# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
近期在LLM方面,AI搜索热度居高不下,遥感业务也能做AI搜索。
最近关注到国外开发者完成了几个基于文本检索遥感影像的demo,尝试对其进行进一步解读,将从技术角度详细解析该过程的实现逻辑,读者可以自己尝试复现。
直接通过自然语言对图像进行查询是一项具有挑战性的任务。
传统方法往往依赖于图像的元数据或标签,而更先进的方法则利用 向量嵌入(vector embeddings) 技术,将图像和文本表示映射到同一向量空间,以实现高效的查询和匹配。
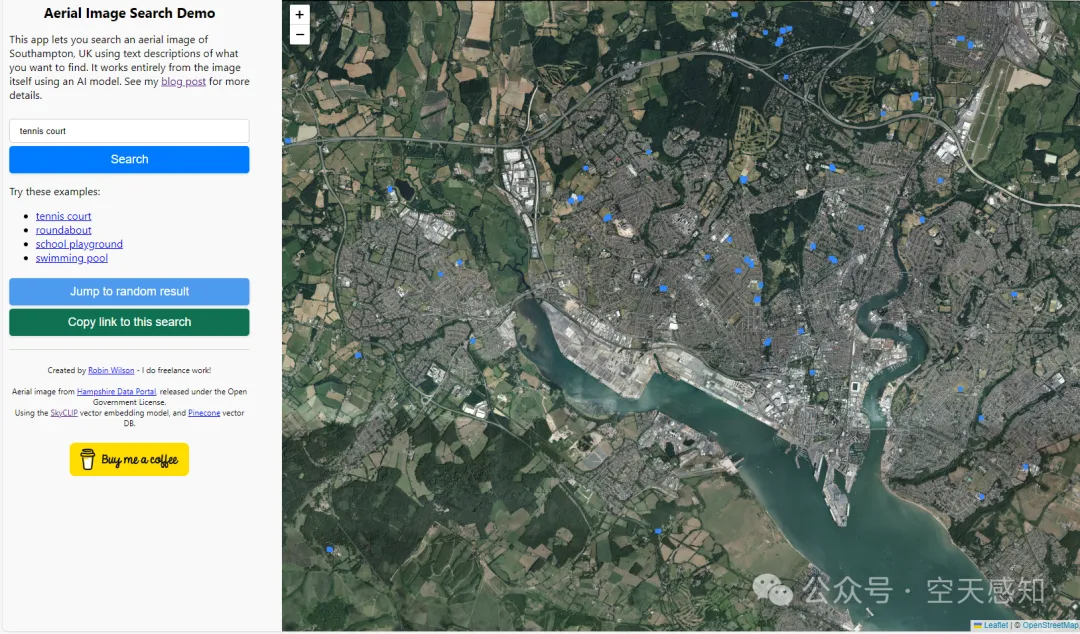
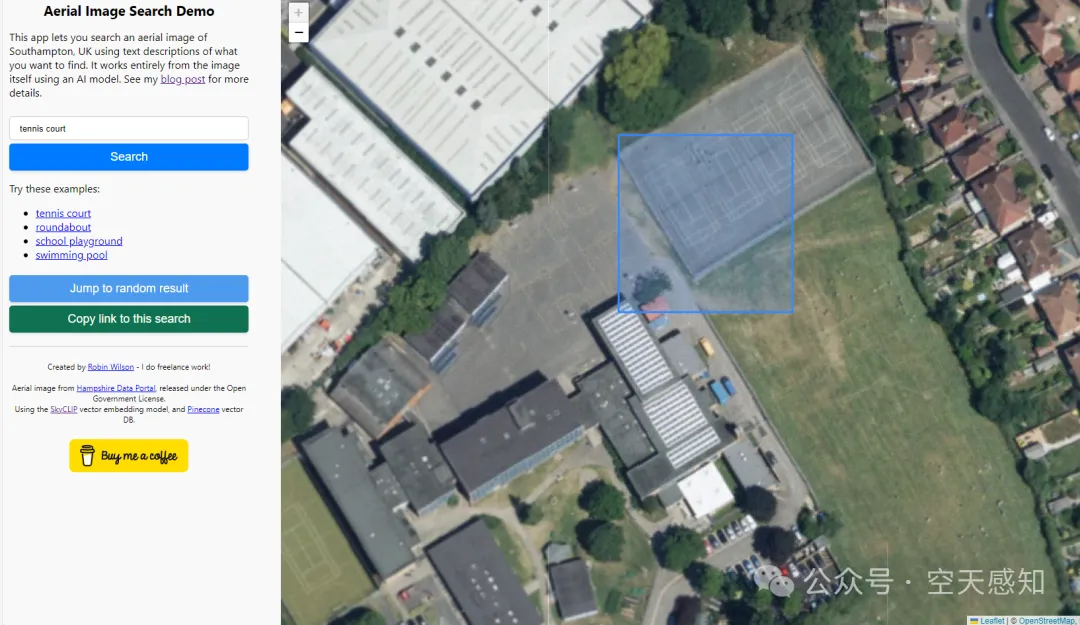
这个demo的前端页面很简单,预置了几个关键词,当我们输入tennis court时,图上会有多个框选结果,放大细节查看,确实是网球场。
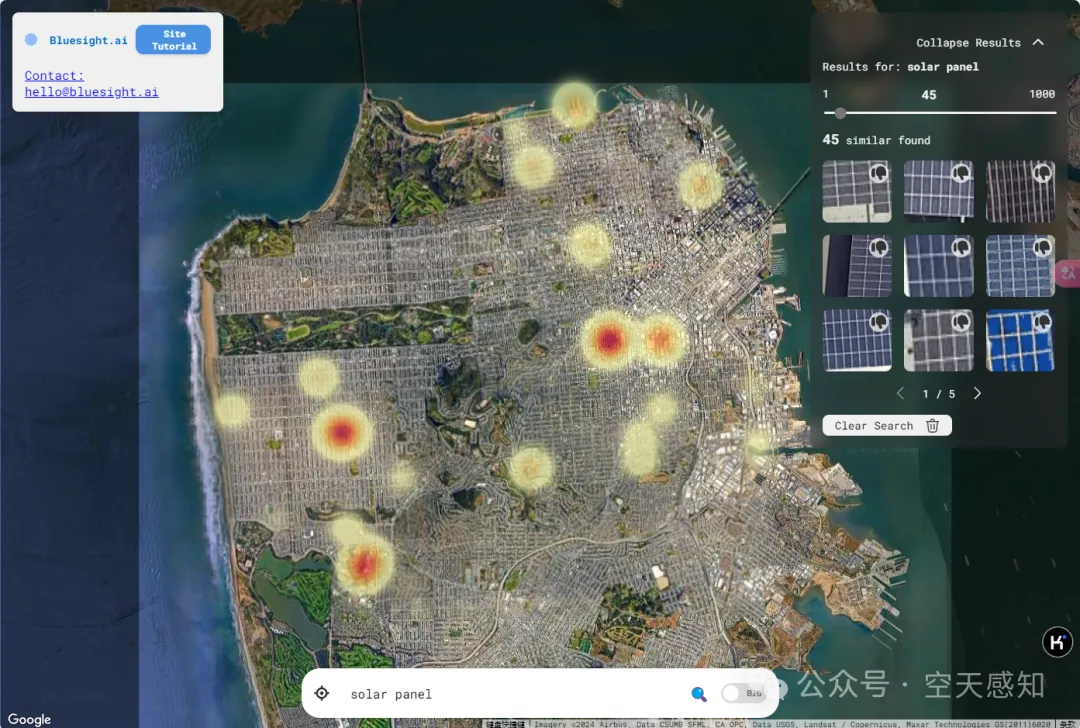
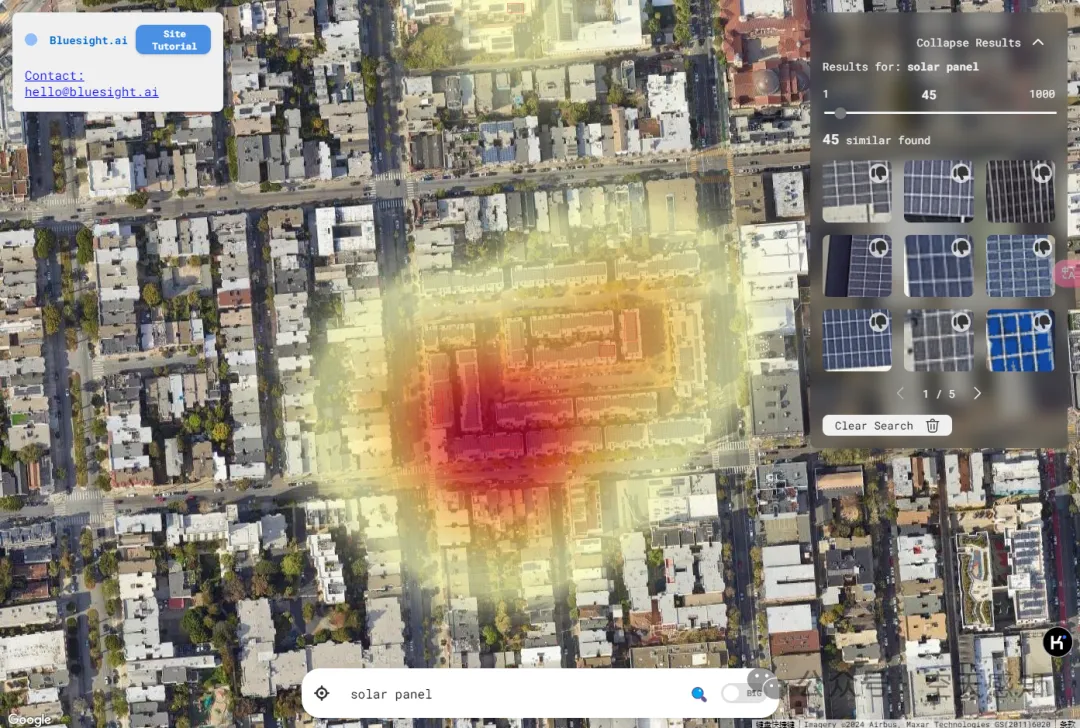
第二个应用稍微有点花样,当我们手动搜索solar panel时,列出了可检出的所有关键图像信息,并且对图上内容还以热力图进行反馈。
下面以Aerial Image Search Demo为例,给出实现过程
首先,理解向量嵌入对于整个系统至关重要。向量嵌入的基本原理是将多种类型的数据(如图像、文本)转化为固定维度的向量。在这个向量空间中,语义相似的对象会被映射到相近的位置。
例如,两个描述相似内容的文本(如“网球场”和“运动场”)会生成相似的向量,这使得它们可以在相同的向量空间中比较相似度。
向量嵌入的实际应用: 在已完成的影像查询系统中,使用了SkyCLIP模型,它是一个结合了图像和文本配对的嵌入模型,能够将图像和文本嵌入到相同的768维向量空间中。这意味着每个输入,无论是图像还是文本,都可以转化为一个长度为768的向量,表示其语义信息。
Wangzhecheng等提出的SkyCLIP模型简介。
SkyScript是一个为遥感图像设计的大规模语义多样化的图像-文本数据集,包含520万对图像-文本对,覆盖超过29K个不同的语义标签。该数据集旨在帮助开发适用于遥感图像的任务无关视觉语言模型(VLMs),并已在AAAI 2024会议上发表。数据集通过连接OpenStreetMap(OSM)和多源、多分辨率遥感图像,提供了丰富的语义多样性。此外,还提供了模型实现、下载链接和使用指南。
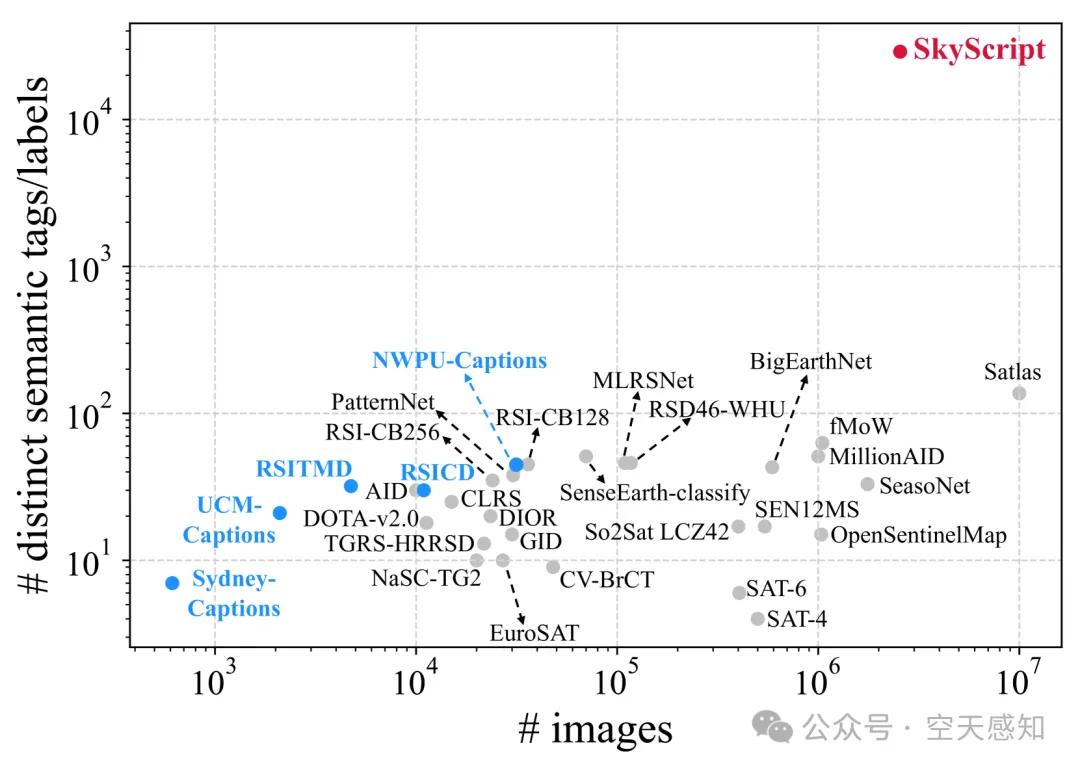
SkyScript数据集的语义多样性比现有的遥感图像文本数据集高出两个数量级
在进行图像查询时,首先需要对整个遥感影像进行处理。为了保证模型可以处理大幅图像,将其分割为多个小片段是必要的步骤。这些小片段被称为图像片段(image chips),每个片段经过模型处理后生成对应的嵌入向量。
使用RasterVision库来完成图像的分块操作。
Raster Vision是一个开源的Python库和框架,用于构建针对卫星、航空和其他大型图像集(包括倾斜无人机图像)的计算机视觉模型。它支持使用PyTorch后端进行芯片分类、目标检测和语义分割。作为一个低代码框架,它允许用户快速配置实验,执行机器学习管道,包括分析训练数据、创建训练芯片、训练模型、创建预测、评估模型和打包模型文件及配置以便于部署。Raster Vision还支持在云中使用AWS Batch和AWS Sagemaker运行实验。

分块的过程通过滑动窗口技术实现,定义每个图像片段的大小以及相邻片段的重叠区域。例如,将图像片段定义为200×200像素,并设定100像素的重叠区域,保证每个图像部分都有足够的细节被处理。
下面的代码展示了如何配置并生成滑动窗口的数据集:
ds = SemanticSegmentationSlidingWindowGeoDataset.from_uris(
image_uri=uri,
image_raster_source_kw=dict(channel_order=[0, 1, 2]),
size=200,
stride=100,
out_size=224,
)
生成的图像片段随后会被调整为224×224像素,这是SkyCLIP模型所需要的输入尺寸。模型会将每个图像片段转化为768维的向量表示,供后续查询匹配使用。
通过以下代码可以对图像片段进行遍历,并计算每个片段的嵌入向量:
dl = DataLoader(ds, batch_size=24)
EMBEDDING_DIM_SIZE = 768
embs = torch.zeros(len(ds), EMBEDDING_DIM_SIZE)
with torch.inference_mode(), tqdm(dl, desc='Creating chip embeddings') as bar:
i = 0
for x, _ in bar:
x = x.to(DEVICE)
emb = model.encode_image(x)
embs[i:i + len(x)] = emb.cpu()
i += len(x)
# normalize the embeddings
embs /= embs.norm(dim=-1, keepdim=True)
这段代码使用PyTorch进行批量处理,并将生成的嵌入结果存储为矩阵。在此过程中,通过torch.inference_mode()提升了推理速度,并确保内存占用最小化。
当用户输入查询文本(例如“网球场”)时,需要将文本嵌入同一向量空间中。这是文本-图像查询的关键步骤。文本查询同样可以被转化为768维的向量,并且该向量可以直接与图像嵌入向量进行比较。
以下代码展示了如何对文本进行嵌入计算:
text = tokenizer(text_queries)
with torch.inference_mode():
text_features = model.encode_text(text.to(DEVICE))
text_features /= text_features.norm(dim=-1, keepdim=True)
text_features = text_features.cpu()
与图像嵌入类似,文本嵌入也需要进行归一化处理,确保不同数据类型的向量能够在相同的尺度下进行相似度计算。
在获得图像片段和文本的嵌入向量后,接下来的任务是通过计算它们的相似度,找到最符合查询要求的图像片段。这里使用的是余弦相似度,其结果范围在-1到1之间,值越接近1表示向量越相似。
为了加速检索过程,利用了向量数据库技术。向量数据库可以高效存储大规模向量,并通过快速搜索返回与查询向量最接近的结果。
示例项目中使用了Pinecone,一个云原生向量数据库,用于存储图像片段的嵌入向量及其对应的位置信息。这样,每当用户输入查询文本时,系统会通过Pinecone数据库快速找到相应的图像片段。
通过结合先进的遥感大模型、Embedding等技术,实现了基于文本检索遥感影像的技术,展示了如何将自然语言与遥感图像相结合,为用户提供了一种简洁、直观的图像查询方式。
文章来自于微信公众号“测绘学术资讯”




【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
