# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
实话说,我一直没想明白阿里为什么会在大模型这个赛道,成为中国版的Meta。
扎克伯格被问及为什么要做开源大模型时说,“我们的商业模式并不是靠卖模型赚钱“。显然,Meta没有云平台产品,就算要卖模型赚钱,效率也不高。
而阿里就不一样了,背靠阿里云,如果把通义千问完全闭源,放到阿里云上提供API&大客户定制,营收可能会很可观。但阿里不仅没这样做,而且根据笔者对通义千问团队的了解,其对于通义千问持续开源这件事儿是非常坚决的。
这个坚决可不是口号,你在今天的云栖大会上就能感知到这块的信号有多强烈。

要我说,这绝对是AI史上最大一波开源发布会了——
本次Qwen2.5开源全家桶包括:
详细的参数可以见这张表:
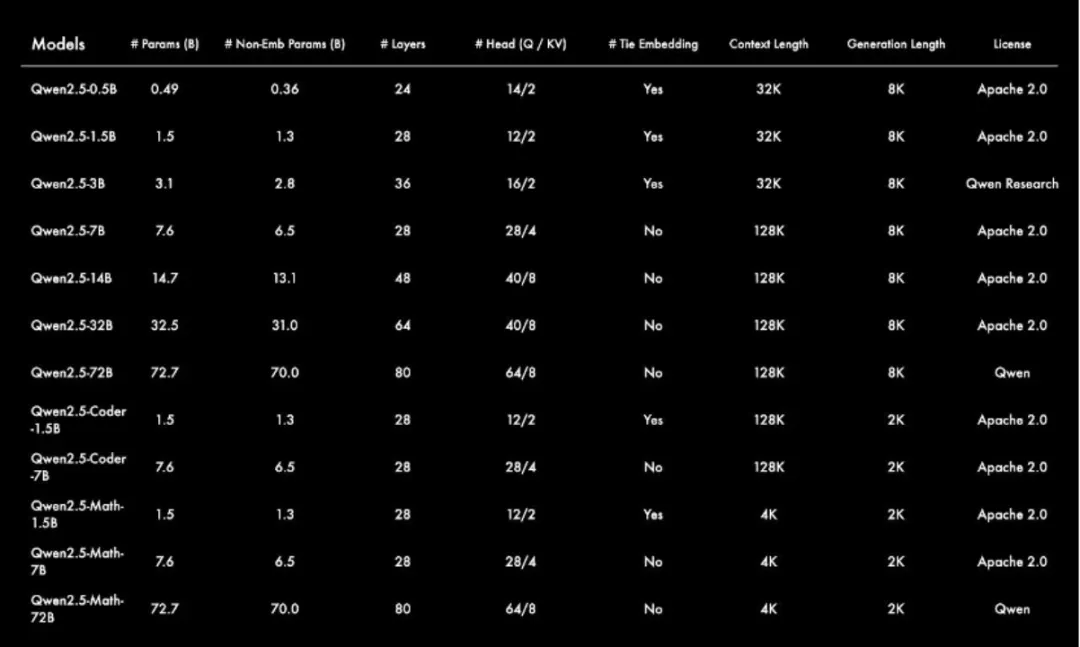
看到这里你可能会问,一下子开源了这么多不同参数规模的模型有啥用呢?
如果你做过AI大模型的落地就懂这里的意义了。比如,0.5B参数规模适合极致低功耗场景,如耳机、鼠标等;3B则是适配手机等端侧设备的黄金尺寸;32B是最受开发者期待的“性价比之王”,可在性能和功耗之间获得最佳平衡;72B是开源旗舰版本,适配企业级和科研级的应用场景。
而Qwen2.5系列模型不仅落地场景覆盖的全,在模型能力上,上限也又一次被推高了:
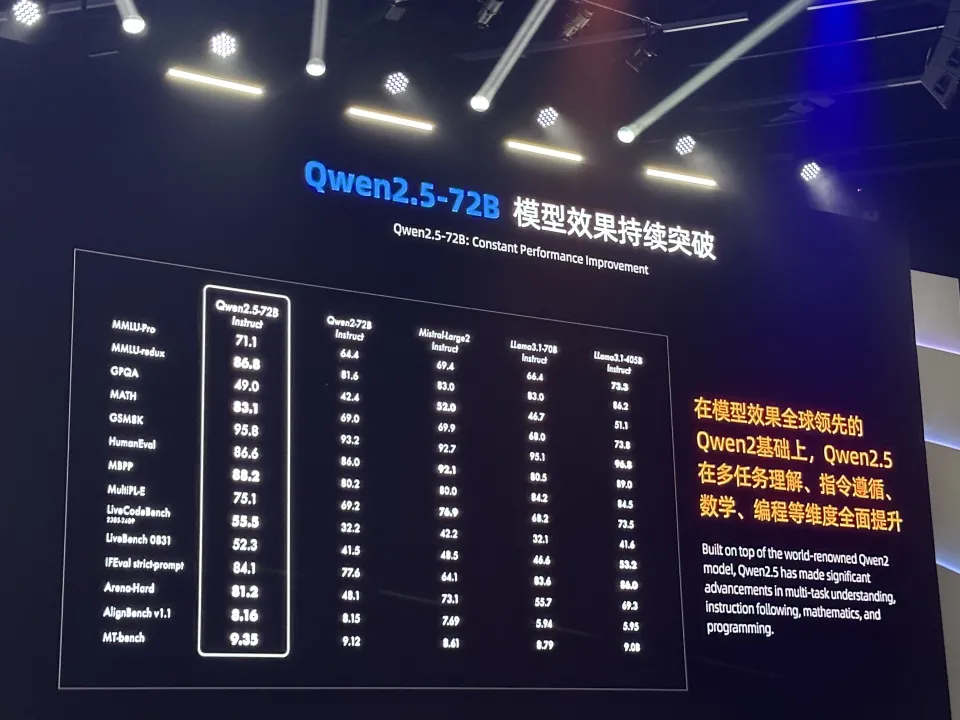
在诸多公开的测试基准上,Qwen2.5-72B Instruct模型的表现也完全不逊Meta家的旗舰开源模型——Llama 3.1-70B Instruct。甚至综合评比之下,打过了Llama3.1-405B Instruct版本。
而站在2024来说,大家都知道,今年不仅是AI应用元年,而且也是多模态元年。
在多模态大模型的开源上,阿里这次也不负众望,时隔1年,终于发布了第二版VL模型。

好家伙,上一次开源的还是一个2B/7B版本,这一波直接搞了个72B的真·大规模视觉语言模型。
Qwen2-VL-72B不止具备图片理解能力,甚至支持20分钟以上的长视频理解,而且具备实时识别物体、视觉推理和跨语言的能力。说其视觉理解能力已经超越了GPT-4o的水平完全不夸张。
如果你以为这就结束了,那就太天真了。连我也没想到,这一把还开源了数学模型和代码模型。

来,我们跑个“难倒全世界顶尖AI”的「经典数学题」——
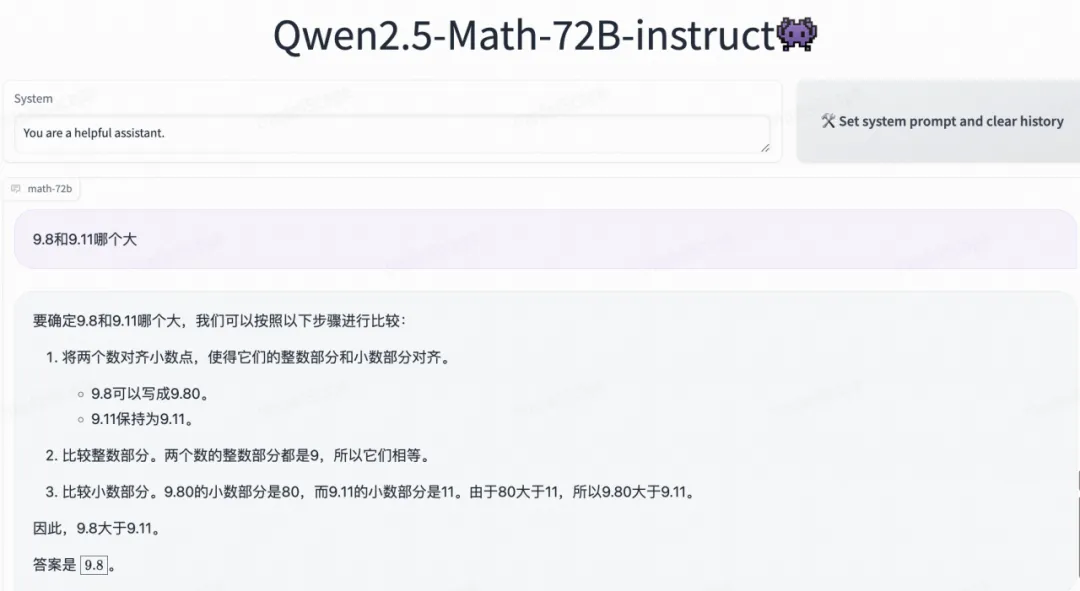
感人,不仅回答对了,而且推理的头头是道。
相比之下,近期大火的OpenAI O1模型在这个问题上有时都会犯糊涂:

对于Qwen2.5-Math模型来说,其强调通过链式推理(Chain-of-Thought, CoT)和工具集成推理(Tool-Integrated Reasoning, TIR)来解决复杂的数学问题。包括生成解题步骤和利用外部工具(如 Python 解释器)来辅助计算。这种方式可以有效减少LLM不确定性推理导致的非精确计算问题,因此对于数学等高度依赖确定性推理的落地场景来说,训一个专用模型会比直接使用通用的语言模型更可靠。
对Qwen-Math模型技术细节感兴趣的小伙伴可以看官方今天刚放出的论文:
https://arxiv.org/pdf/2409.12122
而要说到本次云栖大会上官宣的代码模型Qwen-Coder,那就更有意思了。

点开Qwen-Coder的论文,你会在第一页看到这么一张图:
好家伙,就差把“十一边形战士”贴标题里了。
在预训练的层面,QwenMath和QwenCoder的训练思路很像,两个模型都采用了混合数据策略,将代码、数学和一般文本数据结合起来,以平衡模型在特定领域(如数学或编程)和通用语言理解方面的能力。并且通过弱模型分类器和评分器来过滤掉低质量的内容。
此外,要知道,代码场景对context的长度要求是很高的,动辄丢个代码库进去,因此Qwen2.5-Coder 则通过 YARN 机制和 repo-level 预训练来增强了长文本处理能力。
预训练之后,QwenCoder则主要通过指令调优(instruction tuning)来提高其在编程任务上的表现。
关于QwenCoder的技术细节,可以参考官方今天刚放出的论文:
https://arxiv.org/pdf/2409.12186
虽然这个问题是聊开源的。但我觉得免费给C端用户开放(B端有商用API)的旗舰模型通义千问Max,这次也必须提一下。
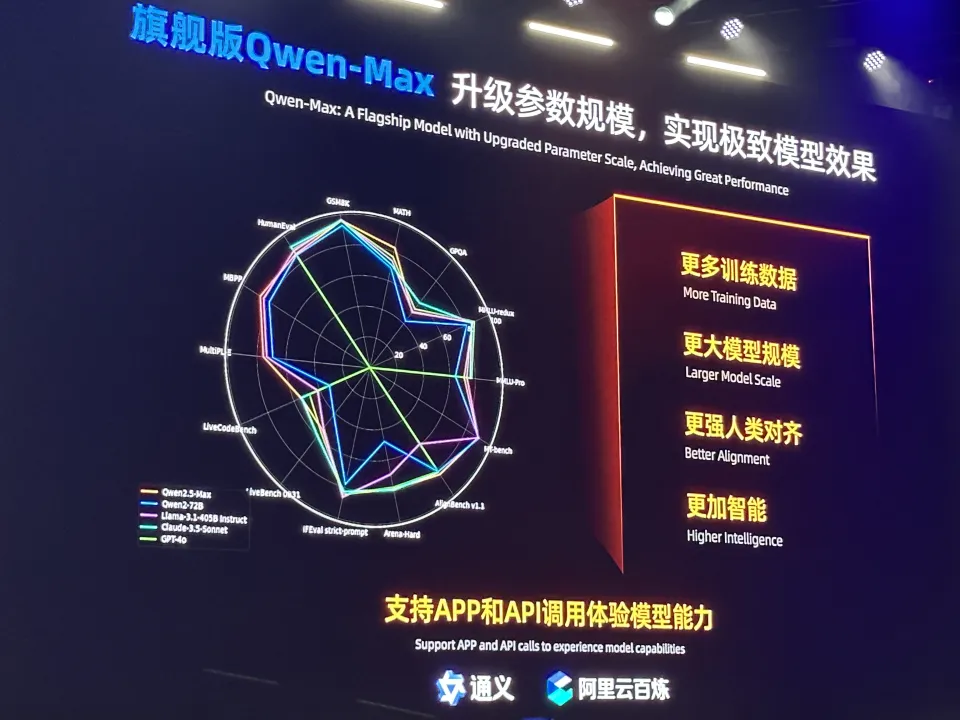
在通义APP的背后,就是这个模型。这个模型可以说是通义千问系列模型中旗舰模型,效果最好,当自然,最好的东西是最贵的。(尽管横向比较的话,已经非常划算了)。
但好在,本次云栖大会上还放出了两个效果不比Qwen-Max模型差多少,但是价格却非常友好的平替API:

简单来说,如果你的落地场景对模型能力要求很高,那么就用Qwen-Plus,否则可以用Qwen-Turbo。
这俩模型API有多便宜呢?看这张图就很直观了:
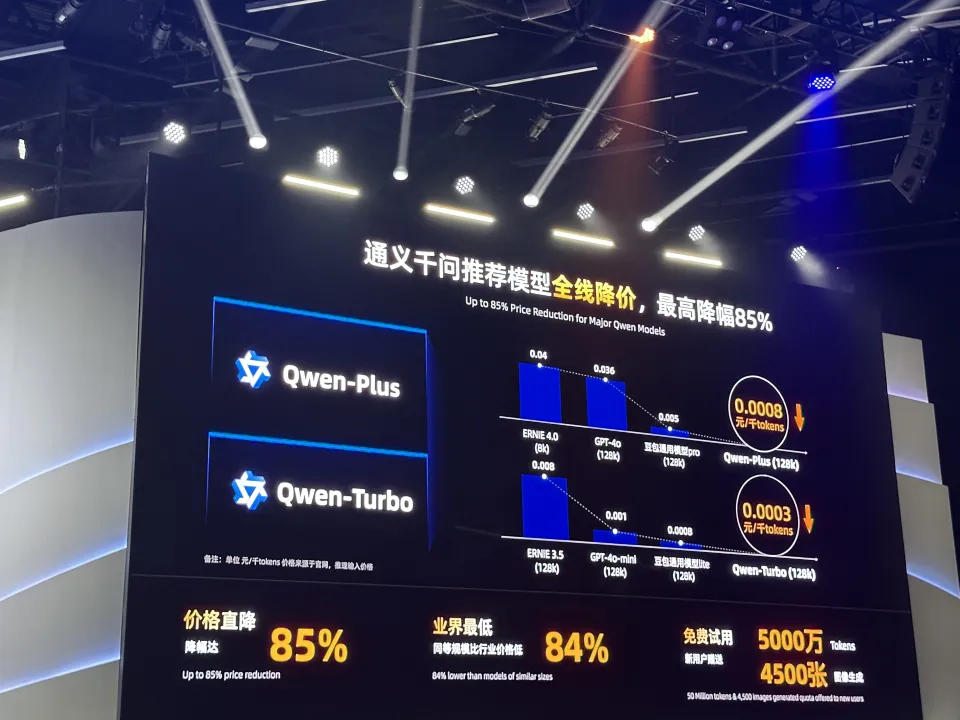
好家伙,这性价比直接卷哭海内外大模型厂商。
除此之外,本次云栖大会还有文生视频产品“通义万相Wanx”、录音转写产品“听悟”、通义PPT创作、编程助手通义灵码、翻译助手等一系列产品的重磅发布、版本升级。篇幅所限就不一一列举了。
总之,都讲到这里了,我真心觉得题主的这个问题都要改一改了——
以阿里目前在AI大模型和AI产品赛道上的疯狂程度来说,
问“能不能追赶上Meta”,属实有点看低阿里在这个事儿上的步伐和野心了。

文章来自于“夕小瑶科技说”,作者“夕小瑶编辑部”。




【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
