# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
开源数字人实时对话Demo来了~
支持语音输入和实时对话,数字人形象可自定义的那种。
生成的数字人效果belike:

目前这个数字人实时对话Demo已在阿里巴巴ModelScope魔搭社区上线。
无需预训练即可使用自定义的数字人形象进行实时对话,支持选择不同的数字人形象和音色,对话首包延迟可低至3s。
基于开源技术,该项目采用模块化系统设计,各模块均可快速更换,开发者可以自由扩展和优化,适用于多种应用场景,包括但不限于直播、新闻播报和聊天助手等。
此外,该项目基于Gradio 5实现流式视频输出,方便部署和快速构建交互式数字人应用。
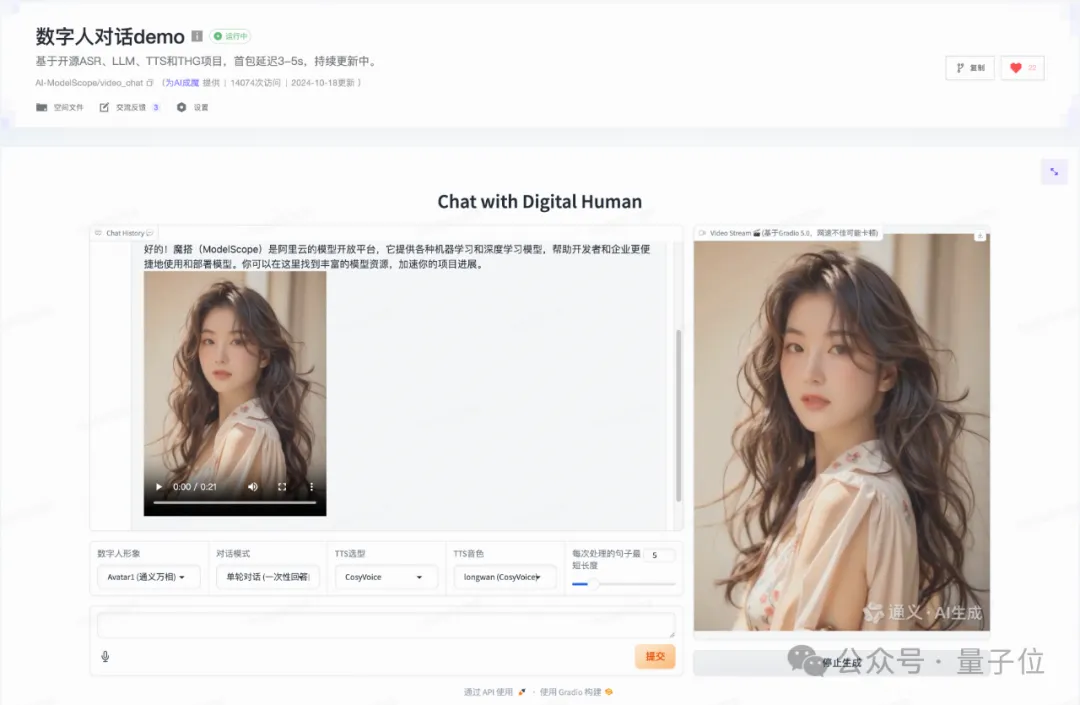
现有的热门开源数字人项目主要有以下几个:
Linly Talker,基于Gradio的数字人对话项目,多模型集成,功能丰富,但不支持实时对话和流式输出。
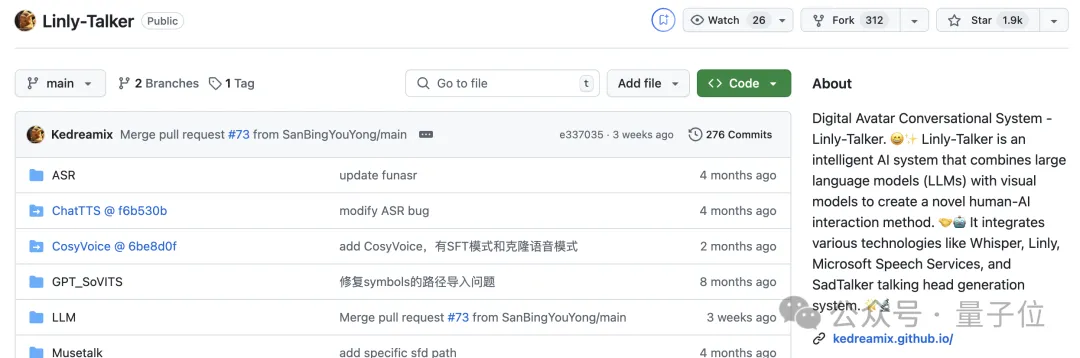
LiveTalking,基于流媒体的数字人生成项目,数字人响应快,但交互界面比较简陋,且需要配置服务器,部署难度较高。
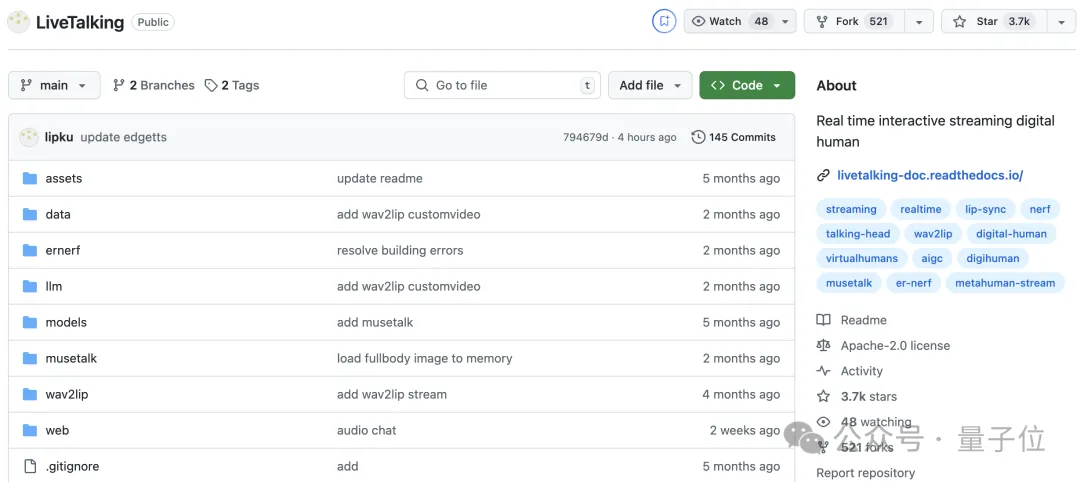
awesome-digital-human-live2d,基于Dify编排的数字人互动项目,轻量化,交互方式丰富,但数字人形象不够真实,且不支持口型同步。
针对现有开源项目存在的问题,本项目实现了一个基于开源的技术方案、支持语音输入和实时对话、数字人形象真实且口型同步、可在线试用的开源数字人实时对话demo。
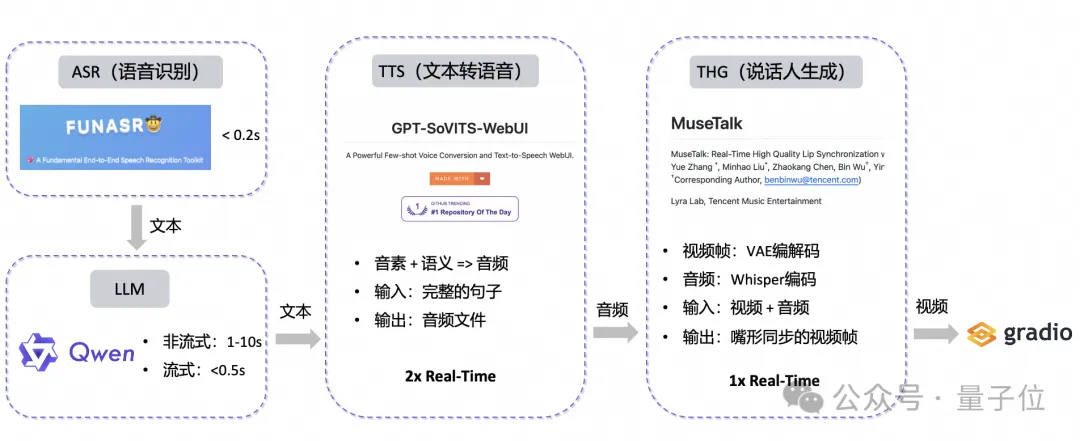
由于目前缺乏效果较好的开源端到端语音/视频对话模型,本项目采用多模块级联的技术方案。
首先,使用语音识别(ASR)模块将用户输入的语音转为文本,然后将该文本输入大语言模型(LLM)模块生成相应的文本回复,文本转语音(TTS)模块会根据这部分文本内容进行语音合成,最后使用该语音驱动说话人生成(THG)模块,得到唇形同步的数字人说话视频,实现用户语音输入、数字人视频输出的对话效果。
此外,为了方便在线试用和本地快速部署,使用流行的Gradio框架来构建交互式应用。

接下来介绍一下各个模块使用的开源技术。
语音识别(Automatic Speech Recognition,ASR)模块负责将用户输入的语音转化为文本。本项目选用了提供工业级语音识别的工具包FunASR。
与PaddleSpeech、kaldi等同类项目相比,FunASR具有更加丰富的功能,包括语音识别、语音端点检测、标点恢复、语言模型、说话人验证、说话人分离和多人对话语音识别等。
不仅方便开发者在现有demo的基础上进行扩展,加入更加丰富的语音功能;还便于部署,能够提供高精度、高效率的语音识别服务。
大语言模型(Large Language Model,LLM)模块负责生成回复内容。
本项目选用了目前备受关注的开源LLM——通义千问,来生成对话结果。
为了提高LLM模块的响应速度且不影响对话效果,使用了轻量级模型来支持日常聊天场景。
如果开发者希望扩展到其他应用场景,可以选用参数规模更大的模型或多模态LLM如Qwen-VL、Qwen-Audio等,以支持更复杂的对话场景。

本项目提供了单轮对话和互动对话两种模式,其中互动对话模式使用OpenAI的meta-prompt生成提示词,每次只回复较短的内容,从而实现一问一答的互动效果。
文本转语音(Text to Speech,TTS)模块负责将生成的回复内容转化为自然的语音。
GPT-SoVITS针对推理速度进行了工程优化,支持并行推理,从而提高了TTS的响应速度。
相比之下,另一个热门项目ChatTTS虽然提供了更加接近真人的语气和精细的韵律特征,但推理速度较慢,且在输入文本较短时韵律优势不明显。

目前来看,GPT-SoVITS更加适合实时对话场景。
此外,机器性能有限的开发者还可以选择使用开源项目edge-tts来进行语音合成,该项目利用微软Edge浏览器的免费在线语音合成服务,能够提供比GPT-SoVITS更快的合成速度。
demo还提供了开源项目CosyVoice的API调用,由阿里云大模型服务平台百炼(Model Studio)支持。
说话人生成(Talking Head Generation,THG)模块根据输入的语音生成一段人物说话视频。
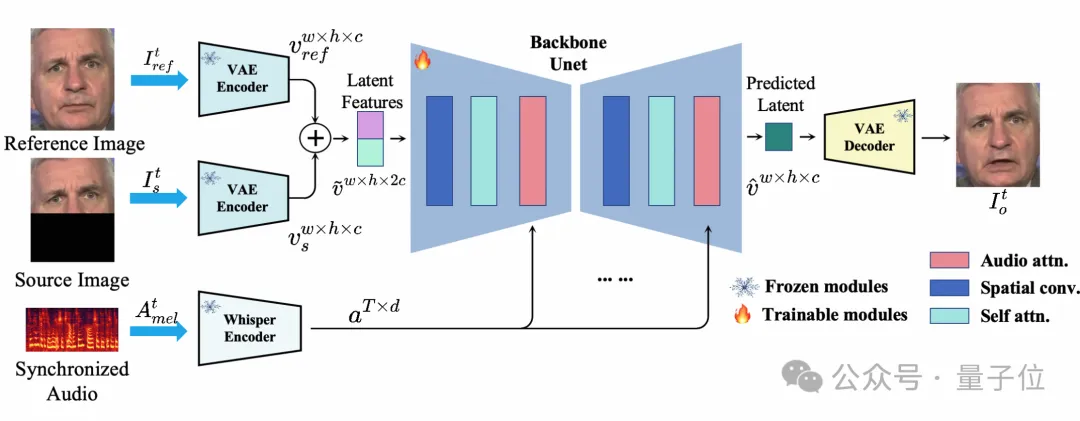
本项目选用了目前实时性最好的THG方案MuseTalk。
MuseTalk只对输入视频中人物嘴唇周围的图像进行处理,将输入的图片和音频编码后使用交叉注意力机制进行融合,然后使用轻量化的Unet完成推理。
在完成预处理的情况下,MuseTalk在V100上可以达到30fps以上的处理速度,能够满足当前场景下数字人实时生成的要求。
与其他开源唇形同步方案(Wav2Lip、TalkLip、VideoRetalking等)相比,MuseTalk在提高生成速度和视频分辨率的同时,保留了较好的唇形同步效果,并且无需额外训练即可完成推理。
相比基于扩散模型的开源方案(EMO、Echomimic、Vasa-1等),虽然唇形同步方案生成的视频结果不够多样化,但考虑到基于扩散模型的方案通常需要数分钟的生成时间以及巨大的训练/推理开销,它们显然不适合实时对话场景。
更进一步地说,由于唇形同步方案是基于给定的人物视频生成结果,可以通过增加输入人物视频的动作和表情的丰富度来优化整体的观感。
如果需要根据输入的人物图片生成视频,可以使用MuseTalk团队的配套开源项目MuseV和MusePose来生成有表情和动作的人物视频,也可以使用图生视频模型来生成满足需求的结果。
如果不受限于特定的人物形象,还可以利用文生视频模型来发挥想象力。
前后端部分选用了适合做在线demo展示和本地快速部署的Gradio,为了实现视频的流式传输,本项目使用了Gradio 5的Video Streaming功能。
由于Gradio 5刚发布且改动较大,创空间暂时不支持,因此创空间上的demo使用了支持Video Streaming的gradio 4.40.0测试版,用户在本地部署时可直接使用最新发布的Gradio 5。
此外,本项目还使用了ModelScope提供的高阶自定义Gradio组件库,其中包括升级版的chatbot组件,支持输出图片、视频等多模态内容。

同时,Lifecycle组件和Gradio的State组件能够管理不同用户的聊天记录。利用这些组件,开发者无需任何前端知识即可实现功能丰富的在线交互式应用。
考虑到LLM、TTS和THG这三个模块均需要一定的处理时间,如果等待前一个模块完全结束后再开始处理,则无法达到实时对话的要求。为了解决这一问题,本项目进行以下处理:
下面展开来讲讲这个流式输出的并行流水线。
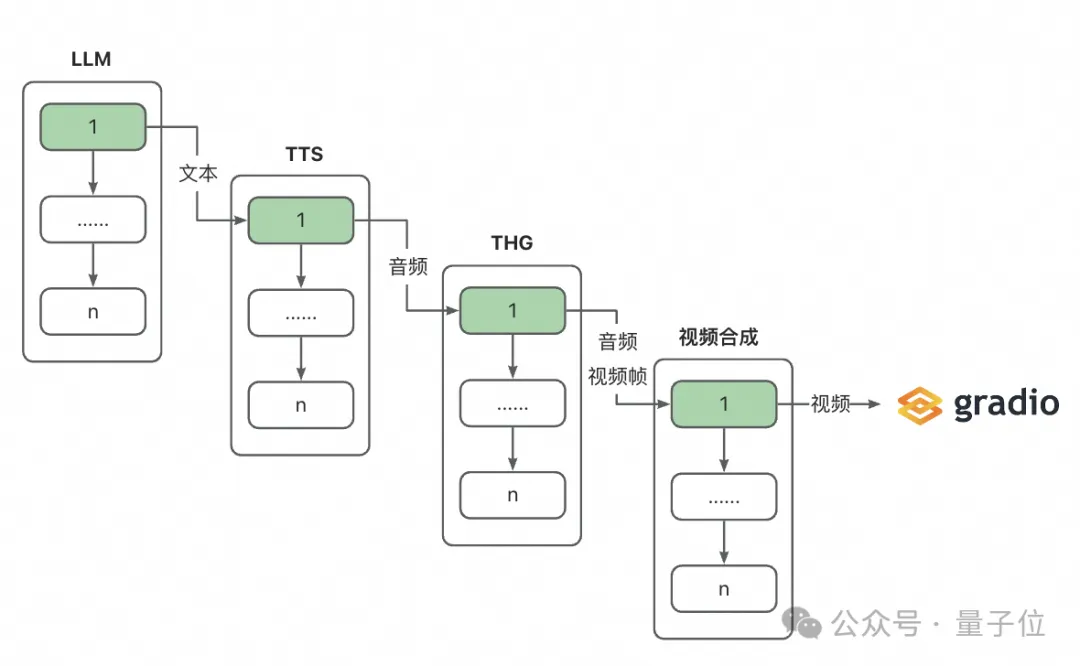
通过使用LLM的流式输出模式,系统在收到一定数量的文本后即可启动后续处理。基于以下考虑,本项目选择以句子为单位进行处理:
在此基础上,本项目维护多个队列,分别保存LLM生成的句子、TTS生成的音频和THG生成的视频帧,并结合多线程进行并行处理。这使得在完成第一个句子的处理后即可开始数字人的响应,边推理边播放,极大地降低了用户的等待时间。
上图中绿色标注部分所需的处理时间即为与数字人对话的首包延迟。
考虑到MuseTalk的推理耗时与输入音频的长度正相关,为了确保边推理边播放的流畅性,研究人员表示需要尽可能保证每次处理的片段长度均匀。
鉴于不同句子长度不一致,本项目设定了一个最小长度,当且仅当LLM缓冲区中的句子长度超过这个值时,将这部分内容作为一个包送入流水线开始处理。这个最小长度需要根据GPU性能动态调整,以平衡首包延迟和整体流畅度。
以语音输入“今天天气怎么样”为例,研究人员在单张A100上测试了各个模块的用时和播放延迟。
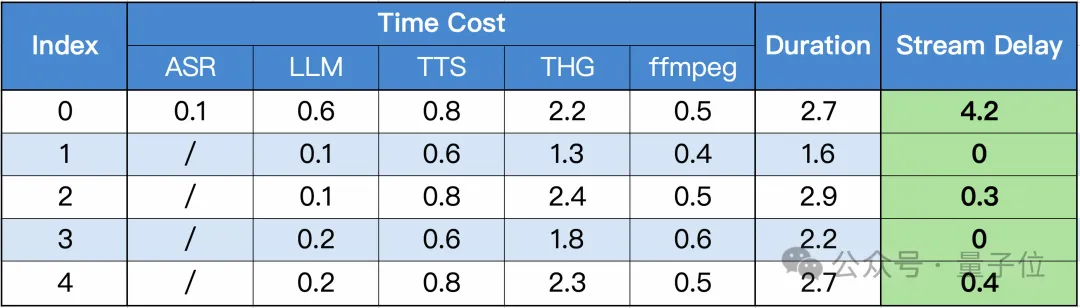
为了确保后续包的流畅性,最小长度被设定为10个字符,即在LLM生成的句子累计超过10个字符后才开始处理。这种设置确保在流式播放时,后续包具有较低的延迟。
对于首包,用户感知的播放延迟是所有模块耗时之和。从上图中可以看出,除了首包之外,后续包的播放延迟均小于0.5秒。
由于句子之间本身存在停顿,这种延迟对用户体验几乎没有影响。
如果想在本地运行本项目,可参考项目的README完成环境配置,支持更换各个模块的技术选型,支持加入自定义的数字人音色和形象视频。
下一步,本项目将会从以下几个方面展开优化:
对本项目感兴趣的小伙伴可以试用在线demo~
项目链接:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
项目README:
https://www.modelscope.cn/studios/AI-ModelScope/video_chat/file/view/master?fileName=README.md&status=1
创空间体验地址:
https://www.modelscope.cn/studios/AI-ModelScope/video_chat
代码仓库:https://github.com/Henry-23/VideoChat
文章来自于“量子位”,作者“池炜恒(池化)”。



【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】Fay开源数字人框架是一个AI数字人项目,该项目可以帮你实现“线上线下的数字人销售员”,
“一个人机交互的数字人助理”或者是一个一个可以自主决策、主动联系管理员的智能体数字人。
项目地址:https://github.com/xszyou/Fay
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
