法,比如基于RAG(检索增强生成)技术,一个问题进来时,需要先从API文档或数据库中检索相关信息,然后把这些信息作为上下文提供给大模型进行决策。这个过程首先检索信息耗时,需要处理大量语义token。由于上下文窗口过长,导致推理时间非常漫长,尤其是在算力和尺寸有限的设备端,模型准确性和响应速度受到限制。
我们的解决方案是通过一个端到端的模型直接输出。首次引入了Functional Token(功能令牌)的概念,用1个token来表征整个函数信息,包括函数名、参数和文档,把上下文长度减少了 95%。当用户输入自然语言指令时,系统能省去繁杂的检索步骤,迅速识别任务关键点,触发相应的Functional Token,从而直接生成所需输出或执行特定的函数调用。
在输出层,由于Functional Token代替了完整的函数表述,使得输出基本都能控制在10个token以内,因此更为简洁。这样做能显著节省计算资源和上下文空间,同时大幅提升处理速度。特别适用于移动设备或边缘计算设备,这些需要快速响应的场景。
硅星人:实际验证下来表现如何?
Zack Li: 像GPT-4o是一个非常大的trillion级别参数量模型,用多个 GPU Cluster来做推理,但我们只是用单卡A100去做比较。即使是在这种极其不公平的硬件条件下,我们的Octopus v2模型依然比GPT-4o快4倍。
硅星人:Octopus v2当时在X反响挺强烈。我看到你们还有Octo-net, Octopus v3和Octo-planner,这些模型是各有所长还是一系列迭代?
Zack Li: v2、v3到planner是一系列迭代,其中v3有了多模态能力,planner有了多步规划能力。Octo-net相当于一个分支,支持端云协同。
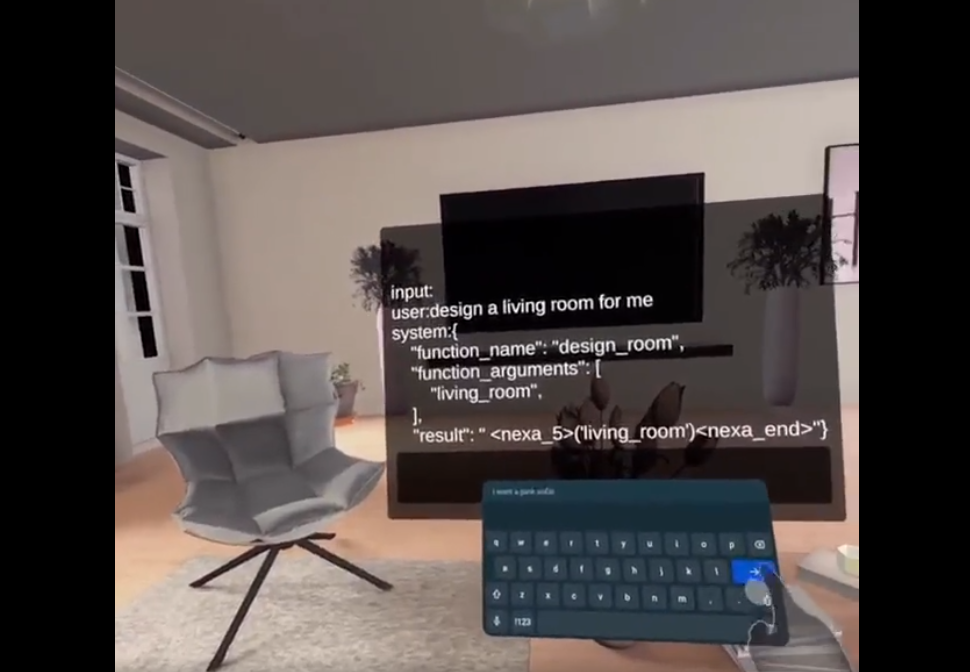
开发者将Octopus模型部署在VR设备上的demo
硅星人:你们最先进的一款模型能力现在到什么程度?
Zach Li:我们的v3模型是目前对enterprise最新的,能够在1B参数以下支持多模态。可能国内外都有一些优秀的端侧公司逐渐出现,但目前还没有1B以下做到多模态,并且能达到我们function calling准确度的竞争对手,2B以下目前也还没看到。
硅星人:其实除了创业公司,很多像OpenAI、Google、Meta之类的巨头也开始去卷小模型了,你们会有威胁感吗?
Zack Li:当然能感觉到竞争是很激烈的。但首先我们抓住一个利器,就是端测模型里最难的function call这件事。同时还能不断结合Model Hub去鼓励更多开发者加入我们,相当于走Hugging Face路线。所以即使现在端侧模型已经逐渐开始内卷了,我们做好模型,同时也做好平台,让更多的开发者去使用这些模型,这就是我们的一个differentiation。
Alex Chen:其实我们真正要打造的是一个on-device版本的Hugging Face。Hugging Face是一个给云端开发者提供的AI研究社区,它有非常多基于Python还有英伟达GPU的模型搜寻和使用框架,但这些都是为服务器端的开发者提供的。我们的不同之处是要让模型部署在本地,那么这些模型的文件格式、部署所需要的软件支持都是不一样的,比如Hugging Face用Python,我们就是C或者C++,这些是核心差异。
你看到我们会有一些软件库比如SDK,有自己开发的Octopus模型,还会支持像微软、Google的一些其它小模型在本地部署。我们是这么考虑整件事情的:其实你去看云端的话,两个典型比较有价值的公司是OpenAI和Hugging Face。我们其实就像一个端侧的 OpenAI和Hugging Face结合体。一方面我们自己在做端测模型,另一方面也希望通过这个平台进一步帮助大家去使用端侧模型。
所以我们将来的商业模式,更多是通过维护这种on-device AI community,去给一些on-device developer提供基于订阅的收入,另外就是针对这些开发者背后enterprise做一些企业服务。
硅星人:就是在你们平台我不仅能用到Octopus,还可以看到许多个体developer或公司发布的端侧AI。
Zack Li:是的。平台积累我们才刚开始,5月试水了一下,大概有1000多个developer,之后就在不断内部打磨,为正式上线做准备。我们也希望向更多人介绍这个产品,提供测试链接看看大家的反馈。
正式上线的Model Hub会成为NEXA AI的主网站页面。主要产品是一个可以让你找到所需端侧模型的平台。之前那些research work可以展示我们的自主研发能力,也有to enterprise的入口。
Model Hub里可以看到各家公司的端测模型。因为我们比较懂端侧,所以专注于端侧常用的GGUF、ONNX这些格式。比如Meta Llama3.1-8b,我们能quantize成不同精度,像int4、int8。这种压缩过的模型专门适用于端侧运行,不像Pytorch、Python在云端环境下运行。
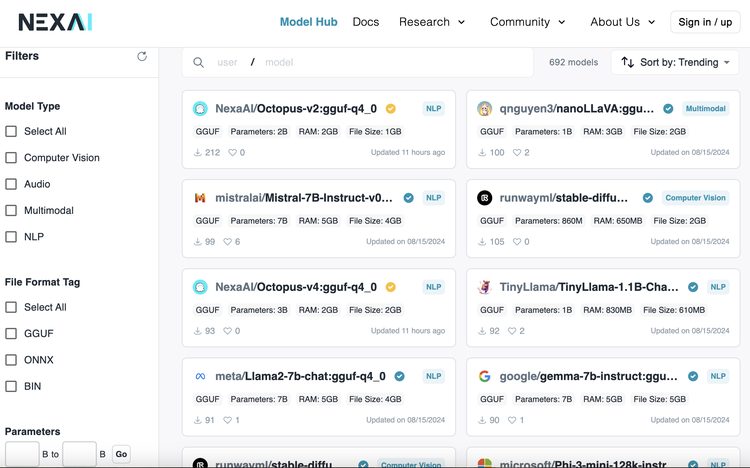
消费级GPU的RAM最多24G,开发者不可能在本地运行原尺寸模型。我们可以帮发布者去做批量的压缩量化。然后我们还有 SDK工具,可以让用户轻松在自己笔记本电脑或手机上使用各种模态的模型,也提供UI展示,完全靠本地算力并且速度很快。
就像Hugging Face,它火是火在有 transformers包。你不光能在这里找模型,还能运行,然后再做二次开发。这才是它能留住用户的核心,对不对?我们其实就是把这个东西给做出来了。
硅星人:下一个问题可能前面也聊到了。现在投资人都会问why you,那对你们自己来说,让目标客户选择NEXA而不是别家竞争对手,这个自信的点是什么?
Zack Li:自信的点第一个是模型优势,我们模型的function calling准确度非常高,同时尺寸很轻。第二个是部署优势,我们可以针对用户不同的硬件需求、操作平台、内存和开销去定制化不同的加速方案。也就是我们不光模型比别人好,还有框架可以支持他们去更好地部署这个模型。
硅星人:这些优势在面对OpenAI或Google时成立吗?
Zack Li:我觉得OpenAI很长一段时间不会直接去触碰端测模型这个领域,它的GPT-4o mini依然是一个云端模型。Google有可能去做,当然Google有人才和设备优势,还有自己的生态。但你很难想象它会去顾及安卓生态之外,尤其在端侧硬件这一块,除了他自己Pixel生态之外的客户,更不会去做像Model Hub这样的事情。
硅星人:可否分享一下最新产品进展和接下来的优化方向?
Zack Li:除了前面说的 Model Hub和 SDK,我们后续还有一系列的 research work,支持长文本处理的压缩模型也正在开发中。后续我们会做好不同场景的服务,其实端侧有很多场景,function call是一个场景,还有其它像question answering能力、多模态能力比如图理解、音频处理等等,这些方向都是会重点关注的。
硅星人:作为一家端侧AI初创公司,你们的挑战来自哪些方面?
Zack Li:包括但不限于一些大厂吧。他们可以去做自己的端模型,尤其具备trillion级大模型开发能力的话,就可以复用很多经验,通过蒸馏或剪枝这样的方式。但我们在做端模型这件事上是有自己独特insights以及对这个领域的理解的,所以我觉得各有千秋。
再就是现有已有的一些社区player。Hugging Face就是一个很好的例子, 它要做端测的话对我们也会是一个挑战。但目前看来,Hugging Face的整个生态,包括过去所有架构都是云架构,服务也都是云服务。所以我觉得它要做转型必然是会比较痛苦的。如果当一个project去做,它的momentum和速度也不会那么快。
硅星人:你们把端侧模型和社区结合在一起,布局市场是比较早的。有没有做一些线下开发者活动推广?
Zack Li:我和Alex现在需要做大量的模型开发训练和一些infra相关工作,活动由我们产品和marketing 同学负责,包括这些年在湾区也积累了很多资源。8月25号Nexa要和 Hugging Face、StartX、Stanford Research Park 、Groq、AgentOps在斯坦福联合举办一场Hackathon,是我们第一次做线下,欢迎来看看。

Nexa AI主办的Super AI Agent Hackathon现场。图源:NEXA AI
硅星人:最后两个小问题,在硅谷这么多年,有没有很欣赏的公司或人?
Zack Li:我还是比较喜欢Elon Musk。他有一句话是“Tough and Calm” ,就是对事情要求高,并且能在巨大困难面前保持冷静,我自己也在朝这个方向去努力提高自己吧。然后你想,他能同时handle这么多公司,每家公司在面对不同挑战时又都有一定的方法去解决。我觉得他有很长远的视野和很强的执行力。
但如果更接地气一点,其实我更喜欢雷军。因为我自己是湖北人,雷军是湖北仙桃人。他非常勤奋、有亲和力,并且能够hands-on去思考很多问题,身上有很典型的开发者气质。不管作为高管、投资人还是创业者都非常优秀。
硅星人:创业到现在,最大的感触是什么?
Zack Li:我觉得创业这件事情还是产品说话。市场会给我最公正公平的反馈,所以get things done是最重要的。要有长远的目标,同时坚持去做难而正确的事情。比如公司最开始的一些工作可能非常偏产品,没有做很多底层创新。直到现在能突然有这么大一个流量和势头,根本原因还是我们在端侧模型底层上的优化,提出了一个前所未有的训练方法,自己发paper申请专利保护。如果没有这些技术,是不可能脱颖而出、取得现在这样影响力的。所谓的套壳公司,我深刻感受到,几乎没有办法杀出重围,除非你在产品上有极强的洞见。
文章来源于“ 硅星人Pro”,作者“Jessica”



【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
