# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
本文将带你构建一个多智能体新闻助理,利用 OpenAI 的 Swarm 框架和 Llama 3.2 来自动化新闻处理工作流。在本地运行环境下,我们将实现一个多智能体系统,让不同的智能体各司其职,分步完成新闻搜索、信息综合与摘要生成等任务,而无需付费使用外部服务。
OpenAI Swarm 是一个新兴的多智能体协作框架,旨在通过集成强化学习和分布式计算的优势来解决复杂问题。该框架允许多个智能体在共享环境中同时交互与学习,彼此共享信息,从而提高决策质量和学习效率。Swarm 框架采用先进的强化学习算法,使智能体能够在动态环境中持续适应和优化策略,同时通过分布式计算高效利用资源,加速训练过程。它具有很强的可扩展性,能够根据需求增加智能体数量,适应不同规模和复杂度的任务。应用场景广泛,包括智能交通系统、机器人群体和游戏开发等,OpenAI Swarm 为实现更高效的智能系统提供了灵活且强大的解决方案,推动各领域的智能化进程。
Swarm 的详细介绍可参考之前的文章:《通过 Swarm 构建模块化、可扩展的多代理应用程序》
本文我们将使用 Swarm 框架来构建智能体。
DuckDuckGo 是一家以隐私保护为核心的互联网搜索引擎公司。与其他主流搜索引擎不同,DuckDuckGo承诺不追踪用户的搜索历史,也不收集个人数据,从而提供更高的隐私保护。该搜索引擎通过结合多种来源的数据,包括自有的网络爬虫和第三方API,提供快速且相关的搜索结果。
DuckDuckGo 的主要特点包括:
我们将使用 DuckDuckGo 进行实时新闻搜索,获取最新信息。将会有一个专门的智能体将负责向 DuckDuckGo 发送搜索请求并处理返回结果。
通过 Ollama 应用在本地运行 meta 公司的大模型 Llama 3.2。使之成为智能体的模型基座,用来处理与总结新闻内容。Llama 3.2 将作为专用的摘要生成智能体,处理从搜索结果中获取的文本信息,并生成精炼、易读的新闻摘要。
Streamlit 是一个开源的 Python 库,专为数据科学家和开发者设计,用于快速创建和分享美观的交互式数据应用。它通过简洁的 API,允许用户以极少的代码实现复杂的应用功能,无需前端开发知识。Streamlit 支持热重载,即代码一保存,应用即更新,极大地加快了开发和迭代过程。此外,它提供了丰富的内置组件和易于部署的特性,使得从数据可视化到机器学习模型演示都变得简单快捷,非常适合快速原型开发和结果展示。
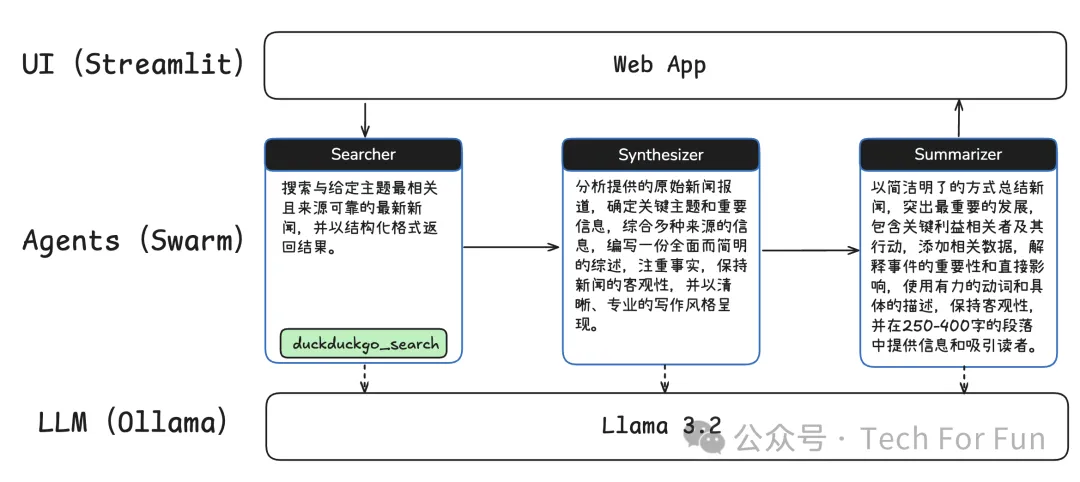
整个流程将由三个智能体分工协作完成:
从 Searcher进行搜索 到 Synthesizer 进行合成,最后由 Summarizer 进行总结。
三个智能体的职责描述如下:
通过 Ollama 下载 Llama3.2:

运行 Llama3.2 看看是否正常:

创建如下 requirements.txt 文件:
git+https://github.com/openai/swarm.git
streamlit
duckduckgo-search
在命令行执行命令 pip install -r requirements.txt,安装相关依赖项。
search_agent = Agent(
name="News Searcher",
instructions="""
You are a news search specialist. Your task is to:
1. Search for the most relevant and recent news on the given topic
2. Ensure the results are from reputable sources
3. Return the raw search results in a structured format
""",
functions=[search_news],
model=MODEL
)
创建新闻搜索智能体:
synthesis_agent = Agent(
name="News Synthesizer",
instructions="""
You are a news synthesis expert. Your task is to:
1. Analyze the raw news articles provided
2. Identify the key themes and important information
3. Combine information from multiple sources
4. Create a comprehensive but concise synthesis
5. Focus on facts and maintain journalistic objectivity
6. Write in a clear, professional style
Provide a 2-3 paragraph synthesis of the main points.
""",
model=MODEL
)
创建新闻合成智能体:
summary_agent = Agent(
name="News Summarizer",
instructions="""
You are an expert news summarizer combining AP and Reuters style clarity with digital-age brevity.
Your task:
1. Core Information:
- Lead with the most newsworthy development
- Include key stakeholders and their actions
- Add critical numbers/data if relevant
- Explain why this matters now
- Mention immediate implications
2. Style Guidelines:
- Use strong, active verbs
- Be specific, not general
- Maintain journalistic objectivity
- Make every word count
- Explain technical terms if necessary
Format: Create a single paragraph of 250-400 words that informs and engages.
Pattern: [Major News] + [Key Details/Data] + [Why It Matters/What's Next]
Focus on answering: What happened? Why is it significant? What's the impact?
IMPORTANT: Provide ONLY the summary paragraph. Do not include any introductory phrases,
labels, or meta-text like "Here's a summary" or "In AP/Reuters style."
Start directly with the news content.
""",
model=MODEL
)
创建新闻摘要代理:
import streamlit as st
from duckduckgo_search import DDGS
from swarm import Swarm, Agent
from datetime import datetime
from dotenv import load_dotenv
# 加载环境变量
load_dotenv()
# 定义模型
MODEL = "llama3.2:latest"
# 初始化 Swarm 客户端
client = Swarm()
# 通过 Streamlit 创建用户界面,为页面和应用程序添加一个标题
st.set_page_config(page_title="AI News Processor", page_icon="📰")
st.title("📰 News Inshorts Agent")
# 定义新闻搜索 Function,使用 DuckDuckGo 搜索 API,获取当月新闻,并返回结构化结果
def search_news(topic):
"""Search for news articles using DuckDuckGo"""
with DDGS() as ddg:
results = ddg.text(f"{topic} news {datetime.now().strftime('%Y-%m')}", max_results=3)
if results:
news_results = "\n\n".join([
f"Title: {result['title']}\nURL: {result['href']}\nSummary: {result['body']}"
for result in results
])
return news_results
return f"No news found for {topic}."
# 创建智能体
search_agent = Agent(
name="News Searcher",
instructions="""
You are a news search specialist. Your task is to:
1. Search for the most relevant and recent news on the given topic
2. Ensure the results are from reputable sources
3. Return the raw search results in a structured format
""",
functions=[search_news],
model=MODEL
)
synthesis_agent = Agent(
name="News Synthesizer",
instructions="""
You are a news synthesis expert. Your task is to:
1. Analyze the raw news articles provided
2. Identify the key themes and important information
3. Combine information from multiple sources
4. Create a comprehensive but concise synthesis
5. Focus on facts and maintain journalistic objectivity
6. Write in a clear, professional style
Provide a 2-3 paragraph synthesis of the main points.
""",
model=MODEL
)
summary_agent = Agent(
name="News Summarizer",
instructions="""
You are an expert news summarizer combining AP and Reuters style clarity with digital-age brevity.
Your task:
1. Core Information:
- Lead with the most newsworthy development
- Include key stakeholders and their actions
- Add critical numbers/data if relevant
- Explain why this matters now
- Mention immediate implications
2. Style Guidelines:
- Use strong, active verbs
- Be specific, not general
- Maintain journalistic objectivity
- Make every word count
- Explain technical terms if necessary
Format: Create a single paragraph of 250-400 words that informs and engages.
Pattern: [Major News] + [Key Details/Data] + [Why It Matters/What's Next]
Focus on answering: What happened? Why is it significant? What's the impact?
IMPORTANT: Provide ONLY the summary paragraph. Do not include any introductory phrases,
labels, or meta-text like "Here's a summary" or "In AP/Reuters style."
Start directly with the news content.
""",
model=MODEL
)
# 实施新闻处理工作流程,按顺序处理,显示进度指标
def process_news(topic):
"""Run the news processing workflow"""
with st.status("Processing news...", expanded=True) as status:
# Search
status.write("🔍 Searching for news...")
search_response = client.run(
agent=search_agent,
messages=[{"role": "user", "content": f"Find recent news about {topic}"}]
)
raw_news = search_response.messages[-1]["content"]
# Synthesize
status.write("🔄 Synthesizing information...")
synthesis_response = client.run(
agent=synthesis_agent,
messages=[{"role": "user", "content": f"Synthesize these news articles:\n{raw_news}"}]
)
synthesized_news = synthesis_response.messages[-1]["content"]
# Summarize
status.write("📝 Creating summary...")
summary_response = client.run(
agent=summary_agent,
messages=[{"role": "user", "content": f"Summarize this synthesis:\n{synthesized_news}"}]
)
return raw_news, synthesized_news, summary_response.messages[-1]["content"]
# 用户交互界面
topic = st.text_input("Enter news topic:", value="artificial intelligence")
if st.button("Process News", type="primary"):
if topic:
try:
raw_news, synthesized_news, final_summary = process_news(topic)
st.header(f"📝 News Summary: {topic}")
st.markdown(final_summary)
except Exception as e:
st.error(f"An error occurred: {str(e)}")
else:
st.error("Please enter a topic!")
在命令行运行 streamlit run news_agent.py:
Streamlit 应用网址 http://localhost:8501 会自动打开:
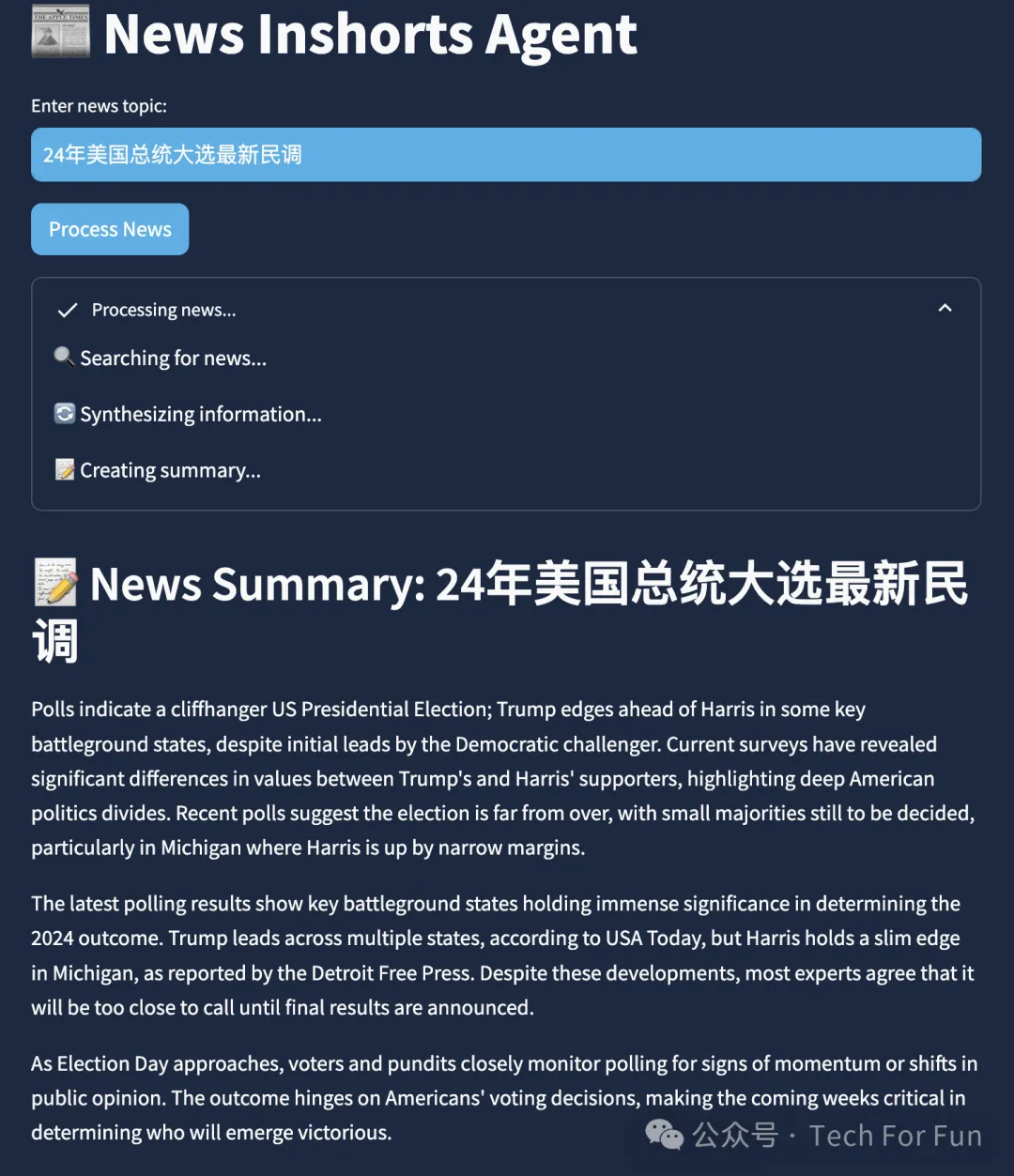
输入主题,并点击处理 Process News 按钮后,会得到搜索概述结果:
文章来自于微信公众号“Tech For Fun”,作者“kaelzhang”




【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】ScrapeGraphAI是一个爬虫Python库,它利用大型语言模型和直接图逻辑来增强爬虫能力,让原来复杂繁琐的规则定义被AI取代,让爬虫可以更智能地理解和解析网页内容,减少了对复杂规则的依赖。
项目地址:https://github.com/ScrapeGraphAI/Scrapegraph-ai
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
