# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
高质量音乐生成、高灵活音乐编辑,Seed-Music 再次打开了 AI 音乐创作的天花板。
放假期间,本 i 人又领教了被 e 人支配的恐惧。
跟 e 人朋友出门玩,先被拉去饭局尬聊,再和陌生人组队打本,下面这首歌真是唱出了 i 人心声。

后两天假期就舒服多了。通关了黑神话悟空还不过瘾,我在家补经典 86 版的《西游记》。无论多少次重温,还是会被大圣的魅力吸引。

这歌怎么样,是不是感觉斗战胜佛活灵活现,如在眼前?
实际上,两首歌都并非真人所作,而是全靠字节最新发布的音乐大模型 ——Seed-Music。
Seed-Music 官网:https://team.doubao.com/seed-music
据豆包大模型团队官网介绍,Seed-Music 是一个具有灵活控制能力的音乐生成系统,包含 Lyrics2Song、Lyrics2Leadsheet2Song、Music Editing、Singing Voice Conversion 四大核心功能,具体涵盖十种创作任务。
刚发布,Seed-Music 就已经在海外平台引起了关注。
有音乐人表示:“(Seed-Music)生成的音乐质量比同类模型都高出一筹。已经期待它能作为一项服务被使用。”
虽说 AIGC 很火,但相较于语音合成、文本生成,音乐生成面临着更为复杂的挑战。
目前,业界在 AI 音乐领域的研究主要集中在以下几个核心问题:
无论是传统的音乐辅助创作工具,还是当下热门的 AI 音乐生成的研究和产品,面向上述问题,均还处于摸索阶段。
比如针对音乐信号复杂性,Google、Meta、Stability AI 等各家在音频、演奏、曲谱层面上做了建模尝试,效果各有优缺,而且各家的评估方法均有局限,人工评测仍必不可少。
面对这些挑战,字节 Seed-Music 采用了创新的统一框架,将语言模型和扩散模型的优势相结合,并融入符号音乐的处理。

通过官方视频展示,我们发现,与其他音乐模型相比,Seed-Music 能更好地满足不同群体的音乐创作需求。
我们仔细研究了 Seed-Music 的音乐生成 demo,发现其能力真・丰富多样,且 demo 人声效果逼真度,绝了。
接下来,我制作成几个短视频,向大家直观展示下效果。
对于专业音乐人来说,使用 AI 工具辅助创作,最大痛点莫过于无法对音乐进行编辑。
Seed-Music 创新点之一,在于能通过 lead sheet(领谱)来编辑音乐,这增加了音乐创作可解释性。
在官方视频的 Lead2Song 部分,可以看到同一版歌词,通过领谱增减音轨、改变输入风格后,就能得到不同结果的歌曲,显著提高模型的实用性。
除领谱外,Seed-Music 也能直接调整歌词或旋律。比如,“情人节的玫瑰花,你送给了谁 / 你送给别人”,歌词修改前后,旋律保持不变,音乐的连贯性得以保持,过渡效果非常平滑。

即使是音乐小白,Seed-Music 也提供了简单有趣的创作场景。
文生音乐这一必备能力,自然少不了。
输入内容除了文本,也可以是音频,它能基于原曲输出续作或仿作。下面这首英文歌曲“摇身一变”,仿写成了中文古风歌。

哪怕输入临时录制的 10 秒人声, Seed-Music 的零样本音频转换技术都能够将其转化为流畅的声乐。
惊喜的是,Seed-Music 能将中文人声输入转换为英文声乐输出,实现了跨语种人声克隆,扩大了音乐小白们的创作空间。


那为什么 Seed-Music 能做到生成高质量音乐、提供灵活编辑能力呢?
来自豆包大模型团队的研究者们表示,这主要得益于统一框架,关键技术贡献如下:
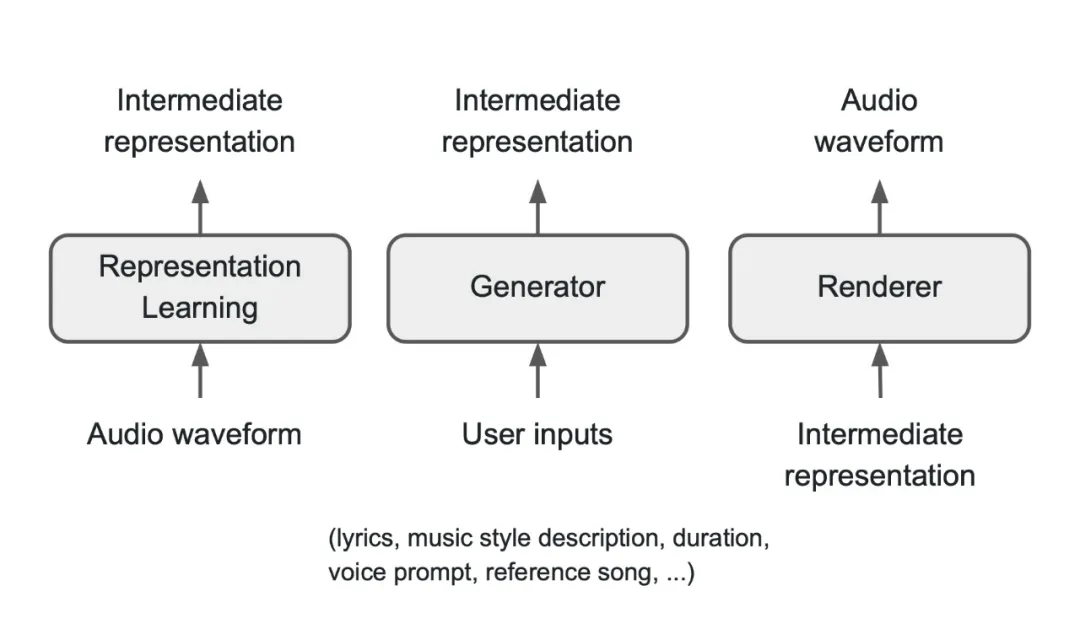
Seed-Music 架构
根据官方论文,如上图所示,从高层次来看 Seed-Music 有着统一的音乐生成框架,主要包含以下三个核心组件:一个表征模型,用于将原始音频波形压缩成某种压缩表征形式;一个生成器,经过训练可以接受各种用户控制输入,并相应地生成中间表征;一个渲染器,能够从生成器输出的中间表征中,合成高质量的音频波形。
基于统一框架,Seed-Music 建立了三种适用于不同场景的中间表征:音频 token、符号音乐 token 和声码器 latent。

Seed-Music pipeline
如图所示,中间表征对整个系统来说很重要,每种表征都有其特点和适用场景,具体选择取决于用户的音乐创作任务。
在上述链路中,Seed-Music 经历三个训练阶段:预训练、微调和后训练。预训练旨在为音乐音频建模建立强大的基础模型;微调包括基于高质量音乐数据集的数据微调,以增强音乐性,或者针对特定创作任务提高可控性、可解释性和交互性的指令微调;后训练是通过强化学习进行的,从整体上提高了模型的稳定性。
此外,在推理时,样本解码方案对于从训练模型中诱导出最佳结果至关重要。研究者们同时会应用模型蒸馏和流式解码方案来提高系统的延迟。
回顾过往,新技术往往能够激发新创新。可以看到,Seed-Music 将音乐生成自然地嵌入不同创作群体的工作流中,使 AI 音乐具备独特的社交属性,这是其与传统音乐创作模式的不同之处。在未来,或许会由此涌现创作音乐、欣赏音乐、分享音乐的新场景。
就目前观察到的业界各玩家动向来说,Meta 和谷歌在 MusicGen 和 MusicLM 论文发布、Lyria 短暂内测之后,暂无更多消息放出。Suno、Udio 更为活跃,正侧重于改善效果。Seed-Music 此番在技术研发层面提供了更多可能。
期待 Seed-Music 乃至 AI 产业各类玩家能在未来获取更多突破。
最后,欢迎对 Seed-Music 感兴趣的朋友访问豆包大模型团队官网 https://team.doubao.com/seed-music,了解更多相关的信息。
文章来自于微信公众号“机器之心”



【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
