# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
是谁出的题这么的难,到处全都是正确答案。
很多智能儿童手表都会有一个“主打”功能——“聆听”。在家长 app 端发起后,手表端静默执行,自动接通、保持黑屏、不通知孩子,以此实现远程观察孩子状态。

它甚至不说“我在~”丨Giphy
这大概是儿童智能手表中最受家长欢迎和孩子厌恶的功能了。
如果把“孩子”换成你我,“家长”换做 AI 呢?也许你坚信:目前还没有任何一个理由戴着一个时刻“监听”自己的设备。
可如果 AI 给了你一个理由呢?很诱人的那种。
目前各种最火热的 AI 硬件形态,智能眼镜、AI 项链、录音饰品等等,都是以收集不同模态“贴身”数据为基础来实现功能的——训练大模型形成个人知识库,让 AI 拓展更多实用能力。
AI 硬件的隐私问题,已经在激起争议和焦虑。
还记得几个月前微软撤回了 Recall 功能么?Recall 是 Windows 11 上的一项新功能,通过对用户 PC 不断截图——已经删除的电子邮件会被保存,无痕浏览的网页会被截取,并制作成个人数据库。再加上 Copilot,PC 就能变得更“好用”。
漏洞很快就被发现了——虽然用户数据被保存在本地设备上,黑客还是能通过恶意软件远程访问、窃取到数据。

并不用“物理打开”你的电脑丨Giphy
AI 时代,如此多的个人数据在采集、保存、训练、输出的过程中要保证安全,对企业来说是前所未有的挑战,移动时代的隐私保护实践,或许并不再适用。
这个问题,比我们想象中要复杂得多。
第一层的恐慌和怀疑,来自于本地和云端的拉扯。
今年春季 WWDC 上,苹果官宣与 OpenAI 合作的消息之后,马斯克立刻在 X 表示上“强烈反对”,并将其形容为“creepy spyware”。

i am watching you丨Giphy
OpenAI 被骂得也不算冤——去年 3 月,ChatGPT 流行正盛时,就发生过一起个人数据泄漏危机。不少用户在社交网络反馈,在 ChatGPT 的聊天记录栏中出现了他人的聊天记录,一些人甚至能看到活跃用户的姓名、电子邮件地址、支付地址、信用卡号等私密信息。
刚刚为 AI 应用开始狂热的用户开始认真地担心起来:云端大模型的隐私泄漏和数据安全到底会成为一个多么严重的隐患?
当下对于 AI 隐私安全的讨论,更多是上一个互联网时代延续下来的“焦虑”——用户个人信息和交互数据在云端存储并用于进一步的训练,这是否会加剧隐私泄漏的风险。
2014 年,黑客利用 iCloud 安全机制的漏洞,撞库盗取了账号,流出了一些好莱坞女星照片;2018 年,“剑桥分析”事件曝光,一个 Facebook 上的第三方应用,通过获取的用户社交数据构建了服务于精准投放政治宣传的算法,进而影响选民的投票行为;2021 年,国内一家电商网站被指,在获得系统照片的权限后,删除了“缓存在云端”的照片,让用户以为平台远程操作了本地设备……以及各种推荐算法和个性化广告等,属于上一代决策式人工智能对于用户行为数据的依赖,“天啊,它给我推的这个内容就是我刚刚聊的,我被监听了……”
在“更好的用户体验(也包括更精准的内容投放)”和“更透明安心的隐私保护”之间,当用户经历了天平摇摆的从左到右,“逐渐觉醒”的过程,也开始步步倒逼厂商采取更严格的隐私策略。
一些厂商做法是把尽量多隐私数据和运算直接留在硬件本地(代表是苹果,如果你还记得当年 CES 场外苹果揶揄安卓的经典广告语);以及利用差分隐私,联邦学习等技术手段,保障调用数据的隐私和安全,比如华为做个人音乐推荐时用了差分隐私,原始个人数据不上云,在云端进行差分后数据的统计分析。

苹果广告丨India Today
传统的隐私计算多是在算法层开展工作,但是,大模型从训练、输出到能力涌现是一个“黑盒”,不透明、无边界、不可解释,对于以前的基于可解释、清晰、可控的技术路线的隐私计算方法提出了全新挑战。
这让很多智能手机厂商都在加码“端侧模型”的概念。去年底,骁龙 8 Gen3 发布,实现了在“端侧”运行 100 亿参数大模型,为了强调“本地”芯片能力,在演示 0.6 秒生成图像时,还将手机开启了飞行模式。
今天,用户大部分最为关键的个人数据都是在手机上产生的,日历、待办事项、笔记、照片、短信等。手机厂商一致认为,基于这些数据生成“个人 AI 知识库”的过程,也要留在本地,才能保证私密安全。

设个密码啥的,没用丨Giphy
AI 时代,更难的是对于“数据边界”的界定。
“隐私意味着用户要知道他们在签署什么。条款应当用清晰易懂的语言,反复强调重点。我对这件事很乐观,我相信用户是聪明的,有些人愿意分享更多数据。但你要问他们,每一次都问,获得明确的授权,让用户准确地知道你用他们的数据干了什么。”
这是 2010年 iCloud 上线前夕,乔布斯与 Walt Mossberg 有过的一段对隐私的精彩论述。并且这段论述,在之后十几年时间里,成为乃至全行业的隐私保护宗旨。
iOS 10 开始,当 iPhone 要获取用户数据和传感器权限(比如蓝牙、通讯录、定位、麦克风、日历、照相机等),都会弹窗进行询问,用户也可以在设置里进行精确管理;iOS 14.5 以来,当 app 需要跟踪用户活动时,都会弹窗询问,并告知用户如果允许,数据将被用在哪里。
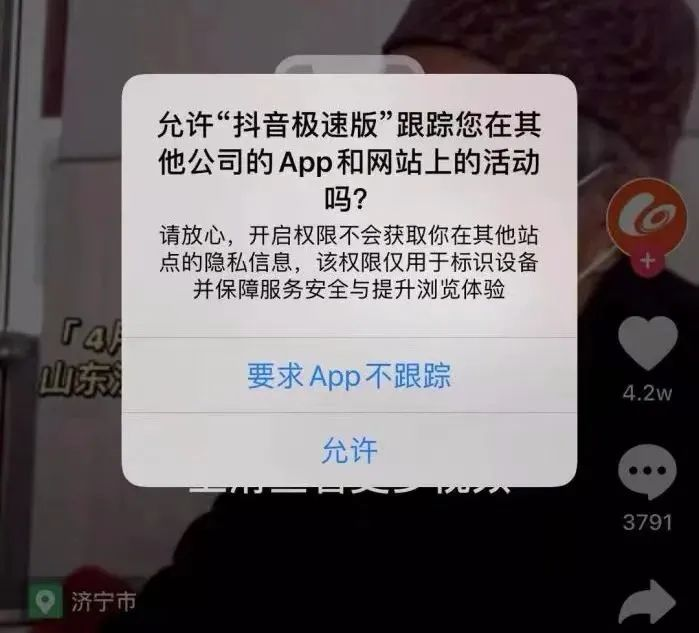
但数据统计,后来人们对于该功能越来越不在意丨网络
Android 14 引入了新权限设置,让用户只授权应用访问特定照片或视频,而不用开放整个媒体库。
欧盟的 GDPR 规定:企业在获取用户数据时,必须用具体、清晰的语言描述需要获得什么数据,并得到用户同意。
而 AI 时代,能靠“自主控制权”来分割“数据边界”似乎成为了一个悖论。
AI 应用开发非常流行的一个概念叫“生活流”(Life Stream)。“生活流”的意思是,用户佩戴类似智能眼镜这样的传感器,让 AI 能够与用户同步获得生活中一切的视听信息,同步理解用户生活中的一切,从而训练出一个贴身的“AI 助手”。

未来,每个人都会有个数字助理丨Giphy
而这类产品好用与否的检验标准,就是减轻用户负担,让其自动化、智能化、通用化地去解决问题——这与不断询问用户“数据权限调用和管理”,本身就是矛盾的。
AI Agent(通常中文译作“智能体”)进行工作流编排时,会调用三方接口功能和用户数据,这让服务生态变得复杂:涉及的主体(数据、算法、服务提供方)数量增加,各主体权责交叉,数据交互(理想状态:AI Agent 按需关联各种数据、功能信息)愈发复杂。
越大量,越有效(包括颗粒度低、多样化、贴近垂直场景等)的数据投喂,生成结果往往越好,这是AI数据投喂的基本规则。但是这样会让用户重新陷入一种“太好用了所以无法拒绝”的境地,而最终只能“把数据全部交给 AI”——你可以类比移动互联网时代已经发生的事情:多少人会对搜索上瘾,而又有多少人会对算法推荐上瘾。

根本停不下来丨Giphy
这种 AI 应用的特性让传统隐私保护的“数据护栏”失效了——比如,过去用户将一张敏感照片放进私密相册,或使用无痕模式访问一个“难言之隐”的网页,而一个诊断皮肤病的“智能体医生”就恰好需要你“生活流”里的这些敏感数据。
与之适配的应该是一套全新隐私保护模式。
也许 Apple Intelligence 设想的模型架构是一个可能的答案:在本地运行的基础模型;PCC,私有云计算;接入第三方。简单来说,这是一个按 Query 难度(查询请求的难度)分发的分层模型策略。既要保证端和云之间的数据有效流转、访问、存储,最终目的是用户体验;又要保证数据安全。苹果实则设计了一套涉及到芯片、终端、云端、系统软件的安全机制。
第三层问题,是新时代的最令人兴奋和担忧的:一大批硬件厂商,正在打造“超越”智能手机的,更面向未来的 AI 硬件。
包括智能眼镜、录音笔等等,第一批原型产品已经面世。称之为“原型”,是因为这些产品的功能设计上还不够完善,性能也捉襟见肘,还达不到“好用”的程度,但设计思路却不约而同地选择了“默认记录”。
还记得 AI Pin 么?别在胸口,摄像头默认对前方;也有录音笔设计得薄片一张,紧贴手机背后,随时启动收音(据说有公司受此启发,要把员工工牌做成这样……);被设计成可日常配备,不会在社交中被“察觉”的智能眼镜更是如此。

默认记录,不易察觉,贴合日常,AI硬件的一个设计思路丨The Verge
单从硬件设计看,这些产品的设计并不新鲜。Google Glass 在十几年前就问世了,更别说各种隐蔽的小型摄像机、录音笔,都早已走出了 007 电影。

Sergey Brin丨Financial Times
但它们的新颖之处,在于躯壳之内包裹的东西——这就从一个技术问题,演化为了一个社会问题。隐蔽的录音录像设备一直有,只不过绝大多数普通人并没有理由去购买使用这些产品。
但 AI 赋予了这些硬件产品存在的理由,甚至可能将社会带入一个人人“佩戴摄像头、录音笔”的轨道,或许当下我们还很难武断地说,这会让社会陷入灾难,但它一定会带来非常深刻的改变。

设备不仅记录使用者,还有使用者周围的一切丨Giphy
十年前,谷歌眼镜刚刚交货的时候,即便数量稀少,也掀起了巨大争议。在当时的硅谷,因为常能碰到佩戴谷歌眼镜的顾客,导致很多酒吧餐馆都贴出了“禁止佩戴谷歌眼镜进店”的标识——这甚至成为了阻碍智能眼镜在那个时代普及的重要因素。

新时代,新技术,新问题丨Giphy
新时代,新硬件,数据被收集和分析的主体,将会从设备使用者个人,变成使用者的周围一切——如果你是一个技术乐观主义者,你就更不该无视这些数据隐私的新问题。
文章来自于“果壳”,作者“Jesse”。




【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
