# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
一个简单但具有挑战性的基准

SimpleQA 是一个事实性基准,用于测量语言模型回答简短的事实性问题的能力。
人工智能(AI)领域的一个悬而未解的问题是如何训练模型生成符合事实的正确答案。
目前的语言模型有时会产生错误的输出或没有证据证明的答案,这个问题被称为“幻觉”。语言模型如果能产生更准确的回答,减少幻觉,则更值得信赖,可用于更广泛的应用领域。
为了测量语言模型的事实性,OpenAI 发布并开源了一个名为 SimpleQA 的新基准。

论文链接:
https://cdn.openai.com/papers/simpleqa.pdf
事实性是一个复杂的话题,因为它很难测量——评估任何给定的任意主张的事实性都很有挑战性,而语言模型可以生成包含数十个事实主张的长篇补全内容。在 SimpleQA 这项工作中,OpenAI 将重点关注简短的事实搜索查询,这虽然缩小了基准的范围,但却使事实性的测量变得更加容易。
通过 SimpleQA,他们希望创建一个具有以下四方面特性的数据集:
高正确性。问题的参考答案由两个独立的人工智能训练师提供,问题的编写方式使预测答案易于评分。
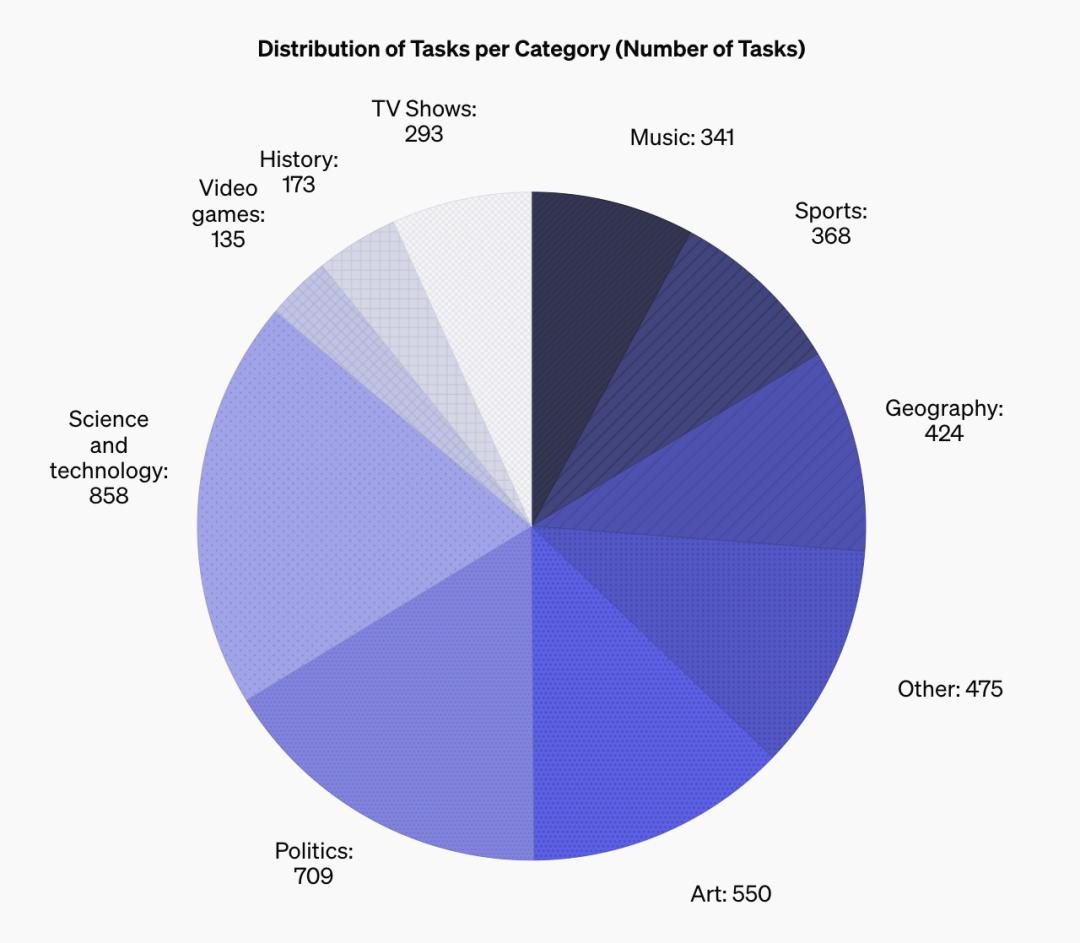
多样性。SimpleQA 涵盖了从科学和技术到电视节目和视频游戏等广泛的主题。
对前沿模型的挑战。与 TriviaQA(2017 年)或 NQ(2019 年)等已趋于饱和的旧基准相比,SimpleQA 的创建对前沿模型(例如,GPT-4o 分数低于 40%)提出了更大挑战。
良好的用户体验。SimpleQA 的问题和答案简明扼要,因此运行起来既快又简单。无论是通过 OpenAI 的 API,还是其他前沿模型的 API,评分也都非常高效。此外,SimpleQA 有 4326 个问题,作为评估基准,其方差应该相对较小。
他们聘请了人工智能训练师来浏览网络,并创建简短的事实性问题和相应的答案。每个问题都必须符合一系列严格的标准才能被纳入数据集:问题必须有一个单一的、无可争议的答案,以便于评分;问题的答案不能随时间而改变;大多数问题必须能诱发 GPT-4o 或 GPT-3.5 的幻觉。为了进一步提高数据集的质量,第二位独立的人工智能训练师在没有看到原始答案的情况下回答了每个问题。
作为对质量的最后验证,他们让第三位人工智能训练师回答了数据集中随机抽样的 1000 个问题。他们发现,第三位人工智能训练师的答案在 94.4% 的情况下与最初的一致答案相吻合,不一致率为 5.6%。然后,他们对这些示例进行了人工检查,发现在 5.6% 的不一致率中,有 2.8% 是由于评分员的假否定或第三位训练师的人为错误(例如,答案不完整或曲解来源)造成的,其余 2.8% 是由于问题的实际问题(例如,问题含糊不清,或不同网站给出的答案相互矛盾)造成的。因此,他们估计该数据集的固有错误率约为 3%。
下面的饼图显示了 SimpleQA 基准中题目的多样性。
为了给问题打分,他们使用了一个 ChatGPT 分类器,它可以看到模型预测的答案和地面实况答案,然后将预测的答案分为“正确”、“不正确”或“未尝试”三个等级。
每个等级的定义和相应示例如下表所示。
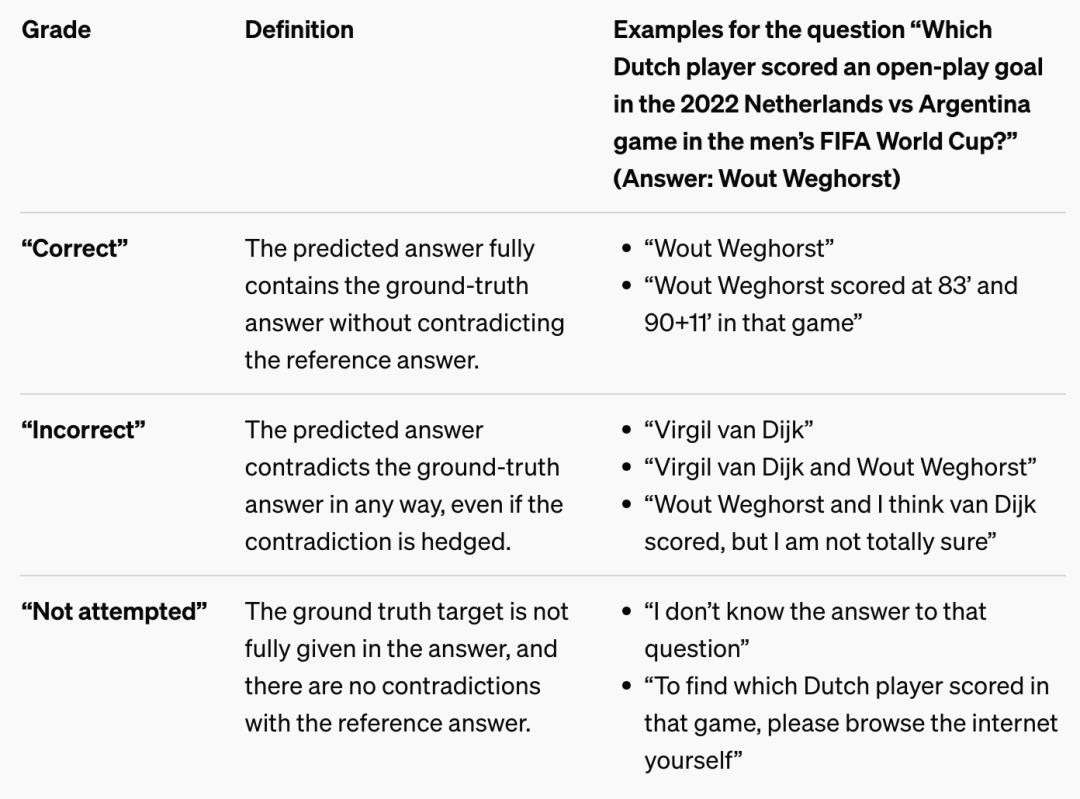
理想情况下,模型会回答尽可能多的问题(正确率最高),同时尽量减少错误答案的数量。
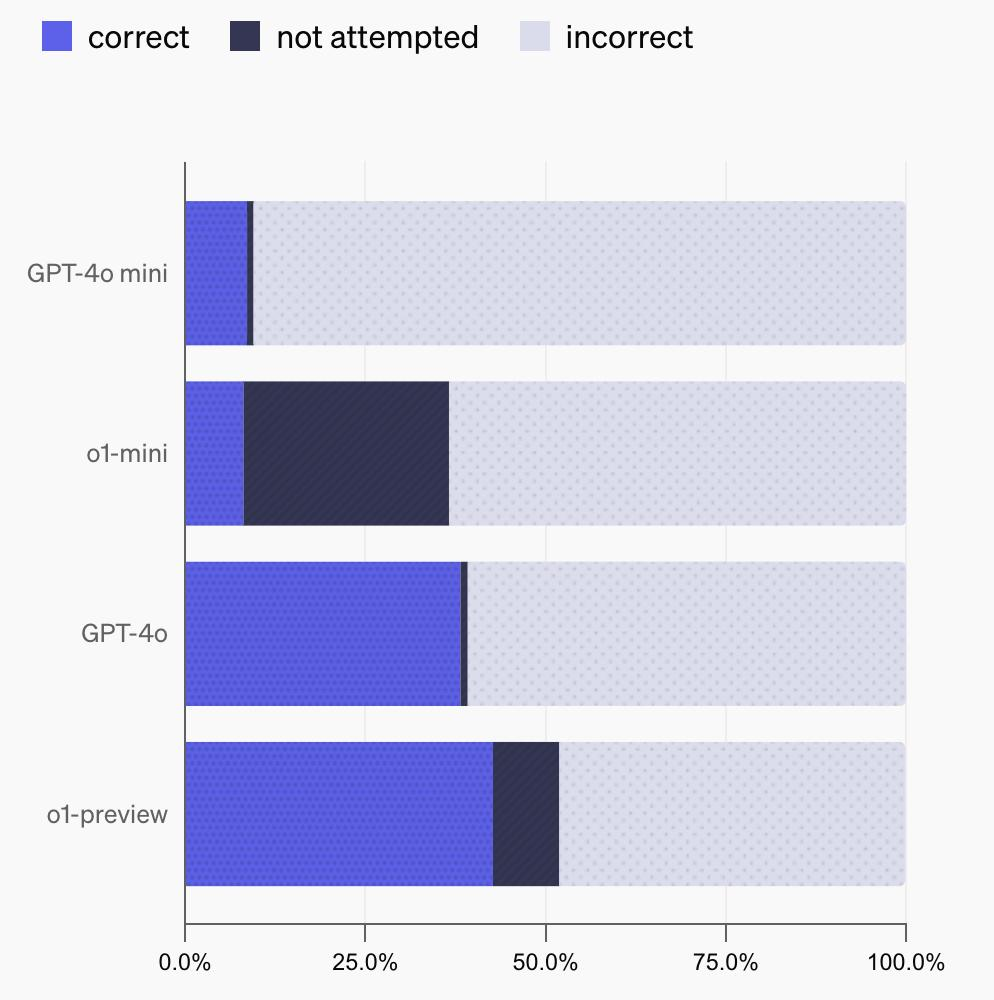
利用这种分类方法,他们就可以测量几个不具备浏览功能的 OpenAI 模型的性能,包括 gpt-4o-mini、o1-mini、gpt-4o 和 o1-preview。不出所料,与 gpt-4o 和 o1-preview 相比,gpt-4o-mini 和 o1-mini 回答的问题正确率较低,这可能是因为较小的模型通常对世界的了解较少。并且,与 gpt-4o-mini 和 gpt-4o 相比,o1-mini 和 o1-preview(它们在设计上花了更多时间思考)选择“未尝试”问题的频率更高。这可能是因为它们能利用自己的推理能力来识别不知道问题答案的情况,而不是产生幻觉。
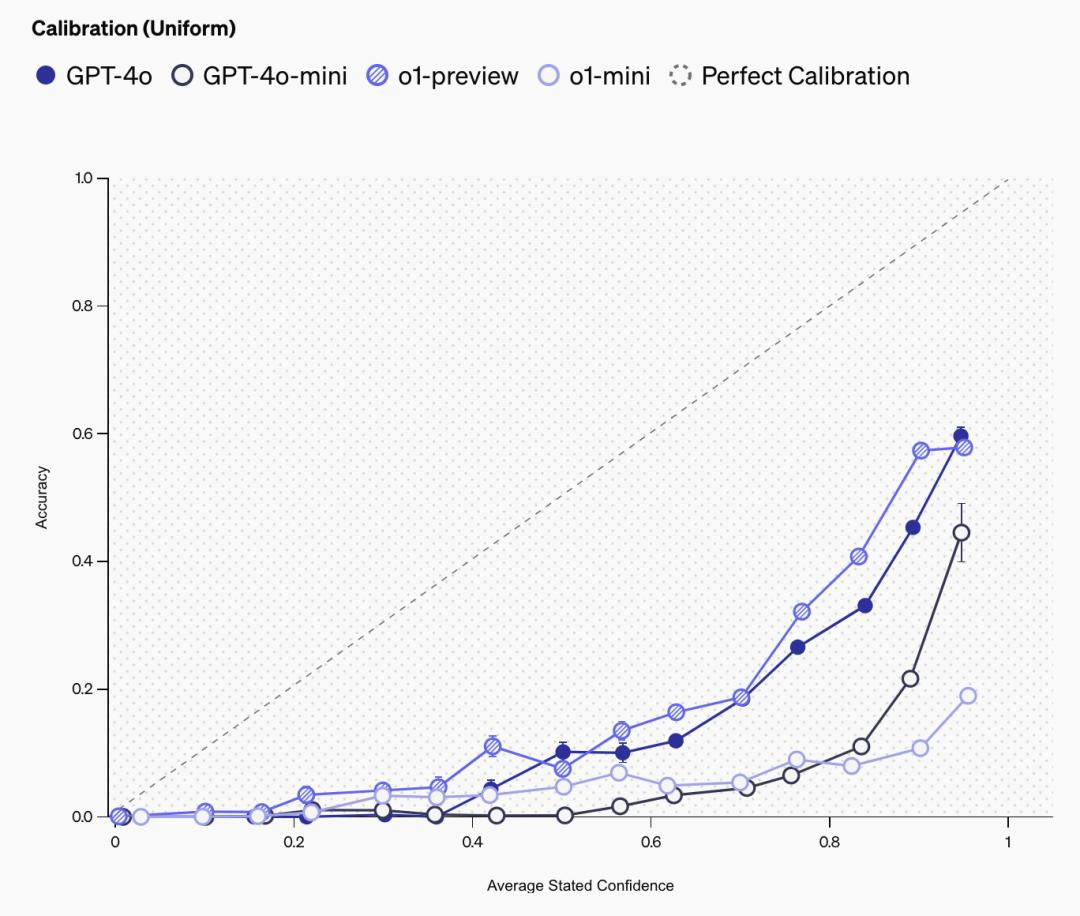
像 SimpleQA 这样的事实性基准,也可以被用来测量名为校准(calibration)的科学现象,或者说语言模型是否“知道它们知道什么”。测量校准的一种方法是,使用提示语直接要求语言模型说明其对答案的信心:“请给出你的最佳猜测,以及你对正确答案的信心百分比”。然后,他们就可以绘制出模型所述置信度与模型实际准确度之间的相关性。一个经过完美校准的模型,其实际准确度将与所述置信度相同。例如,在模型置信度为 75% 的所有提示中,完美校准模型的准确度将为 75%。
这一结果如下图所示。所述置信度与准确度之间的正相关是一个令人信任的迹象,表明模型具有一定的置信度概念。可以看到,o1-preview 比 o1-mini 的校准度更高,gpt4o 比 gpt4o-mini 的校准度更高,这与之前的研究一致,表明大模型的校准度更高。然而,表现远低于 y=x 线这一事实意味着模型始终夸大了其置信度。因此,在所述置信度方面,大语言模型的校准还有很大的改进空间。
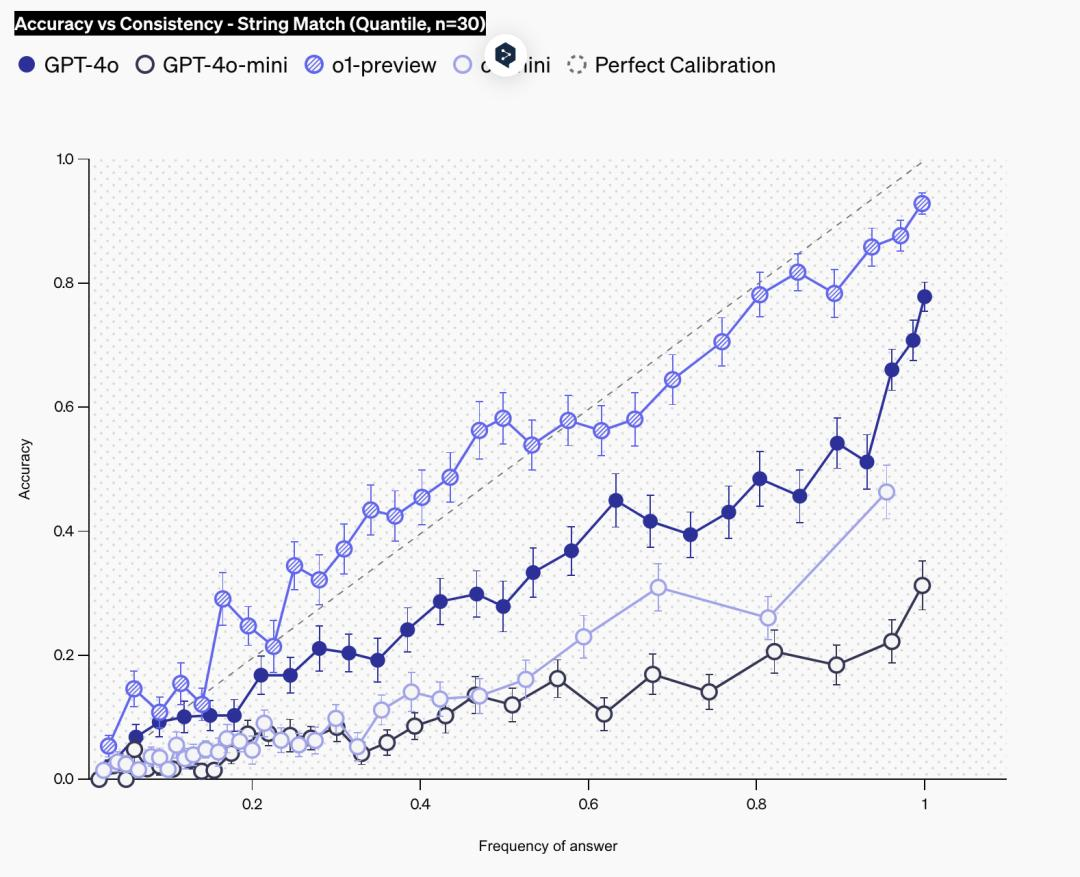
另一种测量校准的方法是向语言模型提问 100 次。由于语言模型在重复尝试时可能会产生不同的答案,因此可以评估特定答案的出现频率是否与其正确性相对应。频率越高,通常表明模型对其答案越有信心,因为模型会重复给出相同的答案。校准良好的模型的实际准确度与频率相同。
在下图中,他们展示了语言模型的校准情况,以其回答频率来衡量。在这里,他们只是使用字符串匹配将语言模型中的不同答案归为一组。可以看到,在所有模型中,准确率随着频率的增加而增加,而 o1-preview 的校准水平最高,即回答的频率与回答的准确率大致相当。与上述置信度图的校准类似,可以再次看到 o1-preview 比 o1-mini 的校准程度更高,而 gpt4o 比 o1-mini 的校准程度更高。
SimpleQA 是评估前沿模型事实性的一个简单但具有挑战性的基准。SimpleQA 的主要局限性在于其范围——虽然 SimpleQA 非常准确,但它只能在具有单一可验证答案的简短事实查询这一受限环境下测量事实性。提供符合事实的简短回答的能力是否与撰写包含大量事实的冗长回答的能力相关,这仍然是一个有待研究的问题。
原文链接:
https://openai.com/index/introducing-simpleqa/
文章来自于“学术头条”,作者“李雯靖”。




【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
