# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
当你开始任何客户项目时,最常见的问题之一是:“我应该使用哪个模型?” 这个问题没有直接的答案,它是一个过程。在本博客中,我们将解释这个过程,这样下次客户问你这个问题时,你可以与他们分享这份文档。
选择正确的模型,无论是GPT4 Turbo、Gemini Pro、Gemini Flash GPT-4o还是较小的选项如GPT-4o-mini,都需要在准确性、延迟和成本之间进行权衡。
核心原则
选择模型的原则很简单:
首先优化准确性:在达到准确性目标之前,始终优化准确性。
其次优化成本和延迟:然后目标是在尽可能便宜和快速的模型中保持准确性。
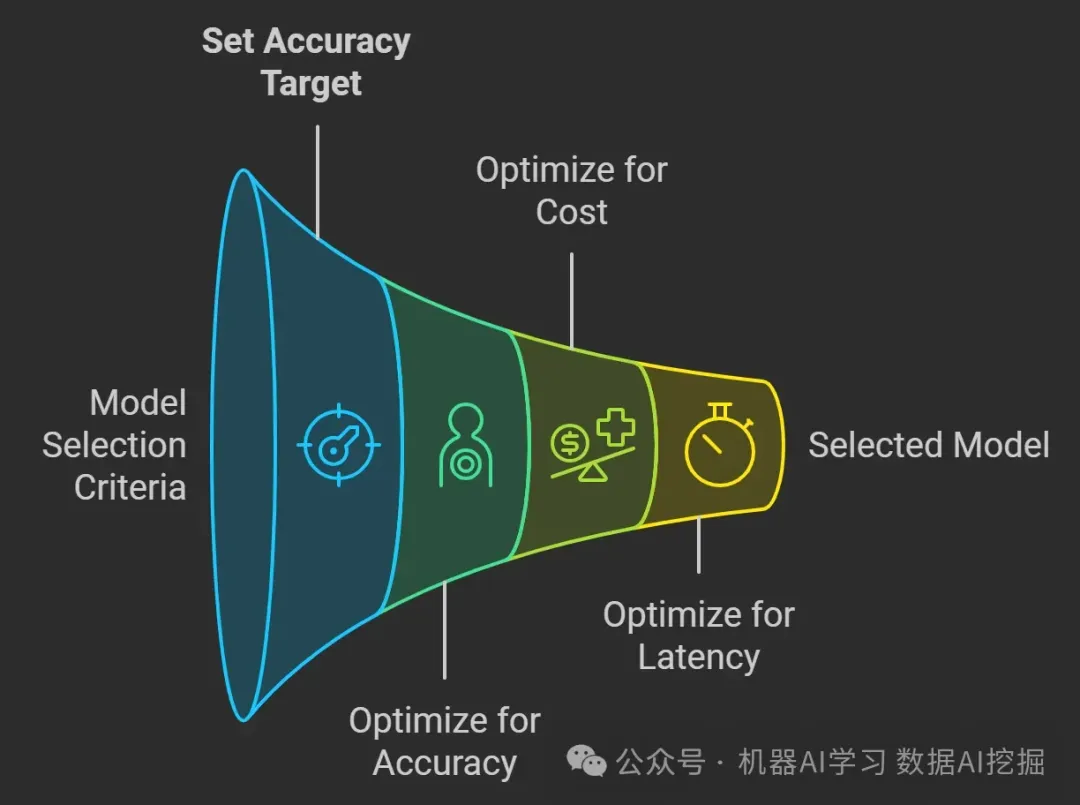
设定明确的准确性目标:定义对于你的使用场景来说什么样的准确性是“足够好”。例如:首次互动中90%的客服通话被正确分类
开发评估数据集:创建一个数据集来衡量模型的表现。例如:收集100个交互示例,包括用户请求、模型分类、正确的分类以及准确性
使用最强大的模型:从最强大的模型开始,以实现你的准确性目标。记录响应以供将来使用。
优化准确性:使用检索增强生成,然后进行微调以确保一致性和行为
收集供将来使用的数据:收集提示和完成对,用于评估、少量样本学习或微调。这种做法,被称为提示烘焙,有助于为将来使用生成高质量的示例。

成本和延迟被视为次要因素,因为如果模型无法达到你的准确率目标,那么这些问题就无关紧要了。然而,一旦你有了一个适用于你用例的模型,你可以采取以下两种方法之一:
与一个更小的模型进行零样本或少样本对比:用一个更小、更便宜的模型替换现有模型,并测试其在较低成本和延迟下的准确率是否得以保持。
模型蒸馏:使用在优化准确率过程中收集的数据对一个小模型进行微调。
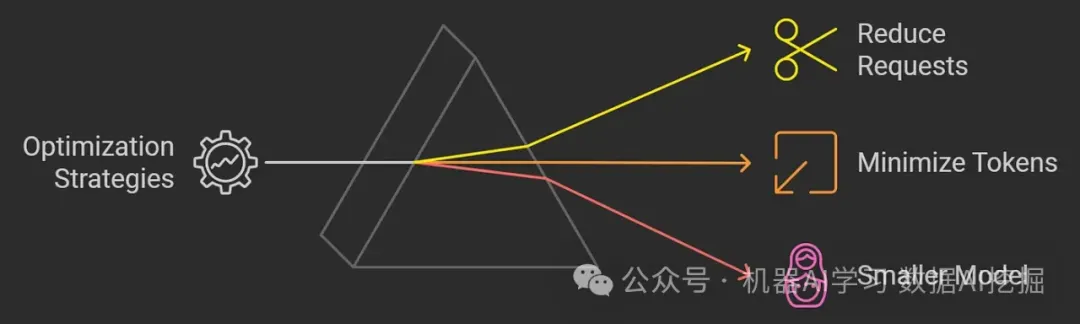
成本和延迟通常是相互关联的;减少令牌和请求通常会导致更快的处理速度。

这里需要考虑的主要策略是:
减少请求:限制完成任务所需的请求数量。
最小化令牌:降低输入令牌的数量,并优化模型输出的长度。
选择较小的模型:使用在降低成本和延迟的同时保持准确性的模型。
来自开放AI的实际示例
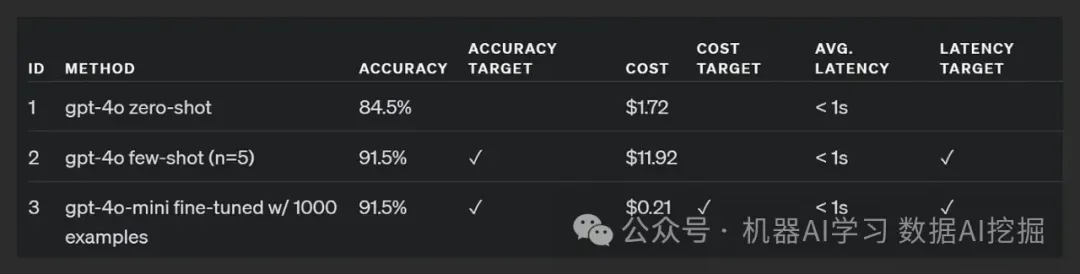
为了展示这些原则,他们开发了一个假新闻分类器,目标指标如下:
准确性:实现90%的正确分类
成本:每1,000篇文章花费少于5美元
延迟:保持每篇文章的处理时间在2秒以内
实验
他们进行了三个实验以达到目标:
零样本:使用GPT-4o和基本提示处理了1,000条记录,但未达到准确性目标。
少量样本学习:包含了5个少量样本示例,达到了准确性目标但因更多的提示令牌而超出了成本。
微调模型:使用1,000个带标签的示例对GPT-4o-mini进行了微调,达到了所有目标,具有相似的延迟和准确性但成本显著降低。
首先优化准确性,然后是成本和延迟的优化。
这个过程很重要——你通常不能直接跳到微调阶段,因为你不知道微调是否是你所需要的优化的正确工具,或者你没有足够的标注样本。
使用一个准确的大模型来达到你的准确性目标,并整理一个好的训练集——然后通过微调来使用更小、更高效的模型。
文章来自于“机器AI学习 数据AI挖掘”,作者“机器AI学习 数据AI挖掘”。




【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
