# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
2024年10月21日,《华尔街日报》的母公司道琼斯公司以及《纽约邮报》联合对人工智能搜索领域的新秀Perplexity提起了诉讼。在一份长达42页的诉讼文件中,道琼斯公司和《纽约邮报》对Perplexity提出了三项侵权指控。
此次起诉,主要针对Perplexity在开发其大型语言模型和生成用户回答的过程中,涉嫌未经授权地使用了原告的版权作品,侵犯了原告的著作权。此外,二者还指控Perplexity在商标使用上存在误导性标识和商标淡化的问题。
10月24日,Perplexity通过官网表示此次诉讼所体现的传统媒体与技术之间的对抗姿态是“短视的、不必要的、适得其反的”,并对诉讼的部分论点予以反驳。
而根据乔治·华盛顿大学DAIL(the Database of AI Litigation)数据库的统计,这将是美国第50个与生成式AI 有关的案件。
Perplexity,一个自称为“世界上第一个对话式搜索引擎”,被视为有潜力颠覆谷歌在搜索领域的统治地位。与谷歌不同,当用户在对话框输入需要查询的内容时,Perplexity将通过整合来自不同来源的信息尝试直接给出答案,而不是仅仅列出与问题相关的网站链接。
技术上,Perplexity利用了多种大型语言模型,包括来自OpenAI和Meta的开源模型Llama,来生成它提供给用户的答案。在它的官方网站上,Perplexity承诺能在这个平台上为用户提供准确且最新的新闻和信息。此外,Perplexity还强调,用户可以在不点击任何链接的情况下,直接获取原始出版商网站上的信息,通过这种方式,将所有用户需要的信息汇总成一个“简洁、全面的答案”。

Perplexity三大特点官网介绍
而正是“跳过链接获取信息”这一点,引发了Perplexity与原告之间的核心争议之一。在诉状中,道琼斯公司和《纽约邮报》抨击道,Perplexity的AI搜索引擎与传统搜索引擎有根本的不同。
传统搜索引擎通过复制内容来索引信息,但目的是为了提供链接到原网站,引导用户访问《华尔街日报》或《纽约邮报》等网站,从而为内容创作者带来流量和收入。这种模式仅促进了内容的发现,而非替代,因此版权持有者通常不会质疑传统搜索引擎的复制行为。
然而,Perplexity这一类“跳过链接获取信息”的商业模式与此不同,它并没有为内容创作者带来利益,反而可能抢占了他们的盈利机会。
道琼斯公司和《纽约邮报》认为,Perplexity在开发其大型语言模型和生成用户回答时,侵犯了他们的著作权。原告在阐述侵权行为时,主要强调了两个关键点。
首先,原告指出,在开发大型语言模型的过程中,Perplexity通过复制他们的版权作品,作为创建其检索技术(RAG索引)的“输入”数据,这侵犯了他们的著作权。换言之,Perplexity在构建其搜索引擎的数据库时,未经授权使用了原告的版权内容。
其次,原告进一步指控,在生成用户查询的“输出”结果时,Perplexity同样复制了他们的版权作品,再次侵犯了著作权。
例如,Perplexity在回应用户的查询时,通常会提供原告的新闻报道、分析文章和观点文章的全文或部分内容,这些内容往往是逐字复制的。此外,Perplexity还采取了将原告的受保护文章转换成转述或摘要的形式,作为在原告网站或授权网站上阅读原作的替代。
而这也是目前的一个显著的趋势,越来越多的著作权持有者正在对生成式AI工具提起著作权侵权诉讼。在美国,这类侵权已经成为针对生成式AI工具诉讼中最为普遍的争议点。此起案件已经是美国第50起与生成式AI相关的诉讼案件,而在先前的案件中,大约有60%都涉及到版权侵权的问题。
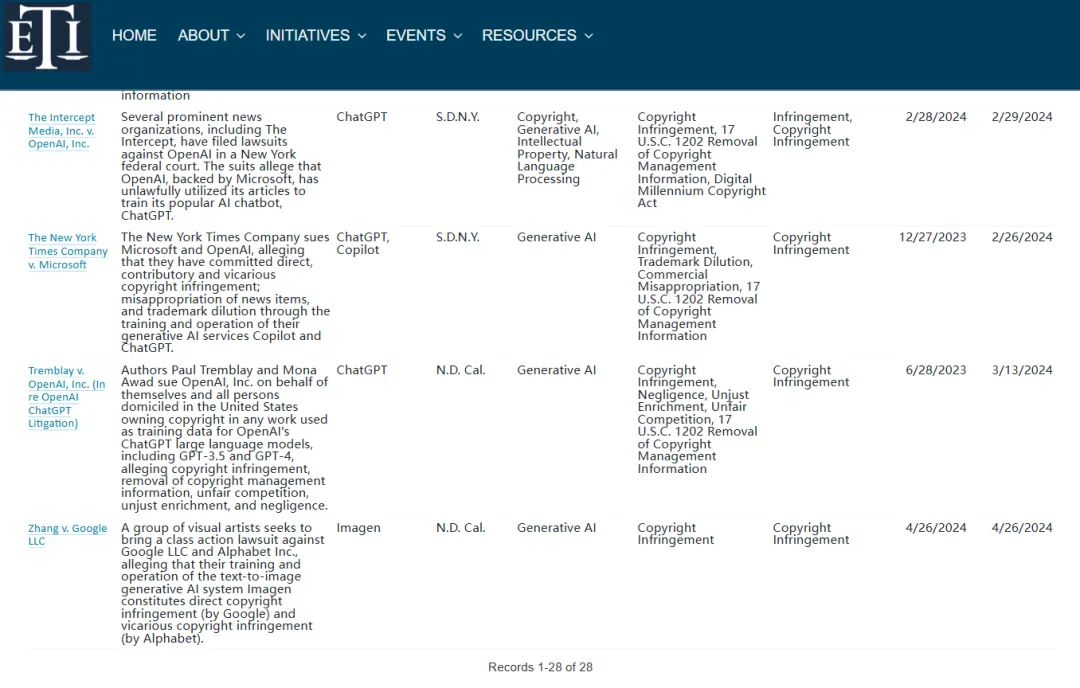
部分与生成式AI工具相关的著作权侵权案件
来源:DAIL
最后,原告依据美国联邦法律15 U.S.C.§1125,指控Perplexity侵犯了其商标权。原告指出,Perplexity未经授权使用其商标,通过提供原告的新闻、分析和观点文章的全文或部分内容,误导消费者认为Perplexity的服务与原告有关联。原告认为该行为不仅构成了虚假来源标识,还导致了原告商标的淡化,损害了原告的品牌价值和市场识别度。
“短视的、不必要的”的诉讼
在受到起诉后的第三天,Perplexity在其官方网站上发表了一份声明,对道琼斯公司和《纽约邮报》提起的诉讼表示惊讶和失望,并认为此类诉讼是“短视的、不必要的、适得其反的”。

Perplexity关于道琼斯诉讼的观点
Perplexity指出,目前大约有30余家媒体公司针对生成式AI工具提起了诉讼。这些诉讼共同传达了一个Perplexity并不认同的信息:这些媒体公司希望这项技术不存在。他们更愿意维持现状,生活在一个由媒体公司控制公开报道的事实的世界里,不允许任何人在不支付费用的情况下使用这些公开报道的事实。
与其他许多AI公司一样,Perplexity坚信媒体和科技行业应该携手合作,为人们提供令人惊叹的新工具,共同创造一个能够真正扩大行业价值的商业模式。然而,Perplexity也对这些商业模式与现有法律之间的关系表示了担忧,其承认,一些非常有创意的想法和项目可能超出了现有法律的默认应用范围。因此,Perplexity希望未来能够与那些选择起诉的公司建立互利的商业关系。
在过去一年中,大型AI公司似乎对此类案件持以相同观点,呼吁加强传统媒体与AI公司之间合作,减少不必要的争议。早在2023年《纽约时报》起诉微软和OpenAI时,OpenAI就曾公开表示对此类诉讼感到惊讶和失望,并认为AI公司应当与内容创作者和所有者合作,确保他们从人工智能技术和新的收入模式中受益。[1]
而对这起诉讼,Perplexity给予了较少的回复。该公司表示,诉状中指控的事实充其量只是误导。所引用的“重复”(regurgitated)输出示例明显歪曲了材料来源。Perplexity生成的答复并不是简单地重复可以在其他地方更直接、更有效地获得的文章内容。
最后,该公司还隐晦地提到一个另其担忧的趋势:它观察到类似诉讼中原告方经常提出一些夸张的指控,声称被告的AI工具能够导致各种不当行为。但是这些指控很可能是基于故意引导AI给出误导性回答的情况,并不代表AI工具在正常使用下的行为。
如果我们观察已经发生的50起有关生成式AI的案件,会发现Perplexity提到的故意引导AI给出误导性回答并将其作为证据的情况其实并不少见。而在审判过程中,大量此类案件通过驳回动议被简化为只包括与输入端训练直接侵权相关的索赔,而原告在争取与AI生成的输出内容相关的一般性索赔方面,面临着一定的困境。
在2024年春季,加利福尼亚北区地区法院迎来了一批新的集体诉讼案件,这些案件由视觉艺术家和作者团体提起,指控AI公司侵犯了他们的版权。案件包括Zhang v. Google、Dubus v. NVIDIA以及Makkai v. Databricks等,它们都聚焦于一个核心问题:AI公司在未经许可的情况下,使用了原告的作品来训练他们的生成式AI模型。
与过去相比,这些新案件中的原告在起诉书中只提出了直接侵权的指控,这与之前案件中原告提出的广泛索赔形成了鲜明对比。这可能是因为原告及其代表的律师事务所注意到,在其他案件中,一些广泛的索赔被驳回的趋势,因此他们调整了策略,转而专注于那些更有可能获得成功的索赔。
在这50起案件中体现的另外一个趋势是,大量针对同一家AI公司的类似版权侵权诉讼被合并处理。2月份,Chabon等人起诉OpenAI的案件与Tremblay起诉OpenAI的案件合并,而Tremblay的案件在2023年底已经与Silverman起诉OpenAI的案件合并。
截至目前,OpenAI正面临总共23起诉讼,这些案件涵盖了多种法律问题,包括版权侵权、不当得利、不正当竞争以及侵犯隐私权等。
结语
在过去的两年中,生成式AI工具技术和发展爆发式生长,并且将在未来一段时间中保持高速增长。仅在中国,根据《中国AI数字商业展望2021-2025》报告,到2025年中国生成式AI技术应用规模预计上升至2070亿元,2020-2025年间的年均复合增长率高达84.1%。
与此同时,与生成式AI工具相关的案件逐渐增多。近一年以来,我们分别见证了国内首例“AI文生图”著作权侵权纠纷的判决、全国首例生成式AI服务侵犯著作权生效判决以及首例AI生成声音人格权侵权案等。
但国内在人工智能生成内容领域的发展目前还处于早期阶段,许多潜在的问题尚未充分显现。与此相对,美国由于拥有更多成熟的生成式AI工具产品,其产业生态内的互动和竞争已经更加明显。因此,深入了解美国在这一领域的司法实践,亦有一定的参考价值。
文章来自微信公众号 “ 智合研究院 “,作者 刘子言 智合研究院中级研究员,中国/英国法学学士、美国法学硕士,关注法律服务评价体系,关注法律科技与数据合规



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
