# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
概览

论文标题:
MedUnA: Language guided Unsupervised Adaptation of Vision-LanguageModels for Medical Image Classification
论文链接:
https://arxiv.org/pdf/2409.02729
代码链接:
作者暂未公布
关键词:
Large Language Models,Vision-Language models
本文提出了一种名为MedUnA的方法,旨在解决医疗图像分类中因缺乏标注数据而导致的监督学习挑战。MedUnA利用视觉-语言模型(VLMs)中的视觉与文本对齐特性,通过无监督学习来适应医疗图像分类任务。该方法包括两个阶段:适配器预训练和无监督学习。在预训练阶段,使用大型语言模型(LLM)生成的描述对应类别标签,并通过BioBERT文本编码器生成文本嵌入,随后训练一个轻量级适配器来对齐这些文本嵌入与类别标签。在无监督学习阶段,将训练好的适配器与MedCLIP的视觉编码器集成,通过对比熵损失和提示调整来对齐视觉嵌入。实验结果表明,MedUnA在多种医疗图像数据集上显著提高了分类准确性。
作者通过MedUnA方法,为医疗图像分类领域提供了一种有效的无监督学习解决方案。他们利用VLMs的强大能力,通过语言引导的方式,实现了对未标注医疗图像的有效分类。具体贡献包括:
提出了MedUnA框架,将视觉与语言模型的无监督学习应用于医疗图像分类。
设计了适配器预训练和无监督学习两个阶段,通过语言描述来指导视觉嵌入的生成和对齐。
在多个医疗图像数据集上验证了MedUnA的有效性,显著提高了分类准确性。
Background
医疗图像分类是医学影像分析的重要任务之一,但由于标注数据的稀缺性,传统的监督学习方法面临巨大挑战。此外,医学图像数据的获取和标注需要专业知识和大量时间,限制了机器学习模型在医疗领域的应用。因此,无监督学习成为解决这一问题的潜在途径。然而,传统的无监督学习方法在医疗图像分类中效果不佳,需要探索新的方法。
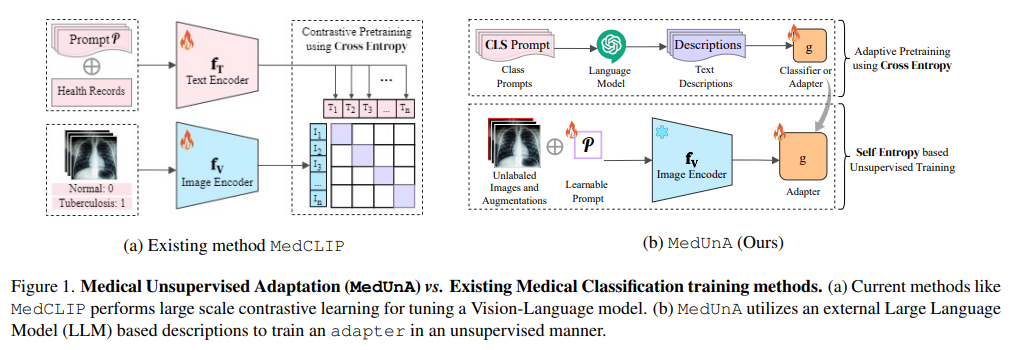
Method
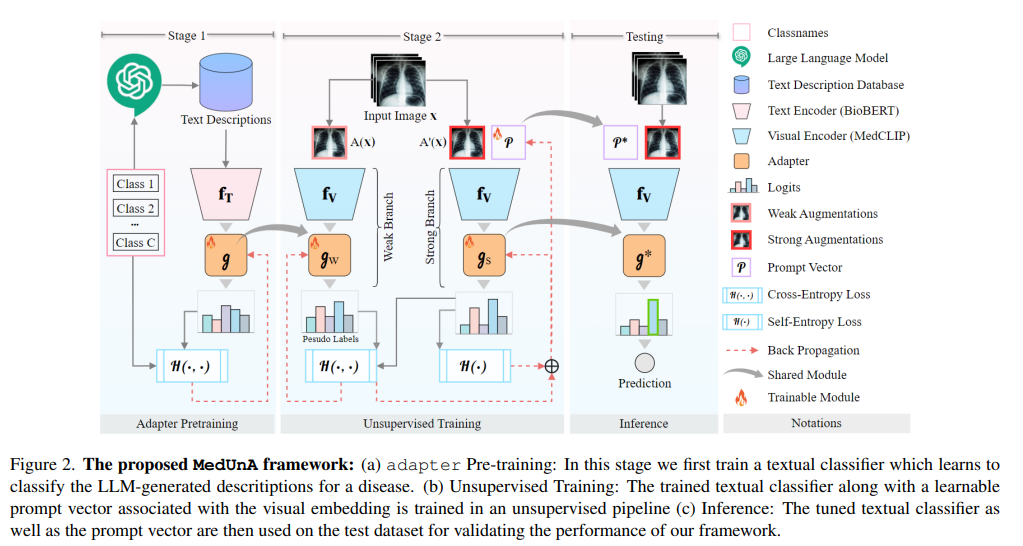
数据收集:从多个医疗图像数据库或合作医院收集未标注的医疗图像数据,确保数据的多样性和代表性。
标签描述生成:利用大型语言模型(如GPT-3)为每个类别标签生成详细的、上下文相关的自然语言描述。这些描述旨在捕捉类别的关键特征,以便在后续的文本嵌入中体现。
使用BioBERT(或其他适用于生物医学领域的预训练语言模型)对生成的标签描述进行编码,生成文本嵌入。BioBERT经过生物医学文本的训练,能够更好地理解医学领域的术语和上下文。
设计一个轻量级的神经网络适配器,该适配器接受文本嵌入作为输入,并输出一个与类别标签相对应的、经过优化的文本嵌入表示。
训练适配器以最小化文本嵌入与类别标签之间的某种度量距离(如余弦距离),确保适配器能够有效地将文本描述转换为对分类任务有用的表示。
将训练好的适配器与MedCLIP(或其他预训练的视觉-语言模型)的视觉编码器集成在一起。MedCLIP是一个强大的视觉-语言模型,能够在多模态数据(如图像和文本)之间建立有效的关联。
利用对比熵损失函数来优化视觉嵌入与文本嵌入之间的对齐。具体来说,通过比较正样本(即属于同一类别的图像和文本)和负样本(即不属于同一类别的图像和文本)之间的嵌入距离,来更新视觉编码器和适配器的参数。
目标是使正样本之间的嵌入距离尽可能小,而负样本之间的嵌入距离尽可能大。
引入提示调整机制来进一步增强视觉嵌入的表达能力。提示调整是一种通过修改输入数据(在这里是图像)来影响模型输出的技术。
在MedUnA中,可以使用自然语言提示(如“这是哪种类型的病变?”)作为图像输入的一部分,并通过调整这些提示来优化视觉编码器的输出。
提示调整可以与对比熵损失一起使用,通过迭代地优化提示和模型参数来改进分类性能。
在训练过程中,通过最小化自熵来确保生成的嵌入更加置信。自熵是衡量嵌入分布不确定性的一种指标;低自熵意味着嵌入具有较高的置信度。
通过在损失函数中加入自熵项,可以鼓励模型生成更加一致和稳定的嵌入表示,从而提高分类的准确性。
数据集选择:选择三个具有代表性的医疗图像数据集进行实验,包括胸部X光片(如ChestX-ray14)、眼底图像(如Diabetic Retinopathy Detection)和皮肤病变图像(如HAM10000)。
数据预处理:对图像进行标准化处理(如尺寸调整、归一化等),以确保输入数据的一致性。同时,对标签描述进行清洗和过滤,去除与分类任务无关的信息。
基线方法:选择几种具有代表性的无监督学习方法(如聚类算法、自编码器)和预训练的视觉模型(如ResNet、EfficientNet)作为基线方法进行比较。
参数设置:对MedUnA中的关键参数(如适配器大小、学习率、迭代次数等)进行调优,以获得最佳性能。
评估指标:使用准确率、召回率、F1分数和AUC等标准分类评估指标来评估MedUnA的性能。
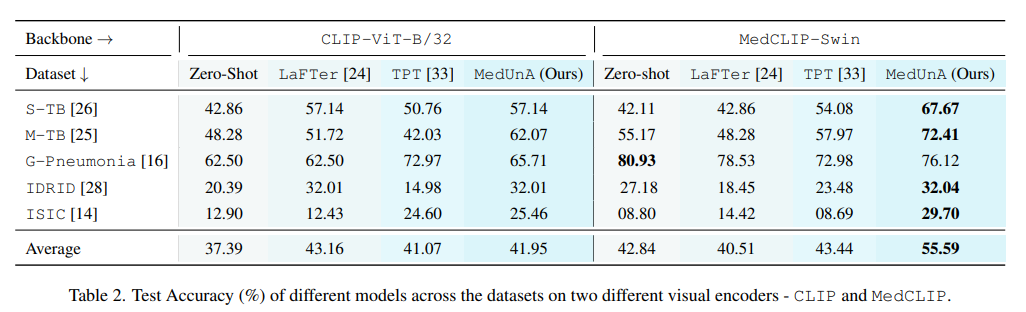
定量结果:展示MedUnA在三个数据集上的分类性能,并与基线方法进行比较。分析MedUnA在不同数据集上的表现差异及其原因。
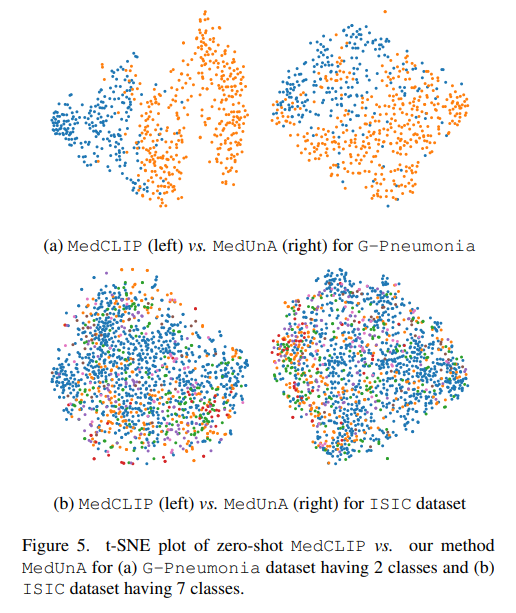
定性分析:通过可视化技术(如t-SNE或PCA)展示MedUnA生成的嵌入表示,分析不同类别之间的区分度和一致性。
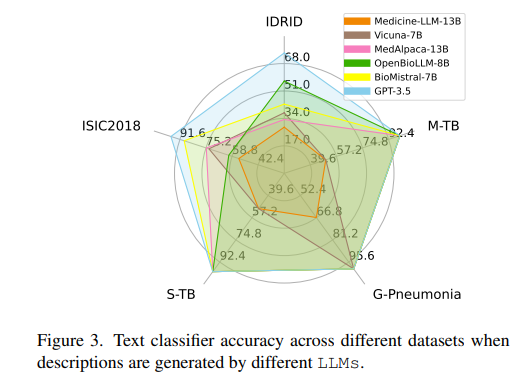
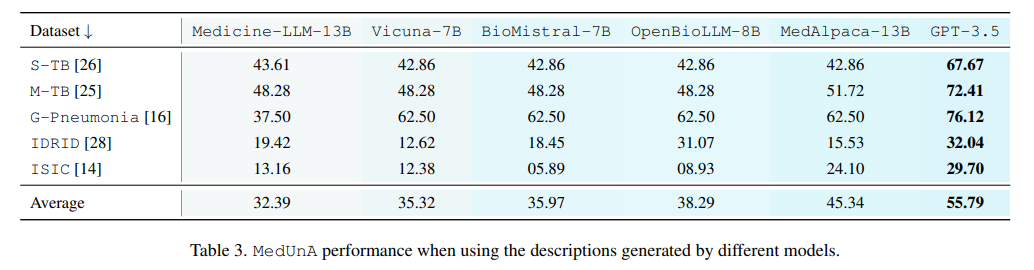
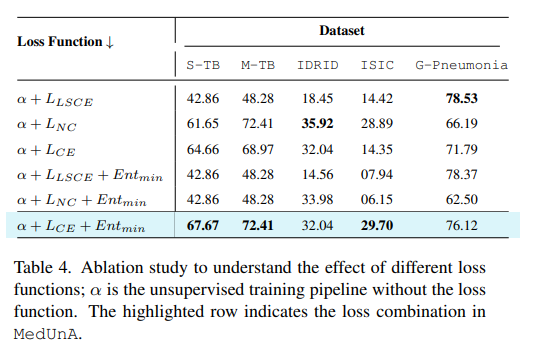
消融实验:进行消融实验来评估适配器预训练、对比熵损失优化、提示调整机制和自熵最小化等关键组件对MedUnA性能的影响。
错误分析:对MedUnA分类错误的样本进行分析,探讨其可能的原因和改进方向。
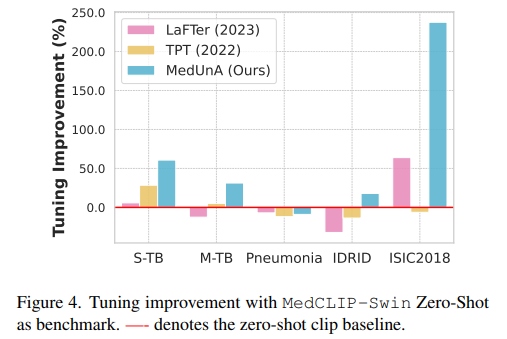
Conclusion
本文提出了一种基于语言引导的无监督视觉语言模型自适应医疗图像分类方法MedUnA。该方法通过利用VLMs中的视觉与文本对齐特性,实现了对未标注医疗图像的有效分类。实验结果表明,MedUnA在多个医疗图像数据集上均取得了显著的性能提升。该方法为医疗图像分类领域提供了一种新的无监督学习解决方案,具有广阔的应用前景。
Assignment
MedUnA的研究为医疗图像分类领域提供了新的思路和方法。它表明,通过利用VLMs的强大能力,并结合无监督学习技术,可以在缺乏标注数据的情况下实现有效的医疗图像分类。这一成果对于推动医疗影像分析技术的发展具有重要意义。同时,它也启示我们在未来的科研工作中,应更加注重跨学科融合和新技术探索,以应对更加复杂和具有挑战性的任务。
文章来自于微信公众号“AI智汇空间”,作者“小c”



【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
