# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
卖铲子相比蜂拥去淘金,永远是更好的选择。在大模型风靡全球、蕴含极大商业价值的今天,「先进铲子」之间的竞赛,正趋向白热化。
如今的AI计算加速芯片眼花缭乱。GPU、NPU、TPU、VPU,新概念层出不穷,手机 SoC、PC 处理器、车端智驾和座舱芯片、高性能 AI 计算大规模服务器集群,AI 计算加速几乎无处不在。
然而万变不离其宗,按计算的通用性,AI 计算大概可以分为 CPU、GPU、FPGA、和 ASIC(NPU/TPU),按使用场景,可以分为训练芯片、云端推理芯片和边缘侧的推理芯片。
我们知道 CPU 遵循传统的存储-控制-运算的冯·诺依曼架构,核心是存储程序/数据,串行顺序执行。CPU 的架构需要大量的空间去放置高速缓存单元和控制单元,现代 CPU 在分支预测和乱序执行上的要求更高,不断新增的长指令集更进一步强化了复杂的逻辑控制单元,相比之下 CPU 计算单元只占据了很小的一部分。大规模并行计算方面,CPU 天然的效率很低,更适合处理复杂的逻辑控制和通用计算。
与 CPU 相比,GPU 80% 以上的晶体管面积都是计算核心,即 GPU 拥有非常多的用于数据并行处理的计算单元,可以高效运行物理计算、比特币挖矿算法等。GPU 还可以为两种,一种是主要搞图形渲染的,我们熟悉的 GPU(游戏)显卡;另一种是主要搞计算的,叫做 GPGPU,也叫通用计算图形处理器(科学计算),A100、H100 就是代表。GPGPU 芯片去掉了针对图形渲染的专用加速硬件单元,但保留了 SIMT(单指令多线程)架构和通用计算单元,计算的通用性更强,可以适用于多种算法,在很多前沿科学计算领域,GPGPU 是最佳选择。
FPGA 是一种半定制芯片,作为灵活可编程的硬件平台,同时具有较高的计算性能和可定制性,芯片硬件模块、电路设计更为灵活,但缺点是专用 AI 计算的效能比 ASIC 差一些。
ASIC 是一种为专门目的而设计的芯片(全定制),根据特定算法定制的芯片架构,算力强大,但专业性强缩减了其通用性,算法一旦改变,计算能力会大幅下降,需要重新定制。我们知道的 NPU、TPU 就是这种架构,都属于 ASIC 定制芯片。
CPU、GPU、NPU 架构区别如下图,CPU 最为均衡,可以处理多种类型的任务,各种组件比例适中;GPU 则减少了控制逻辑的存在但大量增加了 ALU 计算单元,提供给我们以高计算并行度;而 NPU 则是拥有大量 AI Core,这可以让我们高效完成针对性的 AI 计算任务。
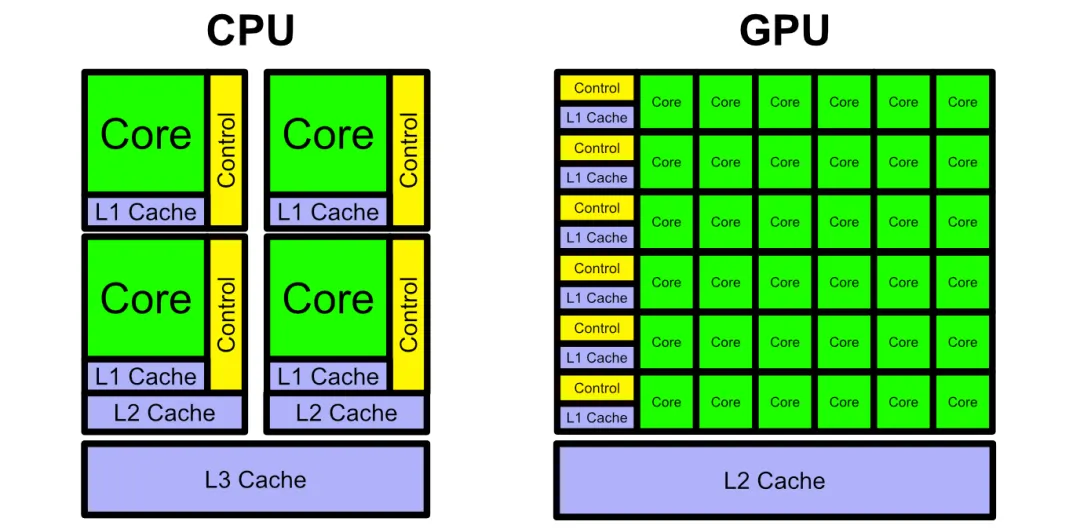
GPU 相比 CPU 有更多的并行计算核心
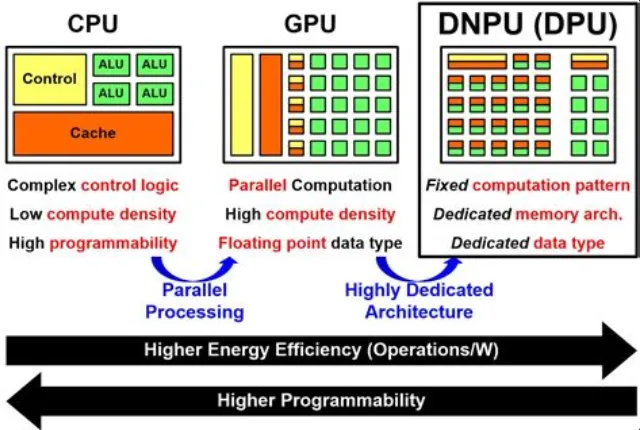
NPU 相比 CPU 和 GPU,有大量专门进行大矩阵乘法和卷积运算的 AI Core
ASIC 思想下的 AI 芯片作为一种专用处理器,通过在硬件层面优化深度学习算法所需的大矩阵乘法、张量运算、卷积运算等关键运算,可以显著加速 AI 应用的执行速度,降低功耗。与在通用 CPU 上用软件模拟这些运算相比,AI 芯片能带来数量级的性能提升。因此,AI 芯片已成为如今大模型训练和推理的关键载体。
AI 专用处理器的发展最早可以追溯到 2015 年。2015 年 6 月,谷歌 I/O 开发者大会上推出第一代神经网络计算专用芯片 TPU,专门用于加速 TensorFlow 框架下的机器学习任务。区别于 GPU,谷歌 TPU 是一种 ASIC 芯片方案,一般来说 ASIC 芯片开发时间长、研发成本高,服务于专用计算,实现的下游任务较为固定和狭窄。此后,谷歌又陆续推出了多个 TPU 系列产品,不断优化其架构和性能。
尽管 AI 芯片的种类、实现的任务和部署形态多样且复杂,但其功能最终可以归结为两种:训练和推理。
在训练阶段,AI 芯片需要支持大规模的数据处理和复杂的模型训练。这需要芯片具有强大的并行计算能力、高带宽的存储器访问以及灵活的数据传输能力。
NVIDIA 最新的 H100 GPU、华为昇腾 Ascend NPU、谷歌 TPU 等专门为 AI 训练设计的芯片,拥有超强的计算能力、超大显存和极高的带宽,能够处理海量数据,特别适合训练类似 GPT 等大语言模型。
在推理阶段,AI 芯片需要在功耗、成本和实时性等方面进行优化,以满足不同应用场景的需求。云端推理通常对性能和吞吐量要求较高,因此需要使用高性能的 AI 芯片,边缘和端侧推理对功耗和成本更加敏感,因此需要使用低功耗、低成本的 AI 芯片,如专门为桌面、移动和嵌入式设备设计的 NPU等。
英特尔最新的酷睿 Ultra 旗舰处理器,基于 x86 平台的异构AI计算,集成的 GPU 和 NPU 性能越来越高。高通和 MediaTek 最新的高端移动处理器,针对不同任务的 AI 计算加速,整个 SoC 微架构上,NPU 的重要性也越来越突出。

相较于训练芯片在云端成为某种“基础设施”,端侧的推理芯片则站在了 AI 应用的前沿。将训练好的模型为现实世界提供智能服务,特别是目前已经成为“个人信息Hub”的手机终端,某种意义上已经成为了普通人新生长出来的器官,当大模型与手机融合,不依赖网络和云端算力就能让手机具备大模型能力,AI Phone 的商业想象力巨大。
大模型推理正在向手机、PC、智能汽车等终端渗透。但是,在终端部署 AI 大模型时,仍面临着多模态模型压缩、存储与计算瓶颈、数据传输带宽限制、模型 always-on 设备功耗和发热、软硬件联合调优等多重挑战。
特别是在手机端,芯片必须在保证高性能的同时,尽量降低功耗,这要求芯片设计在硬件架构和算法加速技术上进行优化,以提高计算效率并减少能源消耗。
以高通最新的骁龙旗舰芯片为例,“为了实现更快的 AI 推理性能,高通提升了所有(AI计算)加速器内核的吞吐量,还为标量和向量加速器增加了更多内核,满足增长的生成式AI运算需求,尤其是面向大语言模型(LLM)和大视觉模型(LVM)用例,以在处理过程中支持更长的上下文。至于大众关心的能耗,高通这次将每瓦特性能提高 45%。终端更加高效,不需要大量消耗电池续航。”
根据高通的官方描述:
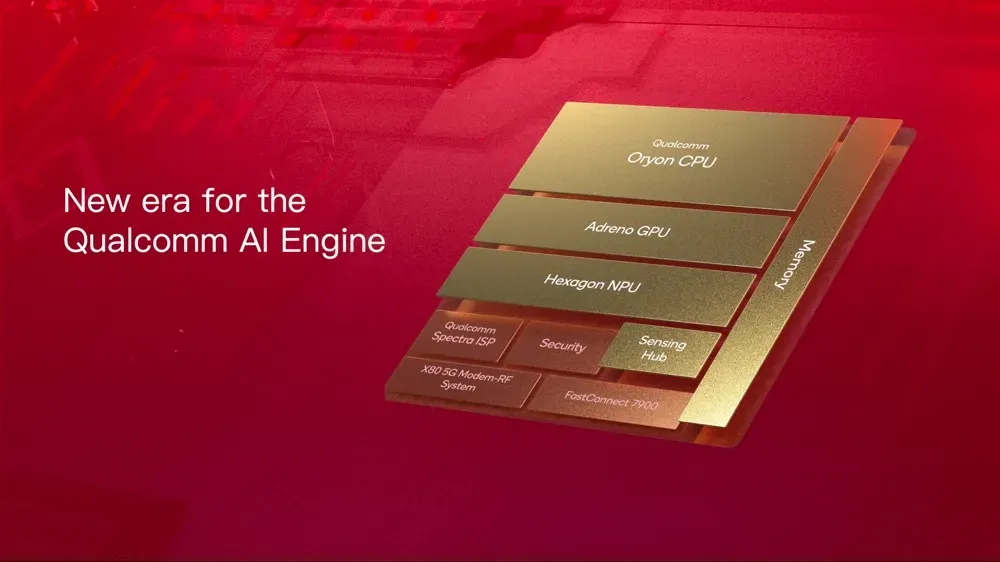
高通最新的旗舰移动芯片,骁龙 8 至尊版首次采用了一系列领先技术,包括第二代定制的高通 Oryon CPU、全新切片架构的高通 Adreno GPU 和增强的高通Hexagon NPU,能够为用户带来终端体验的全面革新。
作为高通迄今为止最快的CPU,Oryon CPU 拥有 2 个主频高达 4.32GHz 的超级内核和 6 个主频 3.53GHz 的性能内核。其单核性能和多核性能相比前代均提升了 45%,浏览器性能提升了 62%,可为大量的多任务处理、飞速网页浏览和疾速游戏响应体验提供强大的性能和能效支持。同时,骁龙8至尊版还支持高达 10.7Gbps 速率的 LPDDR5X 内存,为用户带来更为丰富的终端侧 AI 使用体验。
基于全新的高通 Hexagon NPU,骁龙 8 至尊版首次支持终端侧个性化多模态 AI 助手,能够赋能规模更大且更加复杂的多模态生成式 AI 用例在终端侧高效运行。在处理器上,高通 Hexagon NPU 增加了额外内核,拥有 6 核向量处理器和 8 核标量处理器,能够进一步满足生成式 AI 运算不断增长的需求。
得益于在软件上的不断优化、Hexagon NPU 新增的处理器核心以及多模态模型,骁龙 8 至尊版能实现更快的 AI 处理速度。其 AI 性能提升了 45%,每瓦特性能提升 45%,并支持 70+ tokens/sec 的输入,用户可以上传更大的文档、音频和图像,让手机在处理复杂任务时能够更加游刃有余。

有了全新 Hexagon NPU 的支持,无论是在拍照时的智能识别与优化,还是游戏中的实时渲染与计算,骁龙 8 至尊版都能为用户提供强大的 AI 引擎支持,帮助用户能够随时随地开启灵感世界,创造无限可能。
在影像处理能力上,通过 AI-ISP 和 Hexagon NPU 的深度融合,骁龙 8 至尊版可带来突破性的拍摄体验,让用户在拍照时得到更多的AI加持,其支持 4.3GP/s 像素处理能力,数据吞吐量相比上代提升了 33%,能够支持三个 4800 万像素图像传感器同时进行 30fps 视频拍摄。
骁龙 8 至尊版支持无限语义分割功能,可以对图像进行超过 250 层语义识别和分割,针对性优化图像中的每个细节。在无限语义分割基础上,骁龙 8 至尊版的实时皮肤和天空算法可以利用 Hexagon NPU 来识别光线条件并进行修图,即使在光线条件不足的情况下,也能拍出具有自然效果的皮肤和天空色调。

基于Hexagon NPU,骁龙8至尊版还支持实时 AI 补光技术,让用户即使在近乎黑暗的环境下,也能生动记录 4K 60fps 的视频。在视频通话或者直播时遇到背光情况,实时 AI 补光技术仿佛增加了一个虚拟的可移动光源,让用户时刻都能展现自己美好的一面。
在强大算力的支持下,骁龙 8 至尊版还支持视频魔法擦除功能,用户可以直接在视频中选择需要擦除的对象将其消除,而无需将视频上传到云端。此外,骁龙 8 至尊版还拥有 AI 宠物拍摄套件,能够清晰记录萌宠们“放飞自我”的调皮时刻,无论是快速奔跑还是嬉戏打闹,都能被精准捕捉。
在高通发布骁龙 8 之前,多年蝉联手机移动芯片市场份额第一的 MediaTek,也在最新的天玑 9400 旗舰芯集成 MediaTek 第八代 AI 处理器 NPU 890,在其支持下,天玑 9400 支持时域张量(Temporal Tensor)硬件加速技术、端侧高画质视频生成技术,赋能端侧运行 Stable Diffusion 的性能提升了 2 倍,不仅能够实现高分辨率生图,更支持端侧动图和视频生成,实现更多新玩法。
根据 MediaTek 官方描述:
天玑 9400 拥有强悍的端侧多模态 AI 运算性能,处理能力高达 50 tokens/秒;运行各种主流大模型,平均功耗可节省 35%,为手机终端用户带来更智慧、更省电的 AI 智能体互动。

随着大语言模型能力的提升,智能体多轮对话与复杂场景的判断需求越来越重要。天玑 9400 已能支持到至高 32K tokens 的文本长度,是上一代的 8 倍!

为了强化端侧模型的数据安全和个人隐私作用,MediaTek 天玑 9400 支持端侧 LoRA 训练,不用传资料上云,每位用户在端侧就可以安心享受实时的个性化训练与生成,还可用个人照片创建各种画风的数字形象,并更换各种姿势和背景,让隐私更安全。
Prefill 阶段首 Token 延迟,以及 Decoding 阶段 Token 生成速率。
无论云端模型还是端侧大模型,本质是“一堆参数”。手机终端执行大模型推理的过程:用户输入文本(提示词,也即常说的 Prompt)编码转化为向量,内存加载参数,激活参数执行 AI 计算,输出向量解码。
大模型推理的基本流程,用户提供一个 prompt(提示词),手机运行的推理框架根据输入的提示词生成回答。推理过程通常分为两个阶段:prefill 阶段和 decoding 阶段。在 Prefill 阶段,内存加载模型参数,推理框架接收用户的提示词输入,然后执行模型参数计算,直到输出第一个 token。这个阶段只运行一次,耗时较长。
接下来是 Decoding 阶段,这个阶段是一个自回归的过程,每次生成一个 token。具体来说,它会将上一时刻的输出 token 作为当前时刻的输入,然后计算下一时刻的 token。如果用户的输出数据很长,这个阶段就会运行很多次。Decoding 阶段的 Token 吞吐率,即常说的推理速度 XXToken/sec。
如何评价不同品牌的AI Phone 的大模型运行性能的优劣?运行同样参数尺寸(比如3B)的端侧模型,模型的“知识密度”相同的情况下,Prefill 阶段的首 Token 延迟,以及 Decoding 阶段 Token 生成速率是两个最直观的指标,它直接反馈的模型运行在一款AI Phone是否流畅,用户体验感知最明显。
当然 AI Phone 运行模型时的内存占用压缩,量化精度损失,AI Phone 运行的多模态模型和文本基座模型本身的性能和功能,模型层的优劣影响也是决定性的。一个高效压缩、功能全面、性能强悍、跨算力平台兼容性好的端侧模型,还没有公认的最强者。
目前,AI Phone 算力芯片支持的推理框架,适配优化支持的模型种类和数量,正在肉眼可见的增长和繁荣。端侧模型运行在不同终端,针对不同 ASIC 芯片 NPU 的兼容,进行 AI 计算硬件加速和调度优化的空间还非常大,这是一个涉及终端厂商、芯片厂商、模型厂商三方的生态构建。谁能提前布局,不辞辛劳更多做幕后看不到的“有用功”,大模型时代它一定获得市场的“加速”。
文章来自于微信公众号“OpenBMB开源社区”,作者“杨青山”




【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
