# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
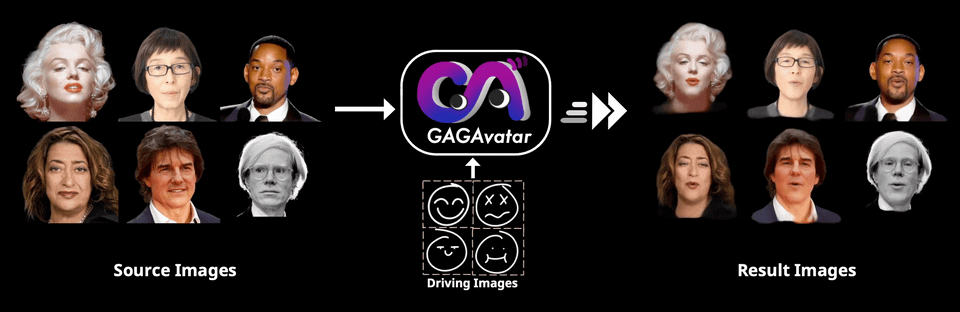
GAGAvatar是一项开创性的技术,能够从一张图片中快速重建高保真、可动画的3D头像,并实现实时面部表情驱动。现有的3D头像重建方法大多依赖于神经辐射场(Neural Radiance Fields),这虽然能实现较为精细的效果,却牺牲了渲染速度,无法满足实时交互的需求。GAGAvatar的出现正是为了解决这一瓶颈,通过一次前向传播就能生成3D高斯参数,实现高效的渲染与动画驱动。
双重提升法是GAGAvatar提出的关键技术,它能生成具有丰富面部细节的3D高斯体,不仅高度还原个体面部特征,还能通过控制这些高斯体来实现精准的表情再现。这种突破性的方法结合了全球图像特征与3D可变形模型,使得表情控制更加流畅自然。(链接在文章底部)
GAGAvatar方法分为两个主要部分:一个是“重建分支”,另一个是“表情控制分支”。重建分支用来构建初步的结果,而表情控制分支负责生成表情和姿势。生成表情时,只需要反复运行一小部分步骤,而其他的部分只需要运行一次就行了。
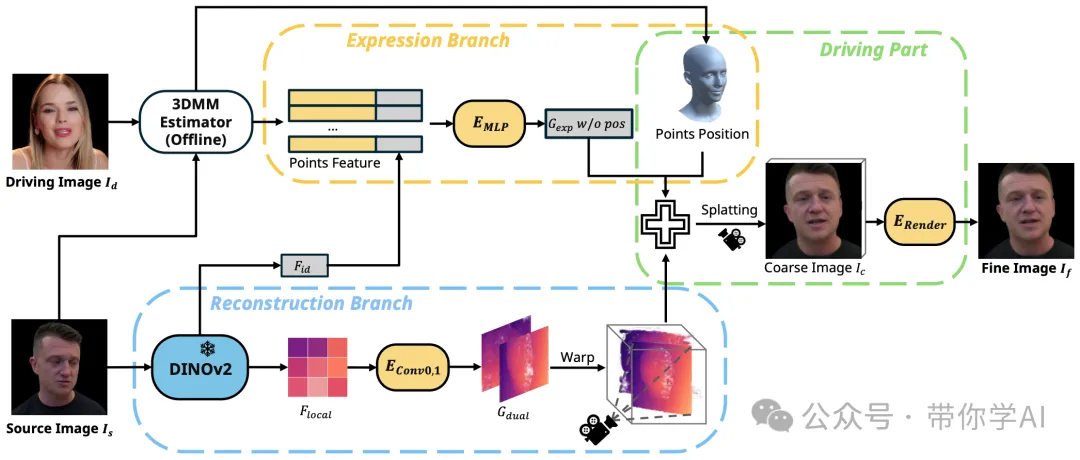
GAGAvatar方法是这样运作的。首先,给定一个图片(比如你自己的照片),然后使用DINOv2算法提取这个图片里的重要特征信息。这些特征可以分为“全局的”和“局部的”。接下来,根据局部特征,运用一种叫“双重提升”的方法,预测出两个3D的高斯分布——这就好像是用数学方式估计出两团3D的“模糊云”。同时,还会给3DMM模型的每个顶点(相当于3D脸部模型的点)分配一些可以调整的参数,并结合全局和顶点特征,预测出另一个表情用的高斯分布。为了简单,直接使用3DMM模型的顶点位置作为表情的“模糊云”的位置。
接着,把这些高斯分布结合起来,通过一种叫“splating”的方法生成一个粗略的图片(这个图片已经带有了想要的表情和姿势)。最后,再通过神经渲染器对这张粗略图片进行精细化处理,生成最终的高质量图片。
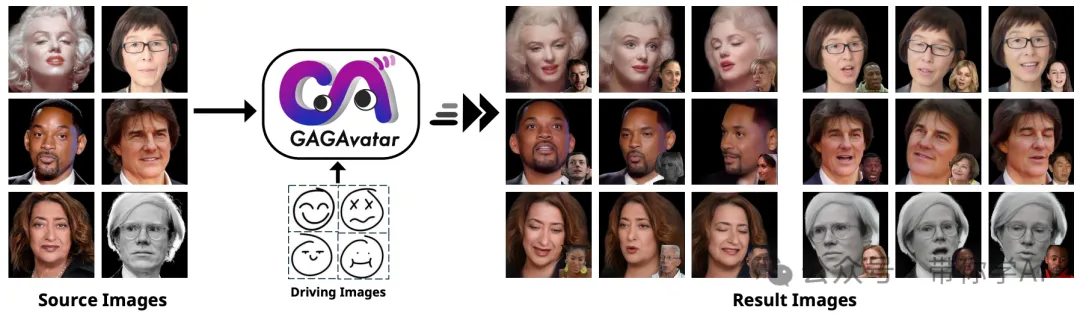
一张参考图,一张表情图,单角度图像:可以看出替换效果非常好,面部细节没有破坏,面部整体形状流畅。

一张参考图,一张表情图,多角度3D渲染:可以看出整体渲染非常高清和完整,面部和后部一致性高。

GAGAvatar方法在头像重建质量和重现精度上都超越了现有的最佳方法,同时渲染速度也大幅提升。尽管GAGAvatar方法有很多优点,但也有一些限制。比如,模型在一些未见区域可能细节表现不佳,而且基于3DMM的表情控制只能作用于已建模的部分,对于头发和舌头等区域则无法控制。
https://arxiv.org/abs/2410.07971
https://github.com/xg-chu/GAGAvatar
文章来自于微信公众号“带你学AI”,作者“弹贝斯的鱼”



