# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
近年来,语音合成和语音转换等技术取得快速发展,基于相关技术能够合成逼真、自然的音频。然而,攻击者可利用该技术进行语音伪造,即「克隆」特定对象语音,为用户隐私安全与社会稳定带来严重威胁。
目前,已有较多基于卷积神经网络、图神经网络等的伪造检测方法取得了优越的检测效果。但现有工作通常需要采用音频波形或频谱特征作为输入,即需要访问语音完整信息,在该过程中存在语音隐私泄露问题。同时,已有研究证实音色、响度等声学特征在语音伪造检测上的重要性[1,2],这为仅基于声学特征进行深度伪造检测带来潜在可能。
针对此问题,浙江大学智能系统安全实验室(USSLAB)与清华大学联合提出SafeEar,一种内容隐私保护的语音伪造检测方法。

论文地址:https://safeearweb.github.io/Project/files/SafeEar_CCS2024.pdf
论文主页:https://safeearweb.github.io/Project/
代码地址:https://github.com/LetterLiGo/SafeEar
CVoiceFake数据集地址:https://zenodo.org/records/11124319
SafeEar的核心思路是,设计基于神经音频编解码器(Neural Audio Codec)的解耦模型,该模型能够将语音的声学信息与语义信息分离,并且仅利用声学信息进行伪造检测(如图1),从而实现了内容隐私保护的语音伪造检测。
该框架针对各类音频伪造技术展现良好的检测能力与泛化能力,检测等错误率(EER)可低至2.02%,与基于完整语音信息进行伪造检测的SOTA性能接近。同时实验证明攻击者无法基于该声学信息恢复语音内容,基于人耳与机器识别方法的单词错误率(WER)均高于93.93%。
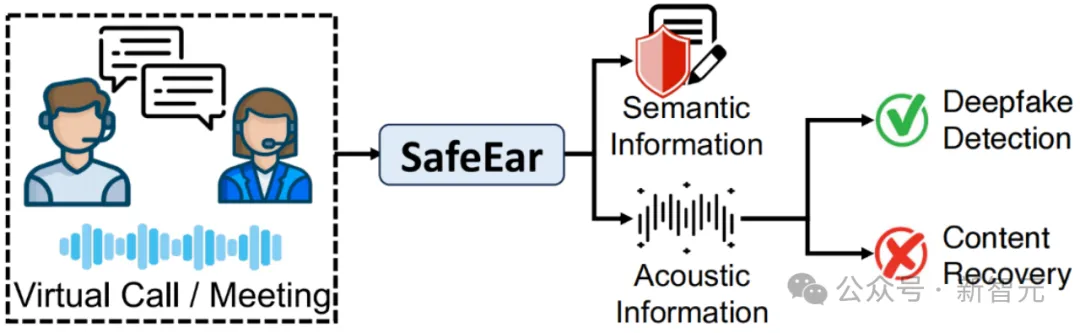
图1 SafeEar原理示意图
SafeEar采用一种串行检测器结构,对输入语音获取目标离散声学特征,进而输入后端检测器,主要框架如图2所示。
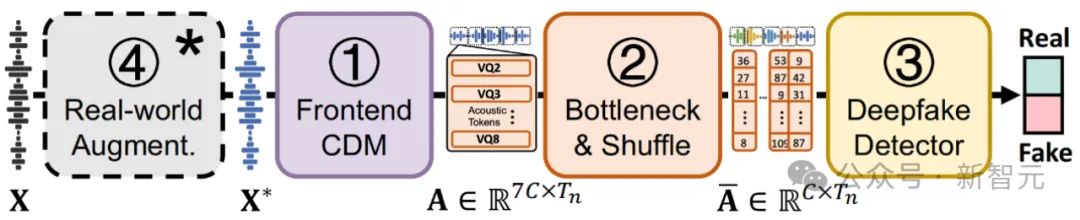
图2 SafeEar框架示意图。(虚线方框内的④Real-world Augmentation仅在训练时出现,推理阶段仅有①②③模块)
主要包括以下四个部分:
1. 基于神经音频编解码器的前端解耦模型(Frontend Codec-based Decoupling Model, Frontend CDM)
受SpeechTokenizer[3]等前期工作的启发,该部分基于神经音频编解码器结构,在语音特征分离与重建的过程中实现语音特征解耦。如图3所示,包括编码器(Encoder)、多层残差向量量化器(Residual Vector Quantizers, RVQs)、解码器(Decoder)、鉴别器(Discriminator)四个核心部分。
其中,RVQs主要包括级联的八层量化器,在第一层量化器中以Hubert特征作为监督信号分离语义特征,后续各层量化器输出特征累加即为声学特征。
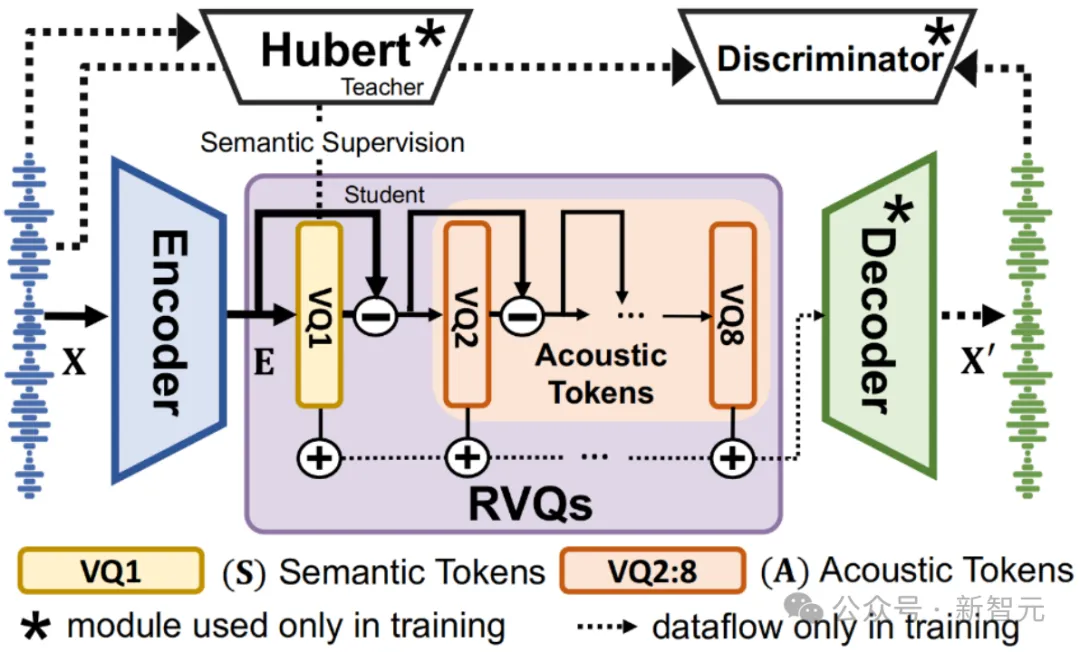
图3 基于神经音频编解码器的解耦模型示意图。
2. 瓶颈层和混淆层(Bottleneck & Shuffle)
如图4所示,瓶颈层被用于特征降维表征和正则化处理。混淆层对声学特征进行固定时间窗范围内的随机打乱重置,从而提升特征复杂度,确保内容窃取攻击者即便借助SOTA的语音识别(ASR)模型,也无法从声学特征中强行提取出语义信息。最终,经过解缠和混淆双重保护的音频可以有效抵御人耳或者模型两方面的恶意语音内容窃取。
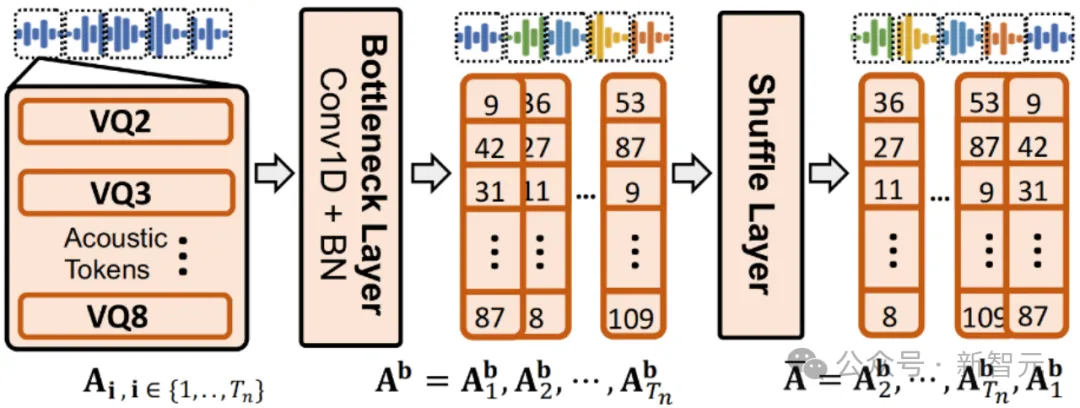
图4 瓶颈层和混淆层示意图
3. 伪造检测器(Deepfake Detector)
最近研究表明Transformer分类器在伪造检测方面的潜力[4],SafeEar框架的伪造音频检测后端设计了一种仅基于声学输入的Transformer-based分类器,采用正弦、余弦函数交替形式对语音信号在时域和频域上进行位置编码。该分类器的主要结构如图5所示,包括编码器、池化层和全连接层等部分。
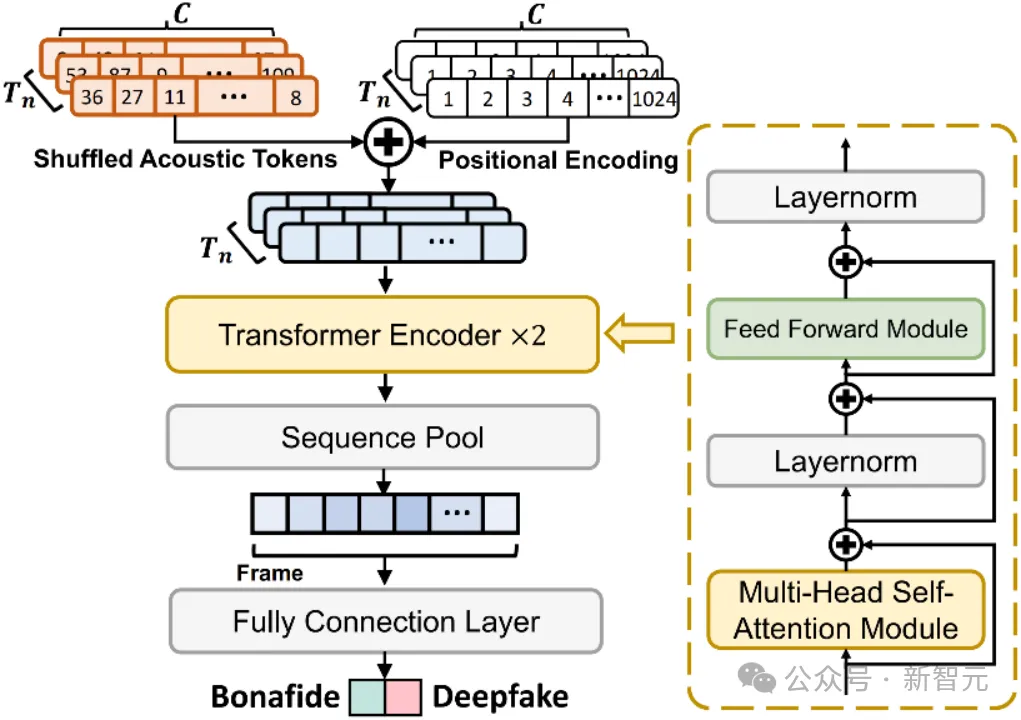
图5 基于声学特征的语音伪造检测分类器。
鉴于现实世界的信道多样性,采用具有代表性的音频编解码器(如G.711、G.722、gsm、vorbis、ogg)进行数据增强,模拟实际环境中带宽、码率的多样性,以推广到不可见通信场景。
本文选择了八个代表性的基线方法,其中包括端到端检测器(AASIST[5]、RawNet2[6]、Rawformer[7])和串行检测器(LFCC+SE-ResNet34[8]、LFCC + LCNN-LSTM[9]、LFCC+GMM[10]、CQCC+GMM[10]、Wav2Vec2+Transformer),测试数据集采用语音伪造检测代表性数据集ASVspoof2019[11]和ASVspoof2021[12],实验结果如表1所示。
SafeEar在信息损失的情况下,仍能实现较为优越的检测效果,在同类型的串行检测器中达到最低等错误率(3.10%),且优于部分端到端检测器。
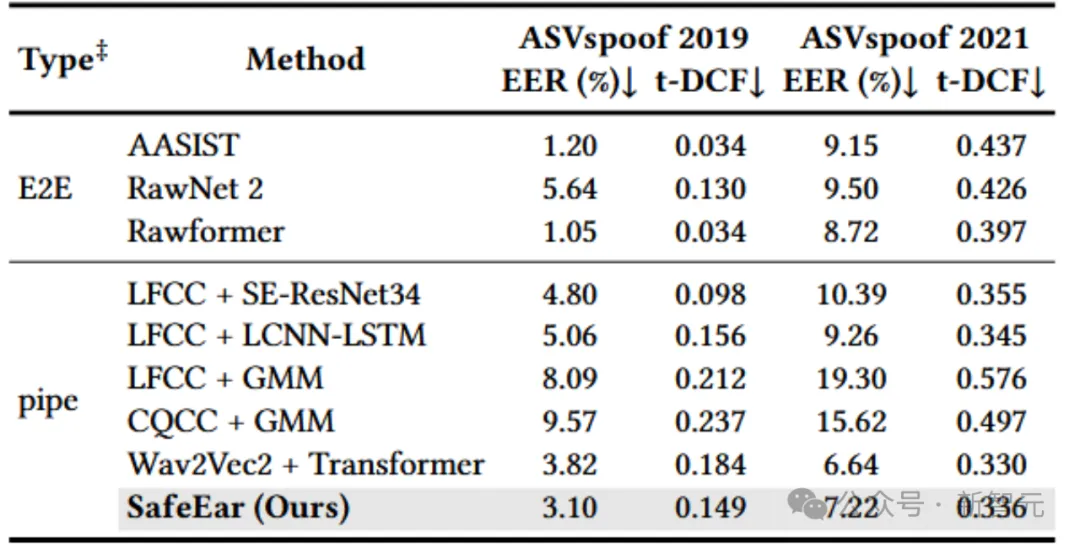
表1 整体伪造检测效果对比
对于隐私保护效果,本文讨论了具有不同能力的三类主要攻击者,包括Naive content recovery adversary(CRA1)、Knowledgeable content adversary(CRA2)和Adaptive content adversary(CRA3),通过语音识别(具有代表性的ASR模型和开源ASR API)准确率评价隐私保护的效果。
由于解耦出的声学特征具有信息损失性,攻击者无法有效恢复或重建语音内容,从而证明该方法具有隐私保护能力。同时,论文通过用户测试体现出人耳与机器在内容隐私恢复上均具有较高难度。部分实验结果如下。
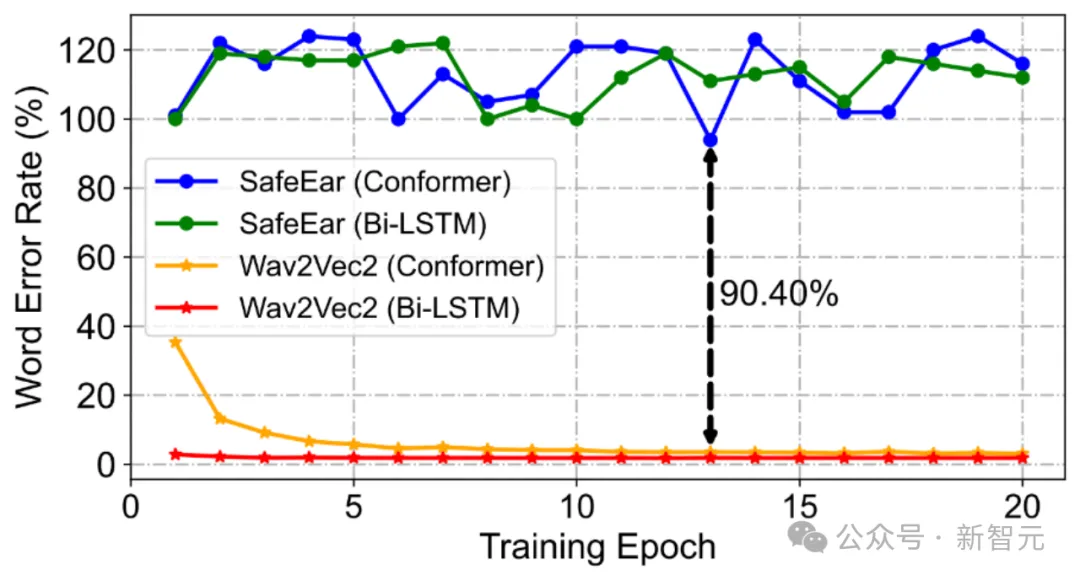
图6 训练过程中验证集上词错误率变化曲线(CRA1)。可见ASR模型(Conformer、Bi-LSTM)对于SafeEar保护后的语音始终无法识别,WER曲线保持过高数值且震荡;而对于完整音频,ASR模型可迅速收敛并在验证集上取得极低的WER
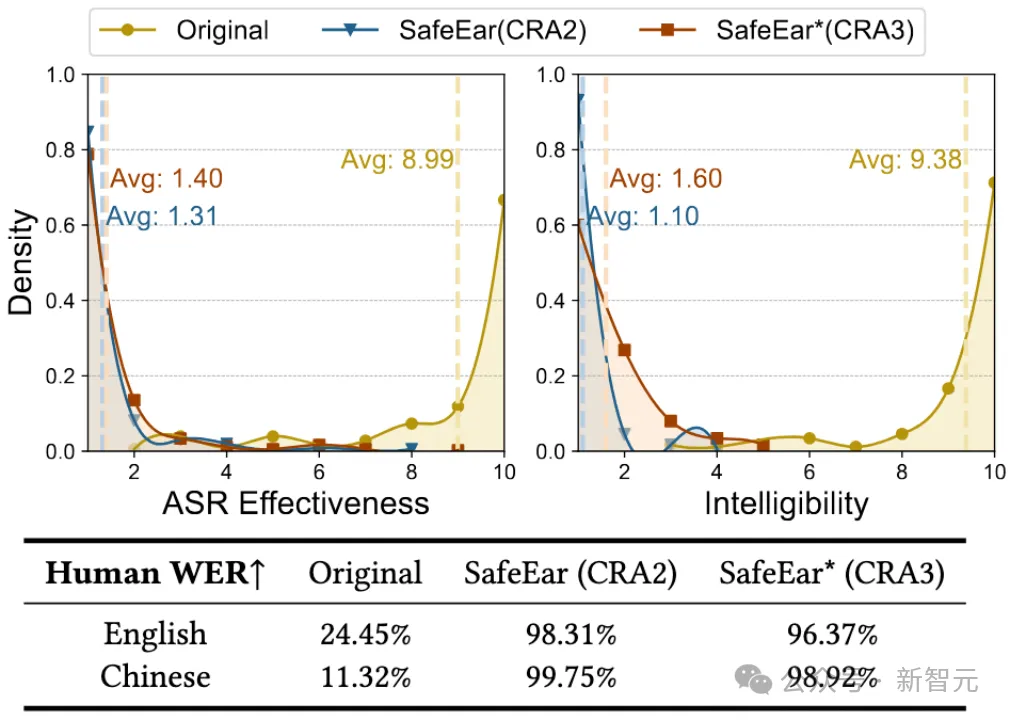
图7 真实的用户调研表明,ASR模型被认为能够有效识别完整音频(高达Original: 8.99),而对于SafeEar面对不同攻击者等级下的识别效果始终很差(低至CRA2: 1.31、CRA3: 1.31);同理人耳听感的清晰度分别为Original: 9.38、CRA2: 1.10、CRA3: 1.60。当用户模拟攻击者尝试恢复语音内容时,在SafeEar保护下的WER始终高于96.37%
音频示例
原始音频 / SafeEar保护后的音频:

本文在保护语音内容隐私的同时实现了语音深度伪造检测,该方法可被应用于实时语音通话环境,具有优越的检测准确性和泛化能力。
同时,该工作构建了涉及五种主流语言(英语、中文、德语、法语、意大利语)、多声码器(Parallel WaveGAN, Multi-band MelGAN, Style MelGAN, Griffin-Lim, WORLD, DiffWave)的语音伪造检测数据集CVoiceFake,最新数据集涵盖150万个语音样本及其对应转录文本,可作为语音伪造检测和内容恢复攻击的基准数据集。
SafeEar也提供了一种新颖的隐私保护串行检测框架,能够在其他相关任务中沿用和拓展,进而推进智能语音服务安全化发展。
文章来自于“新智元”,作者“LRST”。




【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
