# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
Open-Sora-Plan迎来又一次升级。新的Open-Sora-Plan v1.3.0版本引入了五个新特性:性能更强、成本更低的WFVAE;Prompt refiner;高质量数据清洗策略;全新稀疏注意力的DiT,以及动态分辨率、动态时长的支持。
本次升级主要是由于巨大的计算开销和不明确的训练策略限制了3D全注意力架构Open-Sora-Plan v1.2.0的发展。Open-Sora-Plan v1.3.0版本已经开源,并发布到始智AI wisemodel开源社区,欢迎大家前往使用。
模型及github地址:
https://wisemodel.cn/models/PKU-YUAN/Open-Sora-Plan-v1.3.0
https://github.com/PKU-YuanGroup/Open-Sora-Plan
下面内容将主要概述Open-Sora-Plan v1.3.0的更新和改进,包括技术细节、未来工作和Skiparse方法扩展。期待与大家共同推动视频生成技术的发展。
Structure
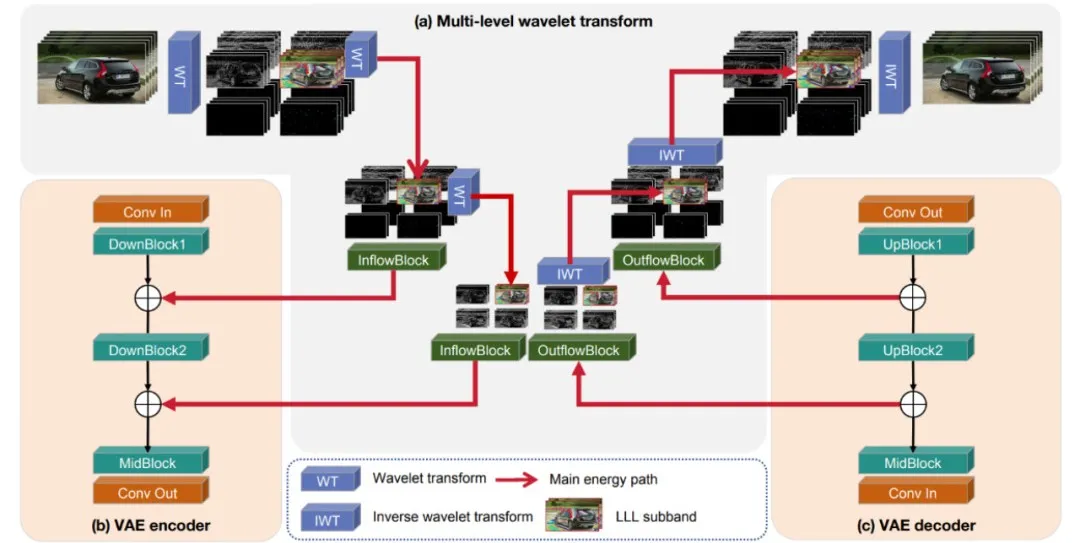
模型结构:为了应对视频生成模型向高分辨率和长时长发展带来的开销问题,Open-Sora Plan通过小波变换分解视频,捕捉不同频域信息,提高VAE性能。后来发现视频中主要能量往往集中在低频,并且为LLL子带的能量建立了损耗更低的传输路径,从而精简模型设计,降低推理时间和显存。
消融研究:使用K400数据集,在8xH100上进行实验,发现模型参数增加可提升重建指标,GroupNorm在训练中不稳定。还发现GroupNorm相较于LayerNorm在PSNR指标表现差,而在LPIPS指标会表现更好。
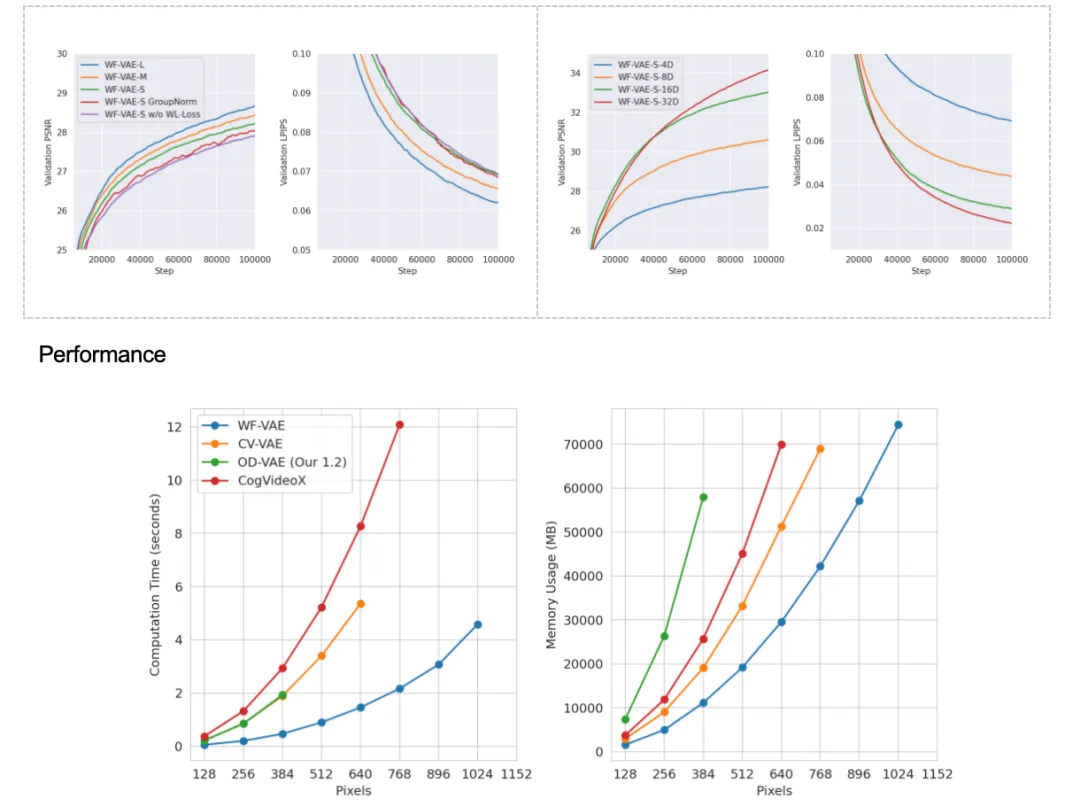
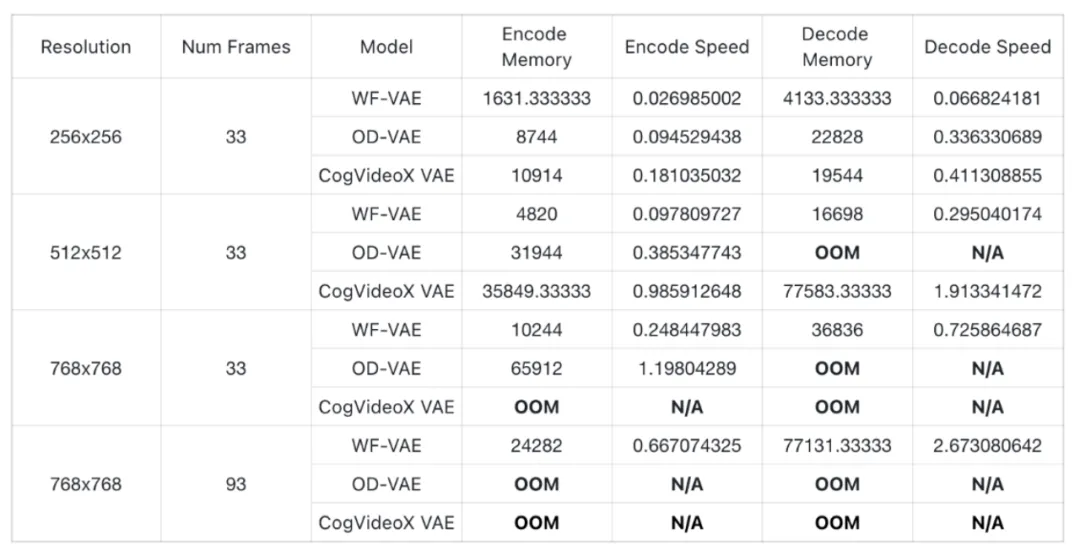
性能:WF-VAE在33xPxP视频无tiling的推理性能测试中优于其他开源VAE。
因果缓存:为解决tiling的有损问题,提出了Causal cache方法,实现时间上的无损分块推理。首先将GroupNorm替换为LayerNorm,并利用CausalConv3D的特性来实现时间维度的分块无损推理。在每一层 CausalConv3D 中,缓存后几帧的信息,以便在处理下一个时间块时,能够衔接之前的卷积滑块操作,从而实现无损。
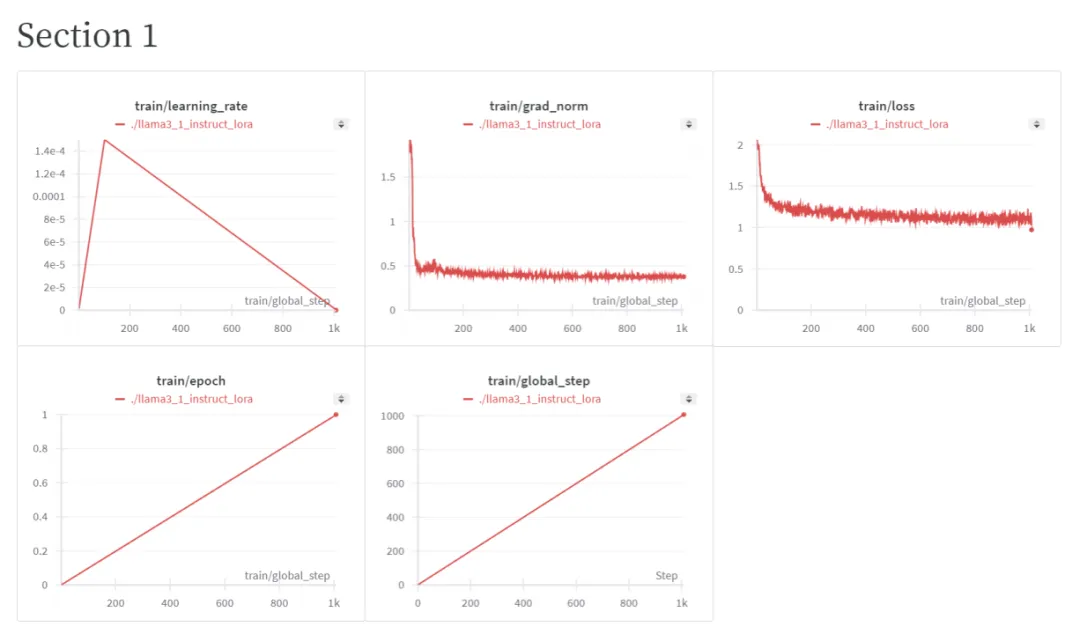
用户输入的caption通常较短,而训练数据的文本标注较稠密。随后收集并重写了不同来源的caption,使用LLaMa 3.1进行LoRA微调,对caption进行分类,并用ChatGPT进行重写,以提高视觉质量和文本对齐度,输入给ChatGPT的指令如下:
SQL
"rewrite the sentence to contain subject description action, scene description. (Optional: camera language, light and shadow, atmosphere) and conceive some additional actions to make the sentence more dynamic, make sure it is a fluent sentence, not nonsense."
最后,使用LLaMa 3.1进行LoRA微调,只用了1 H100在半小时内完成训练。仅微调1 epoch,batch size为32,lora rank为64。
Open-Sora Plan设计了一个视频筛选pipeline,通过多种方法筛选出高质量的视频内容,大约留下27%视频。对原始的Panda70m进行随机抽取,发现其中有许多视频是静止的、多字幕的、运动模糊的,采用lpips跳帧计算帧间语义相似度,将异常点作为跳切点,将均值作为motion score。还对视频进行OCR检测字幕,并使用Laion aesthetic predictor来预测视频的美学质量。

沿用了1.2的架构,引入了稀疏注意力模块,并采用了动态训练策略。定义了每个视频在训练时的shape,并通过sampler聚合相同shape的数据。还采用了--max_token和--min_token来限定任意区间,以匹配Transformer架构。
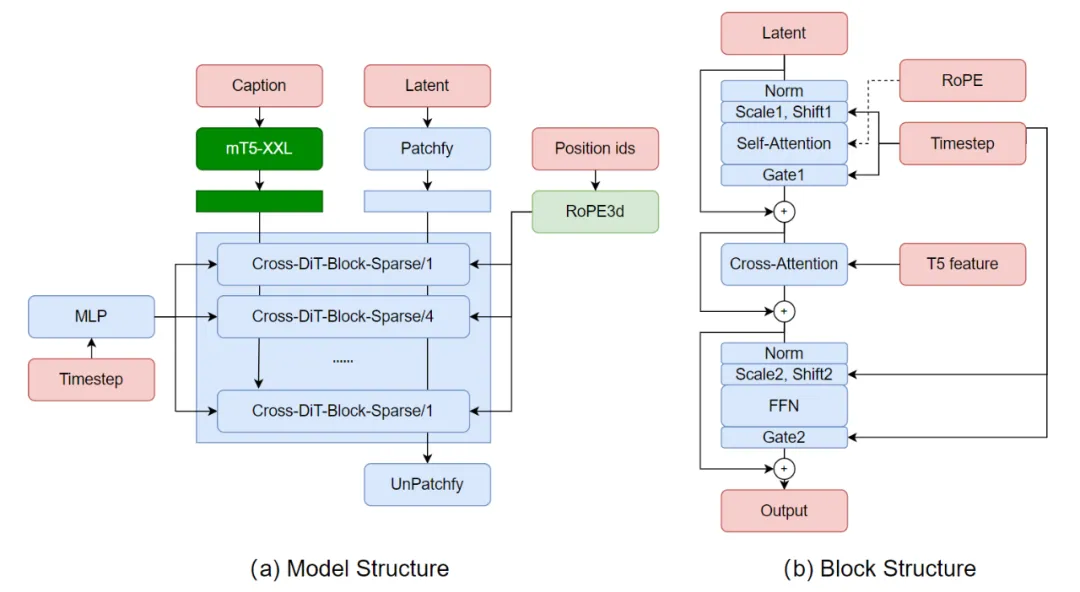
第一阶段:首先从1.2.0的图片权重初始化,并且在1x320x320上训练图片,该阶段的目的是为了将3D dense attention model微调到sparse attention model。并且将eps-pred loss改成v-pred loss。整个微调过程大约训练100k step,batch size 1024,学习率2e-5。图片数据几乎全是1.2.0中的SAM。
第二阶段:联合图片和视频一起训练,最大分辨率为93x320x320。整个微调过程大约训练300k step,batch size 1024,学习率2e-5。图片数据几乎全是1.2.0的SAM,视频数据为未筛过的Panda70m。事实大约在100k step模型几乎已经收敛,并且到300k step时没有特别明显的增益。于是对数据进行清洗、重写打caption等操作。
第三阶段:用筛选过的Panda70m微调,固定分辨率为93x352x640,整个微调过程大约训练30k step,batch size 1024,学习率1e-5。
为了在保证足够性能的同时加速训练,提出Skiparse(Skip-Sparse)Attention方法,以加速训练并保持性能。具体来说,在固定稀疏率情况下,通过两种交替的跳跃-聚集方法组织候选标记以供注意。这种方法保持了注意操作的全局性,同时有效地减少了 FLOPS,从而能够更快地训练 3D Attention 模型。
在实验中,应用了稀疏比率的 Skiparse_k=4对于 2.7B 模型,在 93x720p 下将训练时间减少到每步 42 秒,在 93x480p 下将训练时间减少到每步 8 秒。
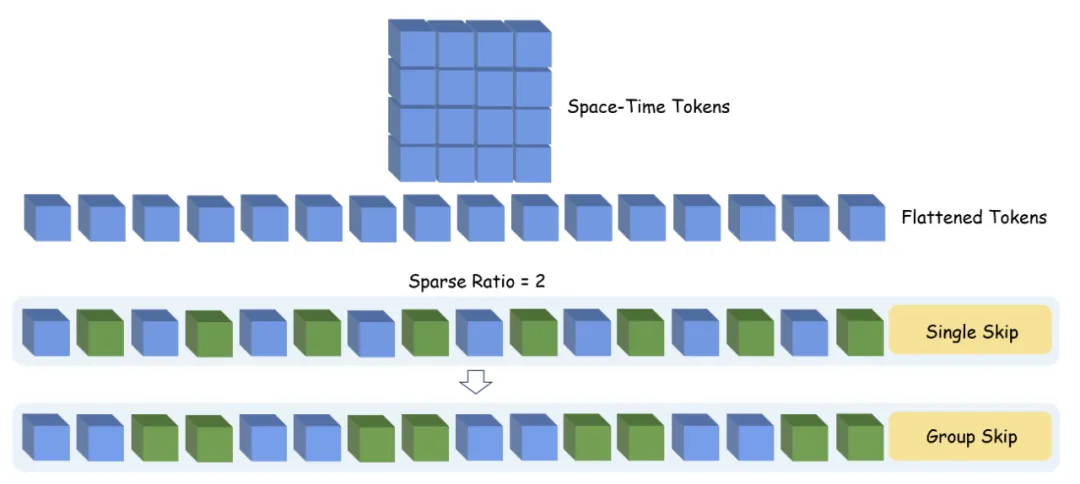
Skiparse DiT 仅修改 Transformer Block 内的 Attention 组件,使用两个交替的 Skip Sparse Transformer Block。
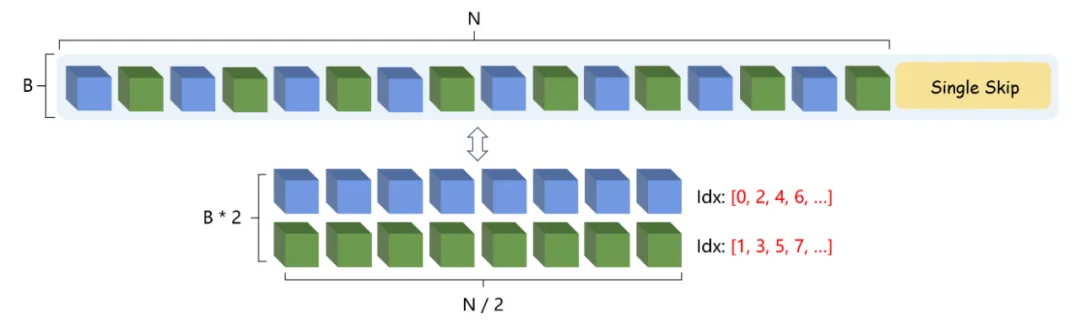
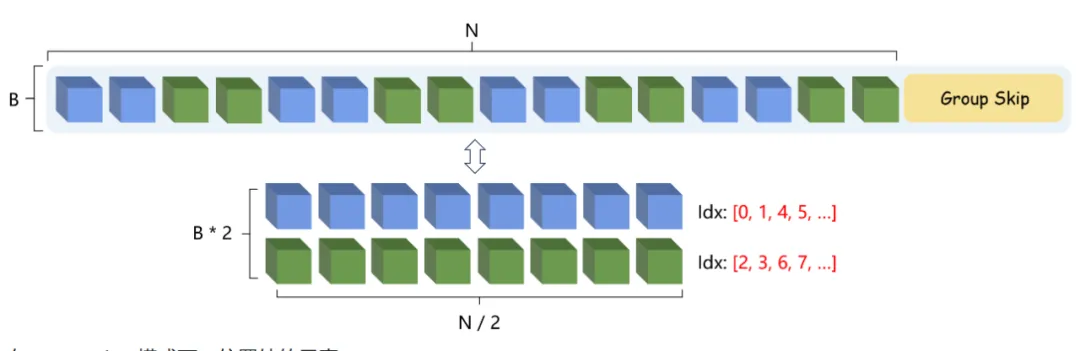
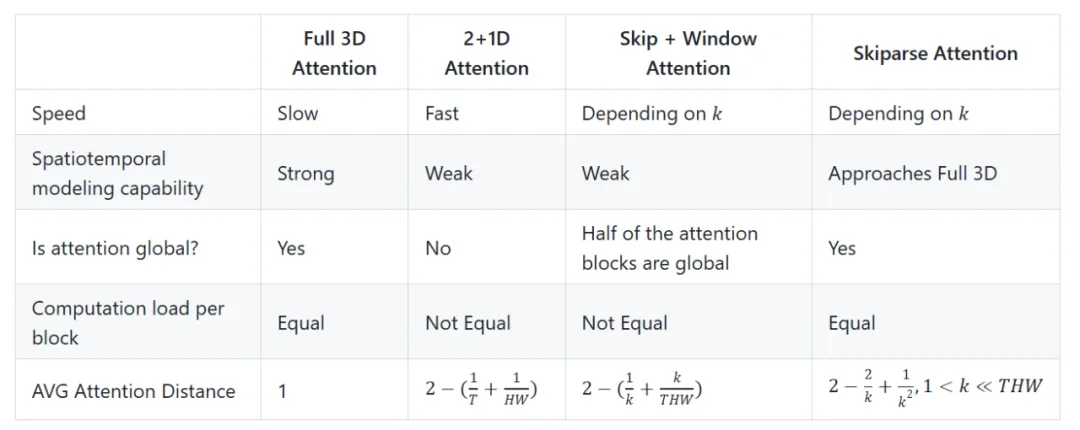
Skiparse Attention方法在每个块内提供全局时空注意力,每个块具有相同的“感受野”。使用“组”操作还引入了一定程度的局部性,与视觉任务非常吻合。
在 Skiparse Attention 中,Single Skip 是一种简单易懂的操作。在 Group Skip 中,Group 操作也很直观,是一种对局部信息进行建模的方法。然而,Group Skip 不仅涉及分组,还涉及跳过(尤其是在组之间),这一点经常被忽视。这种疏忽经常导致研究人员将 Skiparse Attention 与 Skip + Window Attention 方法混淆。
关键区别在于偶数块:Window Attention 只会对 token 进行分组,而不会在组之间跳过。下图说明了这些注意力方法之间的区别,该图仅显示了自注意力的注意力范围,其中深色 token 代表每次注意力计算中涉及的 token。
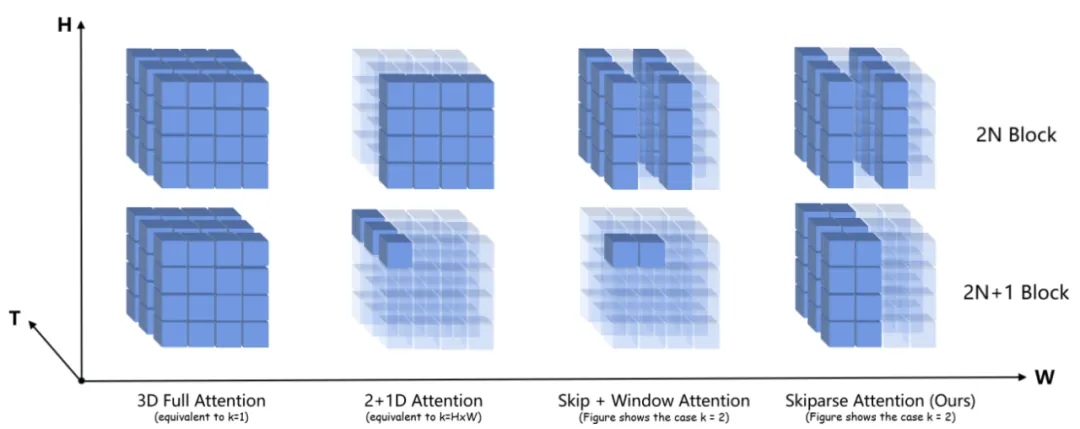
对于常用的 93x512x512 分辨率,使用压缩率为 4x8x8 的因果 VAE 和具有 1x2x2 块嵌入的 DiT,我们在应用注意力之前获得 24x32x32 的潜在形状。不同计算方法的平均注意力距离如下:
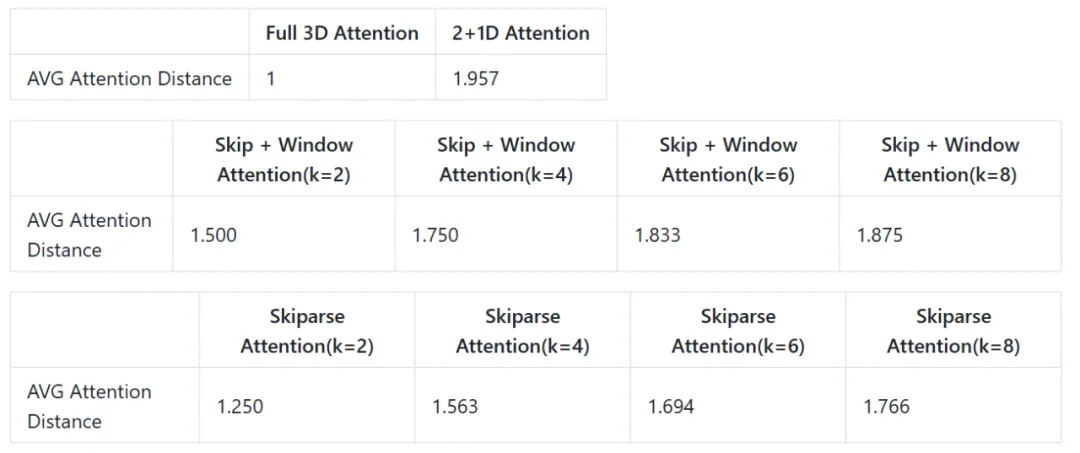
2+1D Attention 的平均注意距离为 1.957,在常用的稀疏率下大于 Skip + Window Attention 和 Skiparse Attention。Skip + Window Attention 虽然实现了更短的平均注意距离,但由于其 2N+1 个 block 中的注意力局部性,其建模能力仍然有限。
Skiparse Attention 具有最短的平均注意距离,并且在 2N 和 2N+1 个 block 中都应用了全局注意力,使其时空建模能力比其他两种非全 3D 方法更接近全 3D Attention。
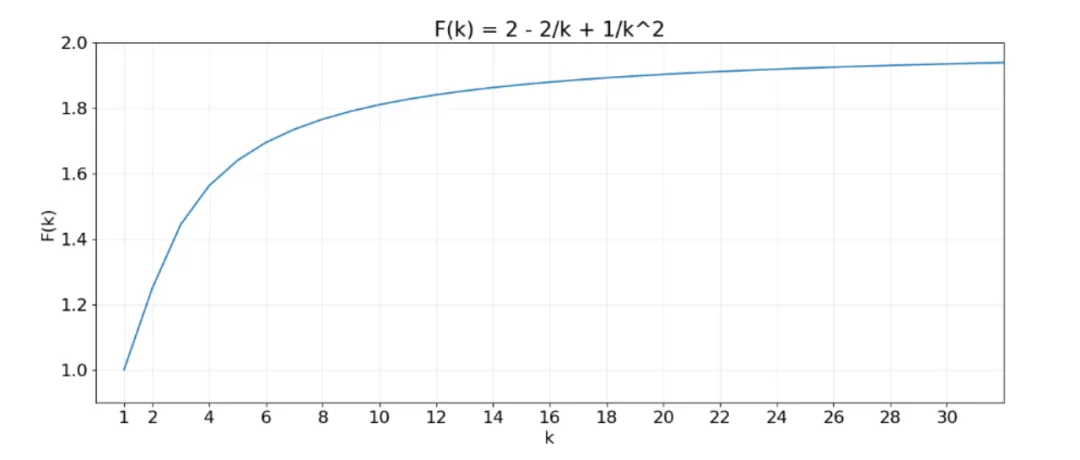
上图展示了 Skiparse Attention 的 AVG Attention Distance 随稀疏比例的变化情况k。
总结这些注意力类型的特点如下:
1、CausalVideoVAE
计划在下一个版本中发布更震撼的VAE,将增加latent dimension以达到更高的压缩倍率是一个趋势。
2、Diffusion Model
对当前模型在物理规律表现不佳的原因进行了推测,包括数据域太窄、图片视频联合训练、模型规模和训练的监督Loss。计划在未来版本进行改进,包括收集更多的数据、探索不同的训练策略、扩大模型规模,并进行更多的消融实验。
使用的稀疏方法在理论上和实践上都很简单,然而,它的实现将原始视频数据纯粹视为一维序列,忽略了 2D 空间先验。因此,扩展了Skiparse以创建Skiparse-2D。
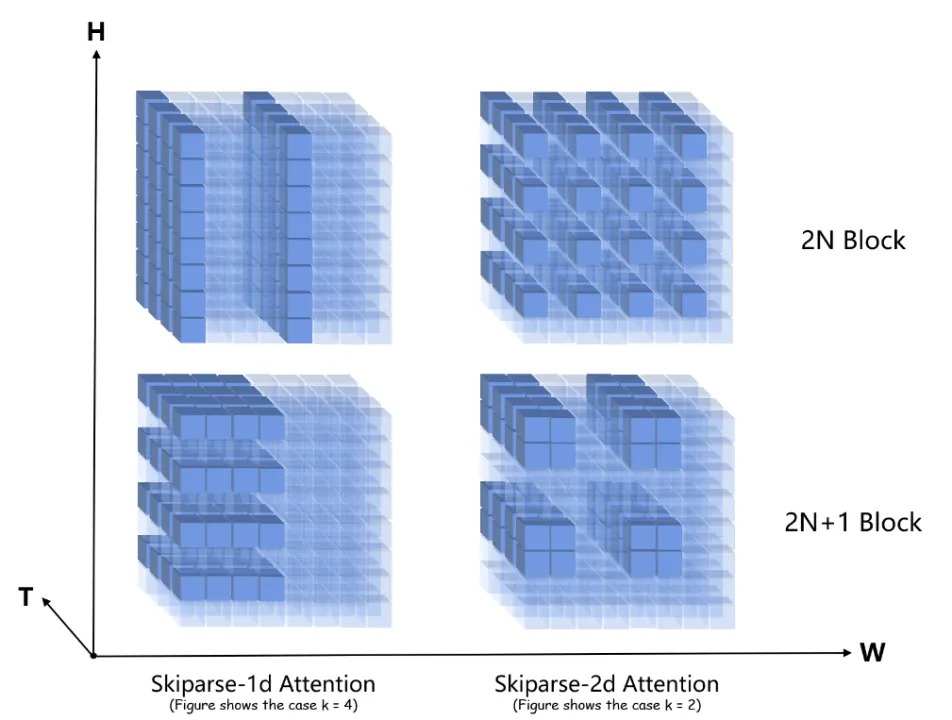
在 Skiparse-2D 中,稀疏比率为k表示沿时长或者宽方向。从参与注意力计算的token数量来看,它相当于Skiparse-1D中稀疏比率的平方。
Open-Sora Plan进行了 Skiparse-1D 和 Skiparse-2D 的基本实验。在相同的实验设置下,Skiparse-2D 在损失或采样结果方面均未显示出比 Skiparse-1D 更好的性能。
此外,Skiparse-2D 的实现灵活性不如 Skiparse-1D。因此,选择在 Open-Sora Plan v1.3 中使用 Skiparse-1D 方法进行训练。
尽管如此,鉴于实验有限,Skiparse-2D 的可行性仍然值得探索。直观上看,Skiparse-2D 更符合视觉的空间特征,并且由于稀疏比率随着维度的增加,其方法直观地近似于 2+1D。因此,鼓励社区中感兴趣的研究人员在这一领域进行进一步探索。
文章来自于“始智AI wisemodel”,作者“始智AI wisemodel”。



【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
