# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
一场围绕大模型自研和创新的讨论,这两天在技术圈里炸了锅。
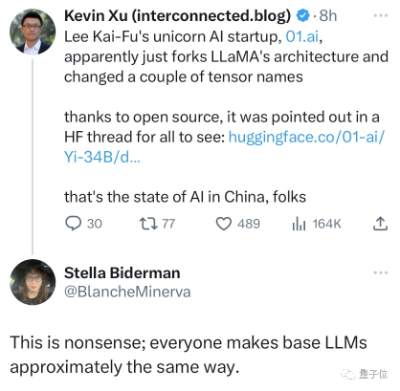
起初,前阿里技术VP贾扬清,盆友圈爆料吐槽:有大厂新模型就是LLaMA架构,但为了表示不同,通过改变开源代码名字、替换几个变量名……
一石激起千层浪,更晚一些时候,“大厂”被与零一万物关联,其刚发布的新模型Yi-34B被指与LLaMA架构如出一辙。
零一万物很快给出了说明和回应。但热议并未就此平息,甚至围绕大模型原创、自研的标准,开始被更进一步争论。
而初步激辩中指向的结论——冷峻又真实:
大模型的架构创新,可能早就死了。
好比烤鸭这道菜的菜谱公开之后,核心方法和步奏,都已经被固定了。
所以如果的大模型研发,都无法再在架构层面另起炉灶……那自研国产大模型,研它还能有啥用?
就在近日,贾扬清的吐槽,迅速火上了海外技术社区热搜。
并且很快,零一万物就被关联起来。
因为就在Yi-34B首次推出后,迅速横扫了各项中英文评测榜单,在英文领域也超越了Llama-2 70B和Falcon-180B等一众大尺寸大模型……一时风头无两、木秀于林。
贾扬清爆料之后,一封Hugging Face的邮件也对外曝光了,邮件核心内容,就是Yi模型与已经开源的LLaMA架构上存在重合,虽然张量命名不同,但按照开源社区的规则和规范,需要作出调整。
这也成为外界对于零一万物和Yi-34B模型自研性的质疑所在。
零一万物很快给出了说明和回应,核心有两点:
第一,Yi模型确实沿用了公开的架构,但和LLaMA一样,都基于的是GPT成熟结构。
第二,大模型的研发中,模型结构只是模型训练的一部分,还有包括数据工程、训练方法、baby sitting(训练过程监测)的技巧、hyperparameter设置、评估方法以及对评估指标在内的核心技术挑战和能力……在大量训练实验过程中,由于实验执行需求对代码做了更名,所以处于尊重开源社区的反馈,将代码进行更新,也为更好融入Transformer生态。
零一的回应,有人表示理解,比如开源社区领袖Stella Biderman,就认为说谁抄袭LLaMA是无稽之谈,因为所有做大模型研发的团队,现在都几乎“华山一条路”了。
但更多的激辩,还在持续。
激辩
辩论的核心话题,开始不断指向——如何定义大模型的创新?创新的标准该是什么?
在一则广为流传的群聊记录中,大模型领域知名“布道者”符尧博士,提出了现状和困惑。
他认为大模型主流架构,就是一个“天下诗歌不断抄”的过程。LLaMA的架构抄的Chinchilla,chinchilla抄的Gopher,Gopher抄的GPT3……每个都是一两行的改动。
而且在Hugging Face上,架构一模一样但名字不同的模型比比皆是……
但需要强调的是,大模型的创新或不同,核心应该关注的是训练方法和数据配比——而这些并不会反映在架构上。
以及如果严格来论,目前国内的自研大模型,不论是零一万物的Yi,还是百川智能的Baichuan,或者阿里旗下的通义千问,架构上和LLaMA都是一致的。
大模型的创新,看架构没有意义。
另一则广为流传的讨论,来自猴子无限的尹伯昊,他表示自己亲手玩过各类模型,自己也大模型从业,可以说说自己的看法。
第一,目前使用LLaMA架构已经是开原模型的最优解。因为LLaMA开源大模型已经实现了断崖式领先,有了大量工具链。国内外各种大模型的预训练,也都是保持了相同或相似的架构。
第二,相同的架构可以做出完全不同的模型,因为大模型的训练是一个充分的系统工程,考察的因素有很多,最后的能力和效果也与这个系统工程息息相关。
但尹伯昊也强调,大模型创业者没必要因为自研ego作祟,就不强调使用已有框架。
从现在的趋势来看,开源大模型生态的发展,其实有统一的架构,对于业内更多开发者的切换利大于弊。
实际上,上述圈内人的发言,也在进一步揭露大模型的现状和真相:
大模型架构创新,早就结束了。
大模型架构创新已死?
如果从大模型社区长期的发展过程来看,我们不难发现一种趋势——向通用化收拢。
因为基本上国际主流大模型都是基于Transformer的架构;而后对attention、activation、normalization、positional embedding等部分做一些改动工作。
简而言之,Transformer这个架构似乎已然是固定的状态。
有圈内团队举例,好比让不同的厨师都去做北京烤鸭,原材料和步骤定然是大同小异的(架构);而最终决定谁做出来的北京烤鸭更好吃,区别更多的是在于厨师本身对火候、烹调技术的掌握(数据参数、训练方法等)。
而这种讨论,几乎也打破了圈外对于热潮中“大模型创新”、“国产大模型”的某些期待,认为大模型的研发,可以完全另起炉灶。
事实是,架构层面,早就几近定型了。
OpenAI用GPT-3彻底点燃了大模型架构基础,LLaMA在GPT基础上作出了总结并且对外开源,其后更多的玩家,沿着他们的藩篱前行。零一万物在最新的声明中也表示,GPT/LLaMA 的架构正在渐成行业标准。
这种事实,也让更多围观这场争议和讨论的人联想到智能手机的系统往事。
当时iPhone发布,带来了闭源的iOS。
其后开源阵营中,Android在谷歌的大力扶植中上位,成功成为开源世界的第一名,并在其后真正成为了几乎“唯一的一个”。
所以GPT和LLaMA,是不是就是iOS和Android的重演?
然而区别于手机操作系统,国产大模型或许还会有不同。
正如在讨论中,大模型创新被强调的训练方法、数据配比,以及更加重要的开发者生态。
iOS和Android之时,完全是太平洋东岸的独角戏。
但现在,大模型热潮中,国产玩家其实面临机遇,如果能在初期就能被全球开发者认可,那最后获得话语权和更长远定义权的,一定是生态最强的那个玩家。
文章来自微信公众号 “ 量子位 ”,作者 金磊


【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda