# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
多模态大语言模型(MLLM)如今已是大势所趋。
过去的一年中,闭源阵营的GPT-4o、GPT-4V、Gemini-1.5和Claude-3.5等模型引领了时代。
而开源MLLM也同样在蓬勃发展,LLaVA系列,InternVL2,Cambrian-1和Qwen2-VL的强劲表现,让作为老大哥的GPT-4o时常躺枪。

开源与闭源之间差距缩小,兼具单图、多图、视频理解能力的MLLM也成为大家研究的重点。
说到潮流,怎么能没有苹果的一席之地?
近日,一向画风精致的「苹果牌AI」,也推出了升级版的多模态大模型——MM1.5。

论文地址:https://arxiv.org/pdf/2409.20566
MM1.5以前代MM1模型为基础,采用数据为中心的方法进行训练,显著增强了文本密集型图像理解、视觉指代和定位、以及多图像推理的能力。
MM1.5系列的参数量从1B到30B,涵盖密集和专家混合(MoE)模型,即使较小的尺寸也有优异的表现。
具体来说,MM1.5提升了OCR(光学字符识别)能力,支持任意图像长宽比和高达4M像素的分辨率,并且擅长理解富含文本的图像。

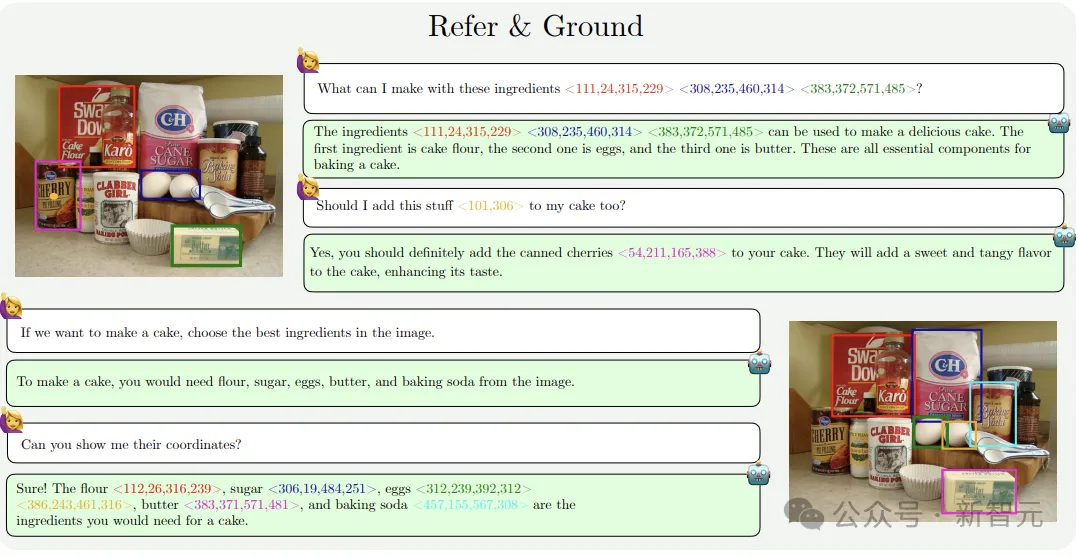
在强大而细粒度的图像理解能力加持下,MM1.5能够超越文本提示来解释视觉内容,例如点和边界框。
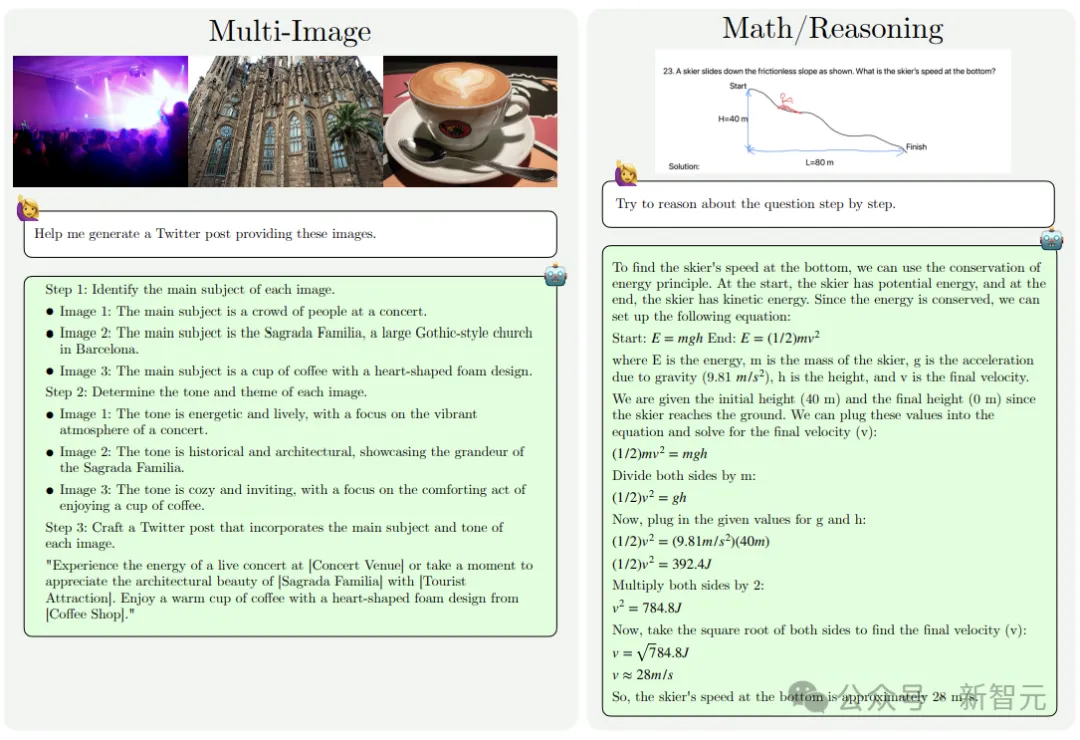
研究人员还通过对额外的高质量多图像数据进行监督微调(SFT),进一步提高了模型的上下文学习和开箱即用的多图像推理能力。
本文作者重点关注两种小规模的MLLM,包括1B和3B的密集模型与MoE模型,其中小尺寸的密集模型可以轻松部署在移动设备上。
「小模型」也符合苹果一贯的作风,在自家的各种设备上,能够更好地与用户场景(如隐私和安全性)融为一体。
之前微软和苹果的很多实践也证明了,利用高质量数据和先进的训练策略,小个子的模型在各种下游任务中同样表现强劲,足以超越大尺寸的模型。

当然了,光是小还不够,通用性更为重要。
MM1.5系列模型在30B参数的范围之内,都能很好地符合缩放定律,模型越大,性能越强。
另一方面,研究人员以MM1.5为基础,微调出服务于视频理解的MM1.5-Video,以及为移动UI(比如iPhone屏幕)理解定制的MM1.5-UI。
MM1.5保留了与MM1相同的模型架构,并将改进的努力集中在以下几个关键方面:
作者在SFT阶段之前引入了一个额外的高分辨率连续预训练阶段,这对于提高富含文本的图像理解性能至关重要。
作者探索了用于持续预训练的富含文本的OCR数据,重点关注图像中文本的详细转录,还尝试了高质量的合成图像字幕。
混合中的每一类SFT数据如何影响最终模型的性能?特别是支持每种功能的数据对其他功能有何影响,作者对此进行了广泛的消融实验。
对于高分辨率图像编码,作者遵循流行的任意分辨率方法,将图像动态划分为子图像,并进行彻底的消融以细化设计中的关键细节。
为了保留前代模型的零样本和少样本学习能力,并更有效地将它们转移到SFT阶段,在开发MM1.5时,研究人员通过探索纯文本数据的影响,并优化不同预训练数据类型的比例,来进一步扩展MM1的预训练。
这种方法提高了知识密集型基准测试的性能,并增强了模型整体的多模态理解能力。
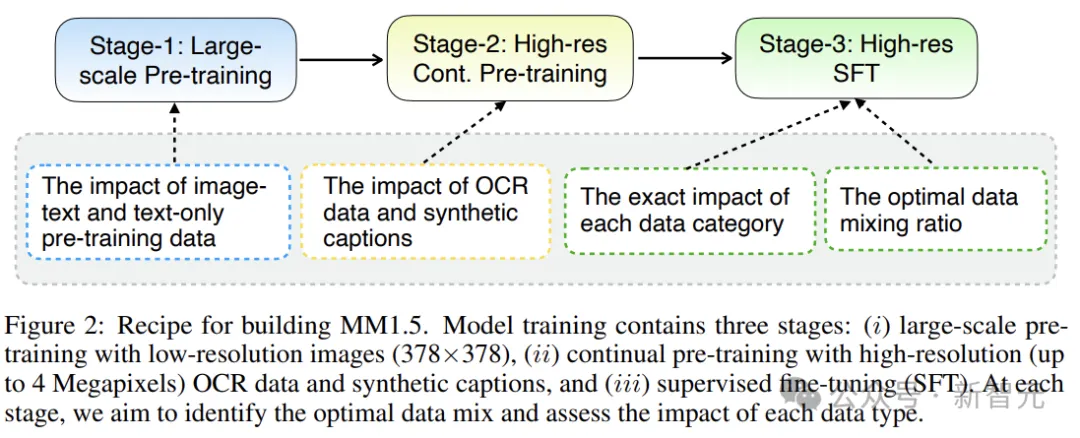
如上图所示,模型训练包含三个阶段:
(i) 使用低分辨率图像 (378×378) 进行大规模预训练;
(ii) 使用高分辨率(高达4M像素)OCR数据和合成字幕进行持续预训练;
(iii) 监督微调(SFT)。
在每个阶段,都需要确定最佳数据组合并评估每种数据类型的影响。
在消融研究中遵循以下默认设置:
静态图像分割通过4个子图像分割(加上一个概览图像)来实现,并且每个子图像通过位置嵌入插值调整为672×672分辨率。为了加快实验迭代速度,在消融过程中没有使用动态图像分割。
对于多图像数据的编码,仅当当前训练样本包含少于三幅图像时才启用图像分割,以避免序列长度过长。
如下图所示,模型可以以引用坐标和边界框的形式,解释对输入图像中的点和区域的引用。
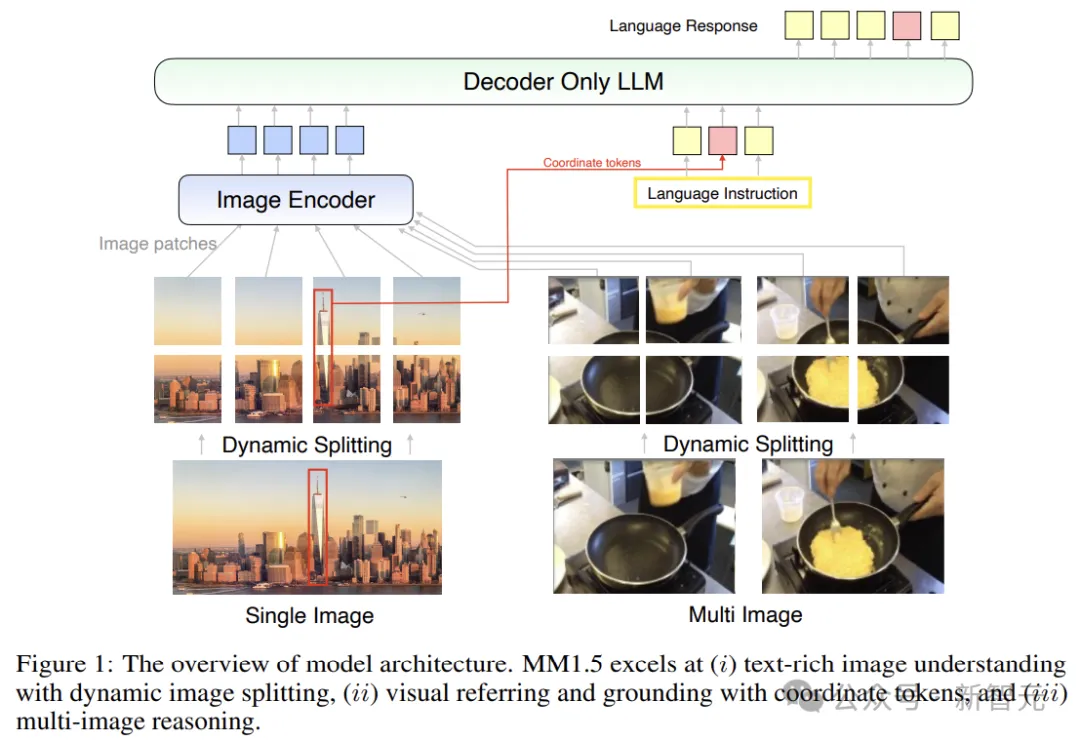
MM1.5采用与前代相同的CLIP图像编码器和LLM主干网络,并以C-Abstractor作为视觉语言连接器。
对于连续预训练和SFT,作者将批量大小设置为256。使用AdaFactor优化器,峰值学习率为1e-5,余弦衰减为0。对于连续预训练,最多训练30k步。在SFT期间,所有模型都针对一个epoch进行优化。
模型使用MM1的预训练检查点进行初始化。这个阶段对45M高分辨率OCR数据(包括PDFA、IDL、Renderedtext和DocStruct-4M)进行持续的预训练,每个训练批次从这四个数据集中均匀采样数据。
与SFT阶段类似,作者使用静态图像分割,将每个图像分为五个子图像,每个子图像的大小调整为672×672分辨率。作者发现这种高分辨率设置对于持续预训练至关重要。
最后,将数据集分组有助于数据平衡和简化分析。在较高层面上,作者根据每个示例中呈现的图像数量将数据集分为单图像、多图像和纯文本类别,详细的分类情况如下图所示:
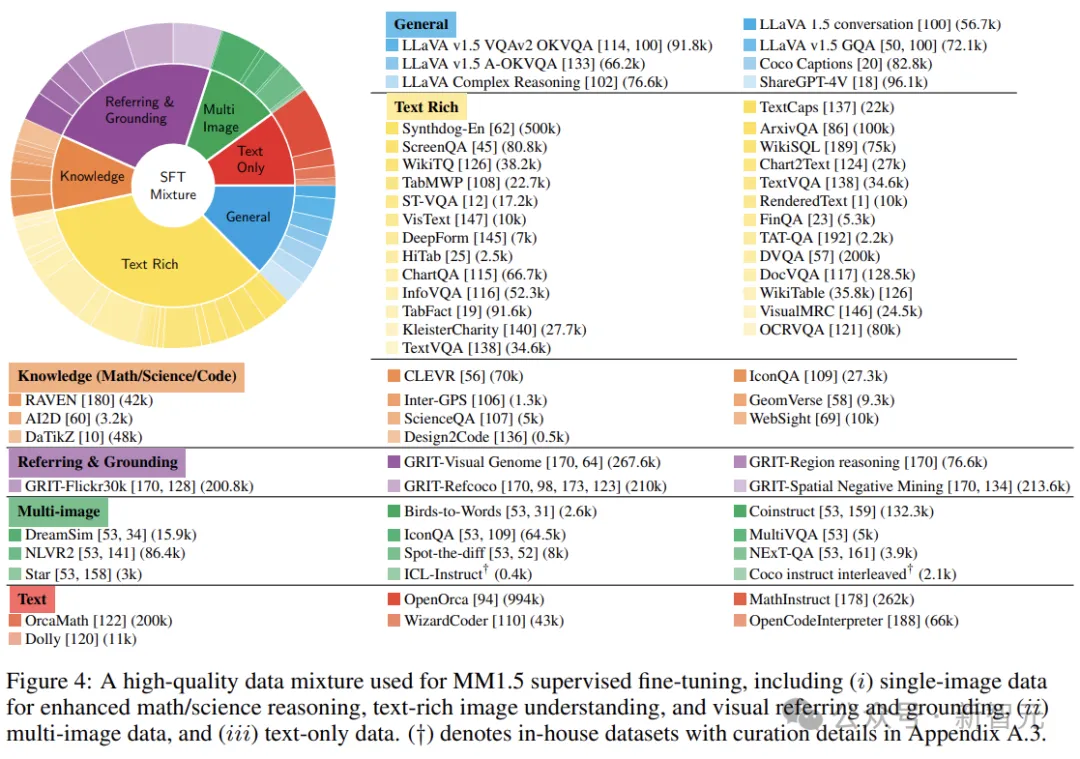
研究人员根据主要衡量的功能将基准分为几类,并提出类别平均分数(每个子类别的所有基准数字的平均分数),以代表该功能的平均性能。
然后是对于SFT数据混合的全面消融。作者首先评估一般数据类别,然后逐步评估单独添加其他子类别的影响。
在训练过程中,作者混合来自不同子类别的数据,通过从混合物中随机采样数据来构建每个训练批次,并使用类别平均得分来比较使用每种功能的模型,结果如下图所示。
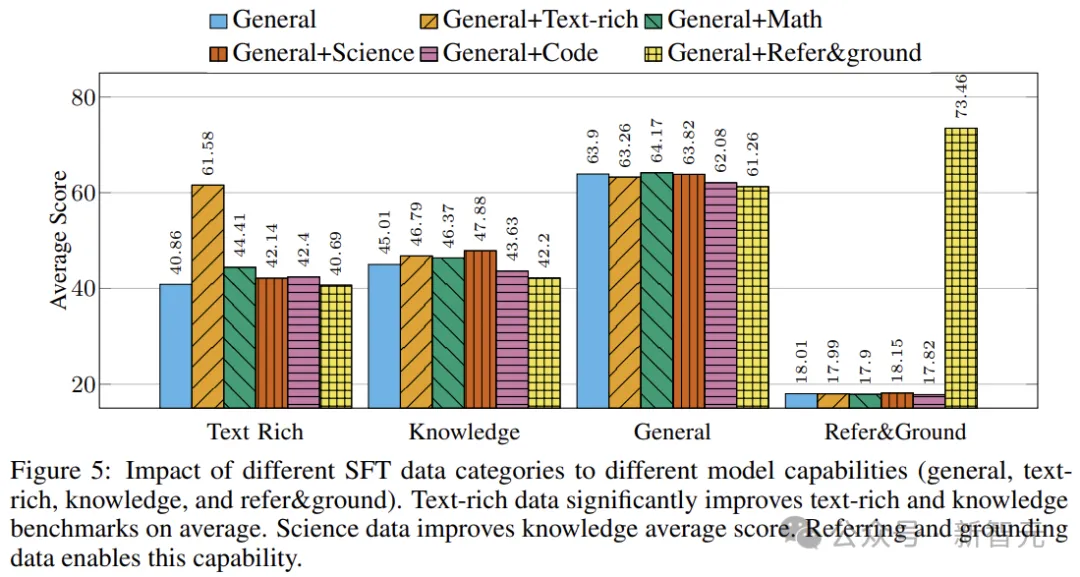
作者观察到,添加富含文本的数据可以显著提高文本密集型和知识基准的性能,数学数据也遵循类似的趋势。
以一般数据类别为参考,对目标类别数据进行上采样/下采样,使得在每个训练批次中,一般数据类别和目标类别的数据比例为1:α。
为了衡量α的平均影响,作者提出MMBase分数用于模型比较。如下图所示,作者针对不同的数据类别改变α。对于科学、数学和代码类别,作者发现α的最佳比率分别为0.1、0.5和0.2。

下一项需要探究的是单图像、多图像和纯文本数据的混合比例。
枚举三个比率之间的所有组合将产生大量的计算成本。因此,作者分别对纯文本数据和多图像数据进行消融,以评估模型对比例的敏感程度。
对于纯文本数据,作者测试了0到0.2的范围,下图结果表明,不同的w值对模型的基础影响较小。
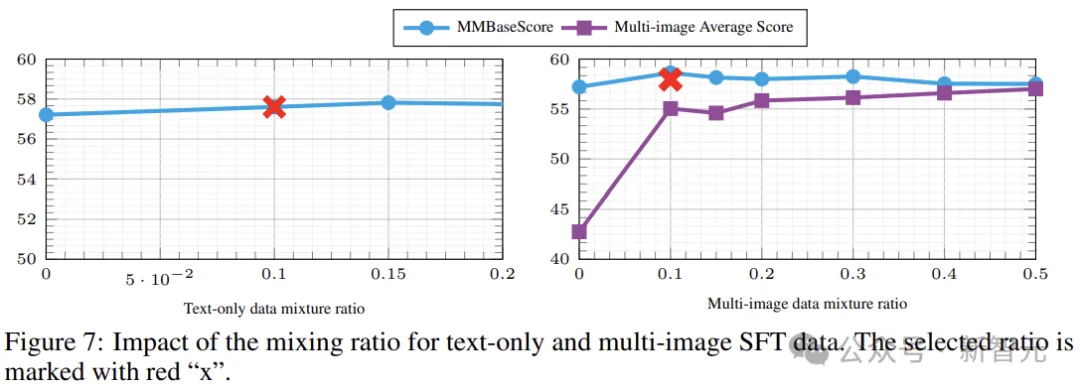
通过图7(右)还可以观察到,增加多图像数据的采样率会导致基本功能的性能下降(MMBase分数减少),而多图像平均分数会增加。所以作者选择w= 0.1为单图像数据分配更高的权重,以提高潜在的性能。
基于上述研究,作者提出了三种混合:基础混合、单图像混合、全混合。
下图前三列表明,包含参考数据和多图像数据会稍微降低密集文本、知识和一般基准的平均性能。
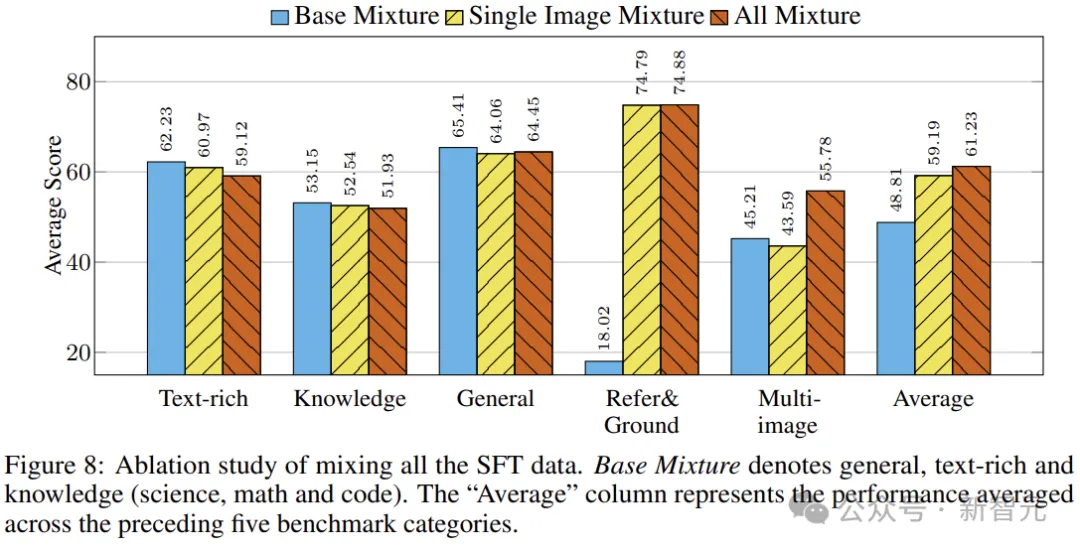
最后一栏表明,作者优化的组合实现了最佳的整体性能,平衡了基准测试中的所有功能。

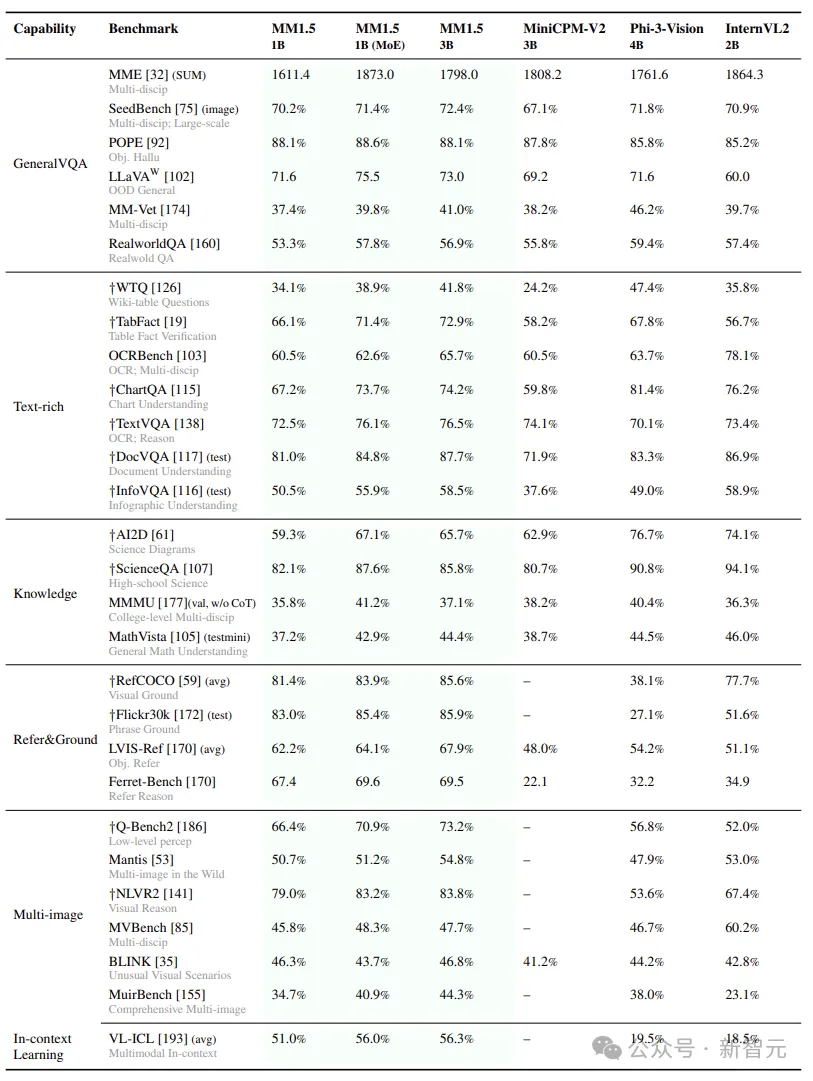
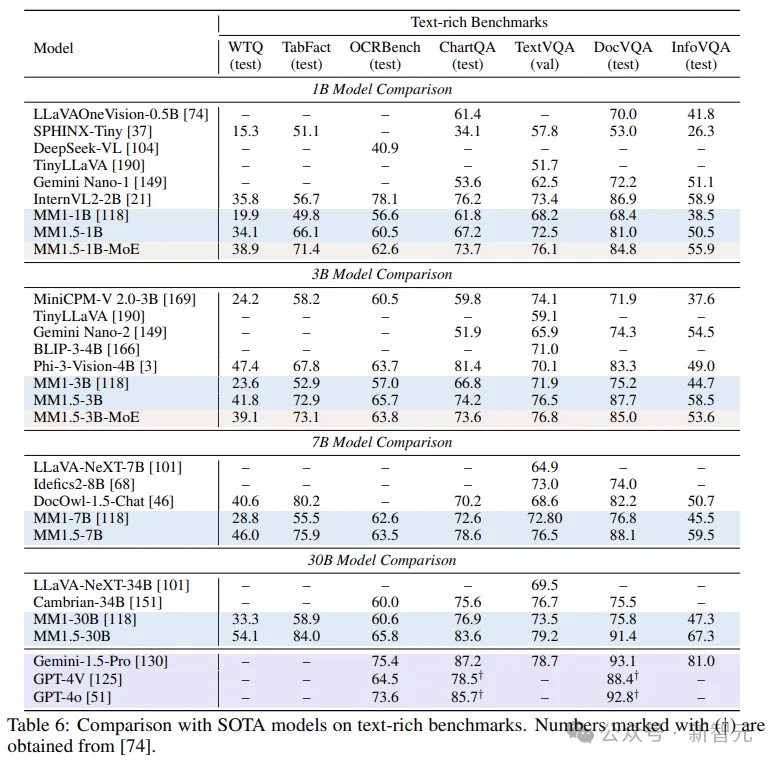
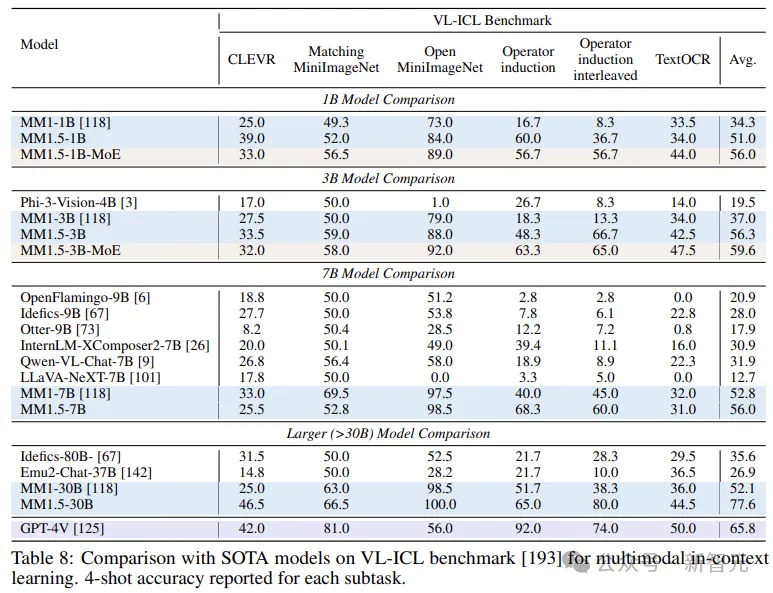
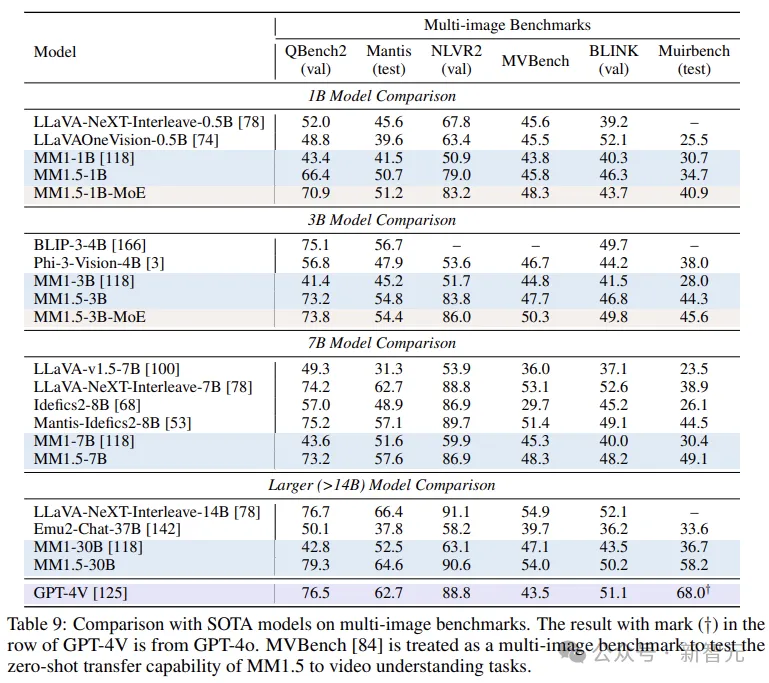
最后,放几张跑分对比,包括Text-rich、In Context Learning和Multi-image:
参考资料:
https://arxiv.org/pdf/2409.20566
文章来自于 微信公众号“新智元”




【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
