# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
这篇文章是笔者之前AI手写连笔书法生成的一个工作,是联合中央美院几位非常知名的老师完成的。当时提出的思路相对简单,主要结构是基于对抗生成网络(GAN)。虽然方法在大模型横行今天可能已经不算太新颖,但近期一些基于diffusion的AIGC工作还是关注到了这篇文章,并产生了一些启发。笔者认为这些灵感仍具有一定价值,因此在这里做个分享。由于一些公式和指标不太友好,为了不影响阅读故省略。

图1:SPFG和BHFG的示意图
在中国几千年的书法历史中,形成了多种书写风格,其中书法风格由骨架结构和笔画风格定义。骨架包含了字符的基本信息,如笔画构成、位置和书写方向,而笔画风格则涉及骨架的变形,如笔画厚度、形状和书写力度。在自动生成毛笔手写字体时,确保结构准确和风格一致至关重要。大多数研究者关注标准打印字体合成(SPFG),而毛笔手写体生成(BHFG)的研究相对较少。如图1所示,BHFG明显比SPFG更具挑战性。即使是相同字符,不同风格的书写会呈现出截然不同的图像。特别是对于草书或行书风格的字符,其图像会有显著的变形。骨架结构在分离笔画基本结构和布局方面有相似之处,有助于字符识别;而在形状上的几何变化使得风格易于区分。基于这些观察和分析,我们强调字符骨架对于保持字符内容在不同风格中的一致性至关重要。然而,大多数现有的SPFG方法忽视了骨架的关键作用。
我们的方法旨在通过提取和生成字符的骨架,将其纳入损失项以提升模型性能。具体过程如下:
我们提出了一种新颖的端到端GAN模型(SE-GAN)用于毛笔手写字体生成(BHFG)。此外,我们在生成器中引入了一种创新的自注意力精炼模块(SAttRAM),旨在有效提取和融合源图像和骨架图像的特征。我们进行了大量实验,涵盖了六种不同风格的中文字体生成任务。自动和人工评估结果均证实了SE-GAN相对于强基线方法的有效性。

图2:央美邱志杰院长手写的数据集
图2展示了SE-GAN的架构,包括转换网络、两个判别器和一个辅助的SkeletonGAN。
在这个框架中,包含两个编码器:图片编码器(E_i)和骨架编码器(E_s),每个由4个残差块组成。为了更好地提取骨架增强的图片表达,我们设计了两个SAttRAM变体:SRAM和CRAM,这两个模块依次堆叠,进一步增强特征提取效果。生成器接收精炼后的图片表达,并生成目标风格的图片。SE-GAN架构包含两个判别器:第一个判别器(D_i)用于判断生成的图片与目标图片是否一致,第二个判别器(D_s)用于判断生成图片的骨架与目标图片的骨架是否一致。骨架抽取算法基于著名的Zhang-Suen细化算法,通过迭代腐蚀和膨胀对二值字符图片进行处理,简单有效地提取出字符的骨架。
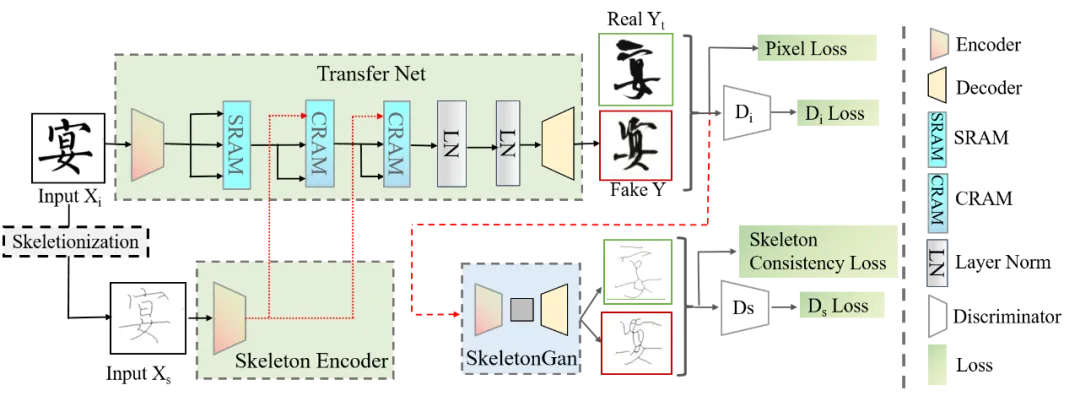
图3:SE-GAN架构
以往的研究已经证明了类激活图(Class Activation Map,CAM)在图像生成和分类任务中定位输入图像重要区域的有效性。受此启发,CAM也可以用于字体生成任务中提取风格辨别注意力热图。
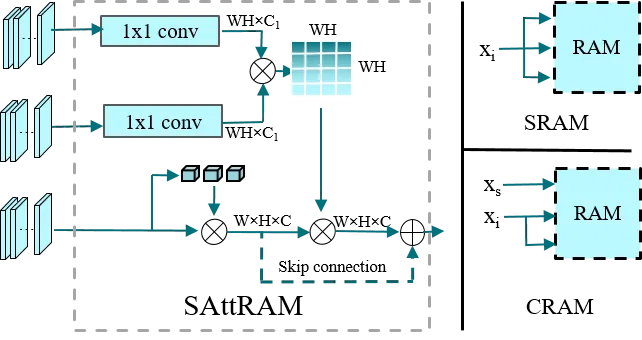
图4: CAM模块
在字体生成任务中,我们借鉴了类激活图(CAM)的思想,利用它来提取风格辨别注意力热图。为了获得风格辨别特征(M(x)),我们先将源字体(x)的解码特征图F(x)输入到带有权重的全连接层分类器中,用于域分类。然后,CAM通过线性加权求和计算注意力热图,其中M(x)表示在空间位置(H, W)处的注意力热图,Ωk代表特征图中通道(k)的权重,F(x)k表示在空间位置(HW)处的最后一个卷积层的通道(k)的特征图。然而,CAM存在缺乏空间注意力的问题,通常导致特征过度激活。为了解决这一问题并整合多模态特征,我们提出了自注意力精炼注意力模块(SAttRAM)。这个模块引入自注意力,通过捕捉空间依赖关系来优化像素级注意力热图,从而定义了精炼后的特征图。在处理图像生成中的多模态输入特征时,我们构建了两个变体注意力单元:自精炼注意力模块(SRAM)和交叉精炼注意力模块(CRAM)单元。SRAM:将图像特征作为输入,以获得关注特征,因为图像特征是图像转换中的基本信息。CRAM:捕捉图像特征和骨架特征之间的模态内交互,进一步优化从字符图像中提取的特征图。通过这些注意力模块的引入,我们能够更好地处理和整合多模态特征,从而提升字体生成任务的效果。
在字体生成任务中,我们使用两个判别器,D_i和D_s,来学习目标字体的风格。D_i评估生成的图像是否符合目标字体的风格,而D_s则评估生成的骨骼图的准确性。由于骨骼化过程不可微,我们采用预训练的skeleton-GAN来生成字符图片的骨骼图。这种引入skeleton-GAN的方法允许我们根据真实字形图片(RealY_t)和生成的字形图片(FakeY)生成相应的骨骼图,从而验证主生成器生成的FakeY的骨骼图的准确性。在字体生成任务中,内容损失和对抗损失是至关重要的组成部分。让我们深入探讨这两个方面的具体内容。内容损失包含两个关键部分:像素损失(L_{pix}),通过迫使生成的图像(GF(X_i, X_s))与目标图像(Y_t)相似,最小化像素间的差异,确保生成的字体在视觉上与目标字体一致;骨架一致性损失(L_{sc}),确保生成的字体在结构上与目标字体保持一致。我们利用预训练的skeleton-GAN(SG)生成字符图片的骨骼图,通过比较生成的骨骼图和目标骨骼图来计算损失。循环一致性损失(L_{cycle})源自CycleGAN论文,确保生成的字体能够在源风格和目标风格之间稳定转换,保证字体风格转换的一致性和稳定性。为了区分图片(X_i)的源风格和目标风格,促进精炼注意力模块的风格转换,我们引入了U-GAT-IT中的CAM损失,这里称为(L_{adv})。CAM损失有助于更好地捕捉和转换字体的风格特征。对抗损失(L_{adv})自然分为两部分:字形对抗损失通过判别器(D_i)评估生成的字体是否符合目标风格,促进生成更逼真的字体;骨架对抗损失(D_s)通过判别器(D_s)评估生成的骨骼图的正确性,确保生成的字体在结构上与目标字体一致。综合利用像素损失、骨架一致性损失、循环一致性损失、CAM损失和对抗损失,我们能够生成高质量、一致性的目标字体。希望这些技术细节有助于更好地理解字体生成任务中的关键要点。

图5: 实验结果
在我们的研究中,我们将提出的模型与几个代表性的生成模型进行了比较,包括zi2zi、CycleGAN、StarGAN和DG-Font。通过上述结果可以看出,我们的模型SE-GAN在处理毛笔字这种复杂字体时,展现出了强大的连笔生成能力。
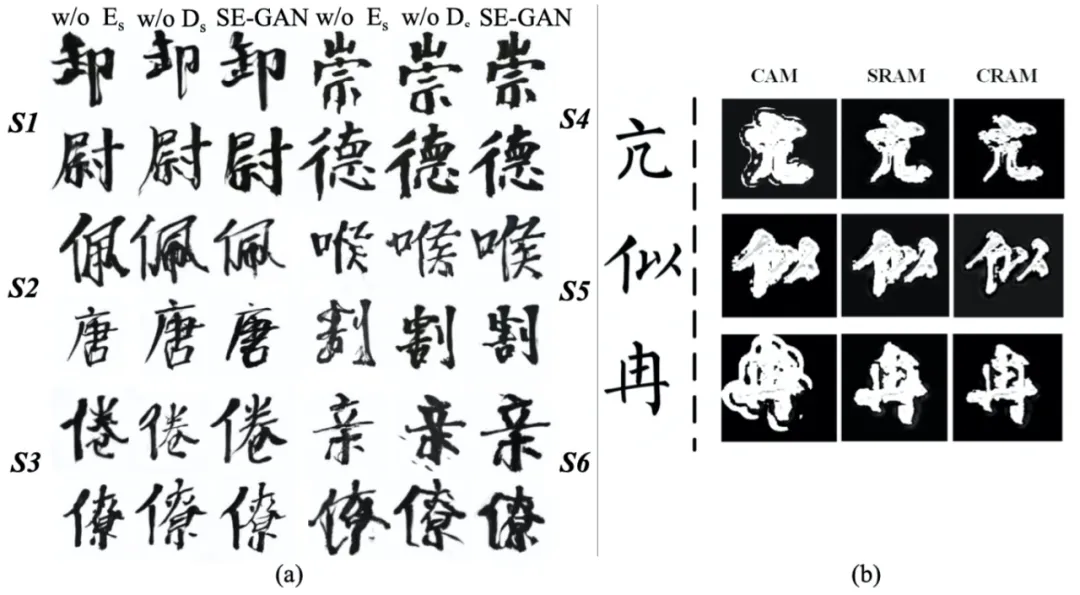
图6: 消融实验
在图5(a)中显示,如果缺少骨架信息,生成的字体可能会出现笔画残缺或夸大的问题。当去除(D_s)时,一些组件甚至可能混在一起,导致字体结构不清晰。从图5(b)可以观察到,相较于CAM,SRAM和CRAM表现出更少的过激活情况,并且覆盖范围更全面。特别是,CRAM学习到的字体形状比SRAM更准确,进一步验证了骨架在字体生成中的重要性。这些实验清晰地展示了骨架输入和判别器在提高字体生成质量方面的关键作用,同时也证实了即使在没有骨架信息的情况下,SAttRAM模块仍然具有显著的优势。
我们进行了两项用户研究。首先,我们评估了不同模型生成的字体图像的偏好得分。其次,我们将生成的字体图像与手写字体图像混合,要求用户选择视觉上最佳的字体图像。我们邀请了一些中央美术学院的学生参与人类评估,这些学生都是美术专业学生,拥有超过三年的书法经验。结果表明,我们的模型在用户偏好得分和专家评审的比赛中均取得最高分。

图7: 用户调研
尽管在当前阶段,GAN技术已经逐渐被深度学习中的Diffusion等新技术所取代,但是骨架的设计思路仍然具有启发意义。这种骨架思路可以在新的backbone结构中得到应用,如近期很火的diffusion,以进一步提升连笔生成的逼真度。通过将骨架的概念融入到新的backbone结构中,可以更好地指导生成过程,使得生成的连笔更加自然和真实。这种方法可以帮助模型更好地理解字体的结构和连接方式,从而生成更具艺术感和连贯性的毛笔字体。因此,尽管技术在不断演进,但是从骨架思路中汲取灵感,并将其运用于新的生成模型中,仍然能够为毛笔字体生成等任务带来新的突破和提升。这种思路的持续探索和应用有望为未来的生成模型带来更多创新和进步。
感兴趣也可以看看原论文:SE-GAN: Skeleton Enhanced GAN-based Model for Brush Handwriting Font Generation
文章来自于“AINLP”,作者“Yuan Shaozu”。




