# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
随着语音技术的快速发展,现有的语音分离和增强方法在静态环境下已经取得了显著的进展。然而,在动态环境中,这些方法的性能仍然存在很大的不确定性。
目前,用于研究动态声源的数据集极为稀少,主要原因是录制成本高昂,难以大规模应用,极大地阻碍了动态环境下语音分离与增强技术的发展和应用。
为了应对这一挑战,清华大学研究团队开发了SonicSim仿真平台和SonicSet数据集:
SonicSim是一个高度可定制的数据生成工具,能够模拟各种复杂的动态声源场景;
SonicSet则是基于SonicSim生成的大规模动态声源数据集,为语音分离和增强研究提供了丰富的训练和测试数据,这一创新性的解决方案不仅大幅降低了数据采集成本,还为动态语音处理技术的发展提供了强有力的支持。

论文地址:https://arxiv.org/abs/2410.01481
项目主页:https://cslikai.cn/SonicSim/
代码地址:https://github.com/JusperLee/SonicSim
SonicSim是一个基于Habitat-sim的可定制数据生成工具,专为语音任务设计。它利用Habitat-sim的高度真实的音频渲染器和高性能3D模拟器,生成适用于各种声学环境的高质量音频数据。

SonicSim的主要功能包括:
通过Habitat-sim,SonicSim可以导入各种由模拟或扫描生成的真实3D资产,如Matterport3D数据集。这使得生成复杂且真实的声学环境变得更加高效和可扩展。
SonicSim利用Habitat-sim模拟3D环境中的各种声学特征:
1. 使用室内声学建模和双向路径追踪算法准确模拟房间几何形状内的声音反射;
2. 将3D场景的语义标签映射到材料属性,设置不同表面的声学特征;
3. 基于声源路径合成移动声源数据;
SonicSim支持多种音频格式,如单声道、双耳和环绕声。此外,还集成了常见的线性和圆形麦克风阵列,并允许用户自定义麦克风阵列的形状。
SonicSim允许用户自定义或随机设置声源和麦克风的位置。除静态定位外,还支持基于指定起点和终点生成移动声源和麦克风的运动轨迹。

SonicSet是一个基于SonicSim构建的大规模动态声源数据集,专为研究移动语音分离和增强任务而设计。
该数据集的主要特点包括:
1. 多样性:SonicSet利用Matterport3D数据集中的90个建筑级场景,涵盖了广泛的真实环境,如家庭、办公室和教堂等。训练集包含62个场景,验证集19个场景,测试集9个场景。
2. 大规模:SonicSet整合了来自LibriSpeech数据集的360小时语音音频,结合来自FSD50K的环境噪声和FMA数据集的音乐噪声,提供了丰富多样的音频素材。
3. 高质量:通过模拟不同材料的声音反射和衍射,SonicSet生成的合成音频的房间冲激响应更接近真实环境,从而产生更高质量的混响音频。
4. 可定制性:SonicSet包含57596个语音移动轨迹,覆盖了室内场景中大多数可能的位置。数据集提供约952小时的训练数据,4小时的验证数据和4小时的测试数据。
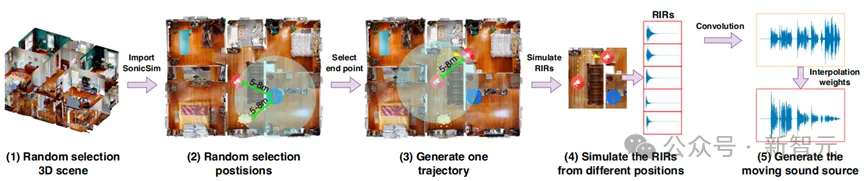
SonicSet的数据构建过程如下:
1. 从Matterport3D数据集中选择3D场景并导入SonicSim初始化声学环境。
2. 在场景中随机选择麦克风和声源的放置位置。
3. 基于声源的初始位置,在一定范围内选择声源的终点位置,并使用SonicSim的轨迹功能生成移动路径。
4. SonicSim计算路径上不同位置对应的房间冲激响应,并与源音频进行卷积。
5. 根据预先计算的索引和权重,从卷积输出中提取对应每个部分起始和结束位置的音频片段,并根据插值权重进行混合。
通过这一过程,SonicSet生成了时间上连贯的音频信号,准确反映了声源在空间环境中的移动。
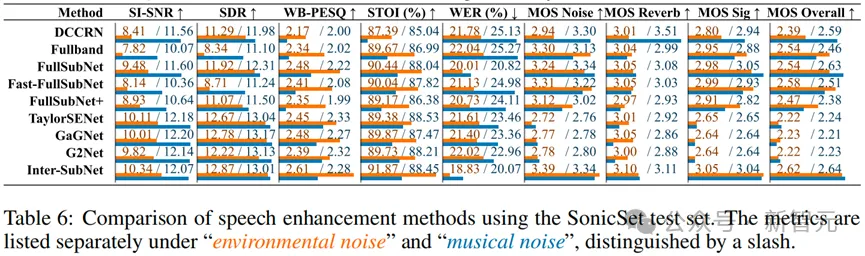
为了全面评估SonicSet数据集的有效性,研究团队在两种不同的背景噪声场景(音乐和环境噪声)下构建了Leaderboard,训练并测试了11种语音分离方法和9种语音增强方法,并分析了不同方法的效率指标。
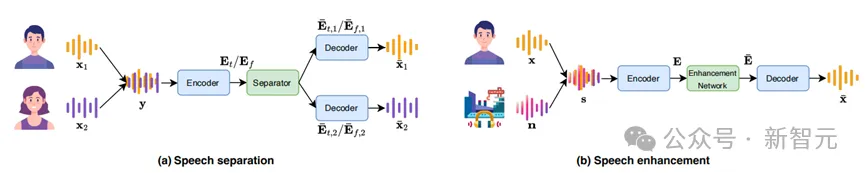
真实环境之间的声学差距,研究团队从SonicSet验证集中随机选择了一些原始音频,并在真实场景中进行录制,构建了一个包含10个场景、总时长5小时的语音分离数据集。

此外,对于语音增强任务,研究团队利用了RealMAN测试集,该测试集包含了来自真实环境的移动声源录音。
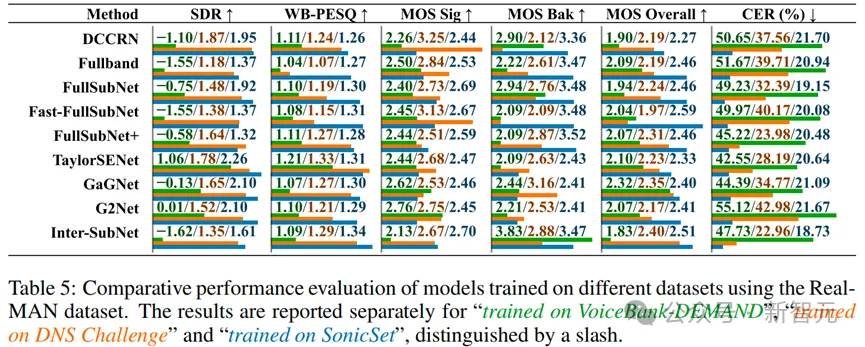
实验结果表明,在SonicSet数据集上训练的模型能够很好地泛化到真实环境中,验证了SonicSim在模拟真实声学环境方面的有效性,同时也凸显了SonicSet作为一个高质量合成数据集在语音研究中的潜力。
在嘈杂环境中,最新的模型相比之前的模型在各项指标上都有显著提升。TF-GridNet在所有评估指标上表现最为突出,特别是在SI-SNR、SDR和WER上显著优于其他模型。Mossformer系列模型也展示了强大的语音分离能力,但在WER上仍有提升空间。早期模型如Conv-TasNet和DPRNN在动态环境中的表现有限,更适合静态或低噪声环境下的应用。
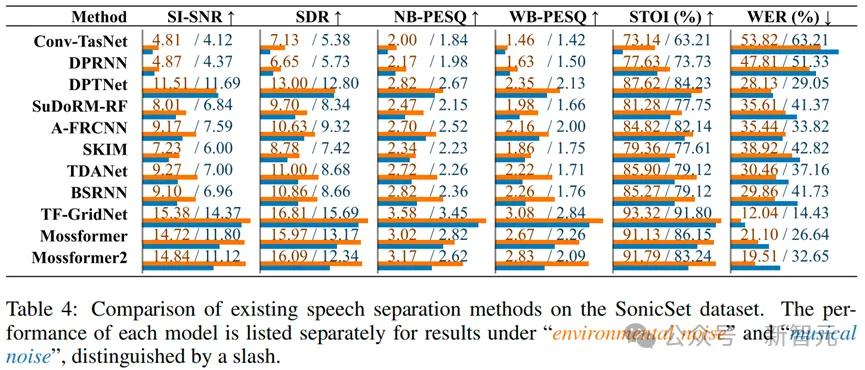
在不同噪声环境(嘈杂环境和音乐环境)中,各模型的表现存在显著差异。在嘈杂环境中,Inter-SubNet表现最为优异,特别是在NB-PESQ、WB-PESQ和WER上显著优于其他模型。在音乐环境中,FullSubNet在多数指标上表现出色,尤其是在WER上显示了较强的鲁棒性。
SonicSim和SonicSet的开发为动态环境下的语音分离和增强研究提供了强有力的工具和数据支持。
研究结果表明,在动态环境中提升语音处理模型的性能需要特别关注以下几个方面:
1, 数据多样性:SonicSet通过模拟不同场景中的动态声源和噪声源,为研究者提供了更真实、更丰富的训练数据。未来可以通过引入更多的环境变量和多源数据,进一步扩展数据集的多样性。
2. 模型适应性:实验结果显示,不同模型在动态环境中的表现存在显著差异。未来的研究应着重提高模型在复杂动态环境下的鲁棒性和适应性。
3. 真实环境迁移:虽然SonicSet在模拟真实环境方面表现出色,但进一步缩小合成数据与真实数据之间的差距仍然是一个重要的研究方向。
4. 新型应用场景:SonicSim的高度可定制性为探索新的应用场景提供了可能,如基于区域的语音增强和移动声源说话人定位等。
SonicSim和SonicSet的发布不仅为语音分离和增强研究提供了新的基准,也为未来的研究开辟了广阔的空间,通过持续改进仿真工具和优化模型算法,相信未来能够在复杂环境中部署更加高效、鲁棒的语音处理系统。
此外,SonicSim的开源性质使得研究人员能够使用更多的场景和数据来无限制地合成更多的移动声源数据,这将有助于训练更加鲁棒的分离和增强模型。研究团队也鼓励社区贡献新的场景和音频数据,以进一步扩展SonicSet的规模和多样性。
最后,SonicSim和SonicSet的成功开发也为其他相关领域的研究提供了启发。例如,在多模态学习、声学场景分类、声源定位等领域,类似的仿真平台和大规模数据集可能会带来突破性的进展。
参考资料:
https://arxiv.org/abs/2410.01481
文章来自于微信公众号“新智元”



