# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
1966年,首个AI精神健康聊天机器人Eliza问世,作为一种简单的自然语言处理程序,它模拟了心理治疗师的对话风格,标志着AI在心理健康领域应用的起点。
58年后的今天,人才短缺与需求多重等挑战,依然限制着心理健康领域的发展。在这方面,基于AI构建的大语言模型(LLM),如Open AI的GPT-4和谷歌的Gemini,展示了在支持、增强,甚至最终自动化心理治疗方面的巨大潜力[1]。

▷图源:AIM
但是,负责任且基于循证的临床实践的临床心理治疗,离不开深厚且精准的专业知识。临床心理学,也因此成为AI难以踏足的高风险领域。
那么,临床心理治疗领域真正期待的LLM,应该具备什么功能与特质?应用心理治疗LLM,是否真的会影响治疗联盟的关系纽带?
近期,综述论文《大语言模型可改变行为医疗保健的未来:负责任的开发和评估建议》一文,梳理了LLM在心理治疗中临床应用的最新研究进展,并提出了在这一敏感领域中进行负责任开发和评估的建议,为LLM在心理治疗中临床应用提供了全景式导航。

▷原文链接:https://www.nature.com/articles/s44184-024-00056-z
目录
1. 引言
2. 临床LLMs的技术基础
3. LLMs在心理治疗中的应用
4. LLMs应用于心理治疗的发展建议
5. 行为健康提供者的视角
6. 技术专家的视角
7. 结论与未来展望

引言
在行为健康(Behavioral healthcare)领域,LLM的应用也已开始,人们正尝试将其用于准治疗(quasi-therapeutic)目的[2]。
融合了自然语言处理(NLP)技术的传统AI应用,早已存在了几十年[3]。例如,机器学习和NLP已被用于检测自杀风险[4],识别心理治疗疗程中的家庭作业分配[5]以及患者情绪[6]。
而行为健康领域的LLM应用目前还处于起步阶段——包括定制LLM以帮助心理咨询师提高同理心表达能力,这种方法已在学术和商业环境中与客户部署[2,7]。另一个例子是,LLM应用已被用于在动机访谈框架中识别治疗师和咨询者的行为[8,9]。
类似地,尽管在面向患者的行为健康领域已部署上了NPL算法智能,但这些领域尚未被大量使用LLM。例如,针对抑郁症和饮食障碍的心理健康聊天机器人Woebot和Tessa[10,11],它们都是基于规则的而非使用LLM,即应用的内容是人类生成的,聊天机器人基于预定义的规则或
决策树回复[12]。然而,它们和其他现有的聊天机器人一样,经常难以理解和响应用户预料之外的问题[10,13],这可能是导致它们参与度低和退出率高的原因之一[14,15]。
而LLM能够灵活生成类似人类的上下文相关的回复,因此可能有助于填补这些空白。目前已有一些面向患者的结合LLM的应用程序进入了测试阶段,包括一个基于研究的生成治疗咨询对话的应用程序[16,17],以及一个基于行业数据的混合使用规则和生成式AI的心理健康聊天机器人Youper[18]。
这些早期应用展示了LLM在心理治疗中的潜力——随着其应用的普及,它们将改变心理治疗护理服务方式。然而,鉴于精神疾病病理学和治疗的复杂性质,尽管LLM在这一方面前景广阔,但仍有必要保持谨慎。
与其它LLM应用相比,提供心理治疗是一个异常复杂、风险极高的领域。例如,在生产力方面,如果有一个“LLM助理(LLM co-pilot)”总结心理治疗的对话笔记,风险在于LLM可能无法最大限度地提高效率和提供帮助;而在行为健康护理中,风险可能包括自杀或谋杀风险处理不当。
AI在其他领域的应用可能生死攸关(例如自动驾驶汽车),但在心理治疗案例中预测和缓解风险则更为微妙,涉及复杂的案例概念化、考虑社会文化背景以及应对不可预测的人类行为。临床实践中的不良结果或伦理违规可能对个人造成伤害,这也可能被过度宣传(如其他AI失
败案例一样[19]),这可能会损害公众对行为心理治疗的信任。
因此,临床LLM的开发者需要特别谨慎行事,以防止此类后果。开发负责任的临床LLM的统筹颇具挑战,主要是因为负责产品设计开发的技术开发者通常缺乏临床敏感性和经验。因此,需要行为健康专家的关键性作用,指导开发并就应用的潜在局限性、伦理考量和风险发表意
见。下文就将从行为健康提供者和技术人员的角度出发,对LLM在行为健康中应用的未来展开讨论。

LLM临床应用概述
临床LLM的形式多样,从简短的干预或用于辅助治疗的限定工具,到旨在自主提供心理治疗的聊天机器人,应有尽有。这些应用可以是:
(1)语言模型的工作机制
语言模型,即对词语序列出现概率的计算模型,已经存在很长时间了。其数学公式可追溯到的[20],最初的应用案例集中在压缩通信[21]和语音识别[22,23,24]上。语言模型已成为语音识别和自动翻译系统选择候选词的主流方法,但直到最近,使用这些模型生成自然语言,很难在抽象诗歌[24]之外取得成功。
(2)大语言模型
大语言模型的兴起,得益于Transformer深度学习技术[25]和计算能力的提升[26]。这些模型首先使用“无监督”学习在大量数据上进行训练,其中模型的任务是预测单词序列中的给定单词[27,28]。然后可以通过包括使用示例提示或微调等方法,对模型进行特定任务的定制,其中一些
方法不需要或只需要少量特定任务的数据(见图1)[28,29]。LLM在临床应用方面具有潜力,它们可以解析人类语言并生成类似人类的回复,对文本进行分类/评分(即标注),并灵活采用代表不同认知理论对应的对话风格。
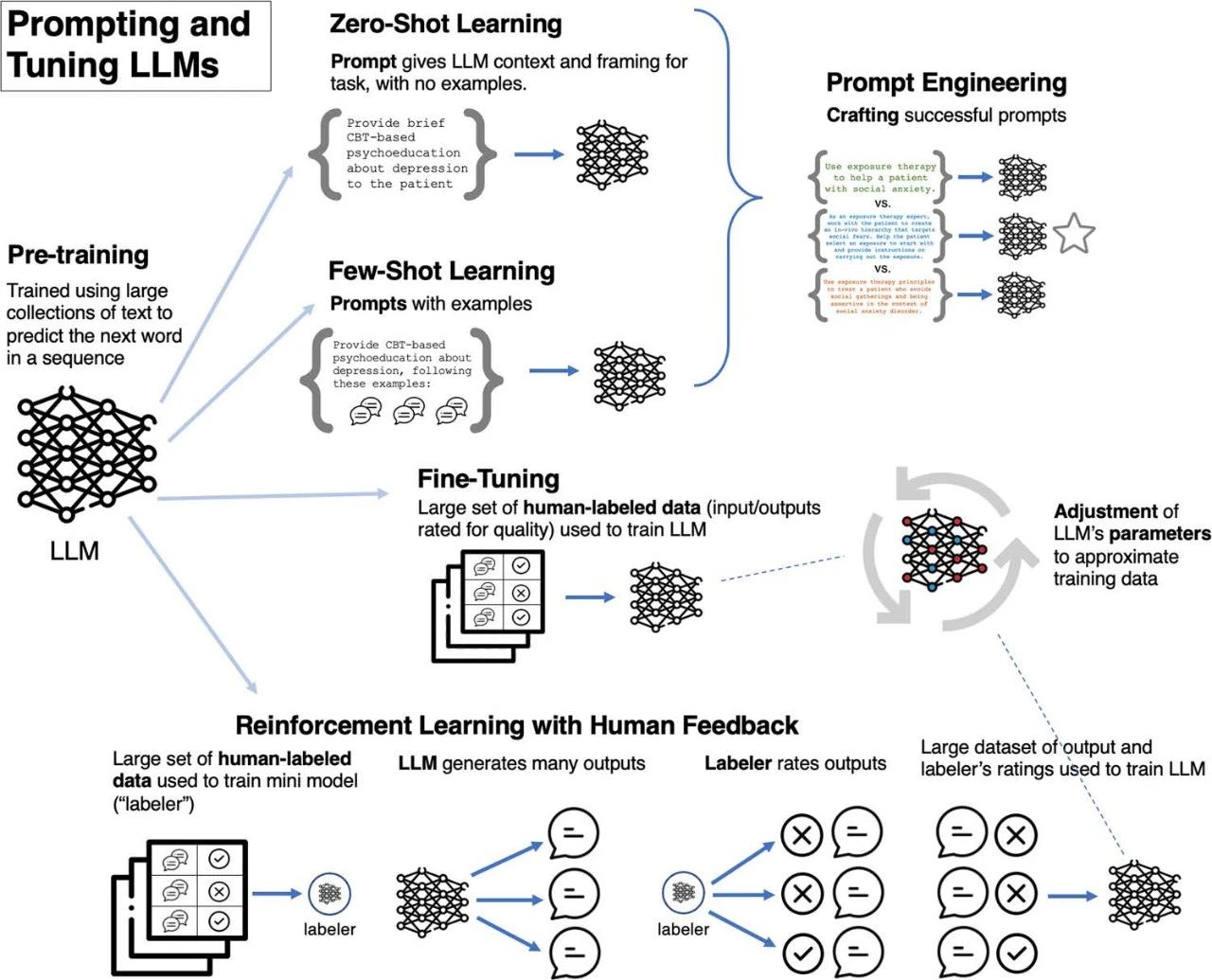
▷图1:定制临床大语言模型的方法
(3)LLM与心理治疗技能
在某些应用案例中,LLM显示出执行心理治疗的任务或技能所需的潜力,例如进行评估、提供心理疾病教育和演示干预措施(见图 2)。
然而,迄今为止,临床LLM产品和技术雏形尚未达到接近取代心理治疗师的精密程度。例如,虽然LLM可以按照认知行为疗法(CBT)方法生成替代性信念,但它能否发起苏格拉底式轮流提问以引发认知变化,还有待观察。这更普遍地突显了在模拟治疗技能和切实减轻患者痛
苦之间可能的差距。鉴于心理治疗记录可能少见于在LLM的训练数据中,以及隐私和伦理问题的挑战,因此,提示工程(prompt engineering)可能是塑造LLM行为的最为合适的微调方法。
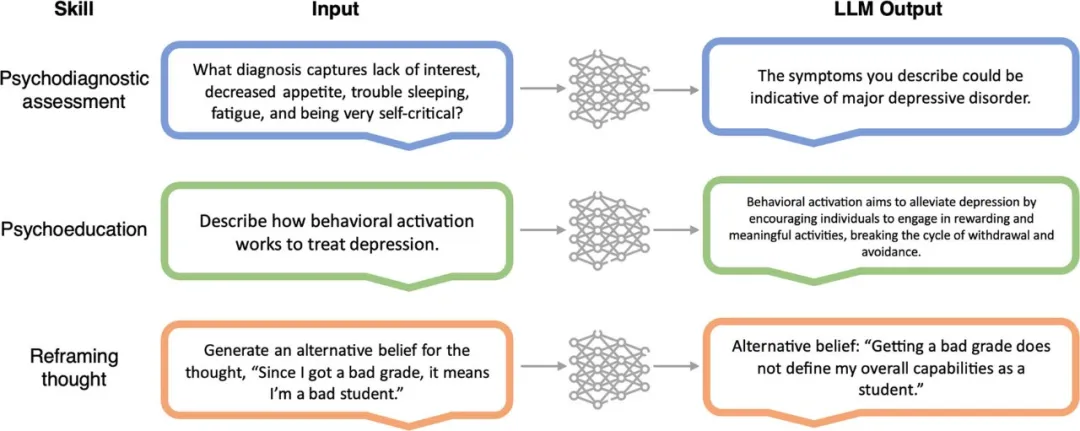
▷图2:大语言模型的临床技能示例。

临床LLM的各个整合阶段
将LLM整合到心理治疗中,可表述为从辅助型AI(assistive AI)连续衍变(continuum)为完全自主型AI(fully autonomous AI),类比其他领域的AI整合模式,如自动驾驶汽车行业(见图3和表1)。
连续衍变的起点是辅助型AI(“机器在环”)阶段,其中车辆辅助驾驶系统本身没有能力独立完成主要任务(如加速、制动和转向),而是提供瞬时的辅助(如自动紧急制动、车道偏离警告)以提高驾驶质量或减轻驾驶员负担。在协作型AI(“人在环”)阶段,车辆系统协助完成主
要任务,但需要人类监督(如自适应巡航控制、车道保持辅助)。最终,在完全自主型AI阶段,车辆可以自动驾驶,不需要人类监督。
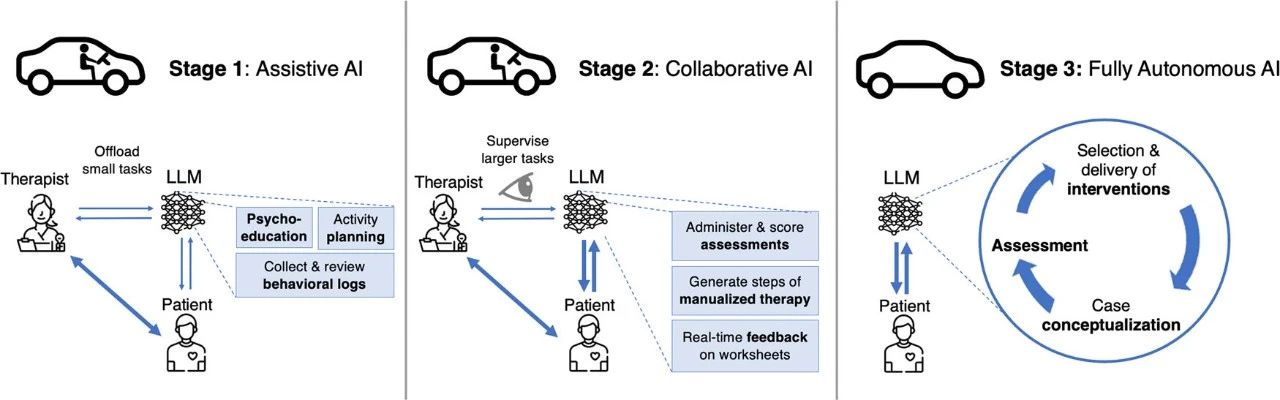
▷图3:将大语言模型整合到心理治疗中的多个阶段。
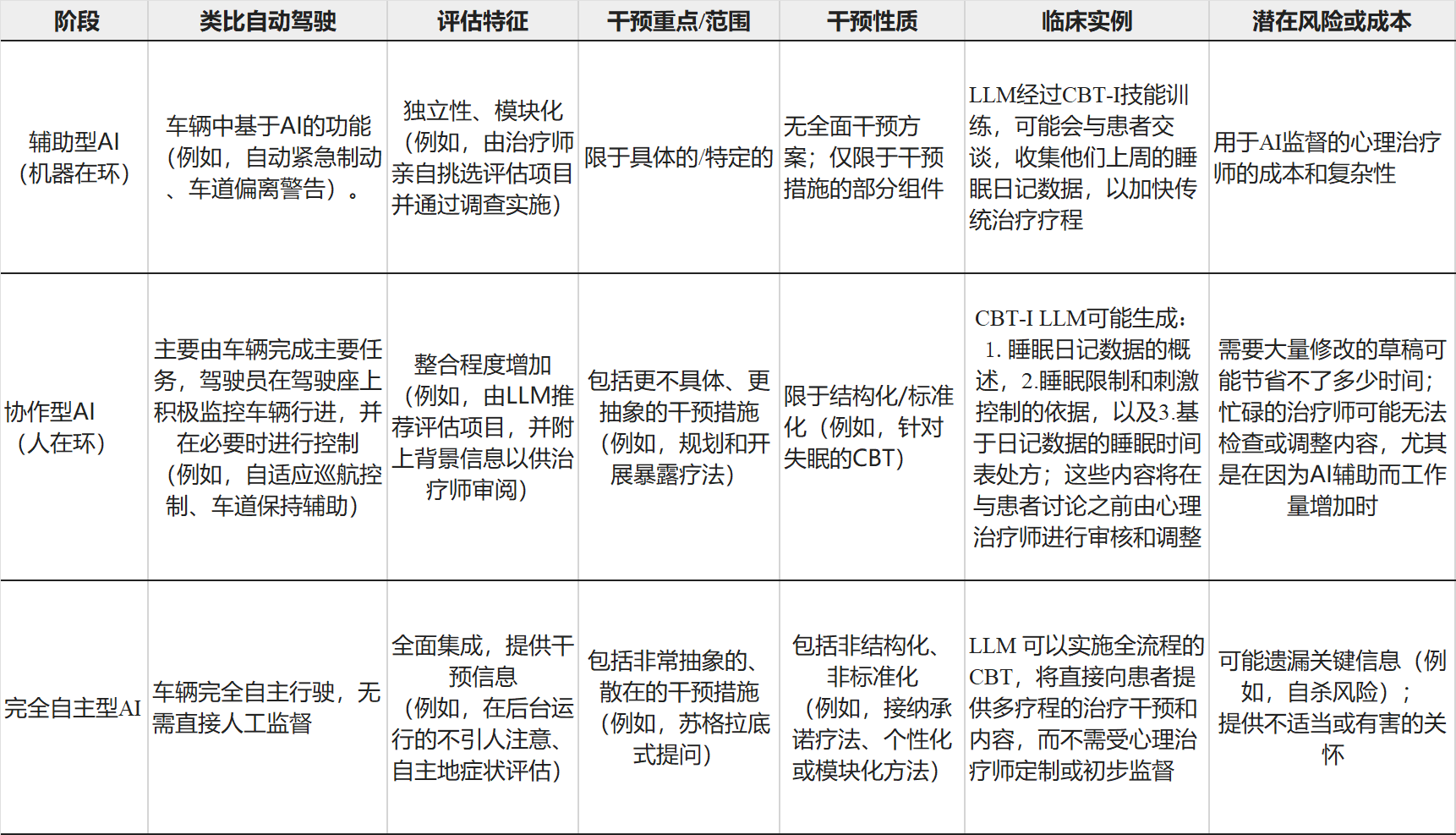
▷表1:将大语言模型整合到心理治疗中的多个阶段
第一阶段:辅助型LLM
在LLM整合的第一阶段,AI将作为工具辅助临床治疗提供者和研究人员完成那些可以轻松“外包”给AI助手的任务(表1;第一行)。由于这是整合的初始步骤,涉及的任务将是低级别的、具体的和特定的,因此风险较低。例如,协助收集患者入院或评估信息、为患者提供基本的
心理疾病教育、为从事基于文本的护理(text-based care)的咨询师提供文本编辑建议,以及汇总患者表单等。此阶段的系统,还可以起草会议记录以支持临床中的文字工作。
第二阶段:协作型LLM
衍变更进一步,AI系统将发挥主导作用,为治疗计划和大部分治疗内容提供或建议选项,而人类则运用其专业判断从中进行选择或调整。例如,在文本或即时消息传递的结构化心理治疗干预中,LLM可能会生成包含会话内容和任务的信息,治疗师将在发送前根据需要对其进行
审查和调整(表1;第二行)。在协作阶段 AI 更高级的应用,可能包括LLM以半独立的方式(如,作为聊天机器人)提供结构化干预,提供者将监控讨论并在需要时介入控制对话。该阶段与“引导性自助(guilded self-help)”法[30]有相似之处。
第三阶段:完全自主LLM
在完全自主阶段,AI将实现最大程度的应用领域和自主性,其中临床LLM将整合一系列临床技能并实施干预措施,无需临床治疗提供者的直接监督(表1;第三行)。例如,这一阶段的应用,理论上可以进行全面评估,选择适当的干预措施,并全程提供治疗,而无需人工干
预。除了临床内容外,这一阶段的应用还可以集成电子健康记录,完成临床文档和报告撰写,安排预约和处理账单。完全自主的应用提供了极具推及潜力的治疗方法[30]。
进阶之路
各阶段的进展可能不是线性的,需要人工监督,以确保更高整合阶段的应用能够安全地在现实世界中部署。
不同形式的精神疾病及其干预措施,复杂程度各有不同,某些类型的干预措施在开发LLM应用上可能比其他类型更简单。与包含抽象技能或强调认知变化的应用(如苏格拉底式提问)相比,更具体和标准化的干预措施可能更容易由模型提供(并且可能更早可用),例如特定的
行为改变干预措施(如活动安排)。
同样,在完整的治疗方案方面,用于高度结构化、行为化和程序化的干预措施(例如失眠的CBT[CBT-I]或特定恐惧的暴露疗法)的LLM应用,可能比提供高度灵活或个性化干预措施的应用更早面世[31]。
在理论上,将LLM整合到心理治疗中的最终阶段是完全自主的心理治疗交付,无需人工干预或监控。然而,完全自主的AI系统能否达到经评估可安全部署到行为健康领域的程度,还有待观察[32]。
具体的担忧,包括这些系统能否有效地对症状表现复杂、高度共病的个案概念化,如考虑当前和既往的自杀倾向、药物使用、安全担忧、其它共患疾病以及生活环境和事件(如法庭日期和即将进行的医疗程序)。
目前也不明确,这些系统能否证明其擅长让患者长期参与治疗,或解析和应对治疗期间的文本中的细微差别(例如,使用暴露疗法治疗因创伤后应激障碍而害怕离开家的患者,而该患者同时还生活在犯罪率较高的社区)。
此外,被视为临床工作核心的几项技能,目前并不在LLM系统的能力范围内,例如解读非言语行为(例如,坐立不安、翻白眼)、恰当地挑战患者、处理联盟破裂(alliance ruptures)以及做出终止治疗的决定。技术进步,包括即将到来的整合了文本、图像、视频和音频的多模态语言模型,最终可能开始填补这些空白。
除了技术限制,出于安全、法律、哲学和伦理方面的担忧,是否适合将完全自动化作为行为健康护理视为最终目标,仍有待决定。尽管一些证据表明人类可以与聊天机器人建立治疗联盟[34],但这种联盟建立的长期可行性以及是否会产生不良的下游影响(例如,改变个人的现有
关系或社交技能)还有待观察。有人记录了聊天机器人的潜在有害行为,如自恋倾向[35],并对其对人类产生不当影响以及更广泛的LLM相关社会风险表示担忧[36,37]。
一旦完全自主型LLM临床应用造成损害,该领域还须应对问责(accountability)和责任(liability)问题(例如,确定医疗事故中的责任方[38])。因此,有人反对在CBT护理中实施完全自主系统[39,40]。综合考虑,这些问题和担忧可能表明,在短期和中期内,辅助型或协作型AI
应用更适合提供行为健康服务。

LLM的临床应用
以下列举了一些即将出现和潜在的长期应用的临床LLM应用,尤其是重点关注与提供、培训和研究心理治疗直接相关的应用。行为医疗保健的初始症状检测、心理评估和简短干预(例如危机咨询)等方面,并未明确讨论。
(1)即将出现的应用
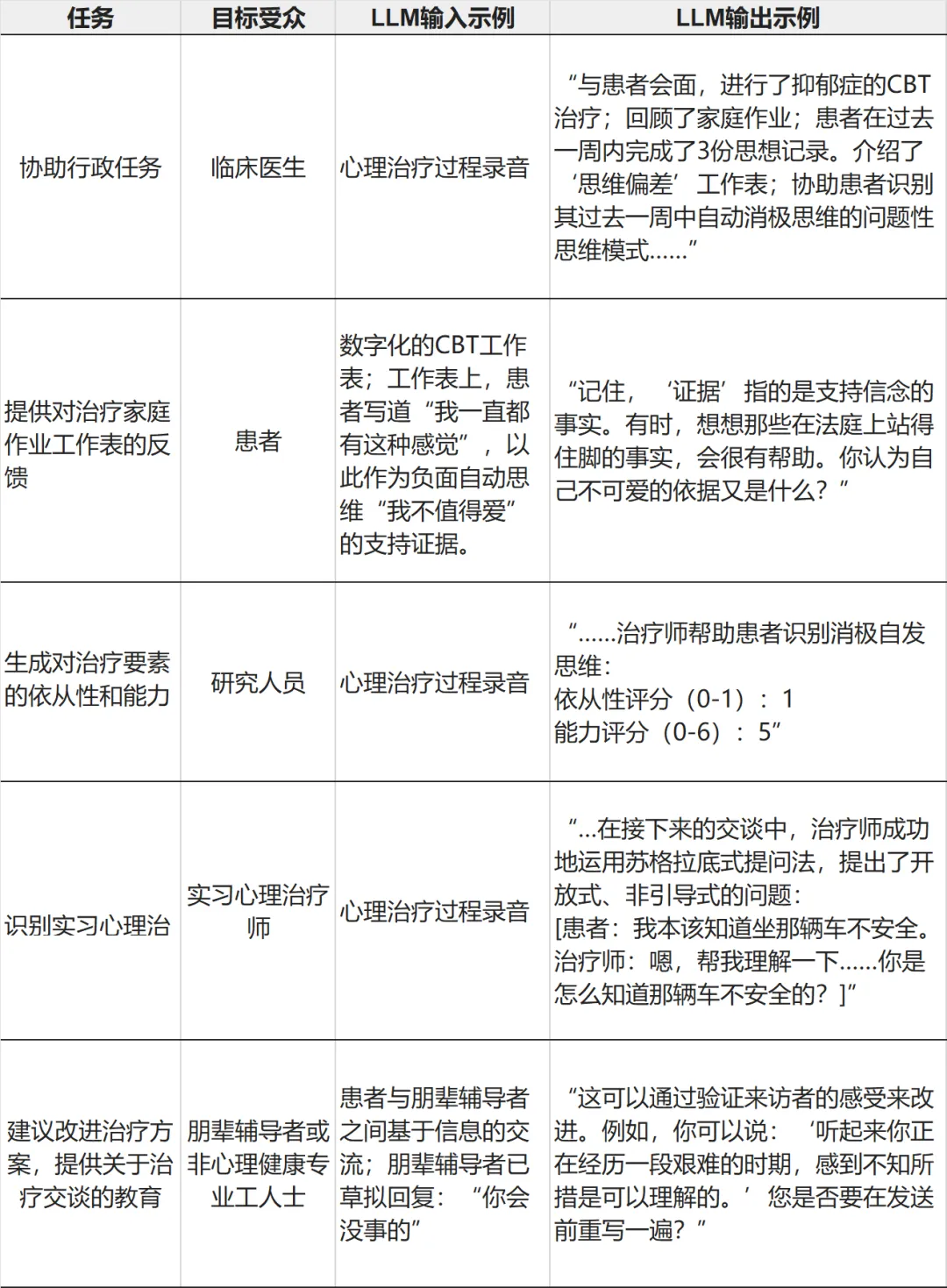
▷表2 临床LLM即将出现的可能性
1. 自动化临床任务管理
在最基本层面上,LLM有潜力自动化与提供心理治疗相关的多个耗时任务(表2,第一行)。除了使用会话记录总结会话以供治疗师参考外,此类模型还有潜力集成到电子健康记录中,以协助临床文档记录和进行病历审查。临床LLM还可以为患者定制一份手册,个性化概述其
疗程、所学技能以及布置的家庭作业或疗程间的材料。
2. 衡量治疗方案忠诚性
一个临床LLM应用程序可以自动评估咨询师是否忠于循证实践(evidence-based practices,EBPs)(表2,第二行),包括测量患者对治疗方案的依从性、评估咨询师提供特定治疗技能的能力、治疗方案的差异性(比较不同治疗方法是否存在实际差异)以及治疗接受度(患
者对治疗内容的理解、参与和依从性)[41,42]。
忠诚性(Fidelity)测量,对于循证实践的发展、测试、推广和实施至关重要,但可能需要大量资源且难以可靠地进行。未来,临床LLM可以计算性地得出依从性和能力评分,帮助研究工作并减少治疗师偏倚(therapist drift)。传统机器学习模型已经被用来评估对特定治疗方法
的忠诚度和其他重要模态,如咨询技能[45]和治疗联盟[46]。考虑到LLM在考虑情境方面的改进能力,LLM可能会提高评估这些构念的准确性。
3. 提供对治疗作业表和家庭作业的反馈
LLM应用还可以发展出为患者的治疗间期家庭作业提供实时反馈和支持(表2,第三行)。例如,LLM被定制用于协助患者完成CBT作业表,当患者遇到困难(例如,患者在填写思想日记时难以区分思想和情绪)时,LLM可能会为其提供解释或协助解决问题。这有助于“弥合治
疗间期的差距”并增进患者技能增强。AI范围之外,早期证据表明,提高作业表的完成度是一个富有成效的临床目标[47]。
4. 自动化监督和培训
LLM可用于对心理治疗或朋辈支持活动提供反馈,尤其是对于受训和经验较少的从业者(例如,朋辈辅导者、非专业人士、心理治疗实习生)。例如,LLM可以用于对朋辈辅导者的对话提出纠正和建议(表2,第四行)。这种应用类似于“任务分担”。“任务分担”是一种全球心理
健康领域使用的方法,通过这种方法,非专业人士可以在专业人士的监督下提供心理健康护理,以扩大心理健康服务的可及性[48]。其中一些工作已经开始进行,例如,如上所述,使用LLM来支持朋辈心理辅导[7]。
LLM也可以在心理治疗师学习新治疗方法时提供督导支持(表 2,第五行)。心理督导的金标准方法,如现场观察或录音审查[49],大多耗时较多。而LLM可以分析治疗全程并找出有待改进之处,为督导或顾问提供可推广的审查方法。
(2)潜在的长期应用
需要注意的是,以下列出的许多潜在的应用都是理论上的,尚未得到开发,更不用说彻底评估。此外,我们使用“临床LLM”这一术语,前提是承认一个事实,LLM的工作在何时、何种情况下才可称为“心理治疗”,这取决于对心理治疗的定义,下定论还为时尚早。
1. 完全自主的临床护理
如前所述,临床LLM的最终阶段可能会涉及能够独立开展综合的行为健康护理的LLM。这可能包括所有与传统护理相关的方面,包括进行评估、提供反馈、选择适当的干预措施并向患者提供治疗方案。这种治疗流程可以通过与当前心理治疗模式一致的方式进行,即患者每周与
“聊天机器人”进行规定时间的互动,或者采用更灵活或替代的形式。以这种方式使用的LLM,在理想情况下,应使用具有大量证据的标准化评估方法和遵循治疗手册的(manualized)的治疗方案进行训练。
2. 针对现有循证实践的决策辅助工具
即使没有完全自动化,临床LLM也可以作为工具,通过优化现有EBP和治疗技术,指导治疗服务提供者为特定患者制定最佳治疗方案。在实践中,LLM能够分析治疗记录,并实时地或在治疗过程结束时,为治疗服务提供者提供治疗技能、方法或语言的指导。此外,LLM还可以
整合最新的EBP证据,融入患者的当前疾病、人口或文化因素以及合并症等针对性EBP信息。基于EBP开发定制的临床LLM“顾问”,既能增强治疗的忠实度,又能最大限度地提高患者根据更新的临床证据而获得临床改善的可能性。
3. 开放新治疗技术和EBP
至目前为止,我们讨论了如何利用现有证据将LLM应用于当前的心理治疗方法。而LLM和其他计算方法还可以极大地促进新的治疗技能和EBP的检测和开发。历史上,EBP一般是来源自人类的洞察,然后经过多年的临床试验研究评估得到的。虽然EBP有效,但其心理治疗效果
通常较小[50,51],并且很大比例的患者没有从治疗中受益[52]。我们迫切需要更有效的治疗方法,尤其是对于症状复杂或有并发症的患者。然而,传统的开发和测试治疗干预措施的方法进展缓慢,导致转化研究严重滞后[53],并且无法在个体层面提供洞见。
数据驱动的方法,有望揭示临床医生尚未意识到的模式,从而产生新的心理治疗方法。例如,机器学习已被用于预测行为健康治疗的效果[54]。利用其解析和总结自然语言的能力,LLM可以为现有的数据驱动方法增添助力。
例如,LLM可以提供一个包含不同治疗取向的治疗记录、结果指标和人口统计学信息的大型历史数据集,并负责检测与客观结果(例如,抑郁症状减少)相关的治疗行为和技术。使用这种方法,LLM可能给出对“现有治疗技术的最佳效果”的精细洞察(例如,现有EBP的哪些组
成部分最有效?有哪些治疗师或患者特征,会影响干预X的效果?干预措施的顺序,如何影响效果?),甚至可以分离出先前未识别的与改善临床结果相关的治疗技术。通过精细地识别治疗的过程,LLM也可以在揭示行为改变机制方面发挥作用,这对于改进现有治疗方法、促进实际应用至关重要[55]。
然而,这一可能性的实现,需要确保基于LLM的改进能够被临床社区整合和审查,就必须要避免发展出“黑箱”,即LLM可识别但可解释性低的干预措施[56]。为避免低可解释性的干预措施,为改善患者预后而进行的微调LLM的工作,可能包括检查LLM所采用的可观察表征
(representation)。临床医生可以检查这些表征,并将其置于更广泛的心理学治疗文献中,与现有的心理治疗技术和理论进行比较。这种做法可以加快识别新的机制,同时防止识别出与现有技术或构念重叠的“新”干预措施(从而避免叮当谬误[Jangle fallacy],即错误地认为名称不同的两个构念必然不同[57])。
从长远来看,通过结合这些信息,LLM甚至可能“逆向设计”出一种新的EBP,摆脱传统治疗方案的束缚,转而最大限度地利用已知能够引起患者行为改变的组成模块(类似于模块化方法,基于患者独特表征,从所有的可用选项中精心挑选和排序治疗模块,为每位患者量身定制
治疗方案[31])。最终,一个自我学习的临床LLM,可能提供广泛的心理治疗干预,并同时测量患者的治疗效果,并根据患者的变化(或缺乏变化)即时调整治疗方法。
(3)趋于精准的心理治疗方法
当前的心理治疗方法,往往无法为病情复杂的患者提供最佳治疗方案指导,这已成常态而并非例外。例如,对于同时患有PTSD、物质使用、慢性疼痛和严重人际关系困难的患者,治疗服务提供者可能会制定出大相径庭的治疗计划。使用数据驱动方法(而非根据治疗者的经验
猜测),处理患者的主诉连同其合并症、社会人口学因素、病史和对当前治疗的反应,这样的模式最终可能会为患者带来最大化的获益。尽管在行为健康领域中,精准医学方法取得了一些进展[54,58],但这些努力仍处于起步阶段,受样本量限制[59]。
上述概述的临床LLM的潜在应用,可能共同促进对行为健康的个性化方法,类似于精准医疗。通过优化现有的EBP、识别新的治疗方法以及更好地理解变化机制,LLM(及其后续迭代)可能强化行为健康护理能力,以识别在何种情况下何种手段对哪些人群最有效。

临床LLM的负责任开发与评估建议
(1)首要关注EBP
在不久的将来,临床LLM的应该基于EBP或共同要素说(common elements approach,即跨治疗共享的循证程序)进行开发,这样的应用将更有可能产生有临床意义的影响。目前针对特定精神疾病(例如,重度抑郁、创伤后应激障碍)、压力源(例如,丧亲、失业、离婚)
和特殊人群(例如,LGBTQ个体、老年人),已经确定了循证治疗和技术[55,61,62]。临床应用如果根源头上没有关注EBP,就无法反映当前的知识水平,甚至可能会带来危害[63]。只有确保LLM均接受了EBP的全面训练,才能考虑以数据驱动的方式逐步应用完全自主的LLM。
(2)关注对现有疗法的改进(不只是参与程度)
还有人强调了推广数字心理健康应用的重要性[15],即重点在于治疗干预达到足够“剂量”。LLM应用具有提升患者参与程度和留存率的潜力,它能够及时响应自然文本、提取关键概念,并在干预过程中及时响应患者的个体背景和关注点。然而,参与程度本身并不是LLM训练的合
适目标,因为它不足以产生行为改变。
将重点聚焦于临床指标,可能会导致忽视主要目标,即临床改善(例如,症状或损害的减轻,福祉和功能的提升)以及风险和不良事件的预防。应警惕对与公司利润有明确关系的临床结果(例如,使用应用的时长)的临床LLM优化的尝试。仅针对参与程度的优化(类似于
YouTube推荐)的LLM,可能有较高的用户留存率,但却不一定采取了有意义的临床干预措施来减轻痛苦和提高生活质量。非LLM的数字心理健康干预中已有先例。例如,暴露疗法虽然是一种有效的焦虑治疗方法,但在治疗焦虑症的热门智能手机应用程序的中却很少用到[64],
可能是因为开发者担心这种方法吸引不到用户,或者担心暴露效果不佳或短期内增加焦虑,反而可能会引来法律风险。
(3)致力于严谨且常识性的评估
临床LLM的评估方法,应优先考虑风险性与安全性,其次是可行性、可接受性和有效性,这与现有的数字心理健康智能手机应用评估建议[65]一致。
评估的第一级,可能需要证明临床LLM不会造成危害,或危害极小且益大于弊,类似于FDA的I期药物试验。风险性与安全性相关的关键指标,包括自杀倾向、非自杀性自伤和伤害他人的风险。
接下来,需要对临床LLM应用进行严格的有效性审查,通过与标准治疗的直接比较,提供其有效性的经验证据(empirical evidence)。在这些经验测试中,需要评估的关键指标,包括患者和治疗师的可操作性和可接受性,以及治疗效果(例如,症状、功能障碍、临床状态、复
发率);其他相关考虑因素,还包括患者对应用的使用体验、治疗师效率与职业倦怠的衡量,以及治疗成本。
最后,我们注意到,鉴于临床LLM可能带来的好处(包括扩大护理机会),因此需要采用常识性的评估方法。虽然严格的评估很重要,但这些评估所依据的比较条件应该反映真实世界的风险和有效率,或许还可以采用分级制度来划分风险和错误(例如,遗漏了提及自杀是不可
接受的,但搞错患者伴侣名字是不理想但可以容忍的),不必用人类无法达到的完美标准来要求临床LLM应用。此外,开发者需要找到优化LLM与实现最大临床效益的适当平衡,例如,如果暴露疗法对患者适用,但患者认为这种方法不可接受,临床LLM可以在提供可能更易接
受的二线干预措施之前,优先推荐考虑有效性的干预措施。
(4)跨学科合作
临床科学家、工程师和技术人员的跨学科合作,对于开发临床LLM至关重要。虽然工程师和技术人员在没有行为健康专业知识的情况下,利用现有的治疗手册来开发临床LLM是可行的,但并不可取。手册只是学习特定干预措施的第一步,因为它们不能指导如何将干预措施应用
于特定个体或表征,也不能指导如何处理治疗中的具体问题或疑惑。
临床医生和临床科学家拥有与上述问题有关专业知识,可以参与诸多环节,如:a)测试新应用,以识别其局限性和风险,并优化其在临床实践中的融合,b)提高应用解决复杂心理现象的能力,c)确保应用的开发和实施符合伦理道德,以及 d)测试并确保应用不具有医源性
影响,例如强化那些会持续心理病理或困扰的行为。
行为健康专家还可以指导如何最好地微调或定制模型,包括回答真实患者数据是否以及如何使用以达成上述目标的问题。例如,最直接的是,行为健康专家可能协助进行提示词工程,即设计并测试一系列提供大模型框架和背景的提示词,以用于特定类型的治疗或临床技能(例
如,“使用认知重构法帮助患者评估和重新评估抑郁中的负面想法”),或期望的临床任务如评估对行为健康疗法的忠实度(例如,“分析这份心理治疗记录,并选择治疗师特别熟练使用CBT技巧以及CBT技巧运用上有待改进的段落”)。
同样,在小样本学习中,行为健康专家也可以参与制作提示词示例。例如,行为健康专家可以生成临床技能的示例(如使用认知重构解决抑郁的高质量示例)或临床任务的示例(如高质量与低质量的CBT交流的示例)。在微调过程中,使用大型标记数据集训练LLM,并从人类
反馈中强化学习(RLHF),即使用人类标记的数据集训练一个较小的模型,然后将其用于LLM的“自我训练”,行为健康专家可以构建和整理(并确保患者知情同意)适当的数据库(例如,包含EBP忠实度评分的心理治疗记录的数据集)。最近的研究表明,对于训练性能良好的
模型来说,数据质量比数据数量更有价值[66]。
在促进跨学科合作的过程中,临床科学家应了解LLM知识,而技术专家学则应了解一些常规治疗特别是EBP知识。
将行为健康专家和临床心理学家聚集在一起,进行跨学科合作与交流的专门会议,有助于此。历史上,此类会议包括在NPL会议上举办的以心理学为重点的研讨会(例如,在北美计算语言学协会[NAACL]年度会议上的计算语言学与临床心理学研讨会[CLPsych]),以及由心理
组织主办的以技术为重点的会议或工作组(例如,美国心理学会[APA]的技术、心灵与社会会议[TMS];行为与认知治疗协会[ABCT]的技术与行为改变特别兴趣小组[ABCTtechsig])。以心理健康技术工具为中心的非营利组织中也开展了这些工作(例如,数字心理健康协会
[SDMH])。
除了这些会议,召开一个汇集技术专家、临床科学家和行业合作伙伴的聚会,专注于AI或LLM,并定期发布其工作成果,这可能会富有成效。世界卫生组织"信息流管理会议"(Infodemic Management Conference),就是通过这种方法来应对虚假信息[67]。
最后,鉴于AI在行为健康领域的众多应用,可以发展出一个新的子领域“计算认知健康”,以提供专门培训,弥合这两个领域之间的间隔。
(5)关注临床医生和患者的信任与易用性
让治疗师、政策制定者、终端用户和人机交互领域的专家加入进来,了解并提高对LLM的信任水平,这对于成功和有效地实施而言是必要的。
关于将AI应用于增强对心理治疗的监督和支持,治疗师们担忧隐私、对细微的非言语线索的检测与文化适应能力,以及对治疗师信心的影响,但他们也看到了AI在培训和专业成长中的益处[68]。其他研究表明,治疗师认为AI可以增加护理的可及性,使个人更舒适地披露尴尬信
息,并持续改进治疗技术[69],但他们也对私密性和与基于机器的治疗干预形成的治疗纽带是否牢固表示担忧[70]。考虑到医护的参与程度对向患者推荐并使用LLM的实践中的重要性,因此需要开发他们信赖并愿意实施的解决方案,并确保这些解决方案具备支持医患信任和易用
性的特性(界面简单、对AI与患者互动总结准确等)。
关于患者对AI系统的信任程度,在实现图3中概述的完全自主型LLM阶段之后,AI与患者的初始交互将继续由临床医生监督,临床医生与患者之间的治疗纽带仍将是主要关系。在这一阶段,很重要的是让临床医生与患者讨论他们在LLM中的体验,也要开始逐步收集相关洞见和
数据,包括何种患者、何种临床应用案例中对LLM的接受程度,以及临床医生如何构建患者与LLM关系。这些数据,对于开发自主性更强的协作LLM应用,并确保从辅助型到协作型LLM的过渡不会带来巨大的意外风险,至关重要。例如,在针对失眠的CBT案例中,一旦辅助型
AI系统经过迭代能够可靠地收集患者的睡眠模式信息,那么它就更有可能演变成一个可以进行综合失眠评估的协作型AI系统(即,同时收集和解读患者的临床显著痛苦、功能障碍情况以及鉴别睡眠-觉醒障碍(如发作性睡病)的数据[71]。
(7)设计有效的临床LLM标准
以下是对临床LLM的理想设计品质的初步设想。
1. 检测伤害风险
a)精准的风险检测和强制报告机制,是临床LLM必须优先考虑的关键方面,尤其是在识别自杀/他杀意念、虐待儿童/老年人和亲密伴侣暴力方面。相关风险检测算法正在开发中[4]。风险检测面临的挑战之一是,当前LLM的上下文窗口(context windows)有限,这意味着它们只
能“记住”有限的用户输入。
从功能上讲,这意味着临床LLM应用可能会“忘记”患者的关键细节,这可能会影响安全性(例如,应用“忘记”患者拥有枪支,会严重影响正确评估和干预自杀风险的能力)。然而,随着迭代模型的发布,上下文窗口正在迅速扩大,这个问题可能不会长期存在。此外,已经可以通
过“向量数据库(vector databases)”增强LLM的记忆,这样做的额外好处是在整个临床过程汇总保留可检查式学习和总结[72] 。
将来,尤其是在更大的上下文窗口中,临床LLM可以为临床医生提供伦理指导、法律要求(例如,Tarasoff规则,要求临床医生在患者表现出严重暴力威胁时警告预期受害者),或有循证依据的风险降低方法(例如,安全计划[73]),甚至直接向患者提供针对性的风险干预措
施。这种风险监控和干预有助于补充现有医疗体系,尤其是在临床医生空缺时段(如夜晚和周末[4])特别有用。
b) 保持“健康”。人们越来越担心,AI聊天系统可能会表现出不良行为,包括类似抑郁或自恋的表达[35,74]。这些难以理解的、不良行为,可能会伤害已经很脆弱的患者,或干扰他们从治疗中获益的能力。临床LLM应用需要监控其行为并预设防范措施,以避免不良行为的表达,保
持与用户的健康互动。这就需要持续地评估和更新,以防止或应对新的不良行为或临床禁忌行为的出现。
2. 辅助心理诊断评估
临床LLM应整合心理诊断评估和诊断,以便于干预选择和结果监测[75]。近期发展来看,LLM颇有希望用于心理健康评估[76]。下一步,LLM还可以以聊天机器人或语音界面形式用于诊断访谈(例如,DSM-5的结构化临床访谈[77])。优先评估(Prioritizing assessment),可提高
诊断准确性,并确保适当干预,降低有害干预的风险[63]。
3. 应答迅速,灵活多变完全自主的临床护理
考虑到临床中经常出现矛盾(ambivalence)和患者参与程度低的情况,如果应用临床LLM以基于循证证据和以患者为中心的方法来处理这些问题(例如,动机增强技术、共同决策),并为对金标准疗法不感兴趣的患者提供二线干预方案,将更有希望取得治疗成功。
4. 当没有帮助和信心时停止工作
在当前治疗方案没有帮助或可能不会帮助的情况下,心理学家有道德义务停止治疗,并向患者提供适当的转诊。临床LLM也应该遵守这一道德标准,可以通过综合评估来评估当前干预措施的适宜性,并识别需要更多专业化或密集干预的情况。
5. 公平、包容、无偏见
大量论述指出过,LLM由于是在现有文本上训练得到的,因而可能会延续偏见(包括种族主义、性别歧视和恐同症)[36]。这些偏见可能导致误差差异(即模型对特定群体的准确性不够)或结果差异(即模型倾向于过度强调人口统计信息)[78],这反过来又会助长少数族裔群体
正在经历的心理健康状况和护理方面的差异[79]。将偏差管理对策整合到临床LLM应用中,可以防止这种情况[78,80]。
6. 有同理心——但有限度
临床LLM,为了让患者积极参与,可能需要表现出同理心并建立治疗联盟。治疗师还可能会施展如幽默、无理或温和地挑战患者的技巧。将这些融入临床LLM可能有益,因为适当的类人属性(human likeness)可能会促进患者的参与程度以及与AI的关系[81]。然而,这需要权衡
将类人属性融入系统带来的相关风险[36]。心理干预是否需要以及需要多少类人属性,仍然是有待未来实证研究解决的问题。
7. AI身份透明化
精神疾病和心理健康护理已经被污名化,未经知情同意使用LLM可能会削弱患者或消费者的信任,这会降低对整个行为健康行业的信任。一些心理健康初创公司已经因在应用中采用生成式AI而未向最终用户披露此信息而受到批评[2]。正如《白宫人工智能权利法案蓝图(the
White House Blueprint for an AI Bill of Rights)》所阐述的,AI应用应明确(或许需反复/持续地)标注,以便让患者和消费者“知道正在使用自动化系统,并了解它如何以及为何会对他们产生影响”[82]。
▷图源:fu.ncsu.edu

讨论
(1)未预见的后果:可能会改变临床认知行为行业
发展临床LLM应用,可能会导致意想不到的后果,例如改变心理健康服务的结构和报酬。AI可能增加非专业人员或准专业人员的数量,导致专业临床医生需要监督大量非专业人员,甚至半自主的LLM系统。这可能会减少临床医生与患者的直接接触,并可能让他们有更多机会接
触不适合LLM的具具挑战性的或更复杂的病例,从而导致职业倦怠并降低临床工作的吸引力。
为了解决这个问题,可以通过研究确定临床医生可安全监督的适当案件数量,并发布指南来传播这些研究发现。基于LLM的干预服务,也可能让消费者对心理治疗的期望,产生不同于心理治疗实践的许多规范改变(例如,为了讨论压力的会面等待,治疗间期患者和医生有限或
仅限紧急情况的联系)。
(2)LLM可能为下一代临床科学铺平道路
除了本文所述的近期应用,值得考虑临床LLM的长期应用,也可能促进临床护理和临床科学的重要进步。
1. 临床实践
在治疗干预措施本身影响的层面,临床LLM可以汇集最困难病例中的有效数据,建立实践研究网络,这或许能够促进该领域的发展[83]。在卫生系统层面,它们可以通过向心理治疗师建议治疗方案来加速研究结果转化为临床实践,例如,推广在暴露疗法中增强抑制性学习的策略
[84]。最后,如果将基于LLM的心理治疗聊天机器人当做阶梯式护理模式中的低强度、低成本选项,临床LLM可以提高获得护理的机会,类似于现有的计算机化CBT和引导性自助(guided self-help)[85]。
随着临床LLM的应用扩展,心理学家和其他行为健康专家的工作可能会向在其技能最高水平转变。目前,临床医生的大量时间被行政任务、病历审查和文件记录所消耗。临床LLM在某些心理治疗方面实现自动化后,其带来的责任转移可能让临床医生担任领导角色,参与基于
LLM的护理的开发、评估和实施,或领导政策工作,或者干脆将更多时间投入到直接的患者护理中。
2. 临床科学
通过促进督导、咨询和忠诚度测量,LLM可以加速心理治疗师培训,提高研究督导人员的能力,从而使心理治疗研究更加经济高效。
在一个完全自主的LLM应用程序负责筛选和评估患者,提供高保真、标准化心理治疗,并收集结果测量的世界中,心理治疗临床试验将主要受限于愿意参与者的数量,而不是受筛选、评估、治疗和跟踪这些参与者所需的资源。这将为前所未有的大样本规模的临床试验敞开大
门。这将允许我们进行强大、复杂的拆解(dismantling)研究,以支持寻找心理治疗中带来行为改变的机制,而这些机制目前只能通过个体参与者层面的元分析来实现[86]。最终,这些关于心理治疗变化因果机制的见解,可以帮助完善治疗方法、提高治疗疗效。
最后,LLM治疗方法的兴起,将挑战(或证实)关于心理治疗的基本假设——治疗(人类)联盟是否解释了患者行为变化中的大部分差异?在多大程度上可以与一个AI智能体形成治疗联盟?是否只有通过与人类治疗师合作,才能实现持久而有意义的治疗改变?LLM有希望为这
些问题提供经验性回答。
总的来说,LLM有望支持、增强甚至取代(在某些情况下)人类主导的心理治疗,从而提高治疗干预和临床科学研究的质量、可及性、一致性和可扩展性。
LLM发展迅速,或许很快就会在临床领域中部署开来,然而我们却对其可能产生的危害却缺乏监管和了解。虽然我们有理由对临床LLM应用谨慎乐观,但心理学家也必须谨慎地将LLM整合到心理治疗中,并教育公众使用这些技术进行治疗的潜在风险和局限性。
此外,临床心理学家应积极与构建这些解决方案的技术人员合作。随着AI领域的持续发展,研究人员和临床医生密切监测LLM在心理治疗中的使用,并倡导负责任和合乎道德地使用LLM,以保护患者的福祉。

1. Bubeck,S. et al.Sparksof artificial general intelligence:Early experiments with GPT-4. Preprint at http://arxiv.org/abs/2303.12712 (2023).
2. Broderick,R.People are usingAI fortherapy,whetherthe tech is ready for it or not. Fast Company (2023).
3. Weizenbaum, J. ELIZA—a computer program for the study of natural language communication between man and machine.Commun.ACM 9, 36–45 (1966). 4. Bantilan, N., Malgaroli, M., Ray, B. & Hull, T. D. Just in time crisis response: Suicide alert system for telemedicine psychotherapy settings. Psychother. Res. 31, 289–299 (2021).
5. Peretz, G., Taylor, C. B., Ruzek, J. I., Jefroykin, S. & Sadeh-Sharvit, S. Machine learning model to predict assignment of therapy homework in behavioraltreatments:Algorithm development and validation. JMIR Form. Res. 7, e45156 (2023).
6. Tanana, M. J. et al. How do you feel? Using natural language processing to automatically rate emotion in psychotherapy. Behav. Res. Methods 53, 2069–2082 (2021).
7. Sharma, A., Lin, I. W., Miner, A. S., Atkins,D. C. & Althoff, T. Human–AI collaboration enables more empathic conversations in text-based peer-to-peer mental health support. Nat. Mach. Intell. 5, 46–57 (2023).
8. Chen, Z., Flemotomos, N., Imel, Z. E., Atkins, D. C. & Narayanan, S. Leveraging open data and task augmentation to automated behavioral coding of psychotherapy conversations in low-resource scenarios. Preprint at https://doi.org/10.48550/arXiv.2210.14254 (2022). https://doi.org/10.1038/s44184-024-00056-z Article npj Mental Health Research | (2024)3:12 9
9. Shah, R. S. et al. Modeling motivational interviewing strategies on an online peer-to-peer counseling platform. Proc. ACM Hum.-Comput. Interact 6, 1–24 (2022).
10. Chan,W.W. et al. The challenges in designing a prevention chatbotfor eating disorders: Observational study. JMIR Form. Res. 6, e28003 (2022). 11. Darcy, A. Why generative AI Is not yet ready for mental healthcare. Woebot Health https://woebothealth.com/why-generative-ai-is-notyet-ready-for-mental-healthcare/ (2023).
12. Abd-Alrazaq, A. A. et al. An overview of the features of chatbots in mental health: A scoping review. Int. J. Med. Inf. 132, 103978 (2019).
13. Lim, S. M., Shiau, C. W. C., Cheng, L. J. & Lau, Y. Chatbot-delivered psychotherapy for adults with depressive and anxiety symptoms: A systematic review and meta-regression. Behav. Ther. 53, 334–347 (2022).
14. Baumel, A., Muench, F., Edan, S. & Kane, J. M. Objective user engagement with mental health apps: Systematic search and panelbased usage analysis. J. Med. Internet Res. 21, e14567 (2019).
15. Torous, J., Nicholas, J., Larsen, M. E., Firth, J. & Christensen, H. Clinical review of user engagement with mental health smartphone apps: Evidence, theory and improvements. Evid. Based Ment. Health 21, 116–119 (2018b).
16. Das, A. et al. Conversational bots for psychotherapy: A study of generative transformer models using domain-specific dialogues. in Proceedings of the 21st Workshop on Biomedical Language Processing 285–297 (Association for Computational Linguistics, 2022). https://doi.org/10.18653/v1/2022.bionlp-1.27.
17. Liu, H. Towards automated psychotherapy via language modeling. Preprint at http://arxiv.org/abs/2104.10661 (2021).
18. Hamilton, J. Why generative AI (LLM) is ready for mental healthcare. LinkedIn https://www.linkedin.com/pulse/why-generative-aichatgpt-ready-mental-healthcare-jose-hamilton-md/ (2023).
19. Shariff, A., Bonnefon, J.-F. & Rahwan, I. Psychological roadblocks to the adoption of self-driving vehicles. Nat. Hum. Behav. 1, 694–696 (2017).
20. Markov, A. A. Essai d’une recherche statistique sur le texte du roman “Eugene Onegin” illustrant la liaison des epreuve en chain (‘Example of a statistical investigation of the text of “Eugene Onegin” illustrating the dependence between samples in chain’). Izvistia Imperatorskoi Akad. Nauk Bull. L’Academie Imp. Sci. StPetersbourg 7, 153–162 (1913).
21. Shannon, C. E. A mathematical theory of communication. Bell Syst. Tech. J. 27, 379–423 (1948).
22. Baker, J. K. Stochastic modeling for automatic speech understanding. in Speech recognition: invited papers presented at the 1974 IEEE symposium (ed. Reddy, D. R.) (Academic Press, 1975).
23. Jelinek, F. Continuous speech recognition by statistical methods. Proc. IEEE 64, 532–556 (1976).
24. Jurafsky, D. & Martin, J. H. N-gram language models. in Speech and language processing: An introduction to natural language processing, computational linguistics, and speech recognition (Pearson Prentice Hall, 2009).
25. Vaswani, A. et al. Attention is all you need. 31st Conf. Neural Inf. Process. Syst. (2017).
26. Bommasani, R. et al. On the opportunities and risks of foundation models. Preprint at http://arxiv.org/abs/2108.07258 (2022).
27. Gao, L. et al. The Pile: An 800GB dataset of diverse text for language modeling. Preprint at http://arxiv.org/abs/2101.00027 (2020).
28. Devlin, J., Chang, M.-W., Lee, K. & Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. Preprint at http://arxiv.org/abs/1810.04805 (2019).
29. Kojima, T., Gu, S. S., Reid, M., Matsuo, Y. & Iwasawa, Y. Large language models are zero-shot reasoners. Preprint at http://arxiv.org/abs/2205.11916 (2023).
30. Fairburn, C. G. & Patel, V. The impact of digital technology on psychological treatments and their dissemination. Behav. Res. Ther. 88, 19–25 (2017).
31. Fisher, A. J. et al. Open trial of a personalized modular treatment for mood and anxiety. Behav. Res. Ther. 116, 69–79 (2019).
32. Fan, X. et al. Utilization of self-diagnosis health chatbots in real-world settings: Case study. J. Med. Internet Res. 23, e19928 (2021).
33. Coghlan, S. et al. To chat or bot to chat: Ethical issues with using chatbots in mental health. Digit. Health 9, 1–11 (2023).
34. Beatty, C., Malik, T., Meheli, S. & Sinha, C. Evaluating the therapeutic alliance with a free-text CBT conversational agent (Wysa): A mixedmethods study. Front. Digit. Health 4, 847991 (2022).
35. Lin, B., Bouneffouf, D., Cecchi, G. & Varshney, K. R. Towards healthy AI: Large language models need therapists too. Preprint at http://arxiv.org/abs/2304.00416 (2023).
36. Weidinger, L. et al. Ethical and social risks of harm from language models. Preprint at http://arxiv.org/abs/2112.04359 (2021).
37. Bender, E. M., Gebru, T., McMillan-Major, A. & Shmitchell, S. On the dangers of stochastic parrots: Can language models be too big? In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency 610–623 (ACM, 2021). https://doi.org/10.1145/3442188.3445922.
38. Chamberlain, J. The risk-based approach of the European Union’s proposed artificial intelligence regulation:Some comments from a tort law perspective. Eur. J. Risk Regul. 14, 1–13 (2023).
39. Norden, J. G. & Shah, N. R. What AI in health care can learn from the long road to autonomous vehicles. NEJM Catal. Innov. Care Deliv. https://doi.org/10.1056/CAT.21.0458 (2022).
40. Sedlakova, J. & Trachsel, M. Conversational artificial intelligence in psychotherapy: A new therapeutic tool or agent? Am. J. Bioeth. 23, 4–13 (2023).
41. Gearing, R. E. et al. Majoringredients of fidelity: A review and scientific guide to improving quality of intervention research implementation. Clin. Psychol. Rev. 31, 79–88 (2011).
42. Wiltsey Stirman, S. Implementing evidence-based mental-health treatments: Attending to training, fidelity, adaptation, and context. Curr. Dir. Psychol. Sci. 31, 436–442 (2022).
43. Waller, G. Evidence-based treatment and therapist drift. Behav. Res. Ther. 47, 119–127 (2009).
44. Flemotomos, N. et al. “Am I a good therapist?” Automated evaluation of psychotherapy skills using speech and language technologies. CoRR, Abs, 2102 (10.3758) (2021). 45. Zhang, X. et al. You never know what you are going to get: Large-scale assessment of therapists’ supportive counseling skill use. Psychotherapy https://doi.org/10.1037/pst0000460 (2022). 46. Goldberg, S. B. et al. Machine learning and natural language processing in psychotherapy research: Alliance as example use case. J. Couns. Psychol. 67, 438–448 (2020).
47. Wiltsey Stirman, S. et al. A novel approach to the assessment of fidelity to a cognitive behavioral therapy for PTSD using clinical worksheets: A proof of concept with cognitive processing therapy. Behav. Ther. 52, 656–672 (2021).
48. Raviola, G., Naslund, J.A.,Smith, S. L. &Patel, V. Innovative models in mental health delivery systems: Task sharing care with non-specialist providers to close the mental health treatment gap. Curr. Psychiatry Rep. 21, 44 (2019).
49. American Psychological Association. Guidelines for clinical supervision in health service psychology. Am. Psychol. 70, 33–46 (2015).
50. Cook, S. C., Schwartz, A. C. & Kaslow, N. J. Evidence-based psychotherapy: Advantages and challenges. Neurotherapeutics 14, 537–545 (2017).
51. Leichsenring, F., Steinert, C., Rabung, S. & Ioannidis, J. P. A. The efficacy of psychotherapies and pharmacotherapies for mental disorders in adults: An umbrella review and meta‐analytic evaluation of recent meta‐analyses. World Psych. 21, 133–145 (2022). https://doi.org/10.1038/s44184-024-00056-z Article npj Mental Health Research | (2024)3:12 10
52. Cuijpers, P., van Straten, A., Andersson, G. & van Oppen, P. Psychotherapy for depression in adults: A meta-analysis of comparative outcome studies. J. Consult. Clin. Psychol. 76, 909–922 (2008).
53. Morris, Z. S., Wooding, S. & Grant, J. The answer is 17 years, what is the question: Understanding time lags in translational research. J. R. Soc. Med. 104, 510–520 (2011). 54. Chekroud, A. M. et al. The promise of machine learning in predicting treatment outcomes in psychiatry. World Psych. 20, 154–170 (2021).
55. Kazdin, A. E. Mediators and mechanisms of change in psychotherapy research. Annu. Rev. Clin. Psychol. 3, 1–27 (2007).
56. Angelov, P. P., Soares, E. A., Jiang, R., Arnold, N. I. & Atkinson, P. M. Explainable artificial intelligence: An analytical review. WIREs Data Min. Knowl. Discov. 11, (2021).
57. Kelley, T. L. Interpretation of Educational Measurements. (World Book, 1927).
58. vanBronswijk,S. C. et al.Precision medicine forlong-term depression outcomes using the Personalized Advantage Index approach: Cognitive therapy or interpersonal psychotherapy? Psychol. Med. 51, 279–289 (2021).
59. Scala, J. J., Ganz, A. B. & Snyder, M. P. Precision medicine approaches to mental health care. Physiology 38, 82–98 (2023).
60. Chorpita, B. F., Daleiden, E. L. & Weisz, J. R. Identifying and selecting the common elements of evidence based interventions: A distillation and matching model. Ment. Health Serv. Res. 7, 5–20 (2005).
61. Chambless, D. L. & Hollon, S. D. Defining empirically supported therapies. J. Consult. Clin. Psychol. 66, 7–18 (1998).
62. Tolin, D. F., McKay, D., Forman, E. M., Klonsky, E. D. & Thombs, B. D. Empirically supported treatment: Recommendations for a new model. Clin. Psychol. Sci. Pract. 22, 317–338 (2015). 63. Lilienfeld, S. O. Psychological treatments that cause harm. Perspect. Psychol. Sci. 2, 53–70 (2007).
64. Wasil, A. R., Venturo-Conerly, K. E., Shingleton, R. M. & Weisz, J. R. A review of popular smartphone apps for depression and anxiety: Assessing the inclusion of evidence-based content.Behav.Res. Ther. 123, 103498 (2019).
65. Torous, J. B. et al. A hierarchical framework for evaluation and informed decision making regarding smartphone apps for clinical care. Psychiatr. Serv. 69, 498–500 (2018).
66. Gunasekar, S. et al. Textbooks are all you need. Preprint at http://arxiv.org/abs/2306.11644 (2023).
67. Wilhelm, E. et al. Measuring the burden of infodemics: Summary of the methods and results of the Fifth WHO Infodemic Management Conference. JMIR Infodemiology 3, e44207 (2023).
68. Creed, T. A. et al. Knowledge and attitudes toward an artificial intelligence-based fidelity measurement in community cognitive behavioral therapy supervision. Adm. Policy Ment. Health Ment. Health Serv. Res. 49, 343–356 (2022).
69. Aktan, M. E., Turhan, Z. & Dolu, İ. Attitudes and perspectives towards the preferences for artificial intelligence in psychotherapy. Comput. Hum. Behav. 133, 107273 (2022).
70. Prescott, J. & Hanley, T. Therapists’ attitudes towards the use of AI in therapeutic practice: considering the therapeutic alliance. Ment. Health Soc. Incl. 27, 177–185 (2023).
71. American Psychiatric Association. Diagnostic and Statistical Manual of Mental Disorders. (2013).
72. Yogatama, D., De Masson d’Autume, C. & Kong, L. Adaptive semiparametric language models. Trans. Assoc. Comput. Linguist 9, 362–373 (2021).
73. Stanley, B. & Brown, G. K. Safety planning intervention: A brief intervention to mitigate suicide risk. Cogn. Behav. Pract. 19, 256–264 (2012).
74. Behzadan, V., Munir, A. & Yampolskiy, R. V. A psychopathological approach to safety engineering in AI and AGI. Preprint at http://arxiv.org/abs/1805.08915 (2018).
75. Lambert, M. J. & Harmon, K. L. The merits of implementing routine outcome monitoring in clinical practice. Clin. Psychol. Sci. Pract. 25, (2018).
76. Kjell, O. N. E., Kjell, K. & Schwartz, H. A. AI-based large language models are ready to transform psychological health assessment. Preprint at https://doi.org/10.31234/osf.io/yfd8g (2023).
77. First, M. B., Williams, J. B. W., Karg, R. S. & Spitzer, R. L. SCID-5-CV: Structured Clinical Interview for DSM-5 Disorders: Clinician Version. (American Psychiatric
文章来自微信公众号“追问nextquestion” 作者“追问nextquestion”



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
