# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

草图在人类生活中扮演着重要角色

草图作为一种图形语言,从旧石器时代至今在人类生活中一直扮演着重要角色。草图是重要的交互和设计工具。早在1963年,计算机图形学之父Ivan Sutherland就发明了第一个交互式绘图系统Sketchpad,为后续的CAD/CAM软件奠定了基础。草图不仅是设计师表达创意的工具,也是普通人日常生活中的一种交流工具。此外,草图也是人们的一种娱乐方式。例如,风靡一时的游戏“猜画小歌”(Quick, Draw!)就要求玩家在限定时间内画出某个概念,并被机器识别。
草图与AIGC

草图是理解人类认知规律的一扇重要窗口。斯坦福大学的Judith E. Fan通过研究草图来理解人类认知,并发表在多个顶级期刊和会议上。草图还被应用于幼儿启蒙教育和艺术疗愈等领域。


草图是一种很“贵”的数据
在计算机视觉和图像图形领域,草图被用于多种生成任务,如基于草图的图像生成和基于草图的三维物体重建。这些任务是指根据给定的草图,机器合成对应的自然图像或三维物体。例如,我们的研究可以基于草图生成鞋子、椅子等物体的照片,甚至三维模型。然而,高质量的草图数据稀缺,收集成本高昂。因此,我们探索了使用AIGC技术合成草图的方法。

草图很抽象,主要由线条构成,没有颜色。风格迥异,即使是绘制同一个事物,由于人们绘画能力和风格的不同,最后呈现的草图也可能有很大不同。且区别于自然图像/照片,草图是绘制而成的,因此包含有时序信息。
为了合成高质量的矢量草图,我们提出了DiffSketcher方法,利用扩散模型生成矢量草图。矢量图由直线、曲线等几何元素组成,相比光栅图像,矢量图不受分辨率的限制,且占据的存储空间相对较小,更适合设计领域。
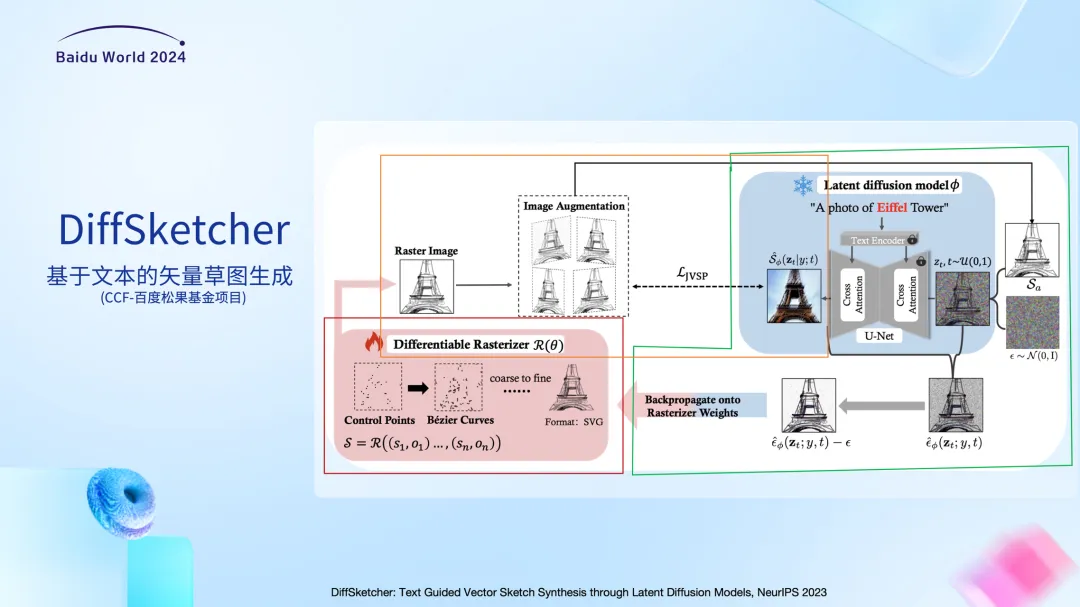

DiffSketcher方法主要分为草图初始化和优化两部分。它的基本思路与DreamFusion类似,就是借助T2I模型的强大先验知识,用于矢量草图的生成。红色的部分是草图初始化部分,像我们前面提到的,矢量草图实际是由组成它的直线和曲线的控制点坐标构成的,所以我们先初始化这些坐标值。接下来,我们不断优化这些坐标值,使得最终生成的草图与输入文本的语义是一致的。
模型优化的信号来自一个文生图大模型,这里我们使用的是Stable Diffusion[1],然后我们利用了改进后的SDS 损失实现从文生图大语言模型的知识蒸馏;另一方面,文生图模型本身可以生成与语义对应的光栅图,我们又引入一个损失函数让生成的草图和文生图大模型生成的光栅图在语义以及外形上一致。简单来说,SDS loss让我们的模型知道如何去画,而与光栅图的比较是告诉我们画出来应该是什么样的。为了保证整个优化的过程中处处有梯度,我们使用了一个开源的矢量图渲染光栅图的可微渲染器Diffvg[2],通过引入Diffvg,我们可以把生成的矢量草图转换为光栅图,然后再与T2I模型输出的光栅图做对比。

上图展示了模型生成矢量草图的过程。可以看到,最初初始化的是一些相对较短的线段。伴随着优化过程,这些线段控制点的位置不断调整,最终呈现出与prompt一致的草图。这个动态的过程可以看作是机器是怎么绘制草图的,和人去绘制草图还是有差别的。这也是后续改进的方向。
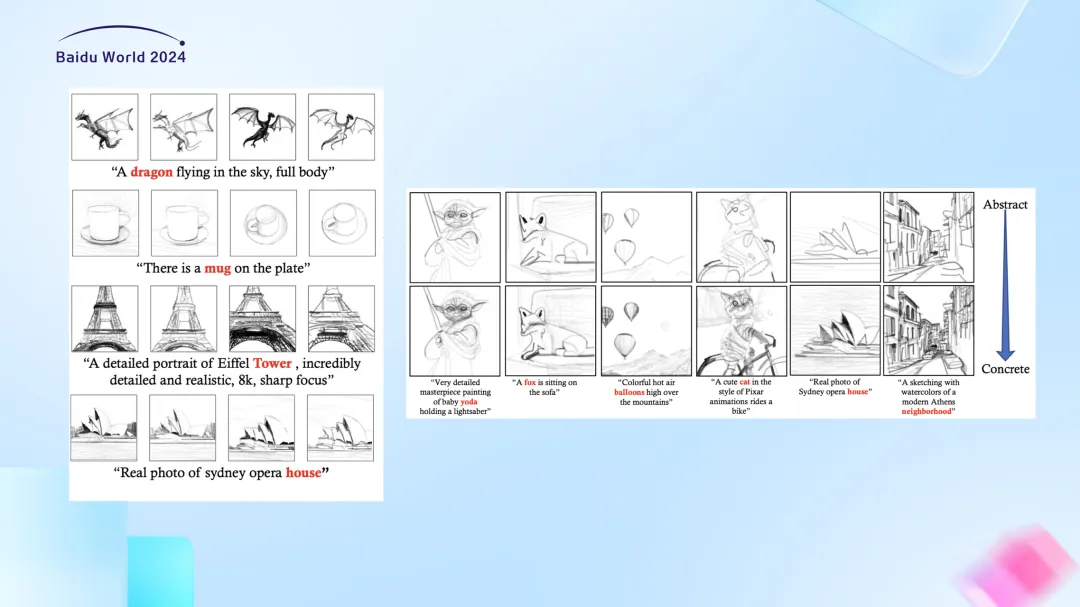
我们的方法能够生成多样化的矢量草图。例如,对于同一个prompt,我们的方法可以生成不同风格的草图,模拟不同人在绘制同一个概念时的差异。此外,通过改变笔画数量,我们还可以模拟不同抽象程度的草图。

通过改变线条颜色,生成具有油画效果的矢量图。此外,我们还可以模拟不同风格的矢量图,如像素艺术、水墨画等。

在今年发表在CVPR 2024的工作中,我们探索了基于文本的多类型可编辑的矢量图生成任务。向实际可用的设计工具又迈进一步。矢量图中的基元包含有多种类型,当我们改变基元的类型的时候,生成的矢量图就会呈现出不同的风格。
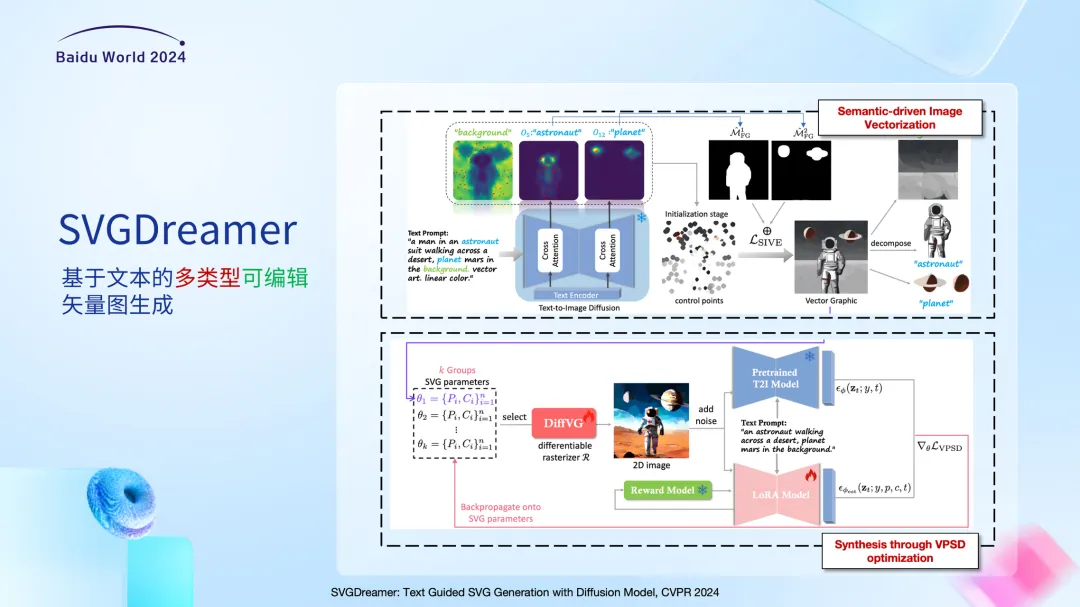
在这个工作中,延续了DiffSketcher基于优化的想法。我们在初始化阶段和优化阶段分别做了改进。之前的方法存在一个问题,比如,在这个宇航员的例子中,原本的方法中同一个基元有可能既参与表达宇航员的概念,又参与表达背景的概念。这样就没有办法把宇航员单独抠出来。通过改进,即在初始阶段利用从注意力图中拿到的掩膜,对不同语义概念分别进行初始和优化,使生成矢量图中的元素可以更好地解耦。从而使得生成的矢量图中的元素相互独立,这样可以作为矢量资产后续被反复使用。
当前矢量图生成方法主要分为基于优化的方法和基于模型直接预测的方法。基于优化的方法生成效果好但效率低,而基于模型直接预测的方法效率高但生成效果相对简单。我们也在进行新的探索,尝试通过更加高效的方式生成高质量的矢量图。

最后,我们推出了开源工具:PyTorch-SVGRender,该工具集成了现有多个矢量图生成算法的实现,并提供了丰富的示例和文档。我们希望通过这个工具,推动矢量图生成技术的发展和应用。
[1]Ben Poole, Ajay Jain, Jonathan T. Barron, and Ben Mildenhall. Dreamfusion: Text-to-3d using 2d diffusion. In The Eleventh International Conference on Learning Representations (ICLR), 2023.
[2]Tzu-Mao Li, Michal Lukácˇ, Gharbi Michaël, and Jonathan Ragan-Kelley. Differentiable vector graphics rasterization for editing and learning. ACM Trans. Graph. (Proc. SIGGRAPH Asia), 39(6):193:1–193:15, 2020.
文章来自于微信公众号“百度高校合作”



【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
