# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在智慧城市和大数据时代背景下,人类轨迹数据的分析对于交通优化、城市管理、物流配送等关键领域具有重要意义。然而,现有的轨迹相关模型往往受限于特定任务、区域依赖、轨迹数据规模和多样性困乏等问题,限制了模型的泛化能力和实际应用范围。近日,来自于香港科技大学(广州)、南方科技大学、香港城市大学的联合研究团队整理了首个全球大规模轨迹数据集 WorldTrace,并基于该数据集训练了首个世界轨迹基础大模型 UniTraj,为交通领域内构建通用时空智能提供了一种全新的思路。
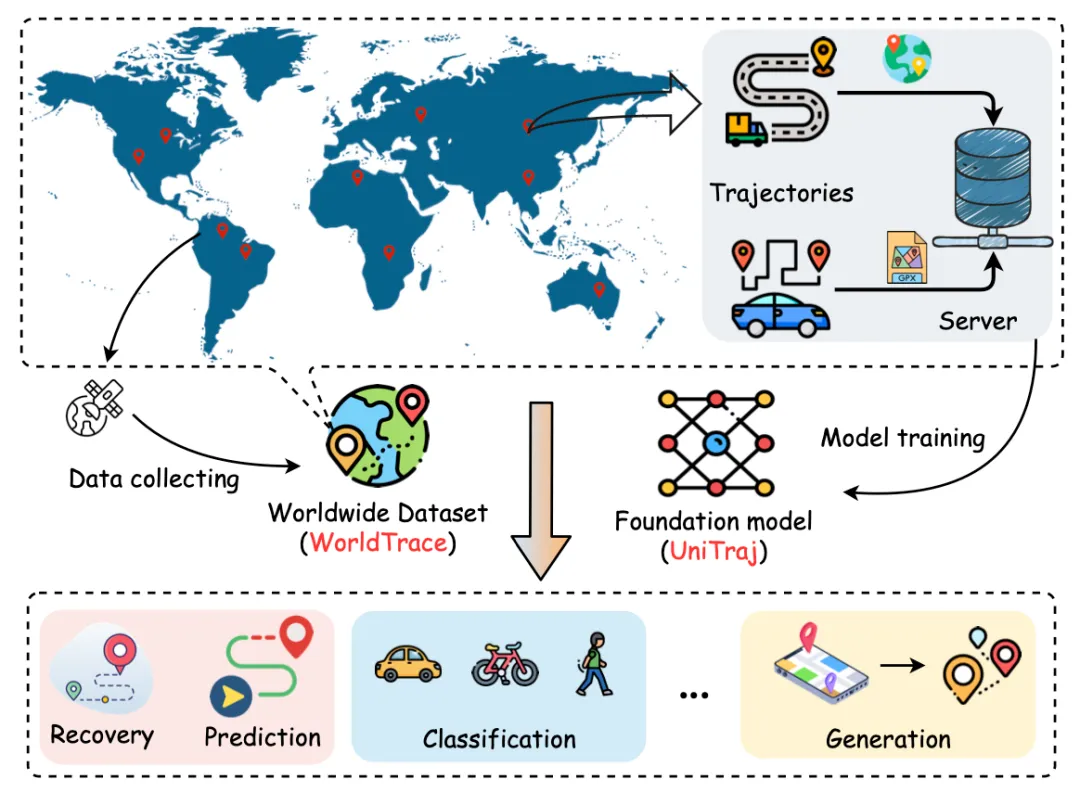
研究团队提出了轨迹基础模型的构建范式,旨在通过其模型架构设计和数据集支撑的流程,克服现有方法的局限性,实现跨任务、跨区域的泛化能力,并在不同数据质量下保持鲁棒性。具体来说,研究团队首先收集了一个全球范围的 WorldTrace 轨迹数据集,涵盖 70 个国家和地区,包括 245 万条轨迹和十亿级别的轨迹数据点。这为构建轨迹基础模型提供了充足且丰富的数据支持。进一步,研究团队设计并预训练了 UniTraj 这样一个通用的轨迹基础模型结构,并集成了多种重采样和掩码策略,能够有效支撑不同区域、任务和数据质量的需要。

论文地址:https://arxiv.org/pdf/2411.03859
为了解决上述问题,这项研究开创了构建轨迹基础模型的新范式,分别从数据准备和模型设计两个方面进行展开。
该研究最显著的贡献是构建了首个大规模、高质量、全球范围分布的轨迹数据集,名为 WorldTrace,并首次实现了全球范围的轨迹数据收集与整合。
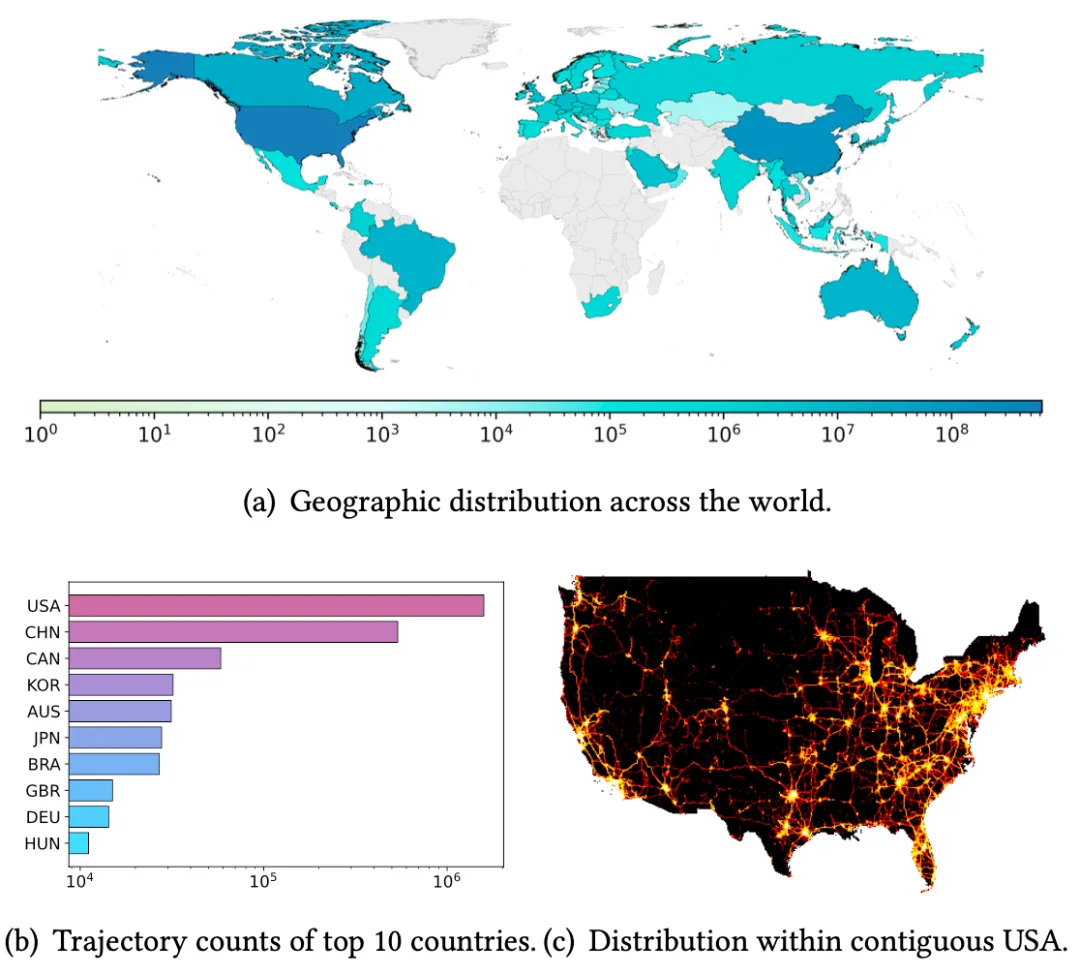
上图展示了 WorldTrace 数据集的地理分布,该数据集在北美、东亚和欧洲部分地区有较为密集分布,涵盖了发达和新兴经济地区,其中美国、中国提供了较多的轨迹数据。从地理分布上来说,这突显了数据集中的轨迹模式的多样性,能够反应不同交通基础设施和地理环境。此外,通过美国本土的数据密度也进一步展示了主要公路网络和城市中心的高分辨率覆盖。进一步说明了该数据在开发独立于区域和通用轨迹基础模型的潜力。
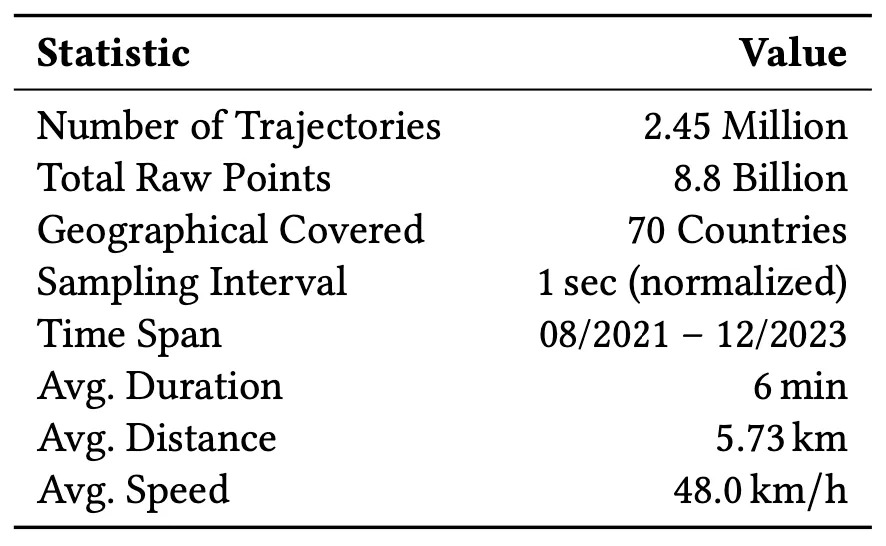
通过作者进一步对原始数据进行规范和校正处理,表中统计了这项研究使用的数据的主要特征。在轨迹规模上,可以看到 WorldTrace 主要包含 245 万条轨迹,8.8 亿个采样轨迹点 (采样频率规范到 1 秒后),并覆盖 70 了个国家和地区。在数据质量上,WorldTrace 数据集的时间跨度从 2021 年 8 月开始,一直持续到 2023 年 12 月,提供了长时间范围和及时的数据样本,能够进一步增强该数据集的应用价值。
构建轨迹基础模型 UniTraj
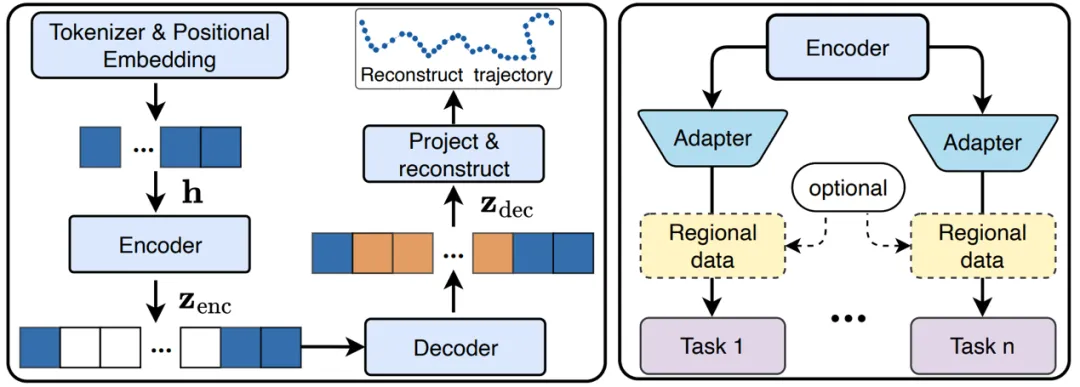
在模型的架构设计上,UniTraj 采用了灵活的编码器 - 解码器架构,为了提升模型的计算效率、鲁棒性和对各种数据质量的适应能力,作者在模型训练过程中进一步集成了一系列的重采样策略和掩码策略。
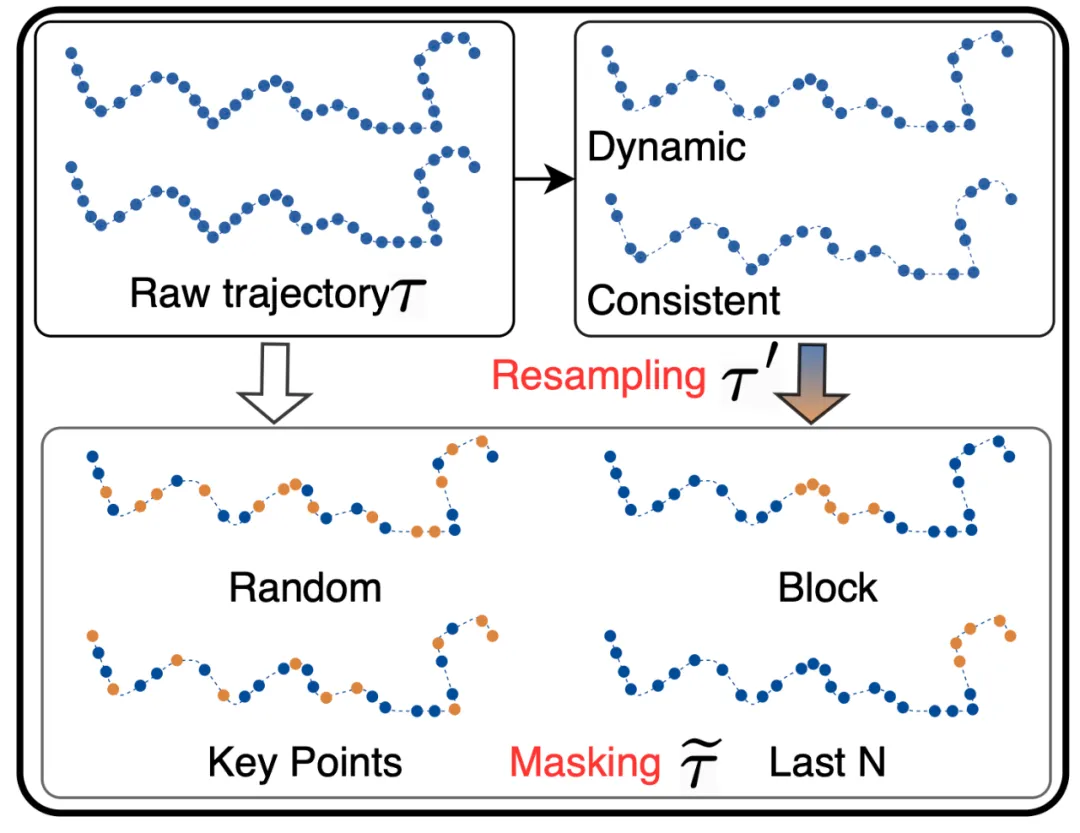
重采样策略
这项研究主要设计了两种重采样策略:
掩码策略
由于 UniTraj 使用重构式预训练的方法来提升模型对轨迹局部和全局模式建模能力。在预训练过程中,作者设计了 4 种掩码策略,而模型的目标是恢复这些被掩蔽的轨迹点,从而帮助模型更好地理解和捕捉轨迹序列的时空关系。
模型架构
在模型架构设计方面,UniTraj 首先将重采样和掩码处理后的轨迹转换为结构化的嵌入,并利用 Transformer 块和旋转位置编码(RoPE)来捕捉轨迹中的时空关系。编码器负责学习可见点的压缩表示,而解码器则基于这些表示来重建被掩码的点,实现轨迹的精确重建和预测。对于训练过程,模型使用重建目标进行训练,旨在最小化预测点和原始点之间的差异。在推理和下游任务应用中,预训练的 UniTraj 编码器可以作为通用特征提取器,通过简单的适配器训练,即可支持多种轨迹相关的分析任务,如分类、预测和异常检测等。
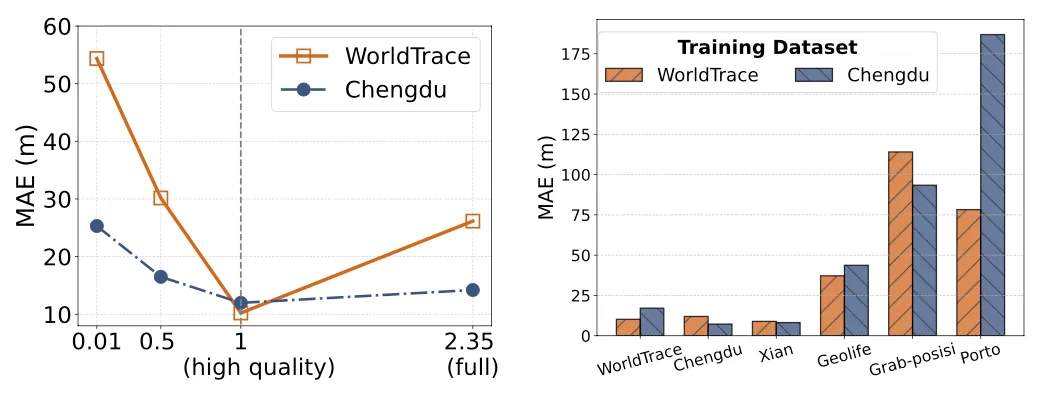
为了测试 UniTraj 模型的性能,研究团队设计了一系列实验,旨在评估模型在处理真实世界轨迹数据时的准确性和泛化能力。研究团队选择了多个具有不同地理覆盖、数据质量和采样率的真实世界轨迹数据集进行实验。这些数据集包括但不限于 WorldTrace 数据集,以及其他公开可用的数据集,如成都、西安、GeoLife 等。实验设计考虑了零样本和少样本学习场景,以评估模型在未见过的数据上的适应性。实验主要围绕以下几个方面进行:
1. 任务适用性分析:评估 UniTraj 在轨迹恢复、预测、分类和生成等不同任务上的表现,以及其在零样本和少样本学习场景中的适应性。

2. 数据集研究:比较 UniTraj 在 WorldTrace 数据集和其他公开数据集上的训练效果,分析数据规模和质量对模型性能的影响。
3. 模型研究:探讨 UniTraj 模型中不同组件和参数设置对性能的影响,包括编码器块的数量、掩码比例等。
UniTraj 这项研究提出了数据 + 模型的基础模型构建范式。在数据准备方面,其首次构建了一个全球范围的轨迹数据集,并且提供了大规模和高质量的轨迹数据用于训练。在模型设计方面,其通过重采样和掩码策略,集成轨迹处理模块和灵活的编码器 - 解码器架构,有效地捕捉了轨迹数据中的复杂时空依赖性以应对各种不同的数据质量。这一模型的提出,为处理大规模、多样化的轨迹数据提供了新的工具,带来了新的思路。
文章来自于“机器之心”,作者“机器之心编辑部”。




