# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
风口已来,“长风破浪会有时,直挂云帆济沧海。”
2023年的手机行业,已然来到了久违的路口。
据The Information报道,OpenAI CEO Sam Altman在与iPhone著名设计师Jony Ive讨论开发一种新的AI硬件设备的可能性,将行业内对AI大模型和手机结合的想象进一步推向高潮。联发科近日也宣布,天玑9300已在端侧落地70亿参数AI大预言模型,且成功在端侧运行130亿AI大预言模型。高通在今年发布的两款新品,骁龙 X Elite和骁龙 8 Gen 3芯片,更是分别对应了PC和智能手机代表的移动设备,宣布实现了百亿参数大模型的本地运行。
从云端,到终端。AI大模型的发展风起云涌,端侧落地大模型已成必然。业内一致认为,大模型“装进手机”有望成为用户体验大幅升级的一个新增长点。是否大模型只要上手机端,就可以抓住趋势一路长红?
把大模型装进手机只是第一道门槛,大模型的端上体验优化之路,才刚刚开始。
大千世界,会是“大模型”与“千人千面”么
11月16日,2023 OPPO开发者大会将在上海世博中心举行,届时将发布 ColorOS 14。与之同台亮相的AndesGPT,正是OPPO自主训练的大模型,包含十亿至千亿以上多种不同参数规模的模型规格,可灵活支撑多元化的应用场景。作为驱动OPPO公司AI战略的核心引擎,AndesGPT正全面赋能OPPO智慧终端,给用户带来全新的个性专属智能体验。
即将发布的AndesGPT突出了三个层面的标签:“千亿参数的对话增强语言模型”“具备知识、记忆、创作与工具能力的智能体”“端云协同全场景智能调度”。
事实上,“端云协同”成为了手机厂商们跨过“第一道门槛”的普遍思路,某种程度是行业推进大模型体验的一个必备要素。云端可以解决需要大算力、大参数模型场景下的问题,而手机端则负责数据安全性要求高、实时性要求高、弱网络环境等轻量化的大模型使用场景。AndesGPT也将面向智能终端革新技术架构设计,提供端云分工、端云互补、端云协作等多种工作模式。
而“个性专属”被放到了AndesGPT的定位层面。之所以强调“个性专属的大模型”,或是因为OPPO看到了手机端大模型的一条必然的进化之路——服务于每个消费者个体,实现真正“千人千面”的体验。
11月7日,AI界的“科技春晚”、OpenAI开发者大会宣布了一系列GPT-4 Turbo的升级。正如参加大会的科技博主Dan Shipper写到:“ OpenAI使任何人都可以轻松构建自己的自定义ChatGPT版本,内置私人数据——无需编程。任何人都可以设置一个ChatGPT版本,具有自己的个性和访问私人知识的能力。这是一个重大进展。”
OPPO要做的,也正是行业的头部玩家正在做的,是在大模型这个层面做到真正的个性专属。并且基于对话这个最常用的沟通方式,做定向的增强。
长路收获,来自一个前行已久的方向
AndesGPT作为OPPO安第斯智能云团队主力打造的基于混合云架构的生成式大模型,它重点打造了在中文对话数据中持续学习、指令微调、人工反馈的强化学习以及知识增强的能力。
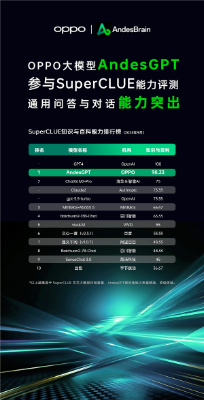
在SuperCLUE 9月十大基础能力排行榜中,OPPO安第斯大模型 (AndesGPT)“知识与百科”能力仅次于GPT4,为国内大模型第一名,“角色扮演能力”排名前三。
OPPO曾对外提出大模型不做toB,而是toC。通过融合“用户画像、情境感知、个人数据”等信息,为用户提供“个性化可定制专属体验”。希望令用户感受到大模型是个性专属、为他专门定制的,以最大程度地满足用户对大模型的需求和期待。
如,OPPO手机上的小布助手,就是大模型“个性专属”能力落地的一个重要应用。在AndesGPT的加持下,小布基于与不同用户的沟通中沉淀下来的记忆特征,给出千人千面的个性化推荐和主动建议、还有内容生成创作。不必每次反复描述自己的需求,小布就能贴心地想到你的每一个偏好。
每次累积,也是AI技术的累进
安第斯智能云在数据、人力、算法、算力等多个维度,早早就为AndesGPT沉淀了优势。
自2020年起,安第斯智能云团队就已开始对预训练语言模型进行探索和落地应用,并自研了一亿、三亿和十亿参数量的大模型OBERT,OBERT也曾一度跃居中文语言理解测评基准CLUE1.1总榜的第五名以及大规模知识图谱问答KgCLUE1.0排行榜第一名。
而在数据方面,OPPO在构建月活过亿的C端产品小布助手的过程中,也已经完成了大规模高质量语料数据的积累;并依托对全球6亿用户的服务,完成了端云用户画像、情境感知等相关基础数据的积累。
布局时间,不争先只种因
OPPO其实对AI这条技术路线一直保有着“长期主义”的定力。消费电子是承载智能体的重要领域,智能体也会帮助消费电子迈向新的发展阶段。
在研发的前期,OPPO的开发人员在大模型的底层上孜孜不倦反复推演,为的是能够在研发路径上有更深、更细的积累。“不争先”,让技术更加脚踏实地,包括了“预训练、指令微调、人类反馈强化学习、海量中文对话数据、精品知识图谱、高质量QA问答数据”等等复杂的技术实践。
据今年7月的一篇技术文章,OPPO的预训练大模型解决方案主要采取的方法是知识增强。知识增强可以理解为数据增强。且预训练模型缺乏先验知识,因此融入知识到预训练模型是一个非常有效的办法。在做模型预训练时,OPPO也更建议基于开放域语料,使用开放域的知识图谱,去帮助模型提升整体泛化能力。
在数据体量方面,OPPO研究院构建了将近5.56亿的一个高质量知识图谱,并从“预训练”和“知识融入”两个模块来将知识更好地融入到预训练模型中。
并且,作为行业领先的智能终端厂商,依托服务全球6亿用户的经验、多年的相关技术沉淀,OPPO已然搭建起了坚实的大模型技术底座。
回看过去10年的消费电子,“智慧”的表述也曾经出现,但"智"的属性更多体现在随想随取,猜你所想。而未来大模型下的智能体,则是法律安全框架下的自主感知,自主决策,主动行为。更加拟人化,人性化的智能体会呈现出更加多样化的形态和功能,满足不同领域和行业的需求。高效、可靠,能够在更短的时间内完成更多的任务,同时也能更好地保证任务的准确性和稳定性。
OPPO未来将把大模型能力与智能体结合,深入布局到各终端产品和系统应用的底层架构中,带来全新的智能交互体验。作为OPPO对话式智能助手和超级终端入口,小布助手也被认为是安第斯大模型应用落地的最佳实验场和技术突破口。
“智”向未来,风物长宜放眼量
展望未来,AI大模型在手机端仍然有着非常广阔的发展空间,类似“全新小布“这样的AI App和智能体应用也会越来越多。不必多言, 机 商天然具有打通软硬件底层能 的优势,OPPO作为头部品牌也将和开发者一起,不断将大模型技术结合Agent落地为用户的实际体验,把自身对大模型的思路和技术生态的助力分享给行业与用户。
即将到来的ODC引起了业内的普遍期待,OPPO将如何打造“个性专属的大模型服务”,又将如何在大模型的技术生态中定位自身的价值和角色?
也许OPPO为这些问题准备的答案,将会带来全新的想象和灵感。
文章来自 “ 中国科学网 ”



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner