# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大模型虽好,但「一本正经的胡说八道」的问题该怎么解?
在金融、法律、医疗等严肃领域,幻觉问题一直是制约大模型落地应用的主要瓶颈。
如何弥补这部分缺陷,使更多行业能快速加入对新一轮生产力变革的探索,是当下AI研究的重要课题,其中,大模型(LLM)与知识图谱(KG)的融合来弥补前者的能力短板,是颇受关注的研究方向。
最近,来自IDEA研究院、微软亚洲研究院、香港科技大学、香港科技大学(广州)、厦门大学和美国南加州大学的研究团队推出Think-on-Graph(思维图谱)技术,通过LLM与KG的紧耦合交互,驱动LLM agent在知识图谱上「思考」,逐步搜索推理出最优答案。

论文地址:https://arxiv.org/abs/2307.07697
代码链接:https://github.com/IDEA-FinAI/ToG
下面,我们先用一个刁钻的问题来认识Think-on-Graph的「脑回路」:如何客观评价段誉和洪七公谁的武功更高强?(段誉出自《天龙八部》,洪七公出自《射雕英雄传》,两者未在同一部作品中出现。)
首先看看地表最强大模型GPT-4是怎么说的:
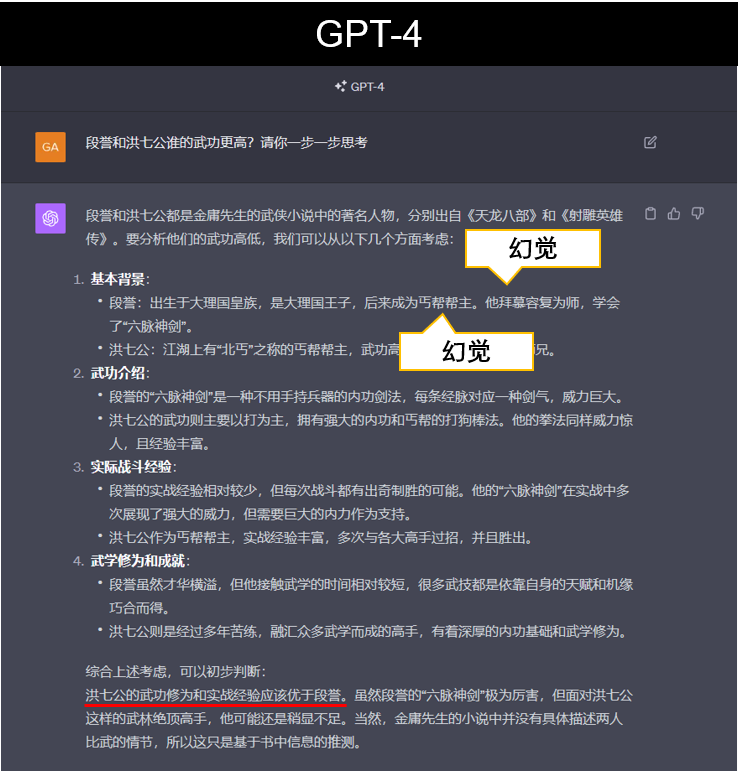
由于LLM是经由海量碎片化语料训练而成,此类线索分析型的推理问题确实对其挑战很大。从回答中不难看出,除了幻觉现象的出现之外,在比较两位人物的武功水平时,GPT-4着重罗列表象事实,缺乏深度的逻辑分析。
那么, Think-on-Graph是怎样解题的呢?
首先,图谱知识显示,六脉神剑是大理段氏最强武功,而一阳指是大理段氏常用武功,大模型由此判断「六脉神剑」强于「一阳指」;继而推理出段誉武功强于以一阳指冠绝江湖的一灯大师。
然后,又根据图谱上的「一灯大师与洪七公同属『华山四绝』」,推理出两者武功相当。最终,段誉>一灯大师,而一灯大师=洪七公,于是得出结论:段誉武功更高。
可见,融合了结构化知识与大模型推理能力的Think-on-Graph,不仅条理清晰,还提供了可追溯的推理链条。
众所周之,大模型擅长理解、推理、生成与学习;知识图谱则因其结构化的知识存储方式,在逻辑链条推理上表现更佳,且具备更好的推理透明度与可信度。两者是互补度极高的好拍档,关键在于能否找到好的结合方式,据研究人员介绍,目前主流的方法有两类。
第一类是在模型预训练或微调阶段,将知识图谱嵌入到一个高维向量空间,并与大模型的嵌入向量相融合。
但此类方法不仅耗时、耗算力,也无法发挥知识图谱的许多天然优势(如:实时知识更新、可解释性、推理可追溯等)。
第二类路径则利用知识图谱的知识结构,通过prompt engineering来进行两者的融合,这之中又分松耦合、紧耦合两种范式。
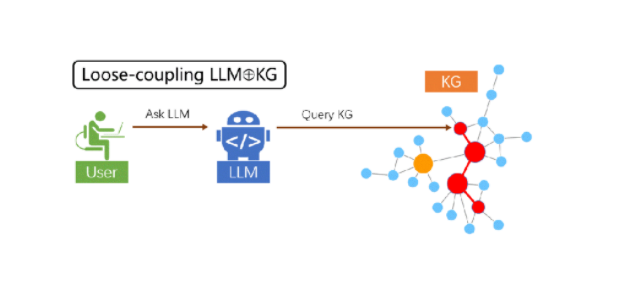
松耦合范式中的LLM相当于「翻译官」,理解用户的自然语言输入后,将其翻译成知识图谱中的查询语言,再将KG上的搜索结果反向翻译给用户,这种范式对知识图谱本身的质量与完整度要求极高,忽略了大模型的内在知识与推理能力。
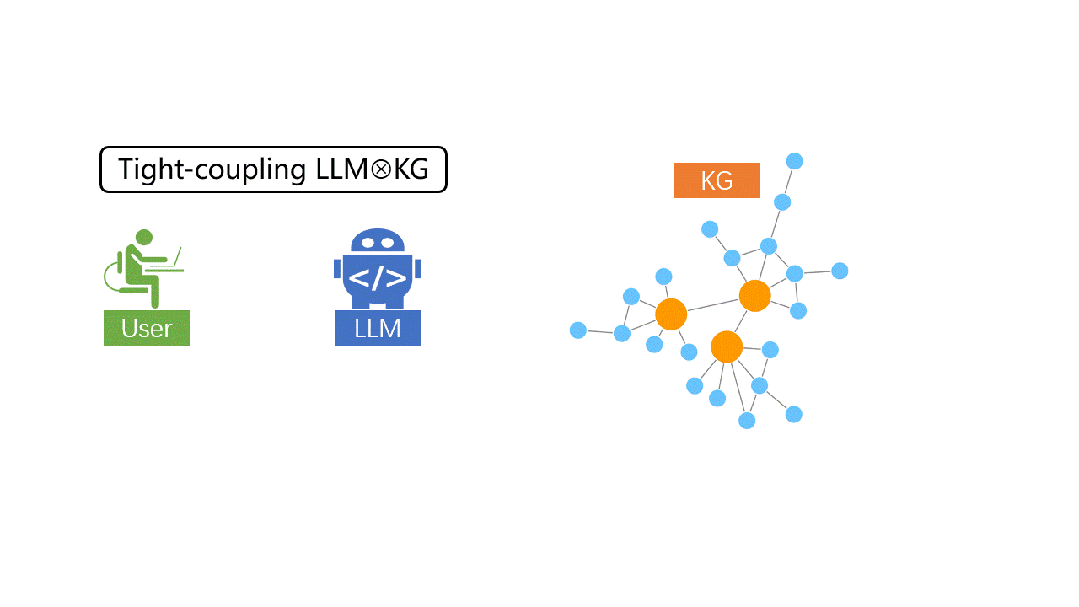
在Think-on-Graph所代表的紧耦合范式中,LLM变身「跑腿」,作为agent在KG的关联实体上一步一步搜索推理出最优答案。因此,在每一步推理中,LLM都亲自参与,与知识图谱取长补短。
在研究中,团队用以下例子展示了紧耦合范式的优势:堪培拉所在国家当前的多数党是哪个党派?
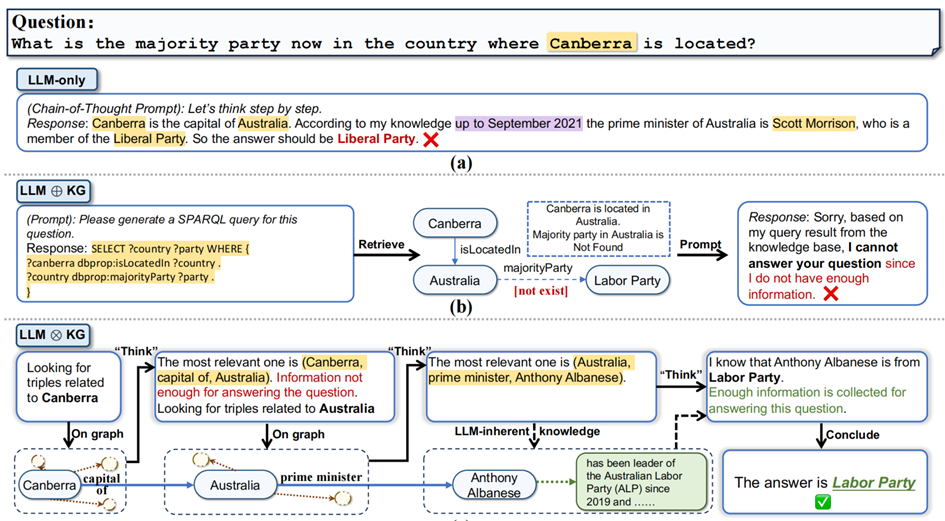
从上面例子中可以看出,ChatGPT由于信息滞后,给出了错误答案。
松耦合范式下,尽管引入了包含最新信息的KG,但由于缺少「多数党」信息,导致推理无法完成;而在紧耦合范式中,LLM自行推理出「议会制国家的政府首脑(总理)通常也是多数党领袖」,弥补了KG中的信息缺失,绕道推理出正确答案。
据研究团队介绍,Think-on-Graph借鉴了Transformer的beam-search算法思路。该算法为一个可循环的迭代过程,每次循环需先后完成搜索剪枝、推理决策两个任务。
搜索剪枝用于找出最有希望成为正确答案的推理路径,推理决策任务则通过LLM来判断已有的候选推理路径是否足以回答问题——如果判断结果为否,则继续迭代到下个循环。
我们依然以「堪培拉所在国当前的多数党是哪个党派?」为例来解释。
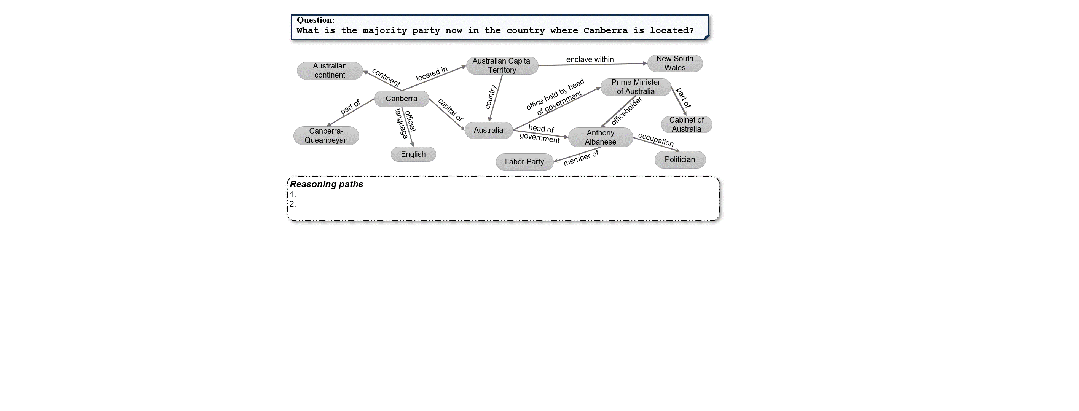
案例:用搜索宽度N=2的beam-search实现Think-on-Graph推理
在搜索剪枝任务中,大模型从关键词Canberra出发,匹配到知识图谱中最接近(或一致)的实体,分别搜索了5个「关系→实体」对,并为它们打分(得分越高,则代表此新实体加入推理路径中,可正确回答问题的能力越高)。

将分数从高到低排序后,LLM保留了得分最高的2个,形成两条候选推理路径:
接下来,LLM对候选推理路径进行评估,并将结果以Yes/No的形式反馈给算法。
在案例中可见,LLM连续两轮否决了候选路径,直到完成第三轮迭代时,LLM才判断已获取回答问题的充分信息,因此停止算法迭代,向用户输出答案(该答案确为正确答案)。

研究团队表示,Think-on-Graph算法还有效提升了大模型推理的可解释性,并实现知识的可追溯、可纠错与可修正。尤其是借助人工反馈与LLM推理能力,发现并修正知识图谱中的错误信息,弥补LLM训练时间长、知识更新慢的缺点。
为测试此能力,我们设计了一个实验:在前述「段誉与洪七公武功对比」案例的知识图谱中,故意掺入错误信息「大理段氏的最强武功是一阳指,一般武功是六脉神剑」。

可见,尽管Think-on-Graph根据错误知识得出了错误答案,但由于算法内置的「自我反思」能力,当判断答案可信度不足时,会自动回溯在知识图谱上的推理路径,检查路径中的所有三元组。
此时,LLM将利用自有知识,将疑似有误的三元组挑选出来,并向用户反馈分析与纠错建议。

研究在四类知识密集型任务(KBQA, Open-Domain QA, Slot Filling, Fact Checking)的共9个数据集上,对Think-on-Graph的表现进行了评估。
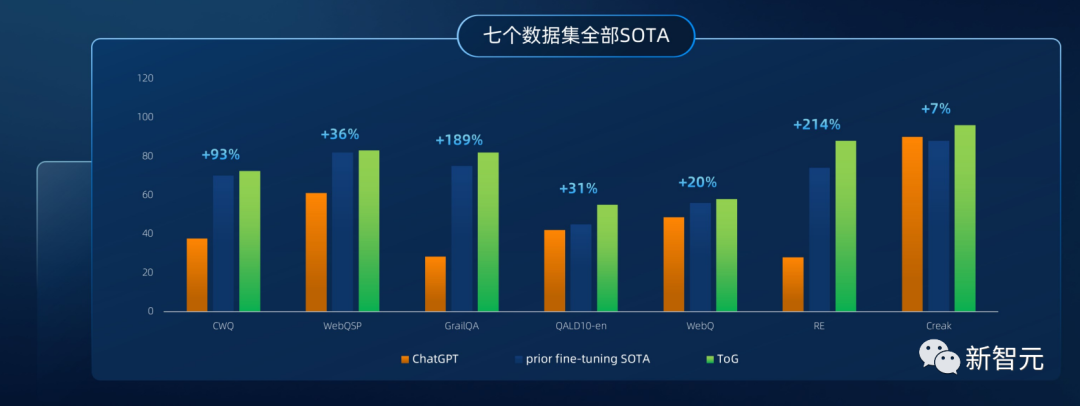
与IO、CoT、CoT-SC等不同prompting策略下的ChatGPT(GPT-3.5)相比,Think-on-Graph在所有数据集上的表现都显著更优。以Zeroshot-RE数据集中的对比为例,基于CoT的ChatGPT精度为28.8%,而同底座的Think-on-Graph精度为88%。
当底座模型升级为GPT-4后,Think-on-Graph的推理精度也明显提升,在7个数据集上取得了SOTA,剩余数据集中的CWQ上也十分接近SOTA。
值得注意的是,Think-on-Graph未在上述任何测试数据集上进行过监督学习性质的增量训练或增量微调,体现出超强的即插即用能力。
此外,研究者还发现,即便替换小规模的底座模型(如LLAMA2-70B),Think-on-Graph依然可在多个数据集上超越ChatGPT,这或可为大模型使用者提供一条低算力需求的技术路线选择。
参考资料:
https://arxiv.org/abs/2307.07697
https://github.com/IDEA-FinAI/ToG
文章来自于t微信公众号 “新智元”,作者 “LRS、好困”


【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
