# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
就在昨天,人类与机器的对话方式,全面升级了!
我们在使用一番之后,可谓是大开眼界。
比如,让它用天津话讲段相声。
您别说,这味儿可太对了!

敲黑板:作为国内首个「极速超拟人交互」,这款讯飞星火版的「Her」,已经全民开放体验了!
只要下载讯飞星火APP,即可体验对标GPT-4o的超自然AI语音助手。
目录中

星火对话中
要知道,传统的语音交互,一直面临着三大挑战:准确理解说话人意图;生成恰当响应;高效通过声音传达信息。
以往的语音交互,一直无法摆脱满满的智障味儿,就是因为这些环节中的延迟,大大拉低了用户体验。
而这一次,人机之间的交互,将如真人般自然流畅。
那么问题来了,所谓的「超拟人」到底有多拟人?
直观感受是:我们也有自己的「GPT-4o」了!
此前,我们见到的语音AI,总是给人感觉不太聪明的样子。
如果忽然打断它,它就瞬间蒙圈了,要么接不上来,要么就开始「已读乱回」。
但这次的小星,模型响应的快速和流畅度让人眼前一亮。
即使随时打断、插话,小星依旧能做到秒回,这个快速反应能力,让我们的观感仿佛真人一般。
比如,我们拿前段时间的全球大热点——巴黎奥运会考一考小星:「中国队在巴黎奥运会上奖牌总数排行第几?」
小星瞬间回复,而且在搜索过程中还使用了「让我来数一数」这种流畅的过渡方式,让交互过程更加自然。
可能是搜索结果太过全面,小星不仅把金银铜牌的总数都说了出来,还开始总结中国队的优势项目。
可以感觉到,整个语音交流的过程中非常顺畅,非常自然,即使随时打断它,它都能立刻给出正确的反应,而不是跟一个「人工智障」在对话,这个感觉真是太~爽~了~
不仅如此,小星「紧跟热点」的能力也是相当令人满意。
十一调休安排过于混乱?只要问一句,它就能给你解释得明明白白——
之所以模型的响应如此之快,如此之流畅,是因为它采用的是统一神经网络,直接实现了语音到语音的端到端建模。
第二个非常鲜明的特点是,小星对情绪的感知,实在是太敏锐了。
无论是高兴、悲伤、生气、害怕,我们话中的情绪,它都能立刻识别出来,敏锐地和你的情绪产生共鸣。
然后,它会自动把你代入符合情境的对话,然后用合适的情绪语气,进行贴心的回复。
可以说,简直秒杀了部分人类。
要上台演讲了,看着台下的几百个观众,紧张得手直抖,不用怕,小星来贴心地安慰你。

「我从未见过如此厚颜无耻之人」的网络热梗,它都知道,识别出这句话中的情绪,自然也是不在话下。
然后,我们还能让它用开心/沮丧/搞怪的方式来描述一下今天的天气。
你见过有带着哭腔念出的「全天多云」吗?
其实,从日常的交流中也可以感受到小星的丰富情绪。
比如没有听清问题时会不好意思地微笑,平时交流时始终情绪高涨、语气上扬,但察觉到你的消极情绪时,语气又会变得十分关切柔和,情绪价值给得相当到位。
注意,它并不是简单地通过语音文本来进行情绪的判断,而是针对复杂场景下的语音识别效果做了提升,因而能够感知数十种情绪。
在交流中,小星可以跟随你的指令,控制数十种情感、风格、方言,还可以变换语速。
比如,让它开心地给我们讲一段睡前故事。

好听,但是还能更夸张一点吗?完全可以!
而且,这个小狐狸和月亮的故事,充满诗意和淡淡的伤感,还悬念十足,听到最后我们都为小狐狸的坚持而感动。

诶,暑假哄娃神器,这不就来了嘛。
我们还能让它用主持人的口气,给咱们读一篇文章。不得不说,小星的朗诵十分有感染力,值得鼓掌!
如果你厌倦了同一种语调,还可以让小星大展身手——扮演东北大哥给你来段相声。
听完之后,没忍住吐槽了一句:就这?
您猜怎么着,小星竟然丝滑地接过了话茬。这体验也太类人了,仿佛手机里真住了个大哥。

小星说起天津话来,也是妥妥的喜剧人一枚,那是相当干哏倔脆、调皮捣蛋。
小星的超拟人交互,还拥有百变人设,一不小心就被挖掘出「戏精」的一面。
孙悟空、蜡笔小新、小猪佩奇……多种角色的音色、语气,它都模仿得惟妙惟肖,甚至还能模仿他们的人设和你聊天。
只需要一句简单的指令:「扮演XX和我对话」,就能随时和它来一场「语音cosplay」了。
只要几句话,我们就召唤出孙悟空了。
那就让我们问一下,取经过程中最难忘的一件事?
看来,白骨精着实给了他不小的阴影。
下一秒,小星就林妹妹上身,「三分柔弱两分温柔四分讥诮一分气恼」的feel,拿捏得是十分到位。
被问到「在大观园中最喜欢和谁一起玩」时,黛玉的回答是薛宝钗和史湘云。
听,小星模仿起熊二的声音和语气简直是惟妙惟肖,瞬间从阳光开朗大男孩变成了一只爱吃蜂蜜的傻萌棕熊,回答问题时也全程在人设内,完全不会OOC。

另外,我们还发现,小星回答问题的知识水平也令人刮目相看。难怪许多人沉迷和AI「谈恋爱」,有「智性恋」那味儿了。
无聊时,可以唤醒它来和你玩儿一段成语接龙解闷——
让它解释物理学概念「胡克定律」和「能量守恒定律」,小星依旧能做到「秒回」。
而且绝不仅是机械地背概念,而是结合弹簧、陀螺这种生活中的例子向你绘声绘色地解释,还会生动地把能量守恒定律比作「大自然的记账本」。
相较以往的语音交互,此次的讯飞星火极速超拟人交互,有何不同?
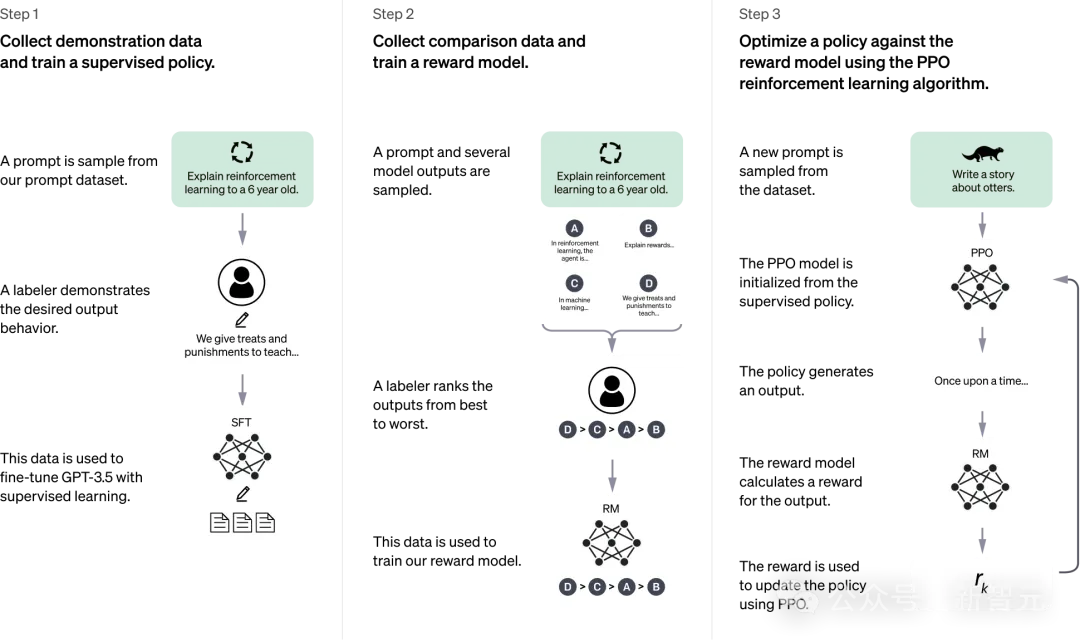
传统语音交互系统,若要实现和人的对话,一般需要通过语音识别——自然语言理解——自然语言生成,这三步来实现。具体来说:
第一步,需要通过语音系统,将语音转换为文字;
第二步,利用大模型生成回复的文本;
第三步,再用语音合成系统,转换成语音。

此前,英伟达高级科学家Jim Fan曾表示,这也是让Siri/Alexa交互能力,提升10倍速的秘诀。

他利用当前先进的AI语音系统Whisper、大模型ChatGPT、以及语音合成技术VALL-E,重述了这一过程。

不过,这一过程需要三个独立管道串联才可实现,因此会带来响应延迟,至少需要3秒左右。
另一方面,语音转文字再转语音的过程中,我们语音中的情感、副语言信息,甚至是环境信息都会丢失。
这样一来,导致语音交互系统,只能针对转换之后的文本信息进行回应,不能有效灵活地做出应答。
由此,基于以上问题,科大讯飞提出了极速超拟人语音交互框架——一个端到端跨文本、音频模型的新模型。
虽然模型内部划分了多个模块,但仍是一个「统一模型」。
用户语音通过音频编码器模块,编码成音频表征,然后通过适配器,将其与文本的语义表征对齐。
再通过多模态大模型,去预测生成表征,最后通过音频解码器得到语音。
相较于传统语音交互系统,端到端统一模型以知识对齐表征方式,让信息在各个模块之间传递。
这意味着,同一个神经网络直接实现语音-语音的建模,输入和输出皆由相同神经网络处理,大大缩短了对话响应时间。
同时,音频中的情感、环境中信息,它都可以没有损失地进行传递。

从上面实测例子能够深刻感知,人类和AI互动终于从你一句、我一句的「聊天软件模式」,切换到对答如流的「日常交流模式」。
不仅如此,整个系统的信息实现了无损贯穿,让交互更加拟人化、丰富流畅。
若说极速超拟人语音交互最大的不同,就是讯飞开发了一种特殊的语音训练方法——多维度语音属性解耦表征训练。
它能够将语音的不同属性分开处理,比如语种、内容、韵律、音色。

要知道,语音中的所有属性都是耦合在一起的,比如你说话的情绪和吐出的内容,是密不可分的。
那么,如何将这些表征分开,如何确保它在下游任务中充分利用,对解耦能力提出了更高的要求。
对此,讯飞团队做了很多对比loss学习,以及研发预测自监督学习等一些方案。
不过需要提一句,这里并非说,必须把所有表征信息彻底分开。这就需要把握一个度,在TTS中就可以控制的更好。
这种方法,能够让不同语音样本之间,实现更好的学习效果。
另外,它还能更灵活地控制内容、音色、情感等元素,满足不同场景和需求。甚至,通过更便捷的相关定制,可加速落地过程。
虽然OpenAI版Her还未全面开放,但讯飞版Her已经完全开放使用了。
语音交互是人机交互的一个子集,也是万物互联最自然的一个交互方式。
从历史上看,人机语音交互经历了几个重要的发展阶段。
第一个里程碑便是,以Siri语音助手为代表云端语音助手的出现,标志着语义交互技术的一大突破。
这是基于语音单点技术的进步,通过将这些技术巧妙地结合,语音助手能够专注于执行基本的指令控制功能。
比如,设置闹钟、查询天气、播放音乐等等。

第二阶段是以「智能音箱」为代表的产品,得益于麦克风阵列处理技术改进,以及远场语音识别能力的提升,使得设备交互可以在很远的距离进行,比如家庭环境。
到了第三阶段,便是以智能汽车语音助手为代表的交互,多音区技术、云端意图识别等技术发展,实现了多人复杂指令控制。
最后一阶段,就是以ChatGPT发布为起点,开创的全新语音对话的新范式。
这一次,讯飞语音交互系统的升级,带来的更快响应、更懂情绪、更加灵活、更加百变的优势,足以重写整个语音交互市场。
2023全球数字经济大会上,来自工信部数据显示,截止去年5月,我国移动物联网终端用户超过20.5亿。
而从产业发展来看,智能语音正迎来应用突破、产业扩展的黄金期。
据IDC分析,预计到2030年,全球智能语音服务市场规模将达约731.6亿美元,复合增长率27%。
国内外科技公司看准这片蓝海,纷纷入局开发,掀起了新一轮人机交互革命。
不光GPT-4o的语音功能还在内测;谷歌宣发的Gemini Live,也仅面向高级订阅用户使用。
反观国内,鲜有大厂能够站出,以匹敌OpenAI版Her产品的姿态,与之进行正面竞争。
凭借语音起家的科大讯飞,是其中最强悍的挑战者之一。
这是因为,讯飞星火大模型在不断迭代过程中,逼近国际领先水平。
今年1月,讯飞星火V3.5发布,历经5个月的时间,再次迭代至V4.0版本,整体能力超越OpenAI的GPT-4 Turbo。
同在1月,讯飞还首发了语音大模型,实现首批37个主流语种语音识别效果超过OpenAI Whisper V3。

基于讯飞全球领先的多语种语音技术,语音大模型随后再度升级,支持74种语言方言免切换输入。
时隔1个月,讯飞在极速超拟人交互上取得的技术突破,足够让终端设备实现「无感迭代」。
设想一下,当你有了这样的设备,不仅手握百科全书,还拥有了一个得力的助手、最亲密的伙伴/朋友。

科大讯飞表示,基于全新端到端框架,未来新系统还会朝着三大方向去拓展:更多模态、更多语言、更好体验,带来更实用、更丰富的功能。
这也代表着国产大模型如今早已从追赶、对标,快进到了自主创新的差异化之路。

不仅如此,讯飞还要双管齐下,加速极速超拟人交互落地,便是下一个需要瞄准的方向。
一项技术只有落地了,才能彰显它的价值。
未来,讯飞可能会布局情感陪伴场景,将极速超拟人交互集成到儿童机器人中,又或是赋予在线IP能够感知用户情绪的能力。
另外,便是在智慧汽车、智慧家电等方面大规模开拓应用。
这一技术的应用和普及,还隐藏着巨大的可能性——语音市场在这个时代将被改写,语音交互带动万物互联的第六次产业浪潮,有望出现一次井喷。
智能语音技术,将进一步应用到智能手机、智能汽车、智能家电以及智能家居等产品中。

据IDC分析,到2030年,全球智能语音服务市场规模将达约731.6亿美元,复合增长率27%。科大讯飞,有望收获这一轮产业红利。
中国AI语音的ChatGPT时刻,指日可待。
文章来源“新智元”,作者“新智元”



【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
