# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
国际权威榜单 LiveBench 官网发布最新的榜单成绩显示,阶跃星辰自研的万亿参数语言大模型 Step-2 在榜单中位列国产基座大模型第一,成绩逼近 OpenAI 的 o1-mini-2024-09-12,超越 gpt-4o-2024-08-06 、gemini-1.5-pro-002 等国际主流模型,是唯一进入榜单前十名的中国语言大模型,位列全球第五。
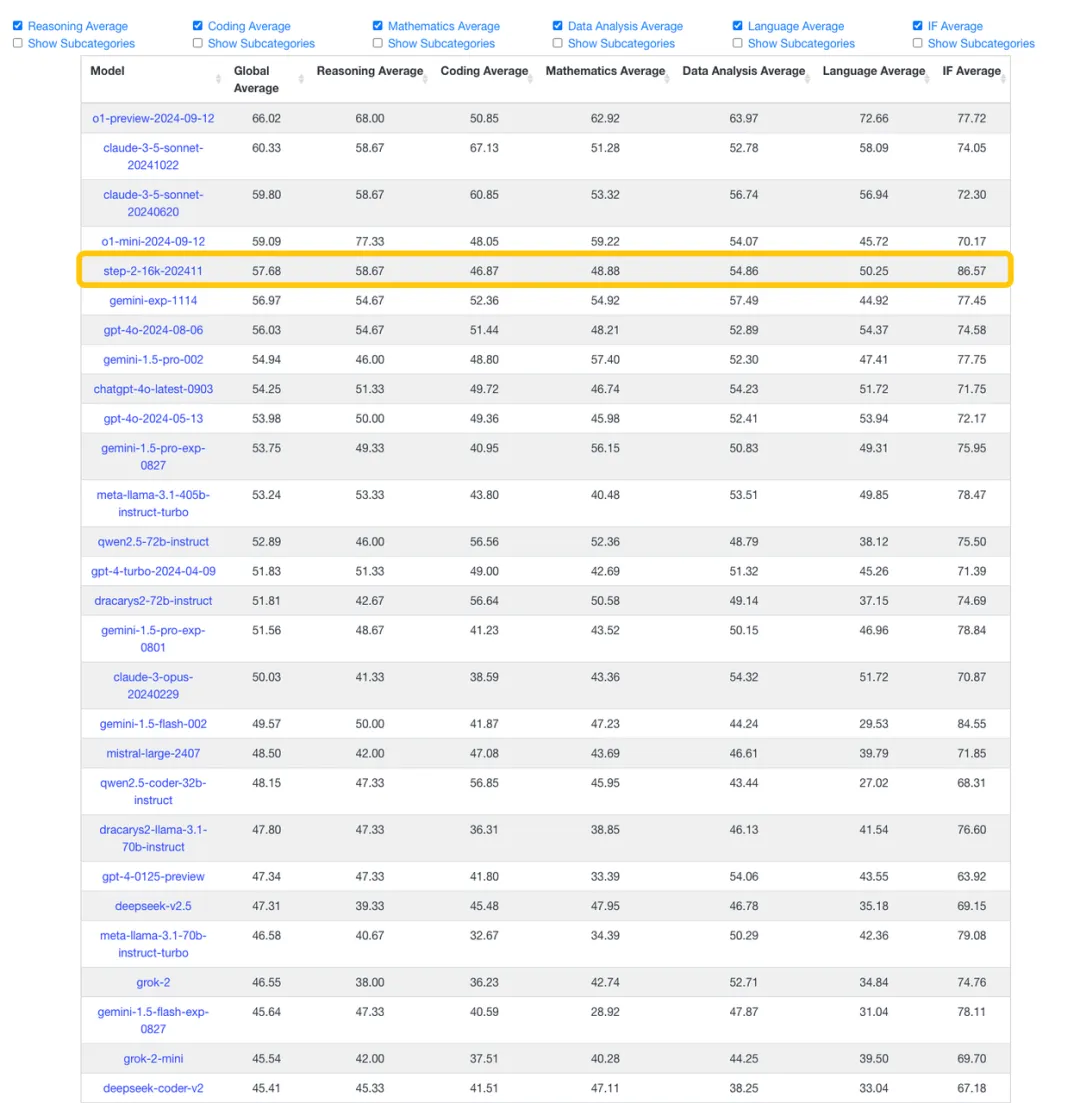
(图片来自 LiveBench 官网)
LiveBench 的权威性在大语言模型测评圈中有着难以撼动的地位,被称为“世界上第一个不可玩弄的 LLM 基准测试”,不仅因为它是由图灵奖得主、Meta 首席 AI 科学家杨立昆(Yann LeCun)联合 Abacus.AI、纽约大学等机构联合推出,更因为 LiveBench 通过一系列设计以确保测试集的客观、中立和广泛性。比如通过“每月更新题目”避免大模型微调作弊,设计中立的评价体系以避免人类评价者受格式偏好和文风影响,全面评估大模型包括推理、编程、写作和数据分析在内的多种维度等等。
因为高度公平和透明,LiveBench 甚至把 “A Challenging, Contamination-Free LLM Benchmark” 直接写在了官网上。
根据榜单,Step-2 在 IF Average(Instruction Following)一项表现突出,超越包括 o1-preview-2024-09-12 在内的所有国内外语言大模型。这意味着,Step-2 在语言生成上对细节有最强的控制力,模型能够更好地理解和遵循人类指令,比如:
1. 模糊指令“更懂你”
Step-2 具备出色的理解能力,能够从上下文中推断出用户的需求,精准捕捉用户在模糊指令中的真实意图,提供更准确、个性化的响应。
2. 知识分布更广更深
Step-2 在知识覆盖范围和深度上都取得显著突破,不仅能够处理常见领域知识,还能深入理解和回答在特定领域或边缘分布中的复杂问题。
3. 文字创作控制上更细致
Step-2 能够生成高质量、有创意的文字内容,同时具备出色的细节控制能力,能够根据用户的指令对文本进行精确地调整和优化。比如在创作古诗词时,对字数、格律、押韵、意境都可以做到精准把握。
今年 3 月,阶跃星辰发布了 Step-2 语言大模型预览版,这是国内首个由创业公司发布的万亿参数模型。Step-2 在语义理解、指令跟随、内容创作方面表现突出。目前,阶跃星辰 C 端智能助手「跃问」已经接入了 Step-2 万亿参数语言大模型,在跃问 App 和跃问网页端(https://yuewen.cn)皆可体验。
文章来自微信公众号 “ 阶跃星辰 “,作者 阶跃星辰



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
