# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
前段时间技惊四座、剑指GPT-4o的实时语音模型Moshi,终于开源了!
自然聊天,情绪丰富,随意打断,拒绝呆板和回合制!
大神Karpathy体验之后也表示:nice~
来自法国的初创团队Kyutai,于7月初发布了这个对标GPT-4o的神奇的端到端语音模型。
2个多月后的今天,他们兑现了自己的承诺,将代码、模型权重和一份超长的技术报告一股脑开源。

论文地址:https://kyutai.org/Moshi.pdf
开源代码:https://github.com/kyutai-labs/moshi
开放权重:https://huggingface.co/collections/kyutai
在海的那一边,GPT-4o的语音模式还没有完全端上来,这边的模型已经免费送了。
大家可以去官网(moshi.chat)在线免费体验,相比于平时你问我答的AI语音助手,这种「像人一样」的聊天方式还是很奇特的。
整个模型的参数量为7.69B,pytorch平台上只有bf16版本,如果在本地跑的话对显存有一定要求,而candle上提供了8bit版本,mlx上更是有4bit版本可供使用。
moshiko和moshika表示男声和女声两个版本
moshi作为一个全双工口语对话框架,由几部分组成:首先是Mimi,目前最先进的流式神经音频编解码器,能够以完全流式的方式(延迟80毫秒)处理24 kHz音频(12.5 Hz表示,带宽1.1 kbps)。
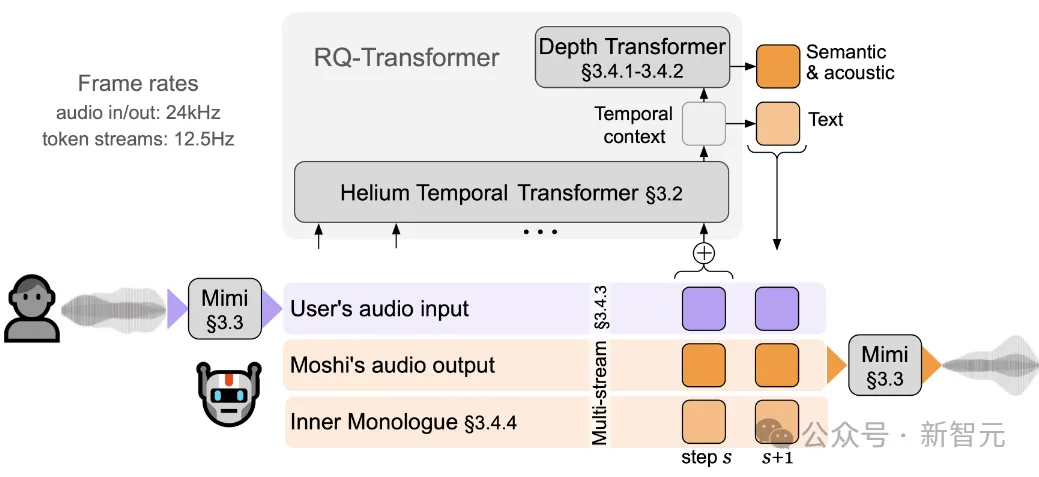
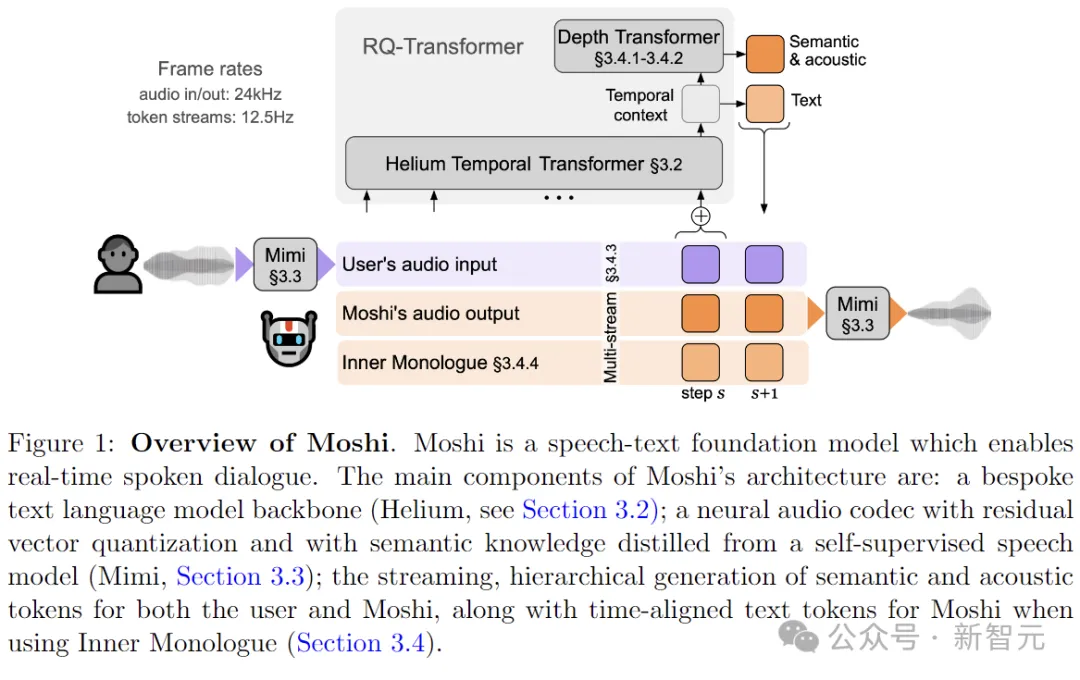
然后是负责知识储备、理解和输出的Transformer部分,包括Helium Temporal Transformer和Depth Transformer。
其中小型的深度Transformer负责对给定时间步长的码本间依赖性进行建模,而大型(7B参数)时间Transformer对时间依赖性进行建模。
作者还提出了「内心独白」:在训练和推理过程中,对文本和音频进行联合建模。这使得模型能够充分利用文本模态传递的知识,同时保留语音的能力。
Moshi模拟两种音频流:一种来自Moshi自身(模型的输出),另一种来自用户(音频输入)。
沿着这两个音频流,Moshi预测与自己的语音(内心独白)相对应的文本,极大地提高了生成的质量。
Moshi的理论延迟为160毫秒(Mimi帧大小80毫秒 + 声学延迟80毫秒),在L4 GPU上的实际总延迟仅有200毫秒。
技术细节
Moshi突破了传统AI对话模型的限制:延迟、文本信息瓶颈和基于回合的建模。
Moshi使用较小的音频语言模型增强了文本LLM主干,模型接收并预测离散的音频单元,通过理解输入并直接在音频域中生成输出来消除文本的信息瓶颈,同时又可以受益于底层文本LLM的知识和推理能力。
Moshi扩展了之前关于音频语言模型的工作,引入了第一个多流音频语言模型,将输入和输出音频流联合显式处理为两个自回归token流,完全消除了说话者转向的概念,从而允许在任意动态(重叠和中断)的自然对话上训练模型。
首先介绍负责文本部分的Helium,这里采用了一些比较通用的设计。
比如,在注意力层、前馈层和输出线性层的输入处使用RMS归一化;使用旋转位置嵌入(RoPE)、4,096 个token的上下文长度和 FlashAttention来进行高效训练;使用门控线性单元,SiLU作为门控函数。
Helium的分词器基于SentencePiece的一元模型,包含32,000个主要针对英语的元素。
作者将所有数字拆分为单个数字,并使用字节退避来确保分词器不会丢失信息。使用AdamW优化器训练模型,先采用固定学习率,然后进行余弦学习率衰减。
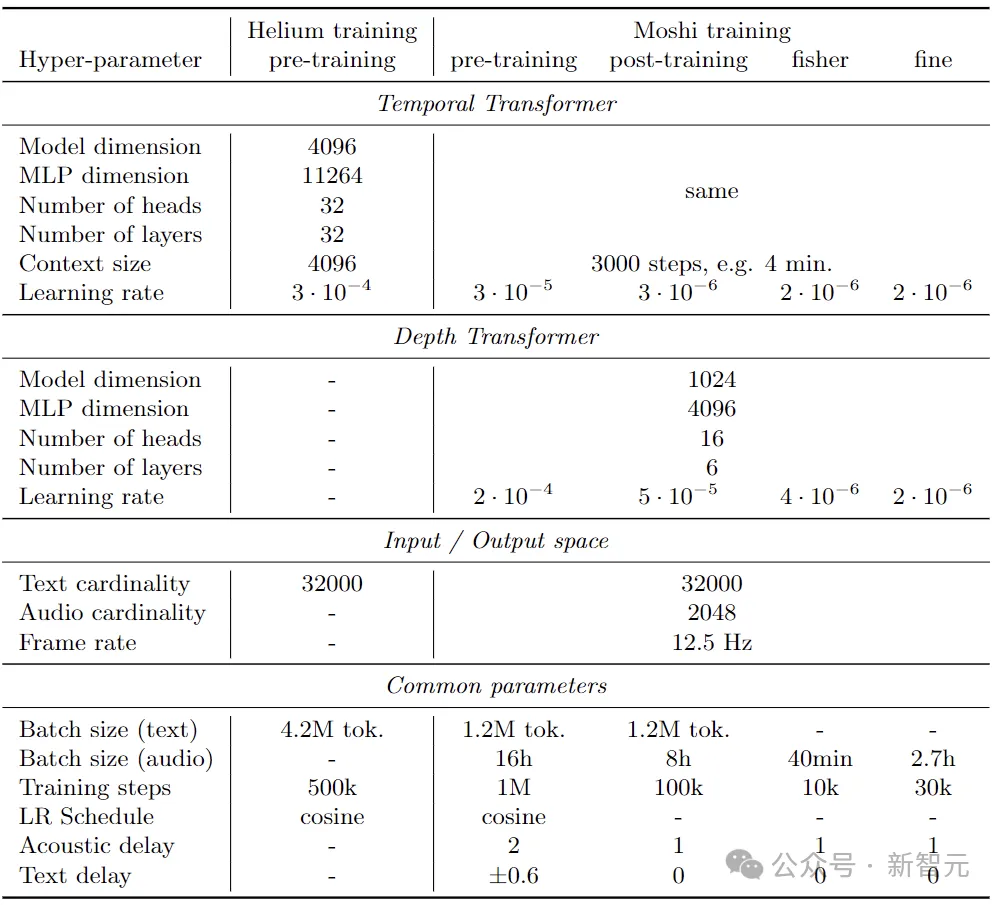
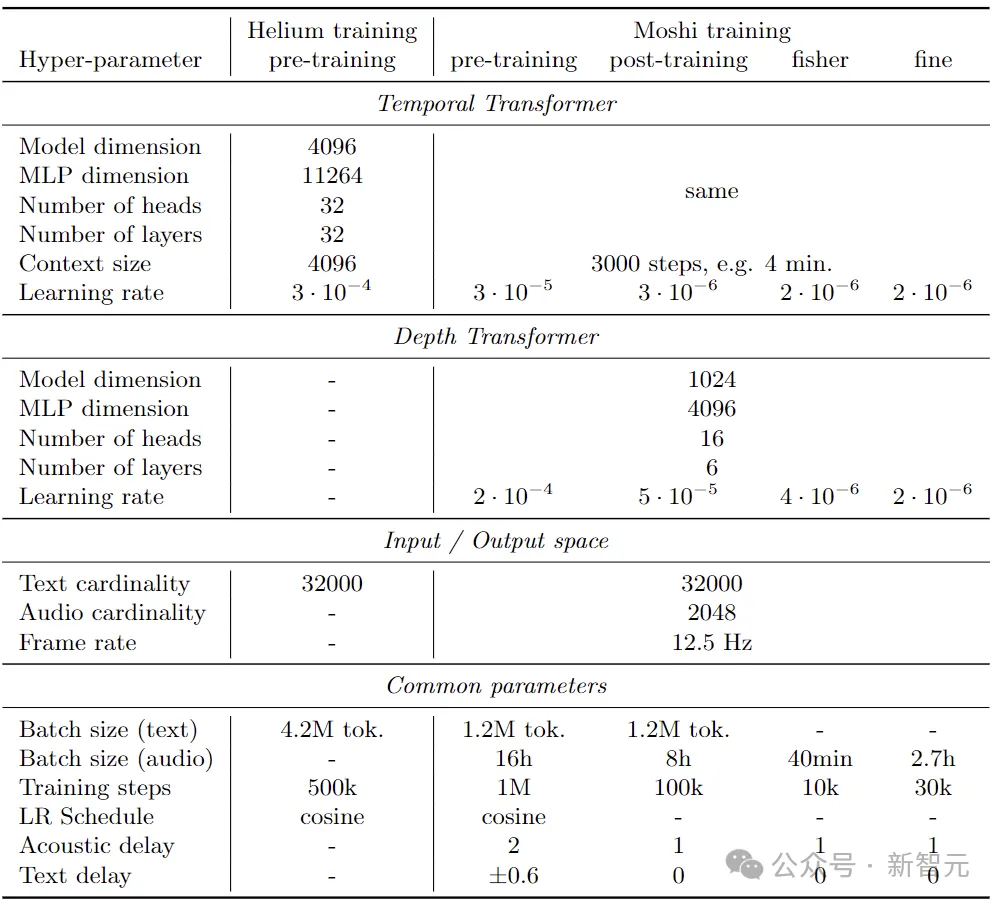
7B Helium语言模型和Moshi架构训练的超参数
研究人员在公共英语数据的2.1T token上对模型进行了预训练。
训练数据包括维基百科、Stack Exchange和大量科学文章,还依赖网络爬取(特别是来自CommonCrawl的数据)来扩展数据集,并通过重复数据删除、语言识别和质量过滤等操作获得高质量的训练集。
Mimi使用残差矢量量化 (RVQ) 将音频转换为Moshi预测的离散token,并通过蒸馏将非因果的高级语义信息传输到因果模型生成的token中,从而允许对语义进行流式编码和解码。
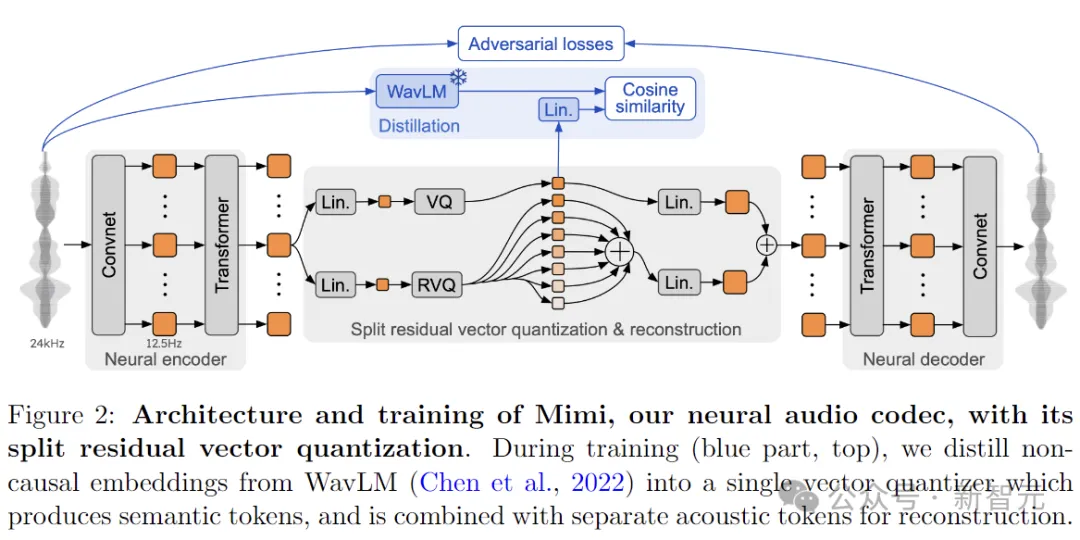
Mimi架构的灵感来自SoundStream和Encodec,编码器通过级联残差卷积块将单通道波形投射到潜在表示。所有卷积都是因果的,因此该自动编码器可以以流方式运行。
通过4个步幅为(4、5、6、8)的卷积块 ,以及步幅为2的1D卷积,Mimi的编码器将24kHz波形投影为每秒12.5帧、维度为512的潜在表示,而解码器采用转置卷积将潜在表示投射回24kHz音频。
为了提高Mimi将语音编码为紧凑表示的能力,研究人员在模型中添加了Transformer模块,分别位于量化之前和之后。
每个Transformer块包含8层、8个头、使用RoPE位置编码、250帧(20 秒)的有限上下文、模型维度512、MLP维度2048。使用 LayerScale来保证稳定训练,对角线值初始化为0.01。两个Transformer都使用因果屏蔽,保留了整个架构与流式推理的兼容性。
Moshi作为一种用于音频语言建模的新架构,将Helium与较小的Transformer模型相结合,以分层和流式传输的方式预测音频token。
这种无条件音频语言模型,提供了优于非流模型的清晰度和音频质量,同时以流方式生成音频。作者进一步扩展了这种架构,以并行模拟多个音频流,从而可以在概念上和实践上简单地处理具有任意动态的全双工对话。
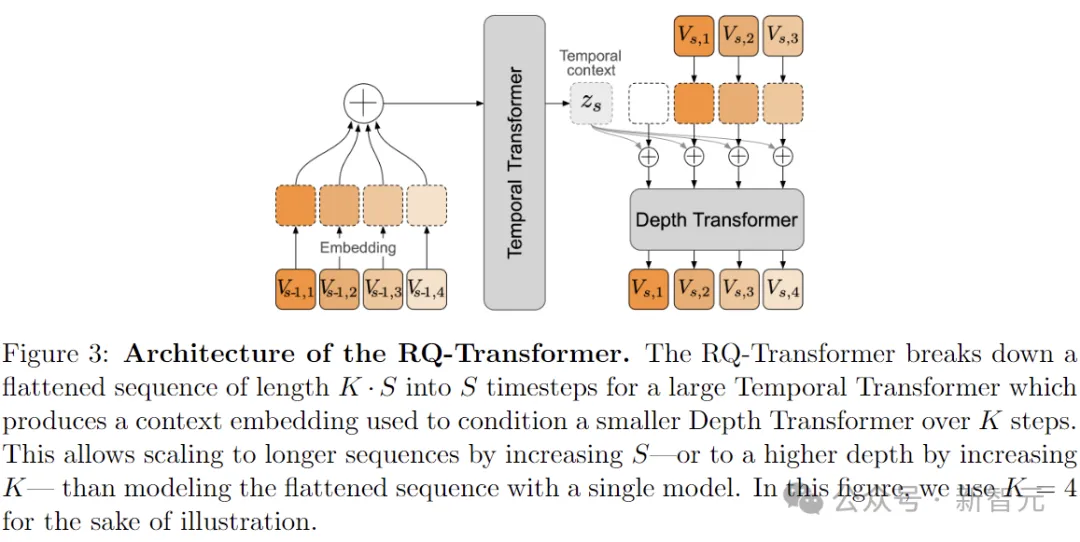
在上图的整体架构中,RQ Transformer将长度为K·S的扁平序列分解为大型时间Transformer的S个时间步长,生成上下文嵌入,用于在K个步骤上调节较小的深度Transformer。
与使用单个模型对展平序列进行建模相比,这允许通过增加S来缩放到更长的序列,或者通过增加K来缩放到更高的深度。
架构中的深度Transformer有6层,维度为1024,16个注意力头。与之前的工作不同,作者在深度Transformer中为线性层、投影层和全连接层使用每个索引的不同参数。
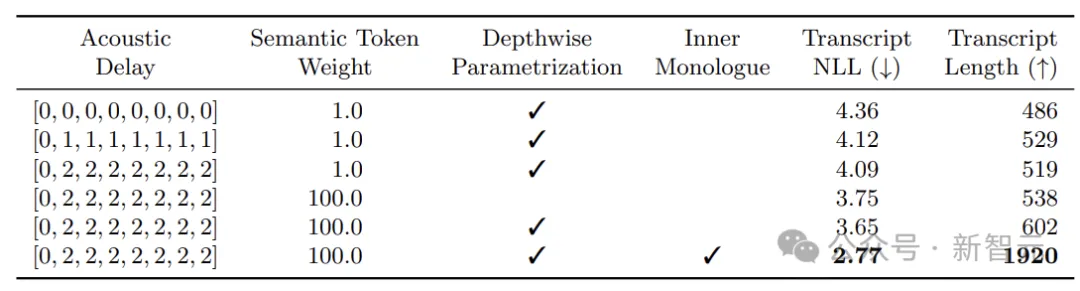
事实上,不同的子序列可能需要不同的转换。鉴于该Transformer的尺寸较小,这对训练和推理时间都没有影响,但上表结果显示这种深度参数化是有益的。
内心独白是一种用于音频语言模型训练和推理的新方法,它通过在音频token之前预测时间对齐的文本token,显著提高了生成语音的事实性和语言质量。
Moshi允许推理来自用户音频和Moshi音频的非语言信息,但这与Moshi在其语音输出中生成文本并不矛盾。根据过去的观察,从粗到细的生成(从语义到声学token)对于生成一致的语音至关重要。
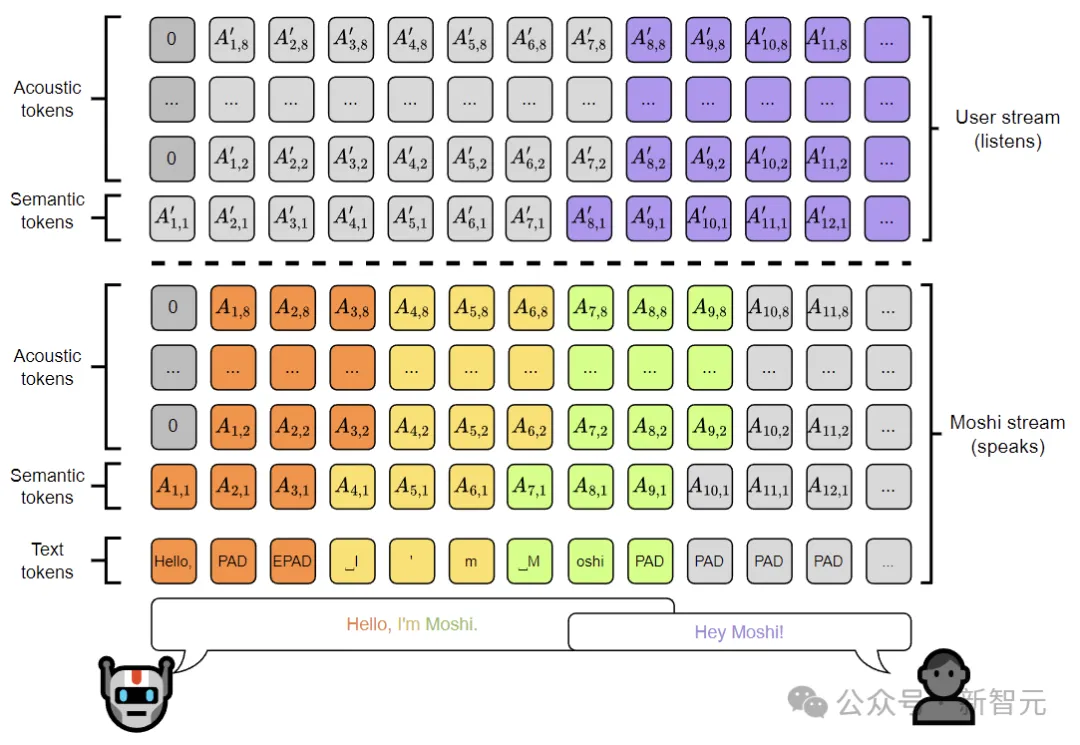
作者利用这种层次结构,使用文本token作为语义token的每个时间步前缀。实验表明,这不仅极大地提高了生成语音的长度和质量,还展示了单个延迟超参数如何允许从ASR模型切换到TTS模型,而不会改变损失、架构或训练数据。
文章来源于“新智元”,作者“新智元”



【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
