# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
开源大模型这个圈子,真是卷到不行——
国内最新纪录来了,直奔千亿量级,达到1026亿。
千亿参数、全面开源、无需授权可商用,GitHub均可全面下载使用,就问你激动不激动!
这便是来自浪潮信息最新的开源大模型,源2.0;话不多说,直接来看下测试结果~
在业界公开的数据集上,源2.0与GPT-4、Llama 2同台竞技的结果如下:
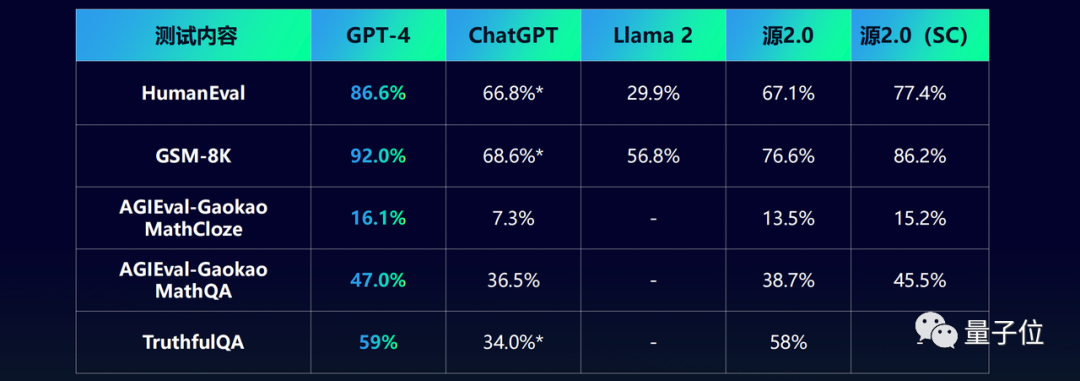
△采用与源2.0相同的输入调用ChatGPT测试的结果,测试时间是11月
不难看出,在代码、数学、事实问答等各项的成绩,除了GPT-4(闭源)之外,源2.0均处于领先地位。
而且浪潮信息此次还一口气发布了三款型号的模型,均完全开源:
纵观今年百模大战的下半场,开源圈可谓是热闹非凡,每隔一段时间便会有新的开源大模型杀出重围。
但浪潮信息所开源的源2.0,不仅是第一个触及千亿参数规模,更是做到了发布即彻底开源。
那么它能够做到如此的底气又是什么?
首先我们进一步来看下源2.0的具体表现。
例如在多轮对话和知识问答方面,我们先给它投喂一句:
请解释一下“乌鸦反哺”的涵义。
源2.0便可精准答出这个成语的意思和所形容的内容。

在此基础之上,我们继续让它用这个成语作诗,源2.0也是信手拈来:

由此可见,在知识问答、多轮对话领域,源2.0是完全能够hold得住的。
我们继续加大难度,上数学题——求解曲线某点处的切线方程!

从源2.0的作答中,我们可以看到它不仅是给出正确答案那么简单,更是将解题步骤一点一点地详细罗列出来。
再来一道,答案同样是非常有逻辑且清晰。

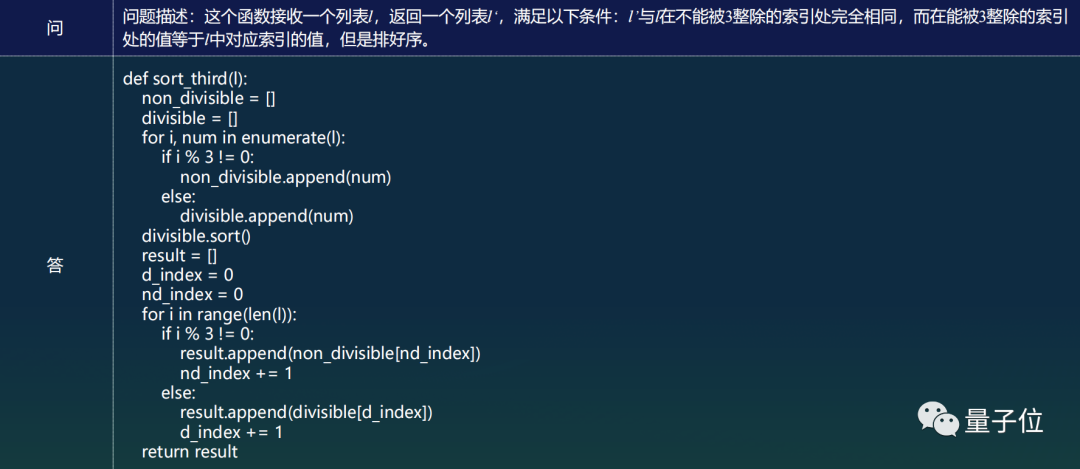
在生成代码方面,源2.0亦是不在话下:
上述的案例也对应了源2.0在各项国际评测中的高分,那么源2.0又是如何做到的呢?
我们发现,此次浪潮信息在把大语言模型开源之际,也将背后的相关技术论文也一并亮了出来。

纵观这篇论文,我们可以将浪潮信息的改进归结为三大方面。
“数据质量的高低直接决定大语言模型输出结果的好坏”,这一点是已然业界达成共识。
因此,相比于源1.0版本,浪潮信息将此前占比最大的网页数据(CC)的比重降低,增加了百科、书籍、期刊数据,同时还引入了代码和数学数据。
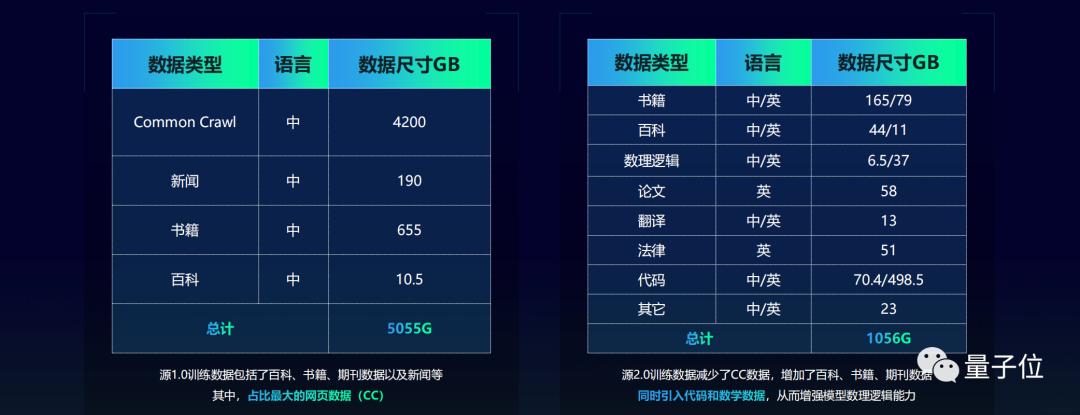
这便是源2.0能在数学逻辑能力上大幅提升的原因之一。
与此同时,浪潮信息还在数据增强和合成方面使出了杀手锏——造大语言模型,也“利用”大语言模型。
具体来说就是用大语言模型作为训练数据生成器,构建高质量数学、代码合成数据集,即用于源2.0的预训练中,也用于微调。
其目的就是生成高质量的指令数据,从而降低人工标注成本大、质量不可控的因素。
在算法方面,源2.0采用了一种新型Attention结构:局部注意力过滤增强机制(Localized Filtering-based Attention,LFA)。
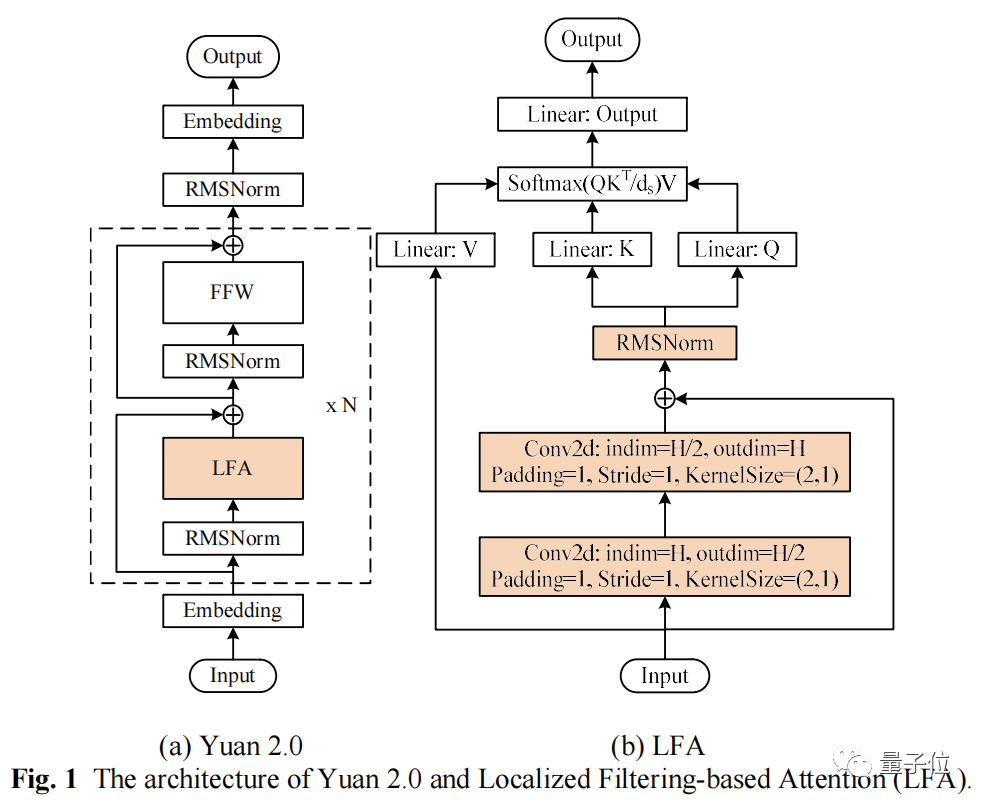
传统Attention机制是对所有输入文字一视同仁,不假设自然语言相邻词之间更强的语义关联。
比如“我想吃中国菜”这个句子,分词后变成“我/想/吃/中国/菜”。
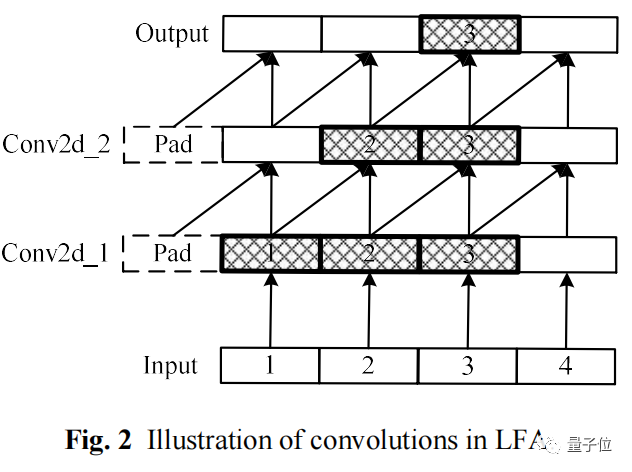
传统Attention机制会同等对待这6个token,而LFA的升级在于,会假设相邻词间具有更强的依赖。
通过强化相邻词之间的关联,然后再计算全局管关联,能更好处理自然语言的语序排列问题,对中文语境的关联语义理解更准确。
在消融实验中,相比传统注意力结构,LFA模型精度提高3.53%。
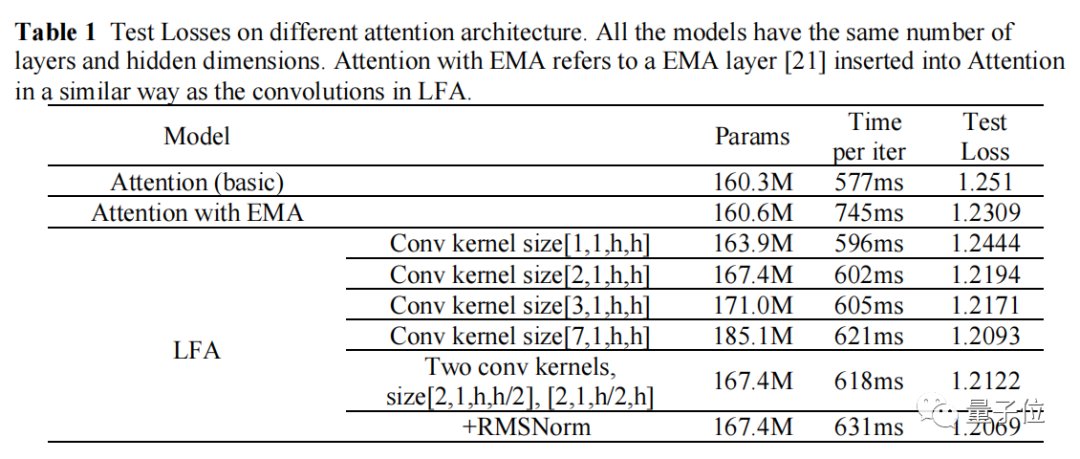
同时经过工程化验证,LFA算法在提升模型精度的同时,有效降低了模型参数量,进而减小内存开销,实现降本增效。
基于LFA的模型结构,源2.0-102B模型训练288B的Tokens,最终Training Loss为1.18;源1.0-245B模型训练180B的Tokens,最终Training Loss为1.64.从源1.0到源2.0,Training Loss降低28%。
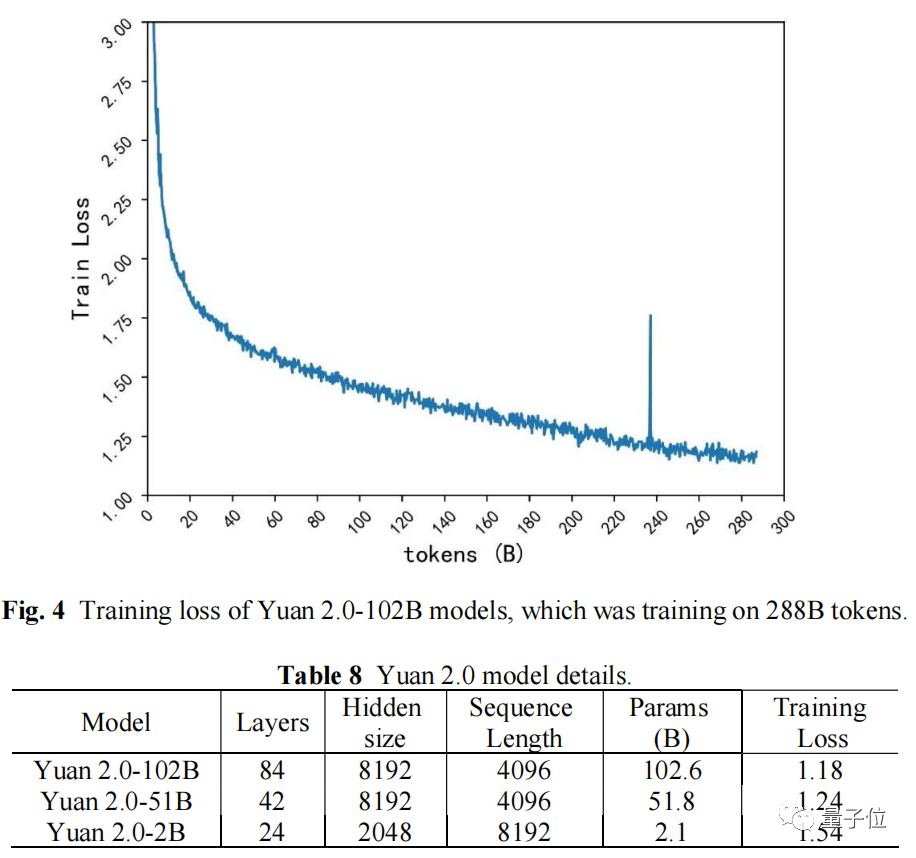
相较于源1.0的计算方案,源2.0也进行了升级。
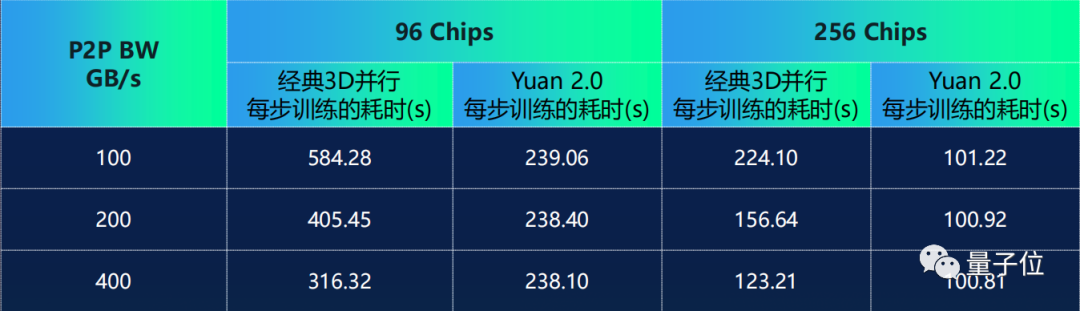
它在3D并行策略的基础上,提出了非均匀流水并行+优化器参数并行(ZeRO)+数据并行的策略。
采用源2.0的分布式训练算法,性能几乎不随带宽变化(0.4%),模型预测的源2.0模型每步计算总耗时与实测值的相对误差仅为3%。
而在经典3D并行中,当芯片之间连接的带宽从400GB/s降低至100GB/s,性能会降低约85%。
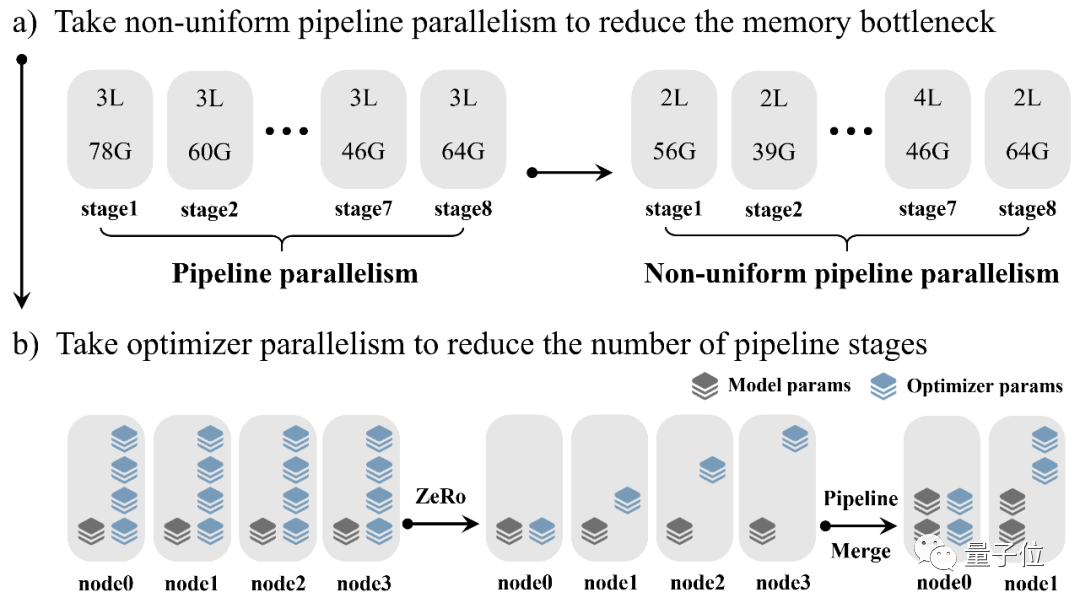
具体方案中,非均匀流水并行,能有效环节流水线头部与尾部的内存瓶颈。
优化器参数并行,能进一步降低流水线每个阶段的参数量,通信复杂度与数据并行类似。
综上,源2.0的面世还伴随着算法、数据、计算三方面更底层的创新。
随着源2.0的开源、论文上线,这些创新也能直接向整个社区输出。
浪潮信息此次推出了开源共训计划。
为了让开源模型更符合开发者应用需求,这个计划支持开发者提出自己的应用或场景需求,由浪潮信息来准备训练数据并对源大模型进行增强训练,训练后的模型依旧在社区开源。
开发者提出的需求没有具体格式要求,只要表达清楚应用场景、对大模型能力的需求以及1~2条示例即可。

不过一直以来,浪潮信息在行业内的角色定位都更偏向于算力基础设施方。
自源1.0之后,此时浪潮信息的“新一轮大模型入世之道”剑指何方?而它为什么能带来这些创新?
实际上,源2.0大模型是浪潮信息AIGC整体规划的一部分。
作为算力行业龙头玩家,浪潮信息通过开放共享自身的算力平台、技术、实践经验,构建算力基础设施+算法基础设施,从技术和基础设施支撑方面,降低AI开发壁垒和门槛。
换言之,浪潮信息不仅提供大模型所需的算力资源,更提供大模型开发应用的一系列服务。
为此浪潮信息持续布局基础算法、训练加速、算力调度管理等方面。源2.0大模型的推出,正是整体战略中的最新举措。
2021年浪潮信息推出“源1.0”大模型,成为国内最早布局大模型的企业之一。
“源1.0”是中文AI巨量模型,规模达2457亿参数,一度问鼎全球最大单体大模型。
同时团队还完成了5TB高质量中文数据集清洗工作,建立了完整的从公开数据爬取到数据清洗、格式转化、数据质量评估的完整流程和工具链。
随后,“源1.0”落地南京智算中心,也成为国内首个(城市级)开放提供领先的智能大模型服务。
过去2年中,浪潮信息也不断向行业输出大模型开发应用的能力。
比如助力网易伏羲中文预训练大模型“玉言”登顶中文语言理解权威测评基准CLUE分类任务榜单,并在多项任务上超过人类水平。

2022年底ChatGPT趋势爆发,一时之间,百模兴起。
大模型的算力需求成为今年业内最热门话题之一。
无论是想要炼成一个大模型、提升模型智能水平,还是扩大应用,都和算力投入直接相关,业内也一度兴起了“囤算力”热潮。
但拥有足够算力只是第一步,怎么用好才是更关键的,也更困扰行业。
大模型训练过程比传统分布式训练更复杂,训练周期长达数月,容易出现训练中断、集群计算效率低、故障频发且复杂等问题。
作为算力行业龙头玩家,浪潮信息在今年8月推出了大模型智算软件栈OGAI“元脑生智”。
它能提供AI Infra能力,提供从集群系统环境部署到算力调度保障和大模型开发管理的全栈全流程的软件,从而大幅提升大模型算力效率。
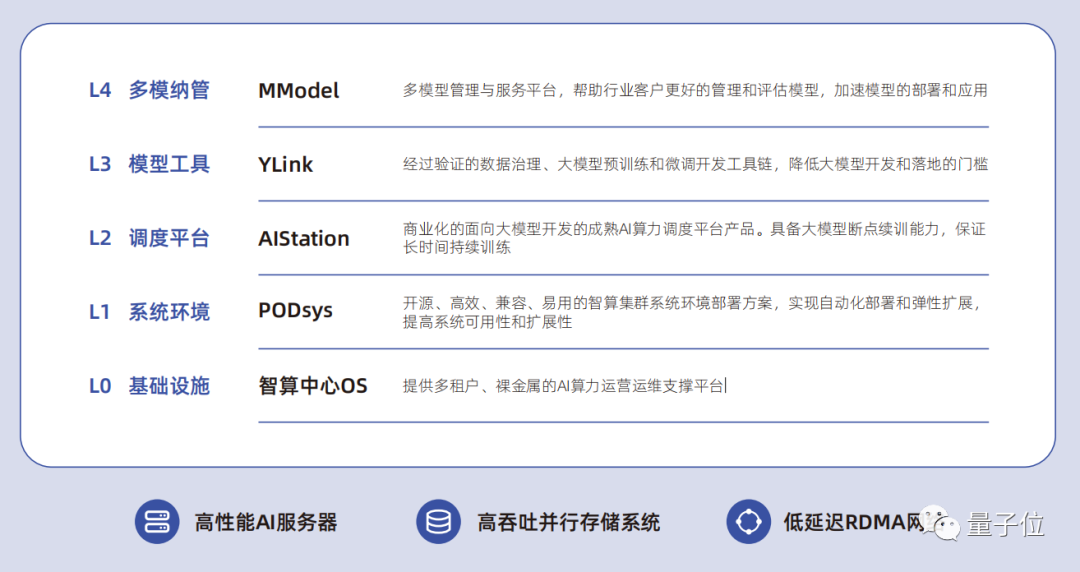
AI Infra的本义是AI基础设施,但目前业内更倾向于将其定义为软件层面。浪潮信息的OGAI(Open GenAI Infra)处于智算硬件之上、AI应用之下的软件层,强调系统环境部署、算力调度保障、模型开发管理三方面能力。
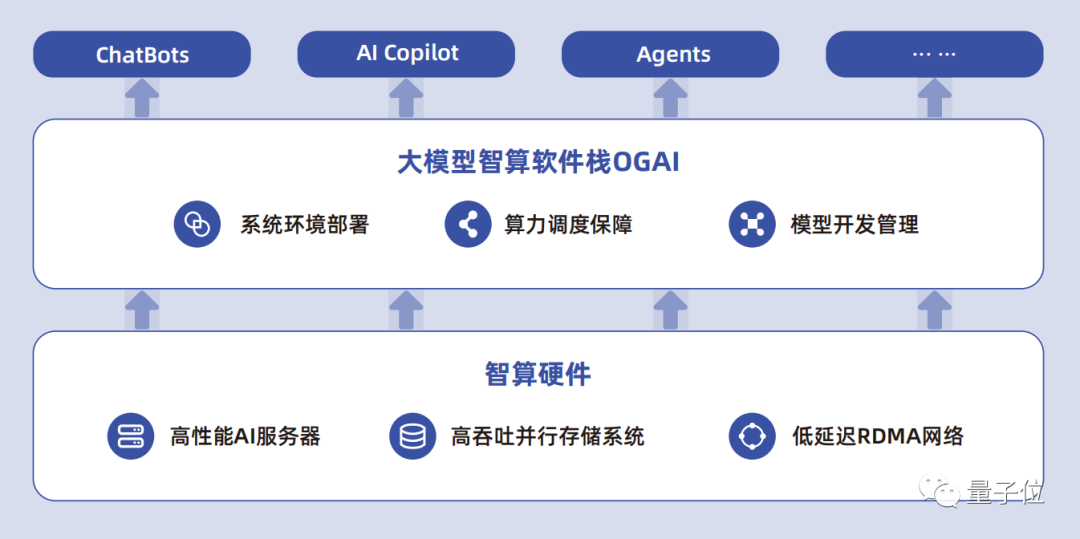
OGAI由5层架构组成,从L0到L4分别对应于基础设施层的智算中心OS产品、系统环境层的PODsys产品、调度平台层的AIStation产品、模型工具层的YLink产品和多模纳管层的MModel产品。
能实现自动化部署和弹性扩展,具备大模型断点续训能力,提供经过验证的数据治理、大模型预训练和微调开发工具,还能对多模型进行管理评估,加速模型部署和应用。
这些能力组合,可以解决最备受关注的三方面问题:
在实际能力上,OGAI支持断点续训恢复、平均故障处理时间小于5分钟;千亿模型千卡集群平均计算峰值效率提升54%;支持多元算力,可稳定接入40+多元算力。PODsys还是业内首个开源的AI算力集群系统环境部署方案。

至此,浪潮信息不仅积累了大模型开发能力,还成功向行业输出大模型训练部署管理经验,加速整个生成式AI浪潮的演进速度。
如今推出源2.0正是例证,它诠释了“如何让算力更好地匹配智能涌现”。
用最先进大模型作为底座,从垂直场景针对性切入,构建技能模型、进而落地行业模型,也是当前业内已经确定的发展路径,是走向AGI的必经之路。
显然,源2.0发布的意义,已经不局限于“一个新模型诞生”。
对于浪潮信息自身而言,源2.0的推出意味着智算力的再次升级。
大模型趋势的核心,还是要看最终能给产业带来何种影响,即大模型的应用落地。
源1.0在To B领域的深度融合,已经验证了路线的正确性。源2.0的推出,便是在此前基础上进一步升级,之后可以提供更加满足生成式AI趋势的模型、算力、应用需求。
对于大模型趋势而言,源2.0给行业增加了一个基座的选择。
目前业内已经达成一个共识,在“百模大战”初期,百花齐放是利好的。这能更大程度上释放生产力,推动行业发展。
而且源2.0在算法、计算、数据上的创新,也向前推动了技术发展。
比如LFA的创新,给Transformer架构上限挖掘提出了一种参考;非均匀流水并行+优化器参数并行(ZeRO)+数据并行策略的提出,改进了源2.0的计算,也为行业提出了缓解内存/计算瓶颈方案。
对于全行业而言,源2.0全面开源,让生态更加繁荣。
优秀开源模型是吸引开发者、繁荣生态的关键因素,它能让创新进行指数级增长,避免“重复造轮子”问题,加速创新迭代速度,给行业提供扎实底座和成长土壤。

最后,随着源2.0的推出,浪潮信息的AIGC战略版图变得更加清晰,也向业内展示了从算力角度出发,可以为行业提供怎样的解决方案。
目前,国内“百模大战”开始进入下半场。
后续还会有新模型入场,已发布模型也在继续不断扩大规模,同时推理需求也开始加速增长。
整体市场的算力需求变得更加复杂多样化。
在这样的激烈变化之下,国产算力供应方还会向行业交出哪些答卷,值得关注。


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
