# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
国内首个全面开源的千亿模型,来了!
就在昨天,浪潮信息正式发布源2.0,无论是2B、51B,还是102B,统统都开源。
这一次,源2.0不仅在数理逻辑、数学计算、代码生成能力上,再次超强进化。
而且,还在算法、数据、算力方面,提出了三项创新。

开源地址:https://github.com/IEIT-Yuan/Yuan-2.0
算法方面,源2.0提出并采用了一种新型的注意力算法结构LFA(局部注意力过滤增强机制,Localized Filtering-based Attention),对于自然语言的关联语义理解更准确。
数据方面,源2.0使用中英文书籍、百科、论文等高质量中英文资料,降低了互联网语料内容占比,增加了高质量的专业数据集和逻辑推理数据集。
算力方面,源2.0采用了非均匀流水并行和优化器参数并行的分布式训练方法,显著降低了大模型对芯片间P2P带宽的需求。
从评测结果来看,不管是在HumanEval上,还是在GSM8K、高考数学上,源2.0模型都超过了ChatGPT,甚至接近GPT-4的精度。
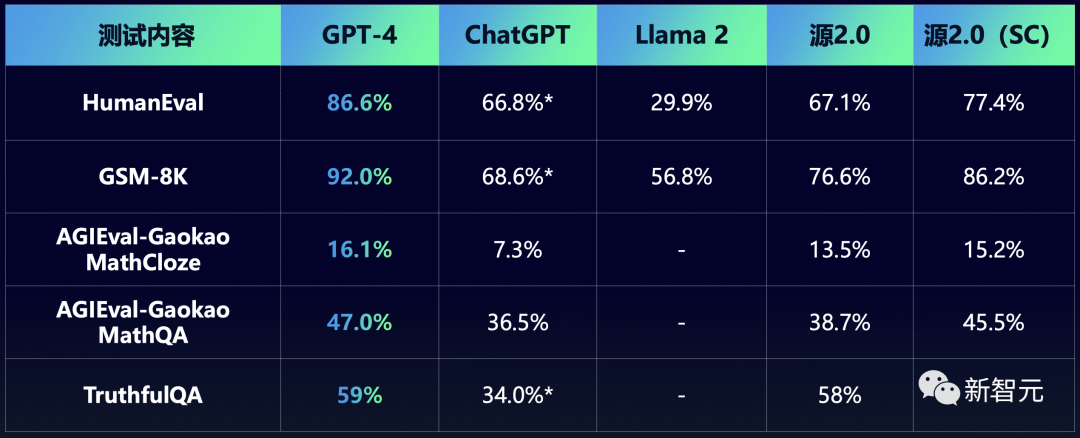
由于源2.0具备生成单元测试的能力,因此团队在HumanEval评估中使用了SC(自洽性,Self-Consistency)方法。也就是,采用由源2.0-102B生成的单元测试作为评判标准,选出成功通过单元测试的候选者。
结果显示,自洽性可以显著提高模型的的性能。比如,HumanEval评测的正确率提升了10.3%,GSM8K提升了9.6%等等。
下面我们就来看看,源2.0的表现到底如何。
首先是数学能力。
仔细看下面这道高考数学填空题就会发现,它的求解逻辑非常复杂。
这就要求模型不仅具备较好的基础知识,还需要有较好的推理以及计算能力。
从解题过程可以看出,源2.0-102B的推理路径正确,求解过程详尽,符号计算和数值计算均准确。在适当的位置上,模型明确地给出了最终答案,表现出了优异的逻辑推理性能。

根据GSM8K的评估结果,1026亿和518亿参数的源2.0,准确率都超过了76%。
与此同时,21亿参数的源2.0在准确率上也超过了规模大几十倍的Llama,达到了66.6%。
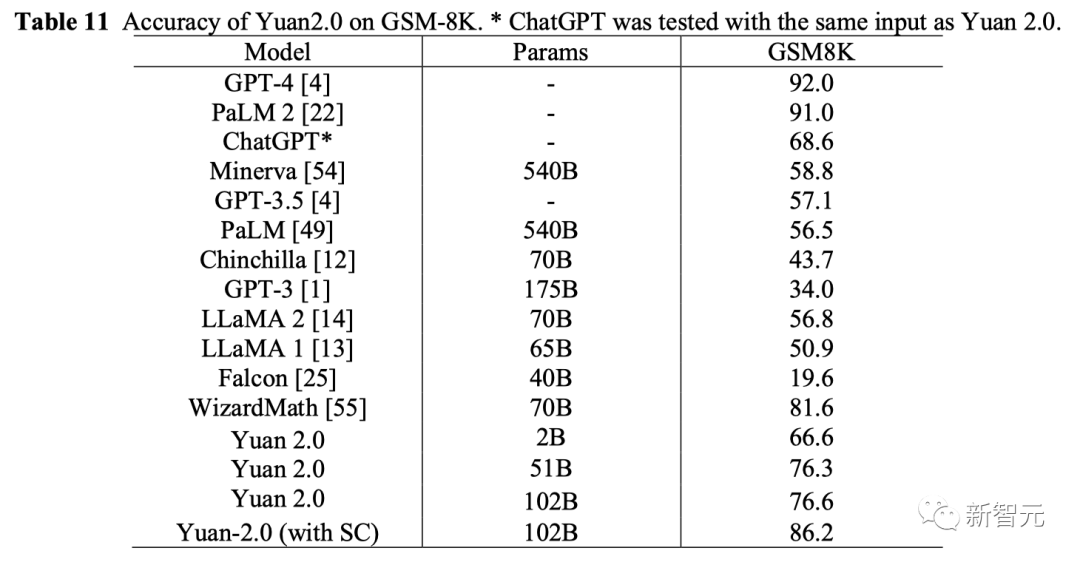
而在AGIEval高考数学任务上,源2.0的得分优于ChatGPT。
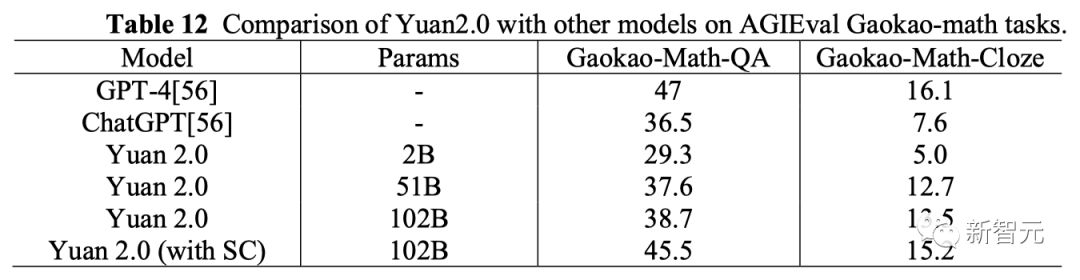
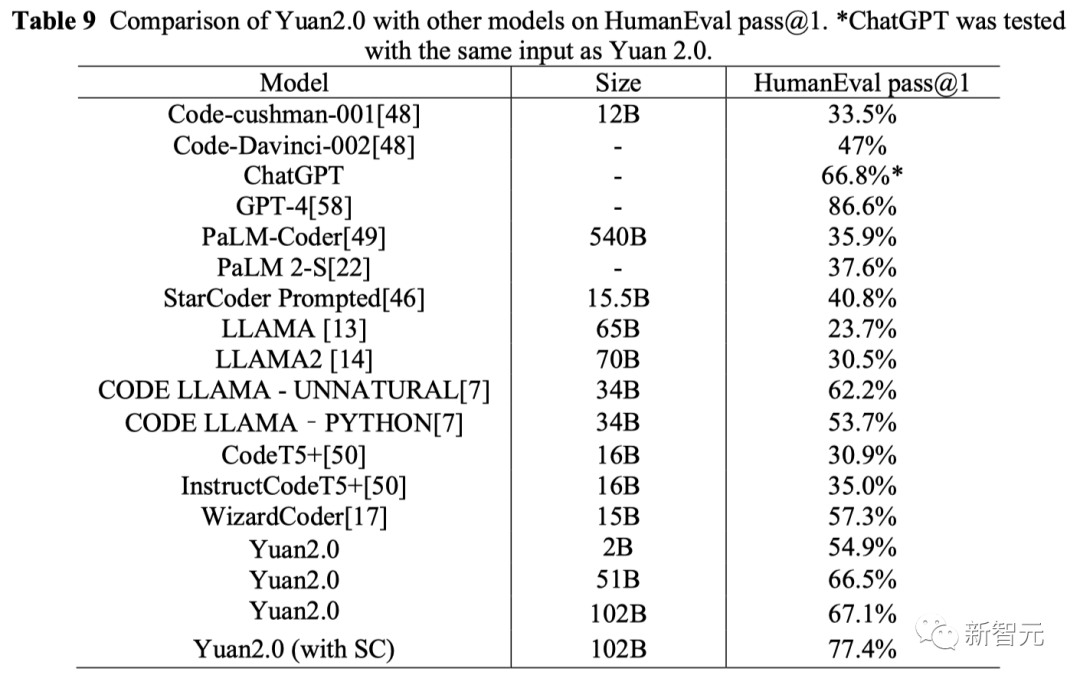
代码生成上,源2.0表现出的优异性能让人印象深刻。
可以看到,下面这道HumanEval评测题出得非常刁钻,即便是经验丰富的程序员,也需要仔仔细细的读题,才能理解清楚。
其中这串拗口的指令「l和l'在不能被3整除的索引处完全相同,在能被3整除的索引处的值,等于l中对应索引的值」意味着需要构建一个子集。
这里,程序员很容易做错,但模型不仅理解了题目,而且还给出了正确的代码。
问题描述:这个函数接收一个列表l,返回一个列表l',满足以下条件:l'与l在不能被3整除的索引处完全相同,而在能被3整除的索引处的值等于l中对应索引的值,但是排好序。

结果显示,在HumanEval评测集上,带SC的源2.0的准确率为77.4%,与源2.0的基本测试相比,性能提高了10.3%。
源2.0的详细提示示例如下——

在浪潮信息看来,基础大模型犹如大模型产业的地基,地基的深度和强度,决定了大厦的高度。
依托基础大模型,可以从垂直场景应用有针对性地切入,从而落地行业。
从长远来看,这是我们走向AGI的必经之路。
而浪潮信息选择开源千亿级模型,也有着更高瞻远瞩的用意。
人们都说,2023年开源社区的荣光应当属于Meta。
今年2月,Meta打造的Llama席卷了整个开源研究领域,掀起了各种大模型爆发新潮——「羊驼家族」就此诞生了。

包括Vicuna、Alpaca、Dolly、RedPajama、Faclon等各种衍生模型泉涌而出。
紧接着7月,升级版的Llama 2面世,再到8月,Code Llama的开源,全都成为点燃生成式AI燎原大势的星星之火。
就在前段时间,Meta公布了当前Llama的生态现状,只能用两个字「震惊」加以形容。

在世界最大开源社区平台Hugging Face上,Llama模型的下载量超过3000万次。其中,仅在过去30天(9月份)内就超过了1000万次。
另外,发布在Hugging Face的Llama版微调模型,已经多达7000+个。
显而易见,Meta开源对整个大模型领域的研究产生了重大的影响,并为未来生成式AI奠定了坚实的开源基础。
一直站在「开源派」阵列的图灵三巨头之一LeCun曾在AI Native大会上称,「我认为开放是必然之路。因为大模型将成为社会人人依赖的基础设施,所以必须是开放的」。
在浪潮信息看来,「源2.0」模型的开源,同样希望能够为中国大模型生态体系的繁荣壮大,增添重要的一笔。
比如,更加轻量的20亿参数模型,不仅具有出色的能力而且还有更小的内存和计算开销,对于终端用户来说便是不错的选择。
众人拾柴火焰高,为了促进生态的繁荣,浪潮信息一方面以优秀的开源模型性能汇聚算力、算法、数据、人才、产业,另一方面以技术创新反哺大模型数据、工具、应用的迭代升级,可谓是目光深远。

最初,在GPT-4刚刚发布时,可谓是「万人空巷」。
而它之所以能够如此炸裂,是因为在底层智力方面的提升,不仅完全吊打了一众中小模型,甚至直接拿到行业应用中也是如此。
近日,随着OpenAI定制GPT能力的开放,全球在短短几天内诞生了数千款应用,几乎每一分钟就会产生一个新的GPT。
这恰好印证了Sam Altman在首届开发者大会上所说,「我们正在孕育新物种,它们正在迅速增值」。
再加上新版GPT-4 Turbo上下文本处理上限更高,足足有128k,价格更加便宜,各种时代应用的爆款都被激发出来了。
举个栗子,一位开发者仅在40秒内,就做出了一个Hacker News的克隆版。

看得出,正是基础大模型拥有强大的智力和泛化能力,提供了扎实的底座,才能催生各种应用实现落地。
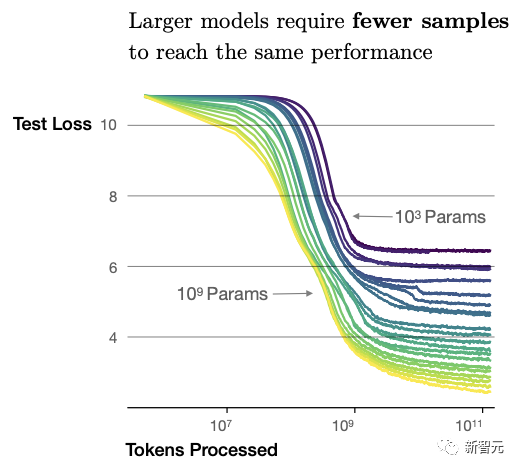
另一方面,根据谷歌、斯坦福等发表的论文「Emergent Abilities of Large Language Models」,680亿参数可以被认为是大模型是否具备涌现能力的一个门槛,如果参数超过1000亿的话效果更好。

举例来说,在上下文学习中,对于3位数的加/减法任务,最小只需要130亿参数就会出现涌现能力。而对于多义词判断复杂的任务,至少需要5400亿参数。
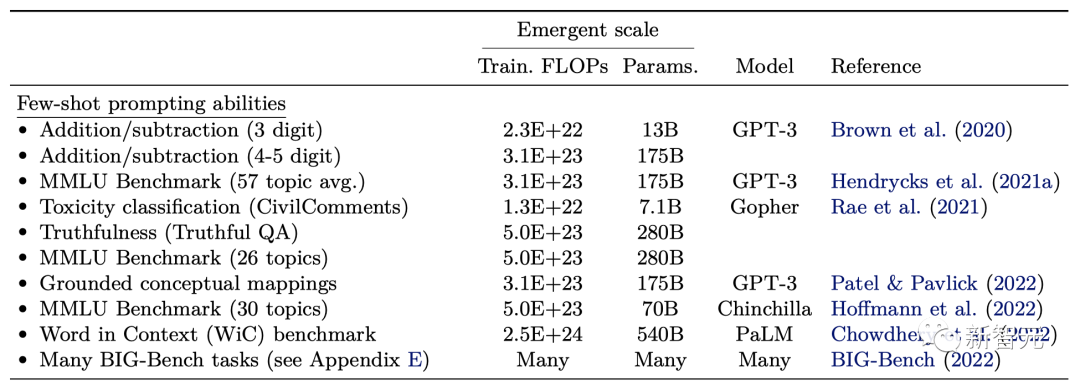
由上可见,大模型参数越大,涌现能力也就更稳定,更出色。
但是,真正炼出一个媲美GPT-4的大模型,还需要在算法和数据上更多的创新。
OpenAI团队在「Scaling Laws for Neural Language Models」文中曾指出,模型的智力水平能力取决于其投入的数据、参数量及算力,也就是业界常提的「Scaling Law」。
模型参数量越大、投入的训练数据越多,模型泛化能力则越强。
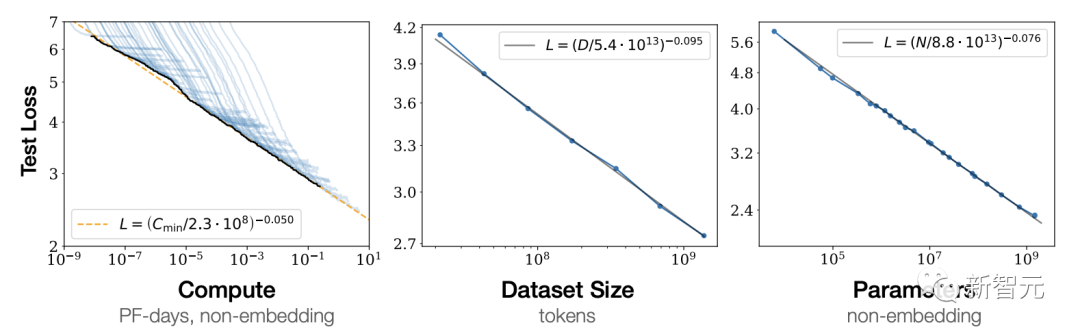
但我们当前所面临的问题是,高质量数据逐渐面临枯竭。
大模型训练几乎用尽了互联网高质量数据,并且所需的数据集的增速,远大于高质量数据生成的速度。

连OpenAI也陷入数据荒,公开求合作,寻求训练模型的各类高质量数据
与此同时,巨量参数模型对算力大量吞噬,愈加凸显了未来大模型算力之殇的困境,它并不可被视为无所顾忌的资源。
那么,我们如何用同等算力,更高质量的数据,来换取更低的loss rate,把效率发挥极致,让算力更有效地匹配智能涌现?
众所周知,想要提升模型性能,充分的训练也必不可少。
DeepMind的研究显示,如果想把一个大模型训练充分,需要把每个参数量训练20个token。相比之下,GPT-3的每个参数只训练了1-2个token。
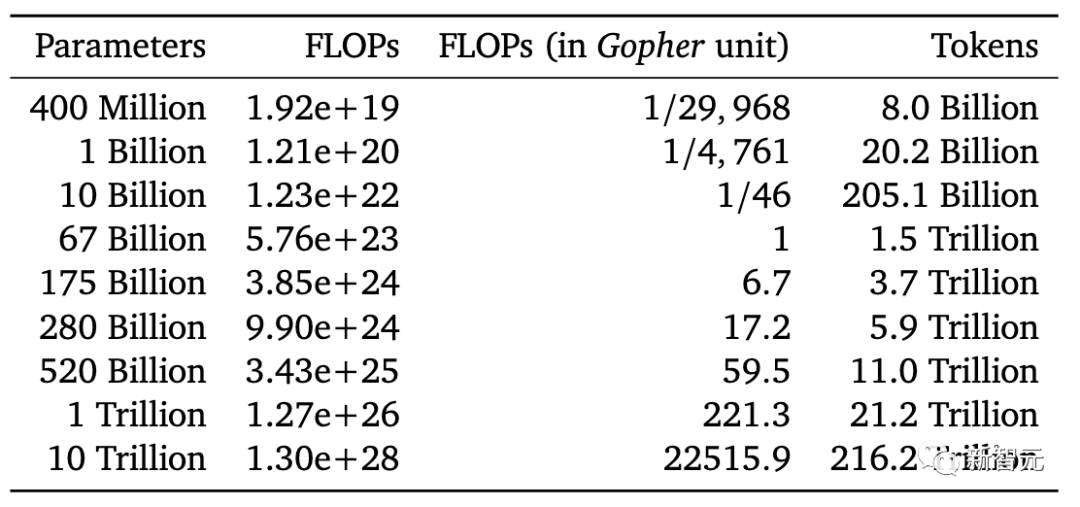
基于这个思路,DeepMind为新的Chinchilla模型准备了差不多4.7倍于Gopher的数据量(1.4T vs 0.3T),但是将参数量降低到了原先四分之一。
其结果就是,在相当一部分任务的表现上,700亿参数Chinchilla效果都要优于2800亿参数的Gopher。
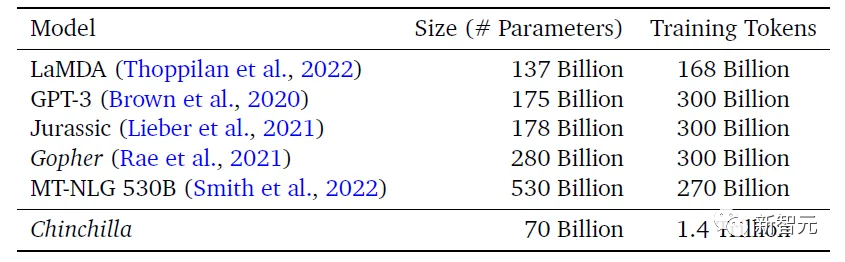
无独有偶,采用更大数据量来训练的LLaMA,凭借着小得多的参数规模击败了GPT-3。
换言之,当前的千亿规模大模型,应该用多10倍的数据进行训练,才能达到比较好的水平。
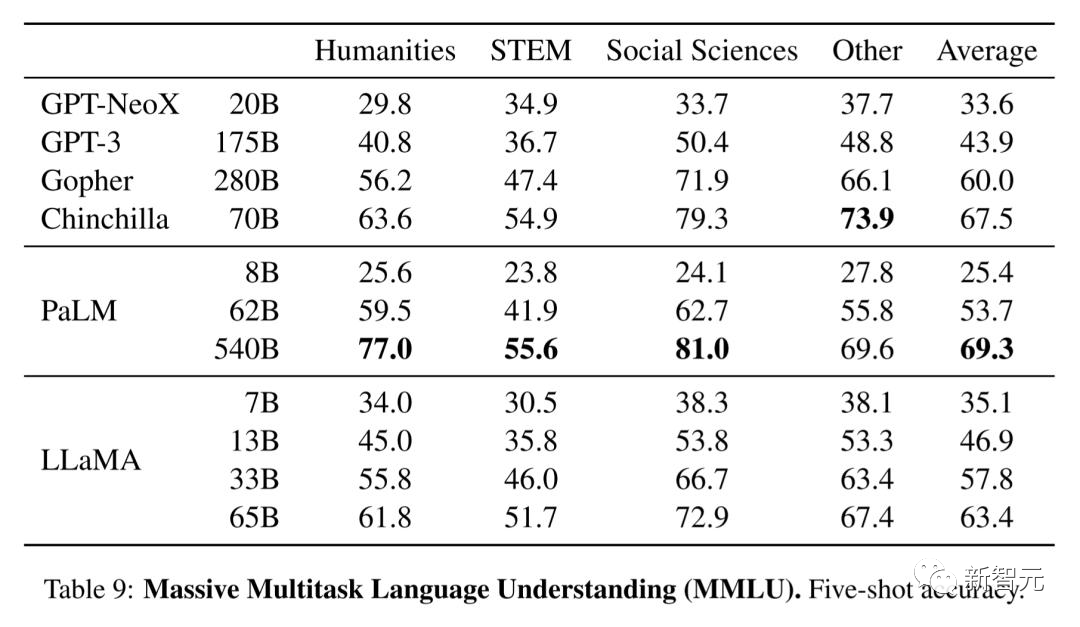
因此,为了提升模型的性能,我们不仅需要更高质量,还需要更大规模的训练数据。
还是以GPT-3为例,它所使用的高质量数据仅占其数据集的17.8%,但其在模型训练中的权重却占到了40%。
然而,现在的问题在于,大模型训练所需要的数据集的增速,要远远大于高质量数据生成的速度。此外,对于具体的行业来说,其自身还普遍存在着高质量数据匮乏的问题,「特别是面向中文语境下的高质量数据集」。
面对高质量数据的枯竭,以及算力资源的限制,浪潮信息给出了它的思考与答案,立足训练数据来源、数据增强和合成方法方面进行全面创新。
相比于源1.0,源2.0减少了网页数据,并增加了百科、书籍、期刊等来源的数据 ,从而增强了模型数理逻辑能力。
其中,团队除了从互联网上获取数据之外,还引入了一部分独特的数据,尤其是在构建数学数据和代码数据的时候。
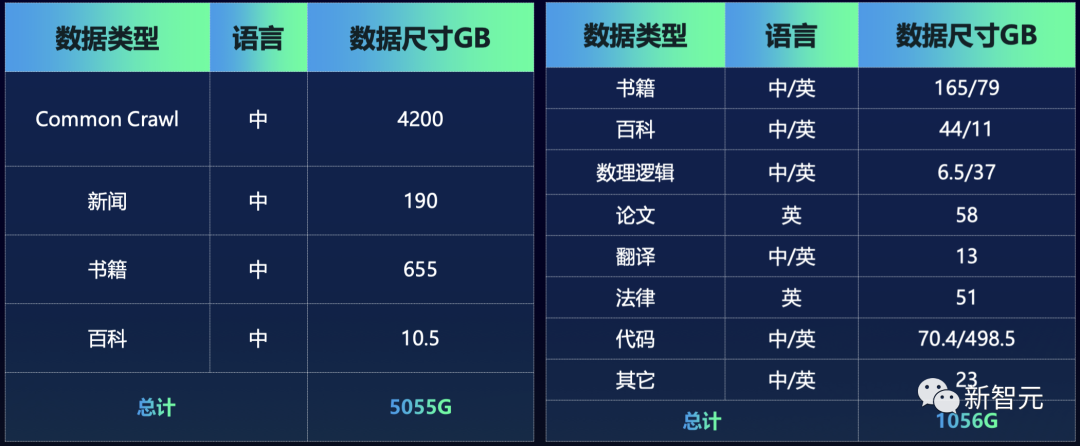
左:源1.0;右:源2.0
而第二种构建高质量数据的方式,则是用大模型生成。
为此,浪潮信息提出了基于主题词或Q&A问答对自动生成编程题目和答案的数据集生成流程,大幅提高了数据集问题的多样性。同时,辅以基于单元测试的数据清洗方法,让高质量数据集的获取更加高效,进一步提高训练效率。
具体来说,在构建高质量的数学和代码数据时,团队先随机选取一批种子数据,然后对其进行扩充,让大模型生成一批合适的问题,再把它们送到模型里,从而产生合适的答案。
这种方法不仅被用在了源2.0的预训练中,而且还可用于模型的微调。
在算法方面,经典的自注意力机制在学习整个输入序列中token之间的相互关系的时候,并不会假设输入的词之间存在某种先验的依赖关系,比如局部关系。
但实际上,在自然语言中,相邻词之间的关联往往较强。
比如把「我想吃中国菜」这样一个句子输入模型,首先就会进行分词——我/想/吃/中国/菜。
很显然,在这句话中,「中国」和「菜」是有更强的关系和局部依赖性的,这种局部依赖性,就是自然语言中一种较强的特性。

那么,如果能把这种局部依赖性引入到自注意力机制中,理论上就可以提升模型对自然语言的建模能力,进而提升精度。
为了更好考虑自然语言输入的局部依赖性,团队提出了一种全新的算法——局部注意力过滤增强机制(LFA)。
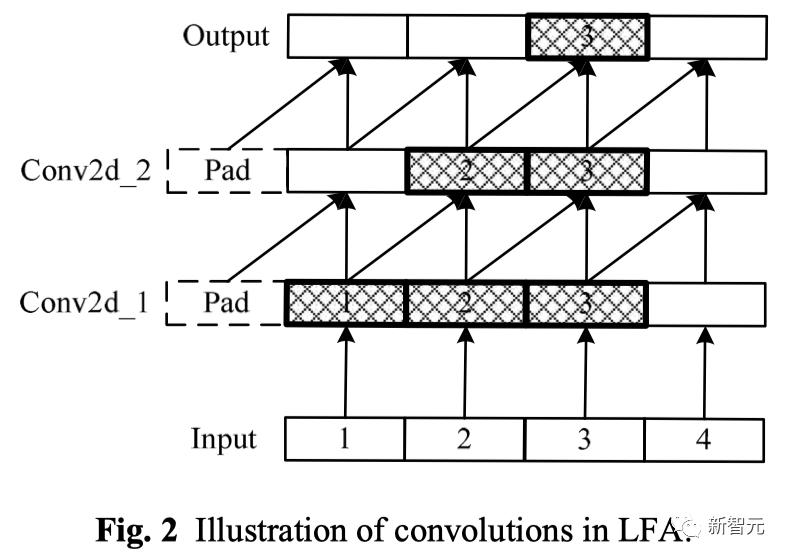
从图1中可以看到,LFA对局部性的引入,是通过两层嵌套的1维卷积操作实现的。
为了确保未来词的信息不会泄露到当前词中,卷积计算中采用了单边操作,卷积核的尺寸是2,在卷积之后应用了RMSNorm,一方面提升了精度,另一方面起到稳定计算的作用。
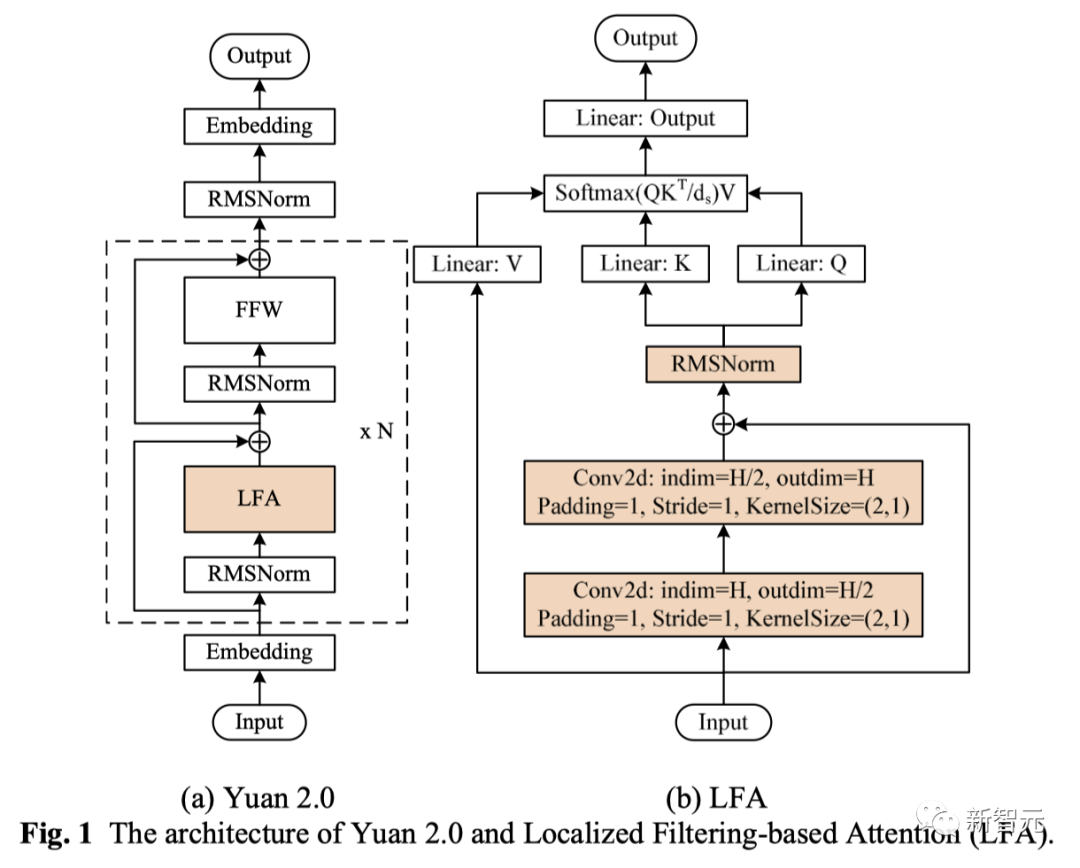
图2是LFA中的卷积操作,可以看到,位置3处的词通过两层卷积后,将会包含位置1与位置2处词的信息。
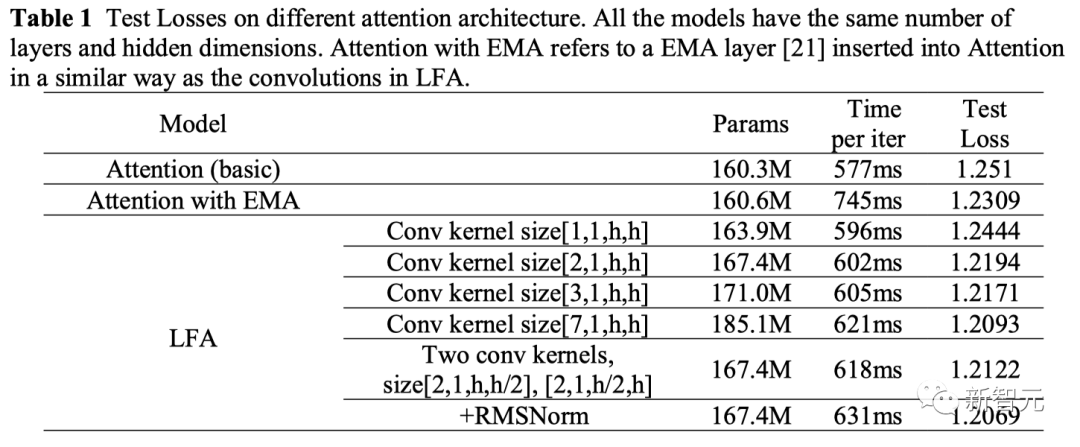
在采用卷积之前,团队首先尝试了建模时间序列局部性关系时最常用的EMA(指数移动平均)算法,并将EMA添加至自注意力的query与key张量计算之前的位置。
从表1中可以看到,采用EMA改进后的注意力模型,确实降低了测试集上的loss值,并获得了更高的精度。但同时也大幅增加了训练耗时,而这对于大模型的训练来说是难以接受的。
随后,团队将全局的EMA改为局部操作,并试验了不同的卷积核的尺寸。其中,当卷积核尺寸为7时,可以达到最优的精度,但依然极大地增加了参数量和内存开销。
为了在保持精度的同时降低参数量,团队采用了2层卷积堆叠的形式,并通过在卷积之后添加RMSNorm的手段,进一步提升了精度,并有效降低了参数量。
消融实验的结果显示,相比传统注意力结构,LFA模型精度提高了3.53%。
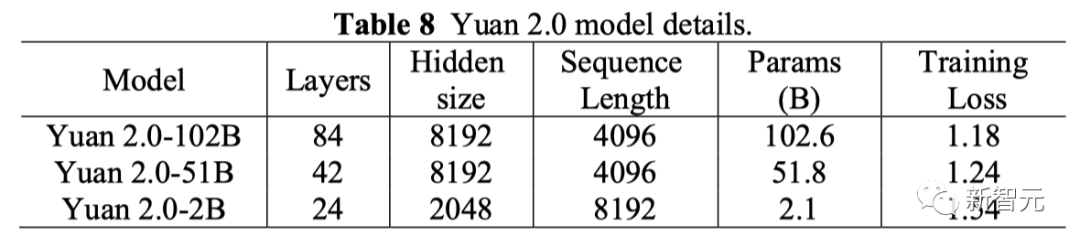
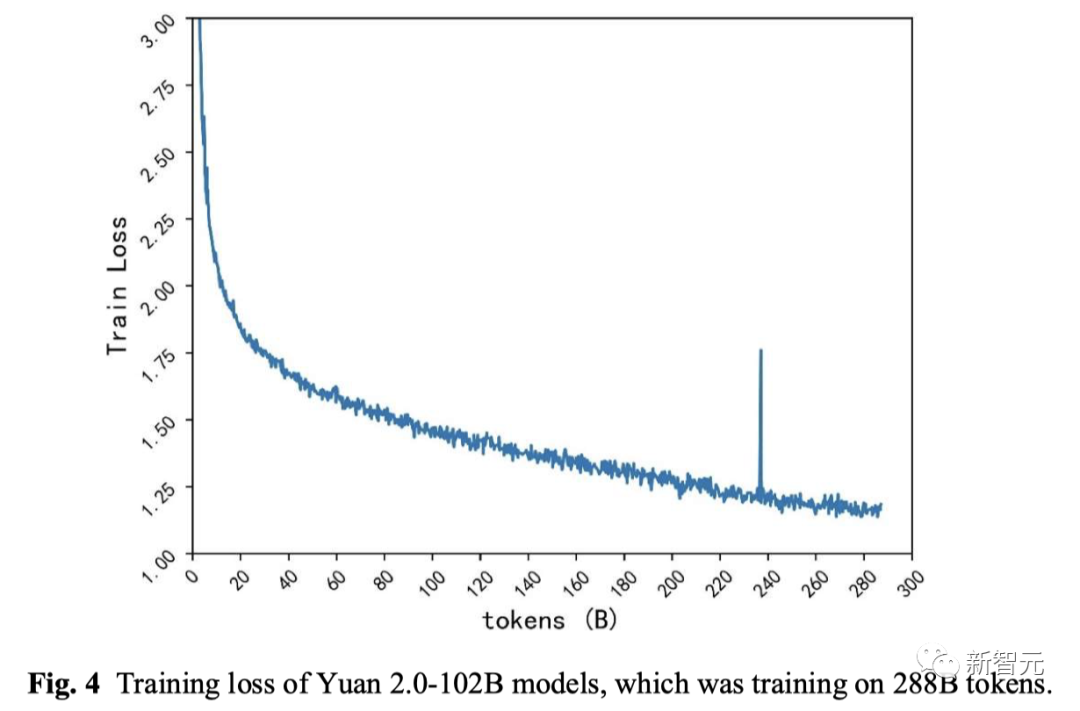
在最终的模型训练上,基于LFA算法的源2.0-102B模型,训练288B token的train loss为1.18 。
相比之下,源1.0 245B模型训练180B token的train loss为1.64。
也就是说,从源1.0到源2.0,train loss降低了28%。
然而,由于资源的限制,在参数和数据两者不可兼得时,又应该如何进行取舍呢?
OpenAI的研究结论认为,与增加数据量相比,先增大模型参数量,受益则会更好——
比如,用1000亿的模型训练2000亿的token和2000亿模型训练1000亿的token,后者的模型性能会更高。
但无论是提高模型参数量还是提升数据规模,算力依旧是支撑大模型智力水平提升的核心驱动力——需要用「足够大」的算力,去支撑起「足够精准」模型泛化能力。
因此,一定程度上也可以说——有多少算力投入,就有多少智能涌现。但当下,我们需要解决的是,如何把算力更有效地匹配智能涌现。
所以,应该如何更好地利用算力呢?
为了在各类计算设备上都达到好的性能,团队提出了一种分布式训练方法。
早在源1.0中,就采用了张量并行+流水线并行+数据并行的3D并行策略。
而源2.0在此基础上更进一步地提出了非均匀流水并行+优化器参数并行(ZeRO)+ 数据并行 + Loss计算分块的方法。相比于经典的3D并行方法,它对带宽的需求更小,同时还能获得高性能。
举个坚果,在均匀流水并行的时候,24层模型分到8个计算设备上,每个设备上会平均分到3层。
从下图中可以看到,这时内存在第一阶段就已经达到了GPU的上限。由此,模型的训练便需要更多设备、更长的流水并行线路,从而导致更低的算力效率。
而采用非均匀流水并行的方法,就可以根据模型每层对于内存的需求,结合内存的容量进行均衡分配,这样就能在有限的算力资源里把模型训起来了。

不过,流水线并行策略下,整个阶段依然是比较长的。
针对这个问题,团队把流水并行和优化器参数并行结合了起来。
采用优化器参数并行,就会进一步降低各个节点上内存的开销。内存空间省下来了,就可以合并成更大的流水线,减少节点使用数量,节省算力资源。

为了对两种分布式训练方法有定量分析,团队还特意构建了两个性能模型,测试证明,数据误差非常低。
用这两个性能模型对于节点类芯片之间的P2P互联带宽进行了模拟。
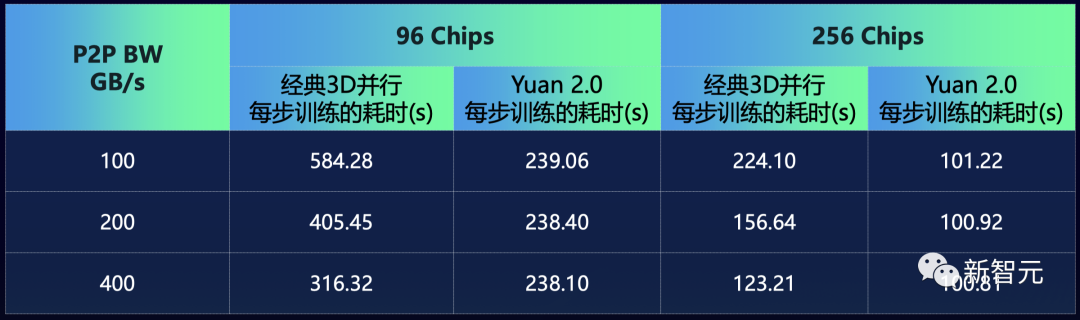
如果用经典的3D并行,当芯片P2P带宽从400GB/s降低至100GB/s,性能就会降85%左右。
但如果用源2.0的分布式训练算法,性能几乎不随带宽变化,仅降低0.4%。哪怕AI芯片之间的P2P带宽很低,依然能保持几乎不变的性能开销,这就大幅降低了大模型训练对P2P带宽之间的需求。
无论是96芯片,还是256芯片上,效果都类似。
大模型下半场,从来都不缺少在AIGC领域中布局的重要玩家。
据不完全统计,中国大模型赛道上,已经诞生了188+个模型,可见大模型暴涨速度如此之快。
作为算力龙头玩家,浪潮信息不仅在大模型领域,更是在AI算力基础设施方面深耕多年。
正是基于产品研发、客户需求、应用落地等因素,浪潮信息AI团队在算力系统的性能调校和优化方面积累了丰富的经验。
这些经验逐渐沉淀在产品AI服务器上,多年来在MLPerf的训练和推理取得了优异的成绩。
得益于自身实践,随着大模型的井喷式爆发,浪潮信息在8月正式发布了大模型智算软件栈 OGAI「元脑生智」(Open GenAI Infra)。
秉承全栈全流程、算力充分释放、实战验证提炼的设计原则,为大模型研发与应用创新全力打造高效生产力,加速生成式AI产业创新步伐。

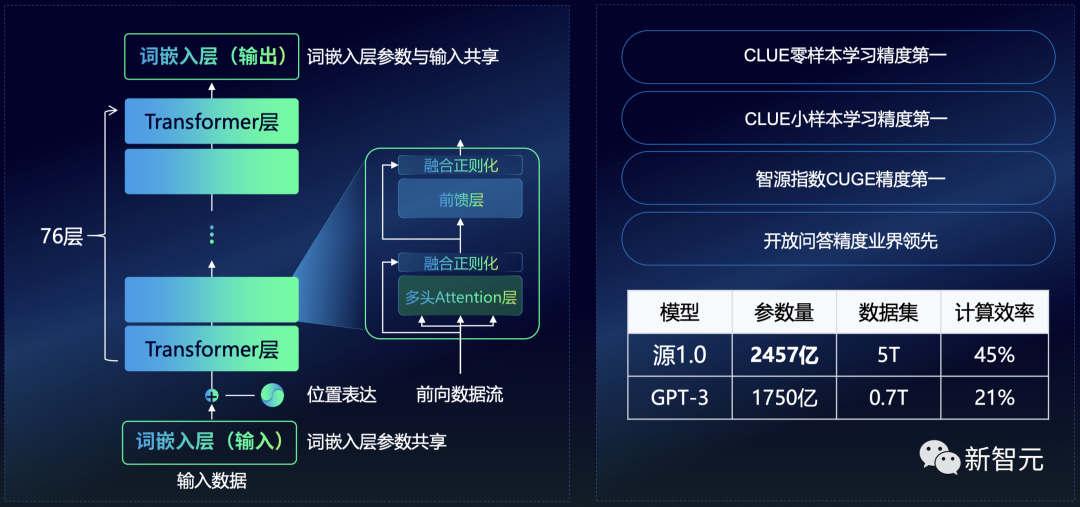
在大模型领域的布局,早在2021年,浪潮信息率先推出了中文领域巨量AI模型「源1.0」,有2457亿参数,成功落地南京智算中心。
源1.0有着出色的中文理解与创作能力,并在许多榜单中霸榜,可与GPT-3相媲美。
「源1.0」研发过程中,浪潮信息AI团队完成了5TB高质量中文数据集的清洗工作。
最重要的是,团队逐步建立了完整流程和工具链,从公开数据爬取,到数据清洗、格式转化、数据质量评估。
「源1.0」开放后,基于「源」大模型的各种应用创新迸发,AI剧本杀,临小助数字社工、AI反诈等在业界引起了很大的反响。

与此同时,基于「源」大模型的研发经验,2022年以来,浪潮信息协助多个客户,将大模型训练GPU峰值效率从30%左右提升到50%,大大加速模型训练过程。
浪潮信息还将「源」大模型的智能力与To B领域复杂的服务场景进行深度融合,并构建首个「专家级数据中心智能客服大脑」,荣获哈佛商业评论鼎革奖。
基于AI算力平台,OGAI智算软件栈等积累,千亿级大模型「源2.0」的开源,将全面助力大模型领域开发者、创业者,激发AIGC时代创新。
浪潮信息高级副总裁刘军表示,「希望通过全面开源千亿级参数源2.0大模型,为业界分享浪潮信息在探索基础大模型领域的实践和成果,降低大模型创新的门槛,为大模型产业的发展提供更开放、更高效、更智能的基础大模型基座,促进AIGC产业生态的繁荣与可持续发展。」
正如Meta的模型Llama开源后,孵化出大量的开发者应用一样。在国内,开源的基础大模型也将成为推动AI创新和落地的重要手段。
大模型开源开放能够让算法数据等信息共享,打破技术孤岛,让更多开发者一起共创。
参考资料:
https://github.com/IEIT-Yuan/Yuan-2.0
文章来自于微信公众号 “新智元”,作者 “新智元编辑部”



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
