# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在全球人工智能(AI)计算竞争中,甲骨文(Oracle)与英伟达联手,希望在2025年达成一个前所未有的计算能力目标——实现多ZettaFLOPS(即每秒进行千万亿次浮点运算)的计算性能。
不仅超越了市场上现有的任何AI计算平台,也标志着云计算与AI技术发展的巨大进步,甲骨文的这一计算蓝图,从硬件部署、网络架构、冷却技术和能源供给等方面,分析其面临的挑战与未来的可能性。

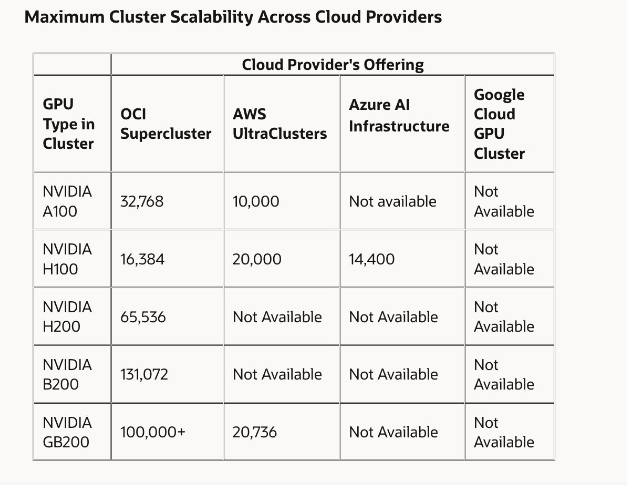
甲骨文计划在2025年实现多ZettaFLOPS的计算能力。这一目标将通过其Oracle Cloud Infrastructure(OCI)超级集群来实现。
以下是计划的关键部分:
● OCI超级集群将使用H100 GPU,扩展至16,384个GPU,实现约65 ExaFLOPS的性能。
● 配备H200 GPU的超级集群将进一步扩展到65,536个GPU,性能将提升至260 ExaFLOPS。
● OCI正在接受订购,提供配备最多131,072个NVIDIA Blackwell GPU的AI超级计算机,预计峰值性能将达到2.4 ZettaFLOPS。
● 利用NVIDIA的GB200 NVL72液冷裸机实例,OCI超级集群将通过NVLink和NVLink Switch实现高达129.6 TB/s的通信带宽。
甲骨文的目标是超越现有的超级计算机,并通过创新的技术在网络架构和扩展策略方面领先,力争成为AI计算领域的领军者。
甲骨文计划在其超级集群中使用NVIDIA Blackwell GPU作为核心组件。相比于之前的NVIDIA HGX B200平台,NVIDIA GB200 NVL72拥有更强的推理计算能力和改进的冷却设计,支持更密集的部署。
为了保证GPU集群间的数据交换快速高效,甲骨文采用NVIDIA Quantum-2、RoCEv2网络协议,以及NVIDIA ConnectX-7和ConnectX-8 SuperNIC网络适配器。
这种高带宽、低延迟的网络架构是实现多ZettaFLOPS计算目标的关键。

在大规模GPU部署中,冷却和能源管理至关重要。
甲骨文计划使用液冷技术来提高冷却效率,降低能耗,从而使数据中心更加环保和可持续。甲骨文还在考虑使用小型核反应堆为数据中心供电的可能性。
随着计算能力的增长,传统的电力供应可能无法满足需求。小型核反应堆可以提供稳定高效的能源,但在实施过程中还需克服监管障碍。
实现ZettaFLOPS级别的计算能力将促进更复杂的深度学习模型开发,提高AI推理能力,并支持更大的实时数据处理需求。这将有助于加快AI模型的训练,推动自动驾驶、自然语言处理、医疗健康等领域的进步。
甲骨文将能够在AI云服务市场中占据有利位置,为用户提供更多选择和灵活的部署选项,帮助他们在数字化转型中取得成功。
甲骨文的计划更为激进,不仅追求单节点的计算能力,还通过集群化提升整体计算水平。甲骨文能否按期实现目标,取决于其在硬件采购、网络设计、能源供应等方面的协调与创新。
小结
甲骨文与英伟达的合作正在将AI计算推向新高度,AI算力的基础设施还在继续投入。
文章来自于微信公众号“芝能芯芯”



