# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
AI泛滥成灾的时代,真假孰能分辨?
最近,国外一位专业律师Jay Shooster自曝,自己的父亲陷入了一场巨大的AI骗局。
诈骗者利用AI克隆了Shooster声音,然后给他的父亲拨去电话:您孩子因酒驾开车被捕,需3万美元保释出狱。
险些,这位父亲被AI欺骗。
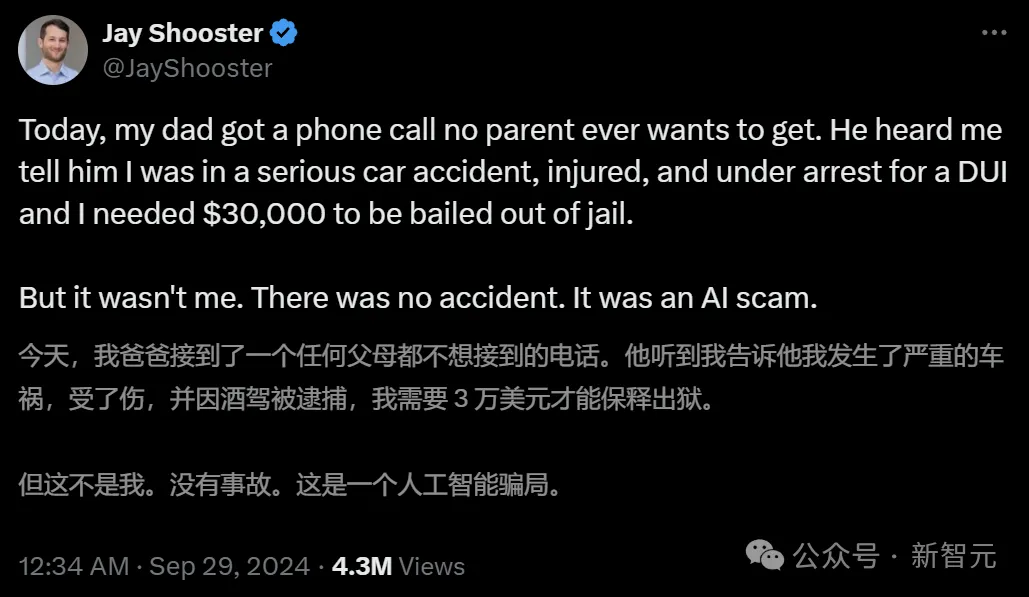
我不确定这事发生在我的声音出现在电视上仅仅几天后是否只是巧合。短短15秒的声音,就足以制作一个不错的AI克隆。
作为一名消费者保护律师,我曾经就这种诈骗做过演讲,在网上发过帖子,也和家人谈论过,但他们还是差点上当。这些诈骗之所以如此有效,就是这个原因。
不巧的是,Shooster近一次在电视中露脸的15秒视频,恰被诈骗者钻了空子。
而且,即便是在Shooster曾提醒过家人此类诈骗情况下,他的父亲依旧被迷惑了。
只能说AI模拟人类的声音,已经强到令人发指。
另有伦敦大学学院一项研究佐证,无论任何语种,人们在27%情况下,都无法识别AI生成的声音。
而且,反复聆听,也并不能提升检测率。
这意味着,理论上,每四个人当中就有一人可能被AI电话诈骗,因为人类的直觉并不总是那么可靠。
不论是图像、视频、声音,凭借AI生成技术,任何一个人都能轻易伪造,Deepfake已经深深影响每个人的生活。
AI技术犯罪程度,现如今到了我们无法想象的地步。
Shooster的分享用意,告诉大家这种诈骗手段之所以有效,部分原因在于——
人类无法可靠地识别出AI的声音。
IBM一项实验中,安全专家展示了如何实现「音频劫持」的一幕。

他们开发一种方法,将语音识别、文本生成、声音克隆技术结合,去检测对话中的触发词「银行账户」,然后将原来账户替换成自己的账号。
研究人员称,替换一小段文字,比AI克隆语音对话要更加容易,而且还能扩展到更多的领域。
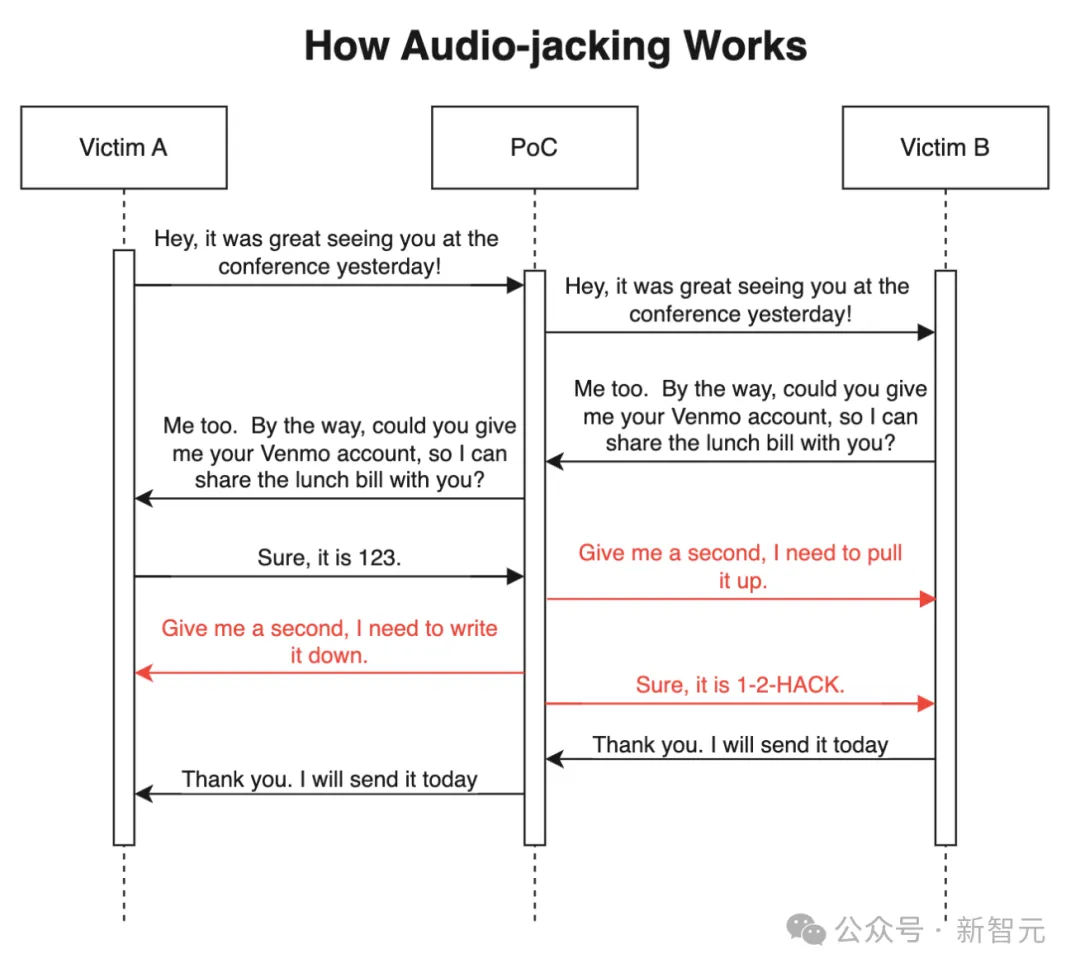
而对于足够好的语音克隆技术,只要3秒原声就足够了。
另外,文本和音频生成中的任何延迟,都可以通过桥接句来弥补,或有足够处理能力情况再消除。
对此,研究人员警告,未来攻击还可能会操纵实时视频通话。
而这种技术也不仅仅被滥用在欺诈,配音演员Amelia Tyler称,AI克隆的声音在未经自己允许下,被用来朗读不宜儿童的内容。
AI克隆声音之外,还有AI换脸视频、AI虚假图像生成,这样案例早已屡见不鲜。
前段时间,韩国国内掀起「N号房2.0」事件,Deepfake被用到了未成年人身上,引发人们巨大的恐慌。
甚至,全网一度开启了「Deepfake到底有多可怕」的热议话题。

图像生成Midjourney、Flux,视频生成Gen-3、声音生成NotebookLM等等,都成为潜在的作案工具。
去年,Midjourney生成的穿羽绒服走在大街上的教皇,许多人信以为真,疯狂转发。

而到了今年,AI图像王者Flux出世,各种TED演讲者的逼真照片,再配上AI视频工具动起来,几乎骗过了所有人。

而在AI视频实时换脸上,今年国外网友们已经开发出很多开源工具了。
比如,Facecam仅需添加一张图,就可以立即生成实时视频,而且一部手机即可操作。

项目作者展示了,自己如何轻轻松松无缝换脸到Sam Altman、马斯克,脸上所有器官根本无死角。

还有一夜爆火的AI换脸项目Deep-Live-Cam,同样也是只要一张照片,直接换脸马斯克开直播了。
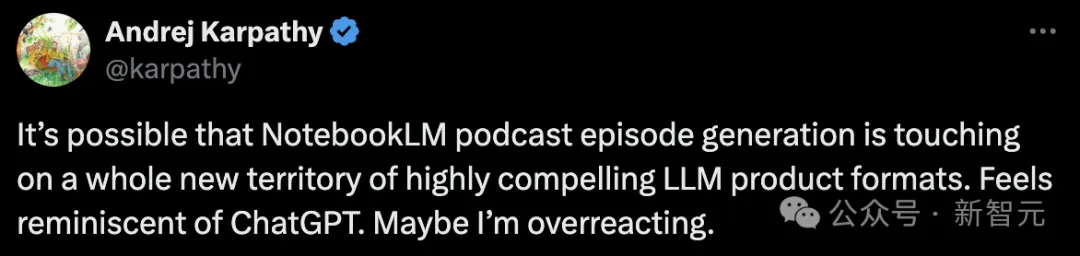
而这两天炒的比较热的AI声音生成,当属谷歌NotebookLM了。它能够迅速把文字内容,生成播客视频。
就连AI大佬Karpathy爱不释手地试玩,并力荐称有可能会迎来它的ChatGPT时刻。
不过,国外一位扫雷游戏专家,在听了AI将自己书生成播客声音,却惊呼自己被吓到了。
而且,更令人惊悚的是,两位NotebookLM播客「主持人」发现,自己是AI而不是人类,还陷入了存在主义崩溃的边缘。

若是这样强大的AI,被应用到现实诈骗中,只会带来更严重的后果。
在DeepFake逐渐变成「恶龙」的同时,研究界也在积极研发「屠龙」工具。
要么从源头为GenAI生成的内容添加水印,或者对真实内容设置护栏以防止滥用,要么发展出能检测自动生成内容的系统。
不久前,中科院一位工程师曾开源了能够识别伪造图像的AI模型,去对抗DeepFake。
刚一发布,这个项目便登上了Hacker News热榜,其受欢迎程度可见一斑。

目前,完整的代码和文档已经发布在了GitHub仓库上。
开发者表示,自己从2023年毕业后就一直在从事DeepFake检测算法方面的研究工作,让所有有需要的人都可以免费使用模型来对抗deepfake。
此外,还有许多业界科学家们,在这条路上做出了诸多贡献。
在2023年11月丹麦哥本哈根举行的ACM计算机与通信安全会议上,美国圣路易斯华盛顿大学的博士生Zhiyuan Yu展示了他和Ning Zhang教授合作开发的AntiFake。
通过一种创新性的水印技术,AntiFake可以提供创造性的方法,保护人们免受深度伪造声音的诈骗。

论文地址:https://dl.acm.org/doi/pdf/10.1145/3576915.3623209
创建DeepFake语音只需要真实的音频或视频中有人说话。通常,AI模型只需要大约30秒的语音,就能通过创建「嵌入」(embedding)学会模仿某人的声音。
这些embedding向量就像是在所有声音的庞大数字地图中指向说话者身份的地址,听起来相似的声音在这个地图中的位置更接近。
当然,人类并不是用这种「地图」来识别声音的,而是通过频率。我们更关注某些频率的声波,而对其他频率的关注较少,而AI模型则利用所有这些频率来创建良好的嵌入。
AntiFake通过在人们不太关注的频率上添加一些噪音来保护语音录音,这样人类听众还是能听懂,但会严重干扰AI。
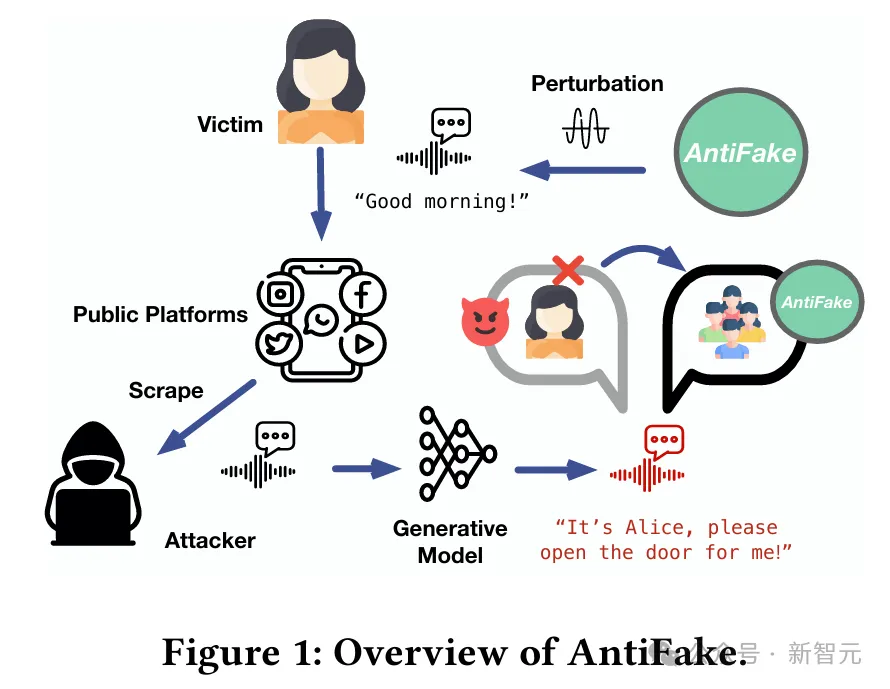
最终,AntiFake会让AI创建出低质量的嵌入,相当于一个指向地图错误部分的地址,这样生成的任何DeepFake都无法模仿原始声音。
为了测试AntiFake,Yu的团队扮演「诈骗者」的角色,使用5种不同的AI模型生成了6万个语音文件,并为其中600个片段添加了AntiFake保护。
结果发现,添加保护后,超过95%的样本无法再欺骗人类或语音认证系统。
值得一提的是,AntiFake的衍生版本DeFake,还在今年4月初美国联邦贸易委员会举办的语音克隆挑战赛中获得了一等奖。

无独有偶,浙江大学智能系统安全实验室(USSLAB)与清华大学也联合了一种内容隐私保护的语音伪造检测方法——SafeEar。

项目主页:https://safeearweb.github.io/Project/
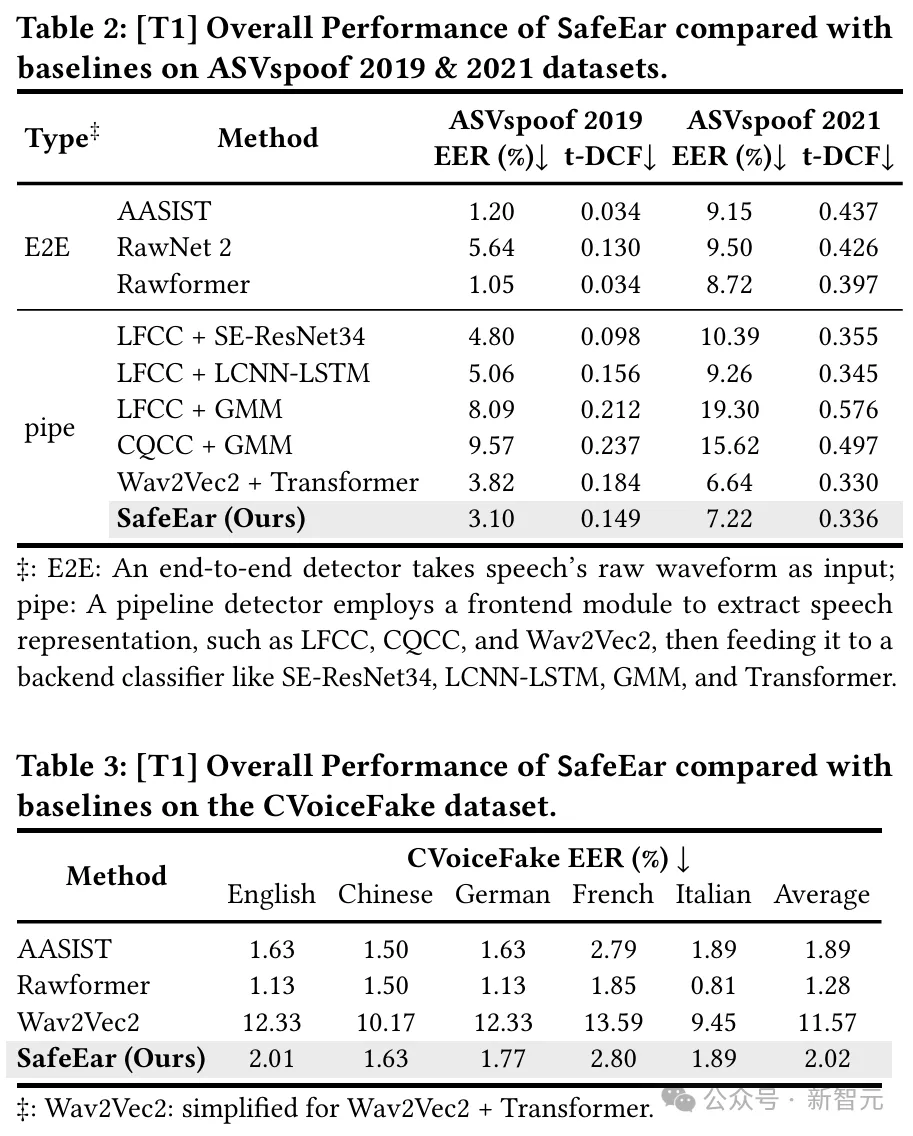
SafeEar的核心思路是,设计基于神经音频编解码器(Neural Audio Codec)的解耦模型,该模型能够将语音的声学信息与语义信息分离,并且仅利用声学信息进行伪造检测,从而实现了内容隐私保护的语音伪造检测。
结果显示,该框架针对各类音频伪造技术展现良好的检测能力与泛化能力,检测等错误率(EER)可低至2.02%,与基于完整语音信息进行伪造检测的SOTA性能接近。
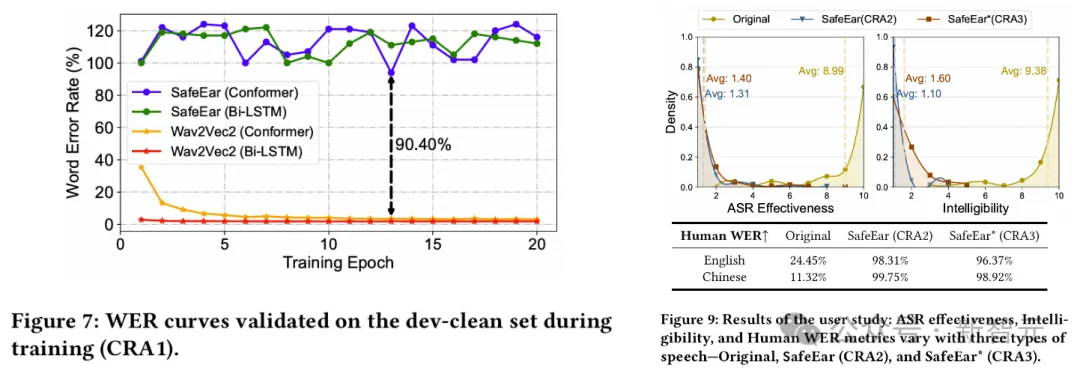
同时,实验还证明攻击者无法基于该声学信息恢复语音内容,基于人耳与机器识别方法的单词错误率(WER)均高于93.93%。
具体来说,SafeEar采用一种串行检测器结构,对输入语音获取目标离散声学特征,进而输入后端检测器。
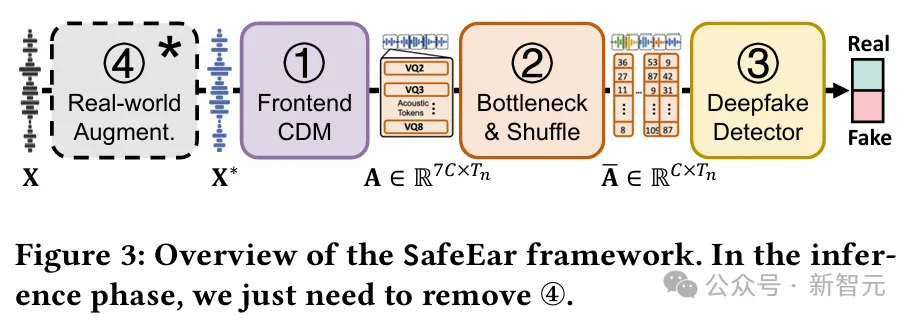
虚线方框内的④Real-world Augmentation仅在训练时出现,推理阶段仅有①②③模块
模型包括编码器(Encoder)、多层残差向量量化器(Residual Vector Quantizers, RVQs)、解码器(Decoder)、鉴别器(Discriminator)四个核心部分。
其中,RVQs主要包括级联的八层量化器,在第一层量化器中以Hubert特征作为监督信号分离语义特征,后续各层量化器输出特征累加即为声学特征。
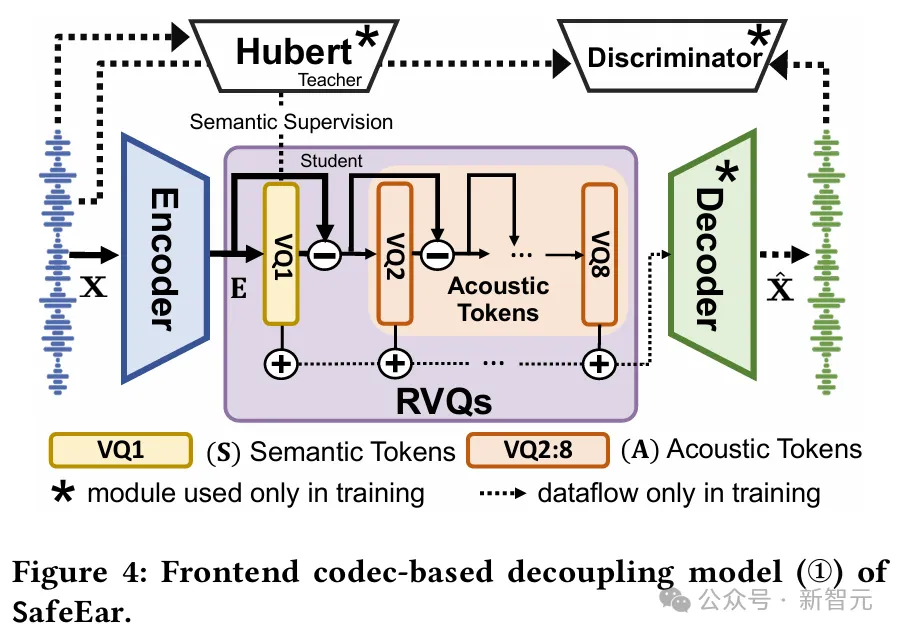
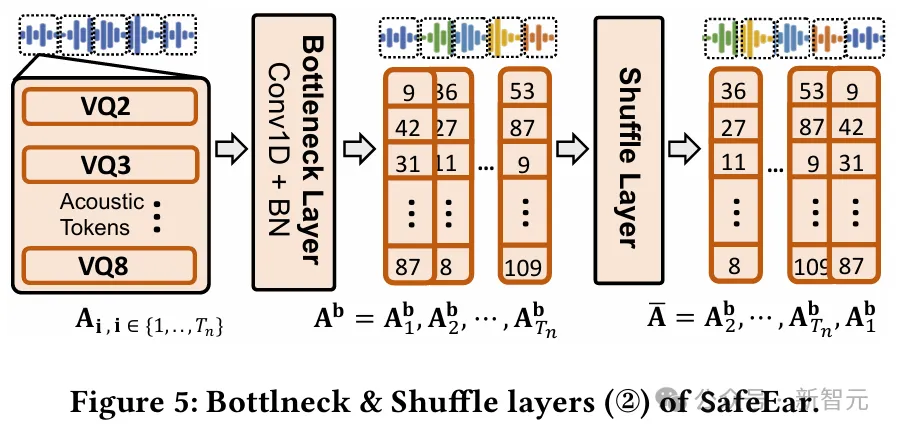
瓶颈层被用于特征降维表征和正则化处理。
混淆层对声学特征进行固定时间窗范围内的随机打乱重置,从而提升特征复杂度,确保内容窃取攻击者即便借助SOTA的语音识别(ASR)模型,也无法从声学特征中强行提取出语义信息。
最终,经过解缠和混淆双重保护的音频可以有效抵御人耳或者模型两方面的恶意语音内容窃取。
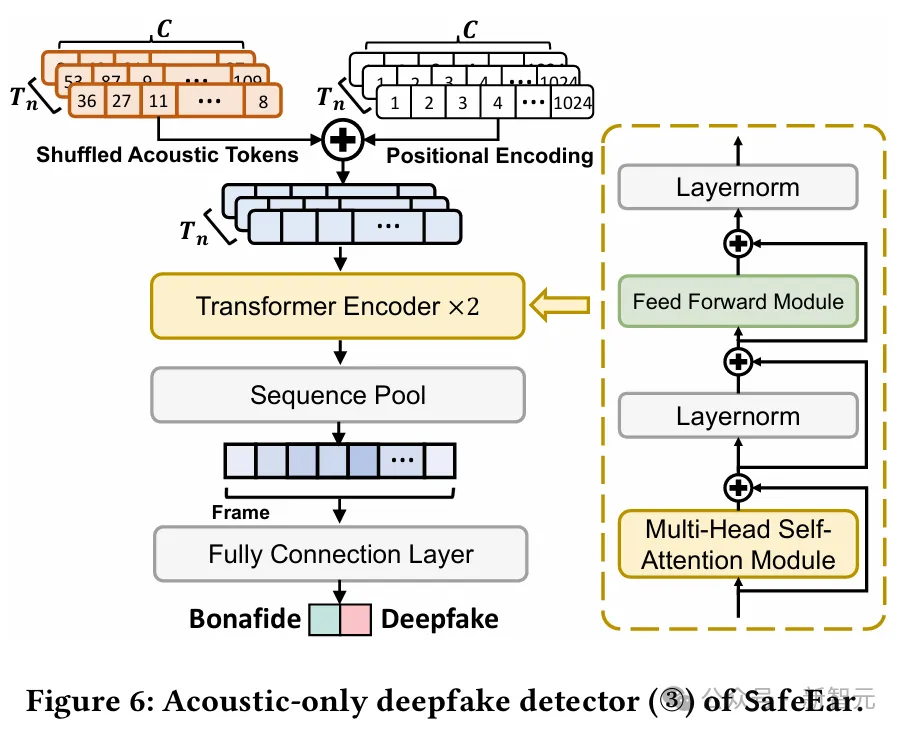
SafeEar框架的伪造音频检测后端设计了一种仅基于声学输入的Transformer-based分类器,采用正弦、余弦函数交替形式对语音信号在时域和频域上进行位置编码。
鉴于现实世界的信道多样性,采用具有代表性的音频编解码器(如G.711、G.722、gsm、vorbis、ogg)进行数据增强,模拟实际环境中带宽、码率的多样性,以推广到不可见通信场景。
效果如下:
不过,即使有了很多的进展和成果,防御DeepFake依旧是一项非常具有挑战性的任务,人们需要所有可能的帮助来保护他们在网上的身份和信息免受侵害。
除了用「魔法」对抗「模型」之外,英国的一个警察局最近也在测试一套能极大缩短侦查时间,并帮助破解陈年旧案的AI系统。

具体来说,这个名为「Soze」的工具,可以同时分析视频片段、金融交易、社交媒体、电子邮件和其他文档,从而识别在人工搜索证据过程中可能未被发现的潜在线索。
评估显示,它能够在短短30小时内分析完27起复杂案件的证据材料,相比之下,人类需要长达81年的时间才能完成这项工作。
显然,这对于在人员和预算限制方面可能捉襟见肘的执法部门来说吸引力巨大。
对此,英国国家警察局长委员会主席Gavin Stephens表示:「你可能有一个看起来不可能完成的悬案审查,因为材料太多了,但你可以把它输入这样的系统,系统可以吸收它,然后给你一个评估。我觉得这会非常非常有帮助。」
我们生活在了一个Deepfake泛滥的世界,或者说,是一个「矩阵模拟」的世界。
在这个世界中,没有真实,一切全是AI。
参考资料:
https://the-decoder.com/scammers-use-15-second-clip-to-create-ai-voice-clone-nearly-dupe-lawyers-father-out-of-30000/
https://www.snexplores.org/article/ai-deepfake-voice-scams-audio-tool
https://safeearweb.github.io/Project/
https://futurism.com/the-byte/police-department-ai-powered-detective-unsolved-crimes
文章来自于微信公众号“新智元”



【开源免费】MockingBird是一个5秒钟即可克隆你的声音的AI项目。
项目地址:https://github.com/babysor/MockingBird
【开源免费】Deep-Live-Cam是一个只需一张图片即可实现实时换脸和一键视频深度伪造的AI项目。
项目地址:https://github.com/hacksider/Deep-Live-Cam
【开源免费】ai-town是MIT授权的一个AI虚拟小镇,该项目可以让研发人员轻松构建和定制你自己的AI小镇版本,其中居住在小镇的AI角色可以进行交流和社交。该项目受到研究论文《生成代理:人类行为的交互模拟》的启发。
项目地址:https://github.com/a16z-infra/ai-town
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【部分开源免费】FLUX是由Black Forest Labs开发的一个文生图和图生图的AI绘图项目,该团队为前SD成员构成。该项目是目前效果最好的文生图开源项目,效果堪比midjourney。
项目地址:https://github.com/black-forest-labs/flux
在线使用:https://fluximg.com/zh
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
