# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
今年的诺贝尔物理学奖颁给了两位享誉盛名的 AI 研究者 John J. Hopfield 和 Geoffrey E. Hinton,这确实让很多人感到意外。
第一层疑问是:Hinton 和物理学有什么关系吗?
第二层疑问是:AI 科学家是如何提名物理学奖的?这程序合理吗?
连 GPT-4o 都不敢相信:

当然,更深层的质疑来自一些同赛道的 AI 科学家,比如挑战 Hinton 多年的 LSTM 之父 ——Jürgen Schmidhuber。
在统计物理学中,Hopfield 模型成为最常研究的 Hamiltonians 学派之一,关于它的论文和书籍已有数万篇。这个想法为数百名物理学家进入神经科学和 AI 领域提供了切入点。
在计算机科学中,Hopfield 网络是促使 AI 寒冬(1974-1981 年)结束以及随后人工神经网络复兴的主要驱动思想。Hopfield 在 1982 年发表的论文标志着现代神经网络时代的开始。
但 Jürgen Schmidhuber 认为:「诺贝尔物理学奖授予了计算机科学领域的剽窃和错误归属,主要涉及 Amari 的 Hopfield 网络和玻尔兹曼机。」
在发表于 X 平台的小作文中,Jürgen Schmidhuber 洋洋洒洒列了四条依据,内容如下:
1、Lenz-Ising 神经元递归结构发表于 1925 年。1972 年,甘利俊一(Shun-Ichi Amari)使其具有自适应能力,通过改变连接权重,学会将输入模式与输出模式联系起来。不过,在「2024 年诺贝尔物理学奖的科学背景」中,Amari 只是被简单引用。遗憾的是,Amari 的网络后来被称为「Hopfield 网络」。Hopfield 在 10 年后重新发表了它,但没有引用 Amari,甚至在后来的论文中也没有引用。
2、Ackley、Hinton 和 Sejnowski 的相关玻尔兹曼机论文是关于神经网络隐藏单元内部表征的学习。它没有引用 Ivakhnenko 和 Lapa 提出的第一个内部表征深度学习算法,也没有引用 Amari 通过随机梯度下降(SGD)在深度 NN 中端到端学习内部表征的独立工作(1967-68 年)。甚至连作者后来的调查和「2024 年诺贝尔物理学奖的科学背景」都没有提到深度学习的这些起源。玻尔兹曼机也没有引用 Sherrington & Kirkpatrick 和 Glauber 之前的相关工作。
3、诺贝尔奖委员会还称赞了 Hinton 等人 2006 年提出的深度神经网络分层预训练方法(2006 年)。然而,这项工作既没有引用 Ivakhnenko 和 Lapa(1965 年)对深度神经元进行分层训练的原始方法,也没有引用对深度神经元进行无监督预训练的原始方法。
4、如「主流信息」所说:「在 20 世纪 60 年代末,一些令人沮丧的理论结果让许多研究人员怀疑这些神经网络永远不会有任何实际用途」。然而,深度学习研究在 20 世纪 60-70 年代显然是活跃的,尤其是在英国以外的地区。
Jürgen 还表示,关于剽窃和错误署名的更多案例,可参见以下参考文献,可以从第 3 节开始:
《3 位图灵奖获得者如何重新发表他们未能归功于创造者的关键方法和想法》https://people.idsia.ch/~juergen/ai-priority-disputes.html
有关该领域的历史,请参阅以下参考文献:
《现代人工智能和深度学习的注释历史》
https://people.idsia.ch/~juergen/deep-learning-history.html
但情况真的如 Jürgen 所说吗?至少一些网友已经指出了表述中的问题:
「在机器学习中,那些无法真正证明其想法可行的想法论文比比皆是,而且往往不会被广泛阅读或采用。除此之外,我们实际上并没有一个统一的理论,因此不同的阵营使用完全不同的术语,直到你真正深入研究它,你才会意识到独立创建的各种模型之间存在数学等价性。」
维基百科词条中,关于 Hopfield 网络的简介如下:
第二个要添加的组成部分是对刺激的适应。中野薰(Kaoru Nakano)于 1971 年和甘利俊一(Shun'ichi Amari)于 1972 年分别对此进行了描述,他们提出通过 Hebbian 学习规则修改 Ising 模型的权重,使其成为联想记忆模型。William A. Little 于 1974 年发表了同样的想法,Hopfield 在 1982 年的论文中对他表示了感谢。
基本上,有 3 个不同的人想到使用 Hebbian 学习进行联想记忆。因此 Hopfield 将这个想法归功于他所知道的人,尽管看起来 Amari 更早(或许 Nakano 甚至比 Amari 还早)。
还有网友说,玻尔兹曼机论文并没有使用反向传播、Hebbian 学习或 Schmidhuber 认为没被引用的任何方法。这篇论文本身并没有说它发明了第一个学习算法,只是说它发现了一种可以产生有用且有趣的中间表示的学习算法。
而 Hinton 早就在几年前解释过 Jürgen Schmidhuber 指出的问题,并表示「从此不会再做出任何回应」。
与 Schmidhuber 就学术信用问题进行公开辩论并不可取,因为这只会助长他的气焰,而且他会不惜花费大量时间和精力来诋毁他所认为的对手。他甚至不惜使用维基百科中的多重别名等伎俩,让别人看起来似乎同意他的说法。他网站上关于艾伦・图灵的页面就是一个很好的例子,说明他是如何试图削弱其他人的贡献的。
尽管我有最好的判断力,但我觉得我不能完全不回答他的指控,所以我只回应一次。我从未声称反向传播是我发明的。David Rumelhart 是在其他领域的人发明反向传播很久之后才独立发明它的。的确,当我们第一次发表论文时,我们并不了解这段历史,所以我们没有引用之前的发明者。我所声称的是,是我清楚地证明了反向传播可以学习有趣的内部表征,而这正是它广受欢迎的原因。我是通过强迫神经网络学习单词的向量表征来做到这一点的,这样它就能根据前一个单词的向量表征来预测序列中的下一个单词。正是这个例子说服了《自然》杂志的审稿人发表了 1986 年的论文。
的确,媒体上有很多人说我发明了反向传播,我也花了很多时间来纠正他们。以下是 Michael Ford2018 年出版的《智能架构师》(Architects of Intelligence)一书的节选:
在 David Rumelhart 之前,很多不同的人发明了不同版本的反向传播。他们主要是独立的发明,我觉得我的功劳太大了。我在媒体上看到有人说是我发明了反向传播,这完全是错误的。这是一个罕见的例子,一个学者觉得他在某件事情上获得了太多的荣誉!我的主要贡献是展示了如何使用它来学习分布式表征,所以我想澄清这一点。
也许 Jürgen 想澄清是谁发明了 LSTM?
在诺贝尔奖的物理学奖和化学奖分别颁发给 AI 之后,大家开始怀疑:莫非今年的诺贝尔文学奖要颁给 ChatGPT?
面对诺贝尔奖评选结果的多重「意外」,顶刊也是早有预料了。
前两天,Nature 杂志就发表了一篇社论,炮轰诺贝尔奖在全球范围内代表性不足,提名过程必须更加公开透明。
类似于 AI 的推理过程还是个「黑盒」,诺贝尔奖的评选过程也是一个有点像「黑盒」的机制,提名人和被提名人名单在评奖结果公布之前必然严格保密,被提名名单更是要保密 50 年。因此,诺贝尔奖评选的具体细节,我们无从得知。
为了预测下一年的诺贝尔奖得主,人们只能从往年的获奖者中寻找规律。于是,一直有传言称,诺贝尔文学奖的评选存在一个不成文的规定,即来自五大洲的作家轮流获奖。
与此相对照的是,负责评选诺贝尔奖的组织表示过,他们正在积极努力提升诺贝尔奖得主的多样性,并且已经取得了显著进展。整个 20 世纪,诺贝尔化学奖、物理学奖以及生理学或医学奖仅有 11 次被授予女性;而在 2000 年至 2023 年间,这个数字就提升到了 15 次。
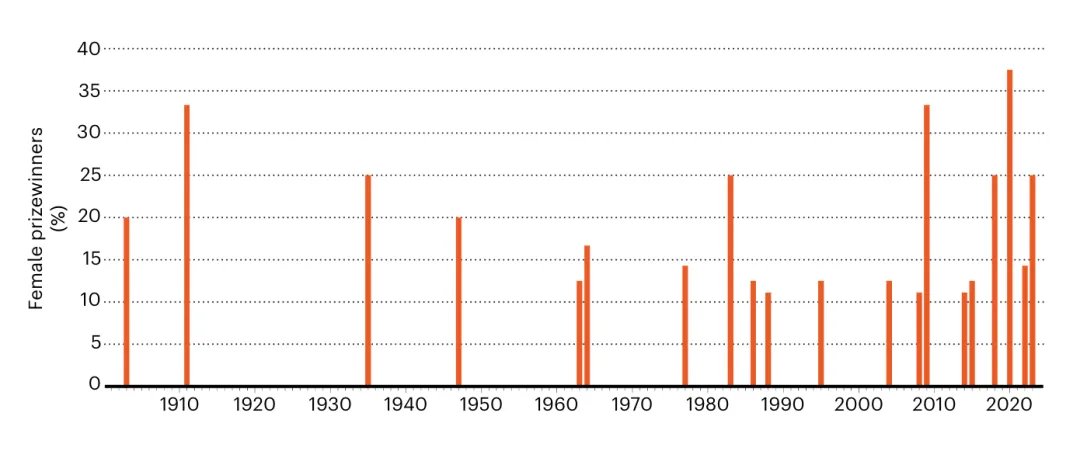
1910 年 - 2020 年女性获得诺贝尔奖的数量变化
虽然性别的多样性取得了可喜的进展,但大家似乎已经习惯了科学界权力和资金分配在全球范围内的不均衡,往往忽视了这一点。在诺贝尔奖的历史中,只有 10 位获奖者出生于目前被世界银行归类为中低收入以下的国家,并且他们中的绝大多数在获奖时已经移居北美或欧洲。
正如《TWAS at 20(第三世界科学院 20 年)》这本书中所写,四十年前,许多非发达地区的科学家面临着艰难的选择:「背弃你的家乡,专注于职业生涯;或者留在家里,献祭你的职业生涯。」
在更隐秘的角落,诺贝尔奖之上还笼罩着一层巨大而无形的「人情网」。Nature 的调查显示,无论看起来有多离谱,几乎所有诺贝尔奖得主都存在某种联系。令人惊讶的是,获得科学类以及经济学奖项中的 736 位得主,其中有 702 位属于同一个学术家族 —— 他们通过学术关系在历史的某个节点彼此相连。
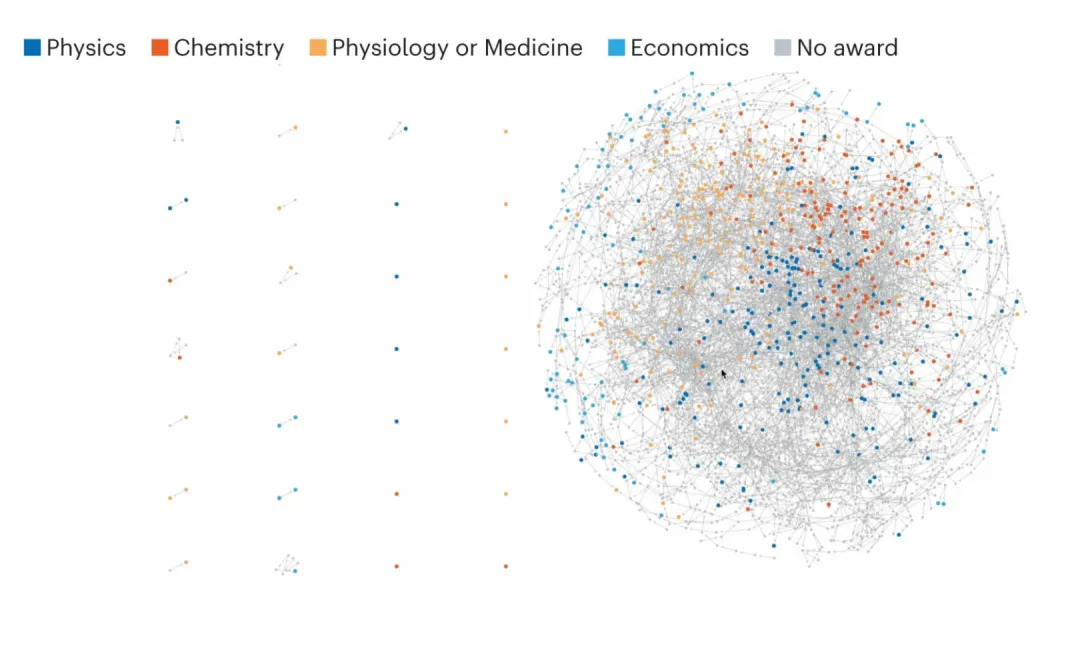
这可能与诺贝尔奖提名采用邀请制有关。根据诺贝尔基金会章程,历届诺贝尔奖得主、瑞典、丹麦、芬兰、冰岛和挪威的大学教授、瑞典皇家科学院成员以及相关诺贝尔奖评审委员会成员可以无需许可,直接提名候选人。其他有资格参与评奖的人则必须获得官方邀请函,才能提名入围名单。
提名过程分为两个阶段:首先高级领导、院长和教授们收到诺奖官方的信件;然后,被这些被选中的科学家们按照标准进行提名。来自斯德哥尔摩大学的 Peter Brzezinski 对 Nature 表示,瑞典皇家科学院今年联系了大约 1250 所大学。但由于人力有限,平均每五年,每所大学只会收到一次邀请。
这种情况可能是诺贝尔在设立奖项时未曾预见的。诺贝尔奖的评选历史已接近 120 年,当初科学研究还是个小众领域。20 世纪初,全世界的物理学家大约只有 1000 人,而如今广义上的物理学家已多达数百万。
诺贝尔奖的揭晓再次激起了世人对科学与技术的热情,但如何在当今科技日新月异的时代设立一个更加全面和包容的评奖机制,确实也是不容忽视的重要议题。
文章来自于微信公众号“机器之心”



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
