# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

MME-Finance: A Multimodal Finance Benchmark for Expert-level Understanding and Reasoning
介绍:
https://hithink-research.github.io/MME-Finance/
代码:
https://github.com/HiThink-Research/MME-Finance
论文:
https://arxiv.org/abs/2411.03314
MME-Finance 是一个专为金融领域设计的多模态基准测试,由同花顺财经旗下的 HiThink 研究团队联合多家高校共同开发,旨在评估和提升多模态大型语言模型(MLLMs)在金融领域的专业理解和推理能力。
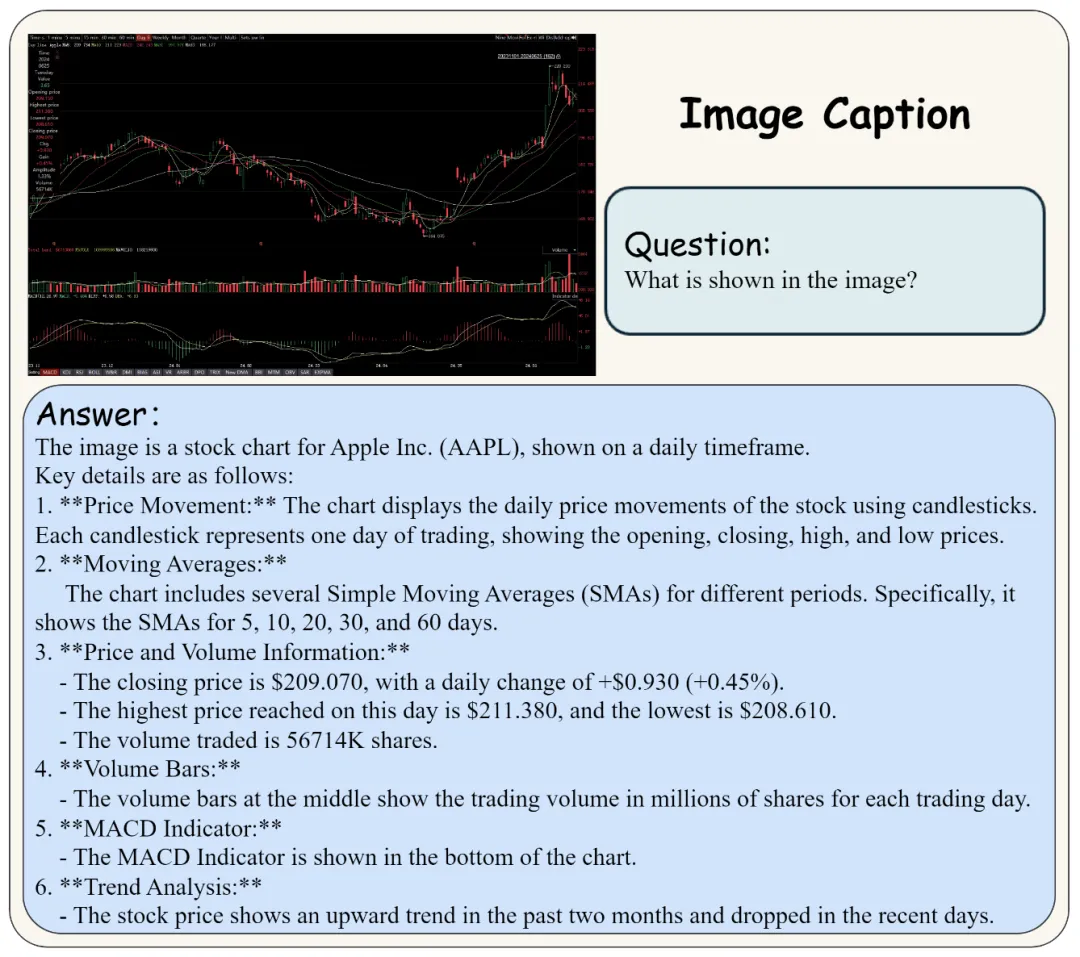
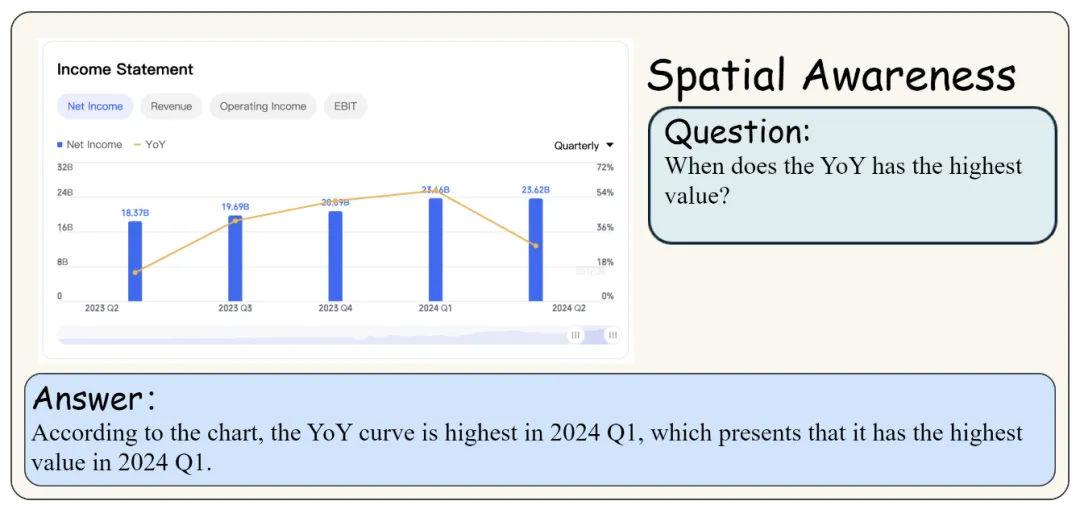
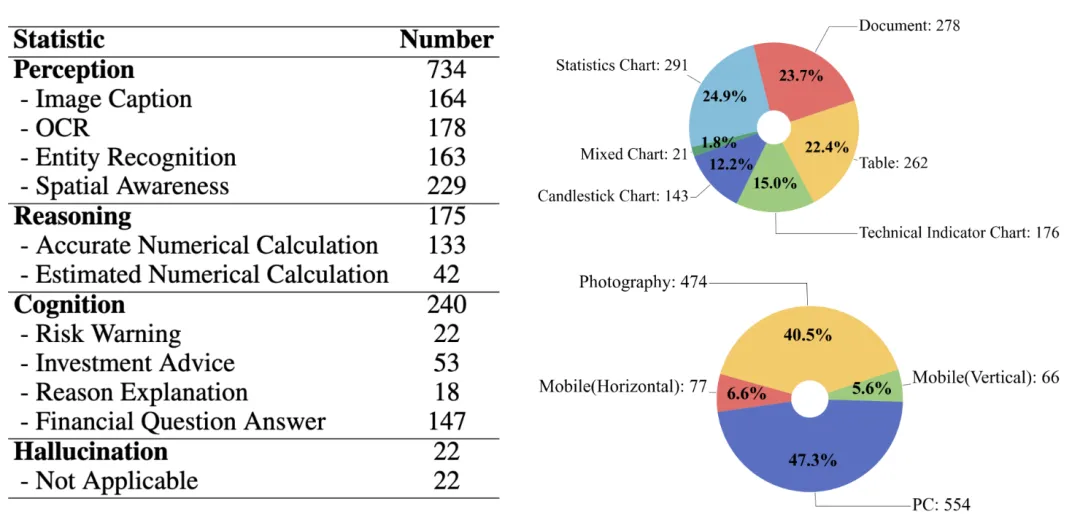
该基准测试具有双语特性,覆盖了金融图表、技术术语和专业知识,通过构建反映实际用户需求的图表和由金融行业专家提出的问答对,确保了测试的专业性和实用性。MME-Finance不仅包括了从基础视觉感知到复杂认知任务的多层次能力评估,还首次引入了视觉信息辅助的多模态评估过程,以提高评估的准确性。
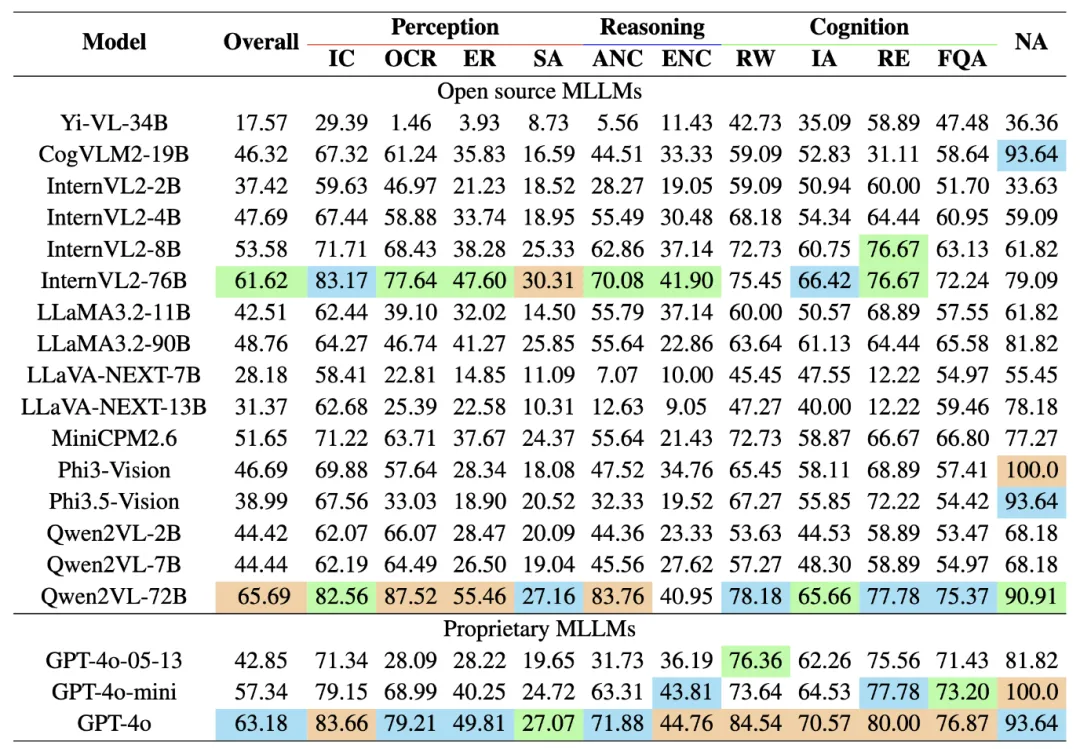
该研究的特点是其对金融领域独特性的深入考量,包括金融术语的复杂性和图表类型的多样性。通过对19个主流MLLMs的广泛评估,研究揭示了现有模型在金融任务上的性能不足,尤其是在理解和分析K线图、技术指标图等金融专业图表方面。此外,MME-Finance的评估方法也显示出与人类评估者高度一致性,为金融领域MLLMs的性能评估提供了可靠的参考。
MME-Finance 是一项针对金融领域多模态大型语言模型(MLLMs)的评估技术,其总体思路是通过构建一个包含丰富金融图表和专业知识的双语视觉问答(VQA)基准测试,来衡量和提升MLLMs在金融领域的专业理解和推理能力。该技术特别关注金融图表的独特性,如K线图和技术指标图,并结合实际应用场景中的视觉信息,以实现对MLLMs更全面和深入的评估。
MME-Finance 的构建和处理过程包括数据收集、问题生成、数据标注和评估方法设计:
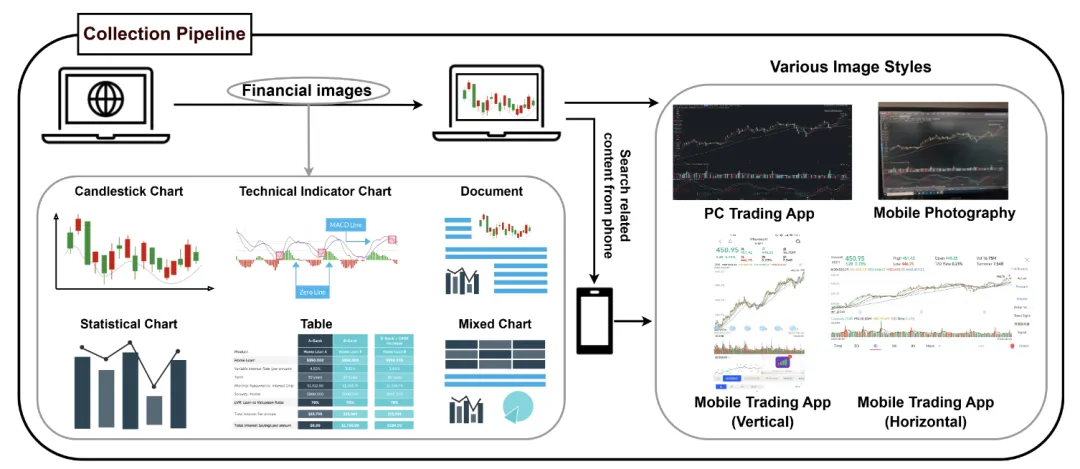
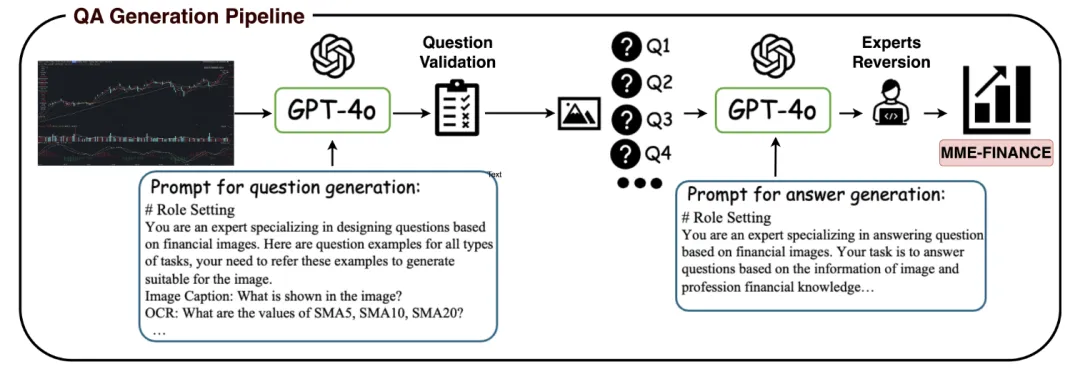
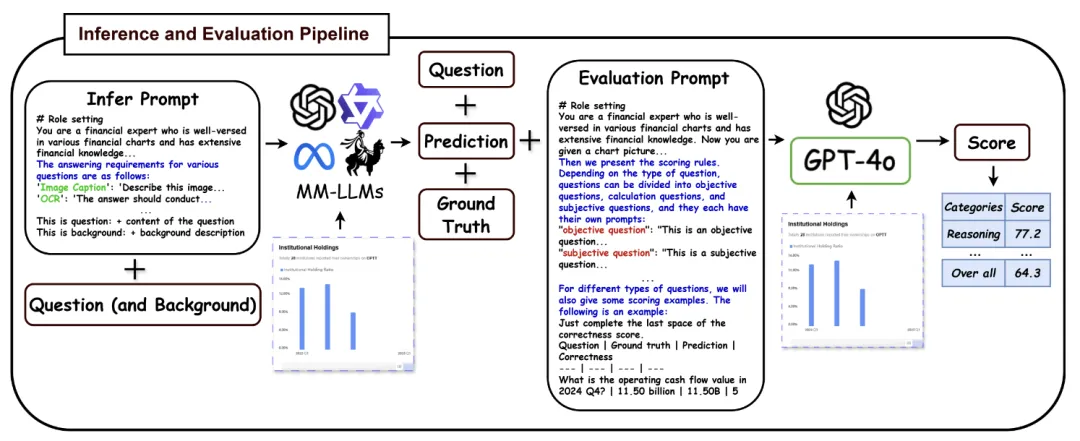
其技术特点体现在其层次化的能力评估结构、实际应用导向的问题设计、专家级的标注质量以及与人类评估者高度一致的评估方法。MME-Finance 未金融领域的多模态大模型提供了一个标准化和专业化的评估平台,有助于揭示现有模型的不足,并指导未来的研究方向。随着金融科技的快速发展,对MLLMs在金融领域的应用需求日益增长,MME-Finance的前景广阔,它不仅能够推动金融多模态模型的技术进步,还可能对金融决策支持系统、自动化交易和风险管理等领域产生深远影响。
这篇论文提出了一个名为MME-Finance的多模态金融基准测试,以下是内容要点:
文章来自于微信公众号 “ADFeed”,作者“ADFeed”




