# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
图片来源:The Algorithmic Bridge
SB-1047法案,如果一切顺利并且Gavin Newsom州长签署,将于9月30日生效,可能决定硅谷的未来。有些人认为这是向好的方向发展,而另一些人则认为这是自OpenAI发布ChatGPT以来,加州在过去两年中在人工智能领域做出的最糟糕的决定。
民主党参议员Scott Wiener于2024年2月提出了这项法案,旨在监管加州的前沿人工智能领域,灵感来自于拜登关于人工智能的行政命令。Wiener将这项法案描述为“确保大规模人工智能系统安全发展的立法,通过为大型和强大的人工智能系统的开发者建立明确、可预测和合理的安全标准”。
我已详尽审阅了该法案的最新修订版。此文档通俗易懂,即便是对法律领域略知一二,或对加州特定的技术规章不甚熟悉的读者,也能轻松领会。我强烈推荐各位细读这份法案,不必非得是法律或人工智能领域的专家。倘若该法案得以顺利推行,它有望成为全球其他地区制定法规的典范。值得注意的是,你们当中有相当一部分人(约四分之一)来自加利福尼亚,即便你并非加州居民,也能从此法案中获益良多。
总之,这里有一个简明的总结,包含我认为的关键细节(如果我有错误,请告诉我):
○训练成本超过1亿美元的模型。
○训练所需计算能力超过10^26 FLOP的模型。
○微调成本超过1000万美元或超过3×10^25 FLOP的模型,只要预训练模型已经是受影响的模型。
○这些模型的衍生物(例如,副本和改进模型)。
○重点在于“采取合理的预防措施”,以确保不会出现问题。
○开发者必须进行年度审核,考虑到变化。
○从2026年起,他们必须保留第三方审计员。
○开发者必须提交年度合规声明。
如果这项法案通过,硅谷-作为人工智能和生成式人工智能的发源地,将经历深刻的变革。这过去两年的快速进展和大胆的创业精神将成为历史的记忆。一些行业参与者可能会考虑迁移,但Wiener确保这并不是一个明智的选择:该法案影响加州的公司,但也影响任何在加州开展业务的公司。
不过,也有一个积极的一面。定义一个人工智能模型是否“受影响”的门槛相对较高。1亿美元和10^26 FLOP的数字超出了大多数参与者的追求,尤其是开源的独立开发者和小型实验室。这就是为什么有人认为这项法律不会对初创公司或创新造成伤害——它只会影响最大的、最富有的公司,如谷歌和Meta。
然而,两年前的GPT-4训练成本已经超过1亿美元,而如果考虑到技术进步的速度,10^26 FLOP可能并不是那么昂贵。鉴于此,一些行业和学术界的知名人士表示,该法案确实会抑制创新。
反对该法案的有领先实验室——谷歌、Meta和OpenAI。尽管Anthropic最初也反对该法案,这让许多人感到惊讶,因为该公司历史上一直支持以安全为中心的人工智能监管,但在向Wiener发送了修订建议的信件后,Anthropic决定更新后的法案的“好处可能超过其成本”。
这些大型实验室对该法案的财政利益最为明显。它们是人工智能竞赛的绝对赢家,也是最有可能在潜在泡沫破裂事件中幸存下来的公司。任何限制前沿技术进步的法律对它们来说都是不利的。它们曾支持——甚至呼吁——全国范围的人工智能监管,但突然间,一项州法比什么都没有更糟?它们的立场似乎证实了那些指责它们采取“踢梯子”策略的观点。
它们是想要监管,还是想要抑制创新以确保竞争不受威胁?它们是真心呼吁联邦立法者采取行动,还是仅仅出于公关的虚假信号?难以确定,但我很容易就可以忽视它们的论点;它们在一个无法追责的空间中获益匪浅。
Bloomberg分享了OpenAI对Wiener的回应,重点在于任何高风险的人工智能监管应由联邦层面进行,而不是作为“一系列州法律的拼凑”:
“一个由联邦推动的人工智能政策框架,而不是州法律的拼凑,将促进创新,并使美国在全球标准的制定中处于领先地位。因此,我们与其他人工智能实验室、开发者、专家和加州国会代表团的成员一起,尊重地反对SB 1047,并欢迎有机会阐述我们的一些关键关切。”
Wiener回应称:国会不会采取行动。喜欢联邦法律当然没问题,但如果选择是无所作为,那又该怎么办?他在回应行业对法案的反对时总结道:“SB 1047是一项非常合理的法案,要求大型人工智能实验室做它们已经承诺要做的事情,即测试其大型模型的灾难性安全风险。”
现在轮到大型实验室出手了。
但这不仅仅是行业的问题。
我对行业主张的态度是听取然后忽视——直到其他没有隐性利益的人以良好的信心表达相同的担忧。然后,我才会认为值得倾听他们的看法。
这正是所发生的事情。
主要与学术界相关的个人声音(甚至Wiener的党内同事)反对该法案。他们认为这是“出于良好初衷但缺乏了解”。原因是人工智能是一种双用途技术,可以用于好,也可以用于坏——就像其他任何发明一样。
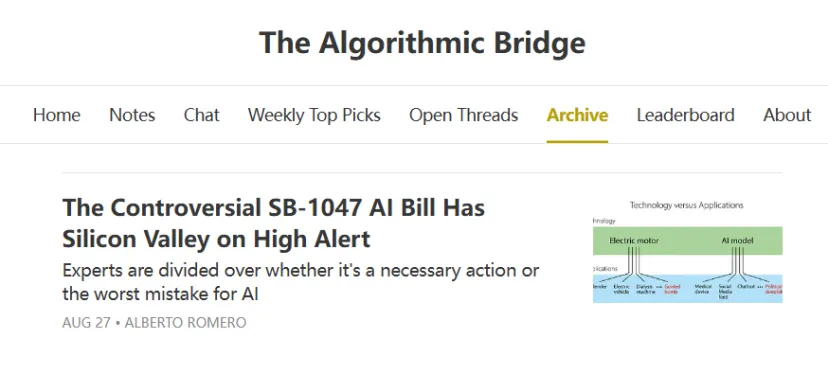
对这种广泛监管的主要论点是,政府不应在技术层面上对人工智能或其他技术进行如此严格的监管。相反,政府应监管技术的应用。开发者应免于因恶意行为者的下游滥用而承担额外负担,以及遵守额外的监控和广泛报告的负担。
斯坦福大学教授、ImageNet的创造者李飞飞表示:“如果通过该法案,将会损害我们新兴的人工智能生态系统,特别是那些已经处于劣势的领域:公共部门、学术界和‘小科技’。SB 1047将不必要地惩罚开发者,扼杀我们的开源社区,并限制学术人工智能研究,同时未能解决它所试图解决的非常现实的问题。”
斯坦福大学教授、谷歌大脑的联合创始人Andrew Ng表示:“该法案有许多问题,但我想专注于一个:它定义了一个不合理的‘危险能力’称号,如果有人利用其模型做出超出该法案定义的伤害(例如造成5亿美元的损害),这可能会使大型人工智能模型的构建者承担责任。这几乎不可能对任何人工智能构建者确保。”
图片来源:Andrew Ng
Yann LeCun、Jeremy Howard等许多人也表达了类似的观点。
“但是,侵权法呢?”Ketan Ramakrishnan说。
关于制造商/分销商在何种情况下对危险工具的不合理使用负有责任,确实有合理的辩论。但是“只有用户有责任”并不是法律,也不应该是。
“只有人工智能的用户有责任”对我来说也从来没有意义。
如果你开发了一种(你知道可能会造成危害的)技术,而没有采取任何措施来确保其安全,并且有人错误使用了它,那么只期望用户是唯一的责任方是毫无道理的。前沿人工智能模型应该需要一份操作手册,而现在,构建它们的公司将被迫制作这样一份安全和保安协议。SB-1047可能会通过增加没人想做的繁琐工作来抑制创新,但也许以任何代价推动创新本来就不是一件好事。
我认为,对于大型实验室、小型实验室、私营公司、开源社区和学术界,存在一个合理的中间立场。既不应是零监管,也不应是“你将承担你所创造之物的全部责任”。这项法案是否恰到好处,应该由法律学者和公正的人工智能专家来评估。我将听从他们在这些问题上的判断。
在支持该法案的学者中,我们看到Geoffrey Hinton、Yoshua Bengio,他们与Yann LeCun一起,被誉为“人工智能之父”,是当今人工智能领域的一些大人物。他们都对自己帮助发明的技术的未来表示担忧,并明确支持监管。
Yann LeCun表示:“SB 1047采取了一种非常明智的方法来平衡人工智能的巨大潜力和风险。我依然热衷于人工智能通过改善科学和医学来拯救生命的潜力,但我们必须有真正有效的立法来应对这些风险。加州是一个自然的起点,因为这项技术正是在这里蓬勃发展。”
Yoshua Bengio则表示:“我们不能让企业自我评分,简单地提出听起来不错的保证。我们在制药、航空航天和食品安全等其他技术领域不接受这种做法。为什么人工智能要被视为例外?在公司之间建立公平竞争的环境,从自愿承诺转向法律承诺是非常重要的。我希望这项法案能在公众对人工智能发展的信心不足时,增强大家对AI开发的信任。”
我的结论是,这些辩论复杂且常常难以明确立场。然而,它们对于一个基本未受监管并且有潜力深刻影响我们世界的行业至关重要。最终,我认为整个讨论背后有两个问题。我认为人们对SB-1047法案(及未来法律)的看法与他们对这两个问题的回答非常一致:
我个人认为OpenAI(尤其是Sam Altman)希望成为一个由国家政府控制的项目的一部分,将人工智能转变为一种地缘政治优势,就像曼哈顿计划对抗纳粹和后来的苏联一样。因此,Altman对人工智能和该法案的看法介于大型科技公司的商业导向和对人工智能超级智能可能意外杀死我们所有人的担忧之间,这更接近Anthropic的立场。这适用于任何股东,比如a16z,而不仅仅是模型构建者。
原文:The Controversial SB-1047 AI Bill Has Silicon Valley on High Alert
https://www.thealgorithmicbridge.com/p/the-controversial-sb-1047-ai-bill
编译:Huiru Jiao
文章来自于微信公众号“Z Potentials”,作者“Alberto Romero”




【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
