# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在当今大模型技术日新月异的背景下,数据已跃升为构建企业大模型知识库、优化训练与微调,乃至驱动模型创新不可或缺的核心要素。
对于企业来说,积累的宝贵知识广泛散布于形式多样的电子文档之中,这些文档不仅格式多样,其内容质量亦呈现出显著的差异性。对海量数据进行精细化的清洗与预处理工作,已成为提升数据价值、确保模型精准高效的关键一环,如何有效提取并利用这些宝贵的知识资源,成为了摆在所有企业面前的一道难题。
9 月 20 日,老牌数字化转型技术服务提供商浩鲸科技在云栖大会期间,成功举行鲸智大模型技术体系发布会,作为企业内部的 “资产沉淀专家”,鲸智文档大模型重磅首发。

据了解,本次发布的 “鲸智文档大模型”,专门针对企业文档场景构建了一组垂直领域模型,浩鲸科技大模型创新中心总经理王玉木表示,鲸智文档大模型与同类产品最大的差异在于,它提供了可快速价值落地的整体性方案,不仅包含了文档大模型能力,还提供了多模态文档工具链 DocChain 和开箱即用的软硬件一体机,基于垂直模型能力和软硬件相互配合,可帮助企业实现文档的知识抽取、知识融合,直至知识推理和问答的全流程覆盖,为企业知识资产的沉淀、高效管理与利用提供了有效通路。
鲸智文档大模型的实践逻辑
浩鲸科技成立于 2003 年,立足于电信行业,智慧触角已触及政务、电力、泛零售等多个领域,迄今已为全球 80 多个国家和地区的电信运营商、700 + 政企客户提供全栈数智化产品技术服务。
“鲸智文档大模型” 始于浩鲸科技 20 余年的数据治理、知识沉淀能力积累,作为垂直领域模型,它从端到端解决场景需求的视角出发,结合了大小模型协作等思路,基于基础大模型构建一套紧密配合的模型组合,主要分三个层面:


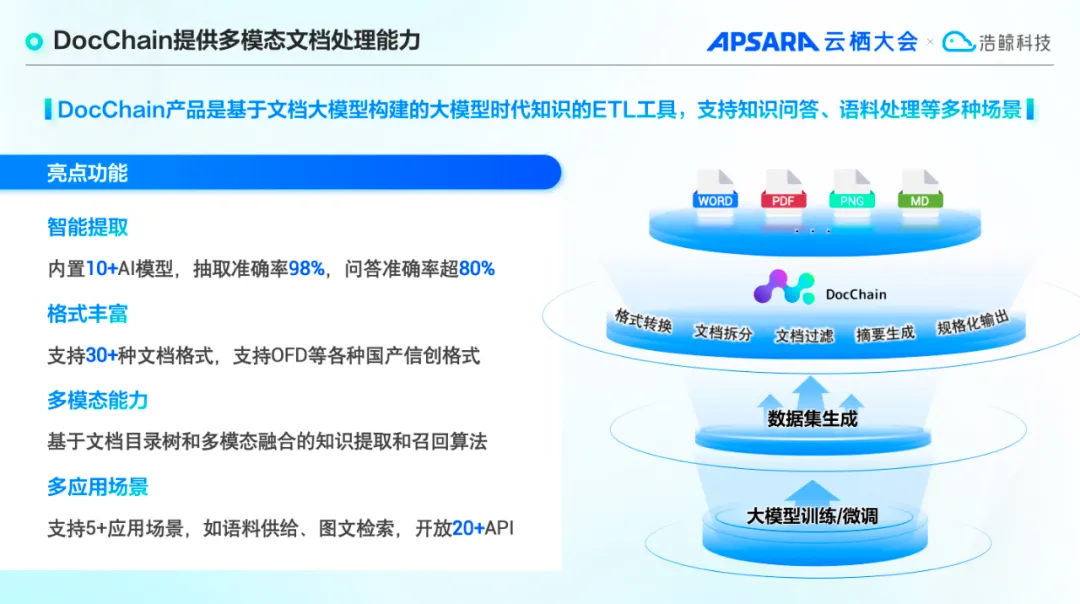
DocChain:文档处理的智慧引擎
为深度赋能企业用户,浩鲸科技依托先进的鲸智文档大模型,匠心打造了多模态文档工具链 ——DocChain。该产品不仅实现了企业文档向宝贵知识资产的转化,更构建了一个集文档知识精准提取、高效检索与智能问答对话于一体的大模型知识服务平台。DocChain 以其卓越的多模态处理能力、广泛的文档格式兼容性和极致的性能优化,成为企业文档处理领域的得力助手。
一体机:解决企业私域场景下低成本上线大模型的诉求
浩鲸科技为解决客户落地大模型过程中算力硬件缺乏、技术人员少、安全要求高等难题,同时推出了文档大模型软硬件一体机。一体机内置了高性能算力,并且预装了大模型以及 DocChain 应用,可为企业快速部署和验证智慧文档处理服务。
从部署上来说,文档大模型一体机具备开箱即用、数据安全可控、性能无忧、快速集成等几个特点,专为轻量级场景设计,私有化部署解决企业隐私保护、数据安全等痛点,低成本实现企业内部大模型快速上线,覆盖通用知识检索、文档问答、服务支撑及品牌宣传等,可帮助企业迅速构建专属大模型问答系统。

随着基础大模型的发展,以及模型增量训练的知识冲突问题日益凸显,RAG 逐渐成为企业智能知识库的标准解决方案,然而知识召回的准确率和完整性成为了影响问答效果的关键因素。
鲸智文档大模型,借鉴了 “大模型 + 小模型” 的思路,基于基座大模型构建了一套大小模型的组合,形成了一套垂直大模型,可以端到端实现垂直应用场景的需求。当前,鲸智文档大模型在多模态识别、检索和精准召回上做了很多的尝试,也取得了一定的成果。
AI 大模型的迅速发展,让企业沉淀的大量文档的知识理解和处理带来了转机,浩鲸科技正通过持续的技术创新与产品优化,推动大模型技术与企业领域知识深度融合,实现企业文档向有价值的资产转化,为企业创造更多价值。
文章来源于“机器之心”



【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
