# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
目前,通义千问开源全家桶已经有了 18 亿、70 亿、140 亿、720 亿参数量的 4 款基础开源模型,以及跨语言、图像、语音等多种模态的多款开源模型。
「Qwen-72B 模型将于 11 月 30 日发布。」前几天,X 平台上的一位网友发布了这样一则消息,消息来源是一段对话。他还说,「如果(新模型)像他们的 14B 模型一样,那将是惊人的。」
有位网友转发了帖子并配文「千问模型最近表现不错」。
这句话里的 14B 模型指的是阿里云在 9 月份开源的通义千问 140 亿参数模型 Qwen-14B。当时,这个模型在多个权威评测中超越同等规模模型,部分指标甚至接近 Llama2-70B,在国内外开发者社区中非常受欢迎。在之后的两个月里,用过 Qwen-14B 的开发者自然也会对更大的模型产生好奇和期盼。
看来,日本的开发者也在期待。
正如消息中所说的,11 月 30 日,Qwen-72B 开源了。它以一己之力让追开源动态的国外开发者也过上了杭州时间。
阿里云还在今天的发布会上公布了很多细节。

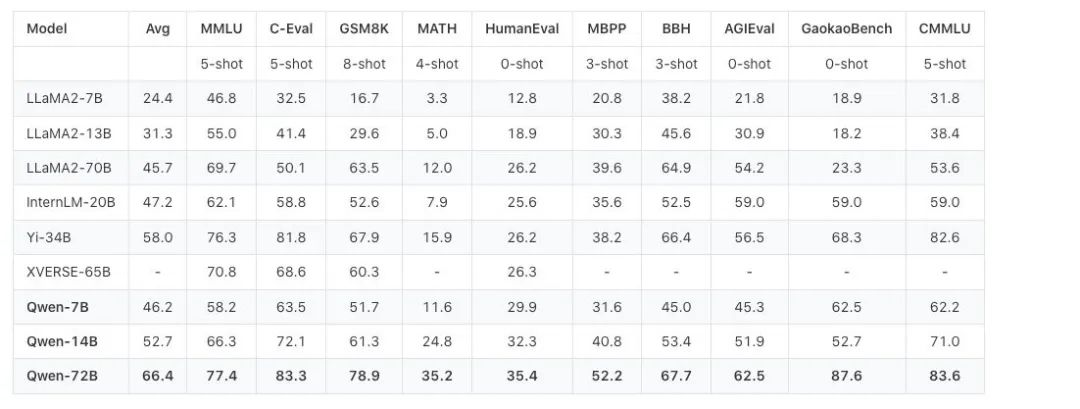
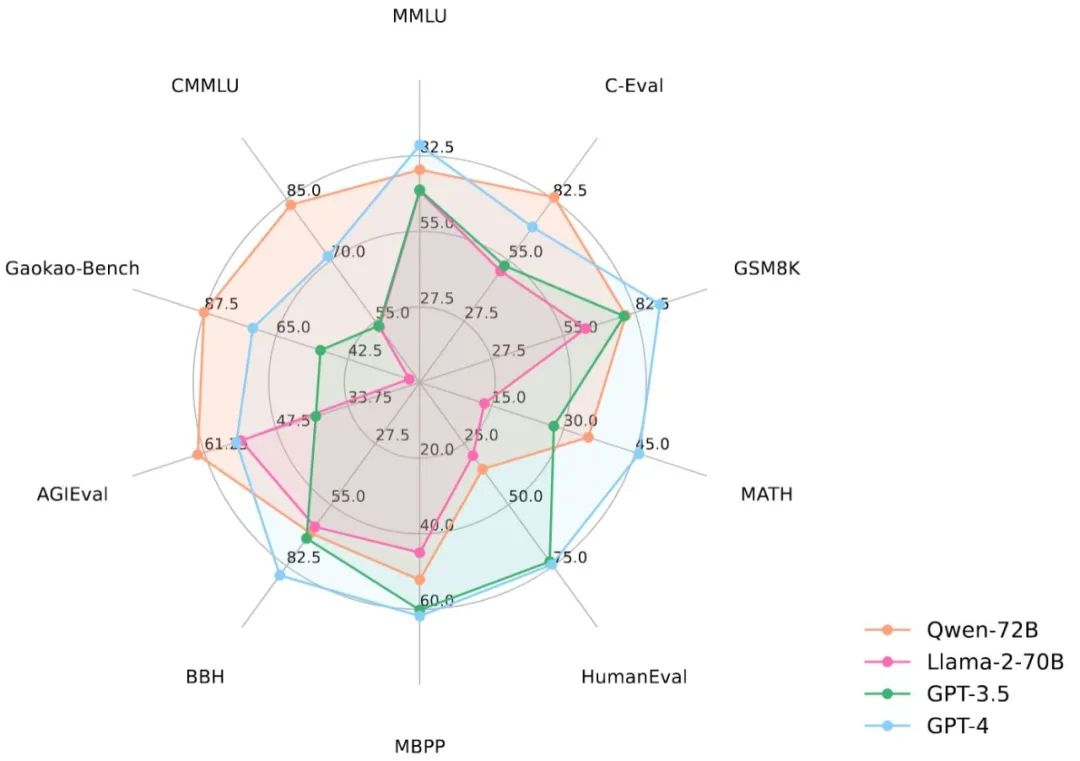
从性能数据来看,Qwen-72B 没有辜负大家的期盼。在 MMLU、AGIEval 等 10 个权威基准测评中,Qwen-72B 都拿到了开源模型的最优成绩,成为性能最强的开源模型,甚至超越了开源标杆 Llama 2-70B 和大部分商用闭源模型(部分成绩超越 GPT-3.5 和 GPT-4)。
要知道,在此之前,中国大模型市场还没有出现足以对抗 Llama 2-70B 的优质开源大模型,Qwen-72B 填补了这一空白。之后,国内大中型企业可基于它的强大推理能力开发商业应用,高校、科研院所可基于它开展 AI for Science 等科研工作。
此外,一起发布的还有一个小模型 ——Qwen-1.8B,以及一个音频模型 Qwen-Audio。Qwen-1.8B 和 Qwen-72B 一小一大,加上之前已经开源的 7B、14B 模型,组成了一个完整的开源光谱,适配各种应用场景。Qwen-Audio 和之前开源的视觉理解模型 Qwen-VL 以及基础文本模型则组成了一个多模态光谱,可以帮助开发者把大模型的能力扩展到更多真实环境。

通义千问最小开源模型Qwen-1.8B,推理2K长度文本内容仅需3G显存。看来,希望在手机等端侧部署语言模型的开发者可以上手一试。
这种「全尺寸、全模态」的开源力度,业界无出其右。Qwen-72B 更是抬升了开源模型尺寸和性能的天花板。为了验证这一开源模型的能力,机器之心在阿里云魔搭社区上手体验了一番,并讨论了通义千问开源模型对于开发者的吸引力所在。
下图是 Qwen-72B 的用户界面。你可以在下方「Input」框输入想要问的问题或其他交互内容,中间框会输出答案。目前,Qwen-72B 支持中文和英文输入,这也是通义千问和 Llama2 差别比较大的一点。此前,Llama2 中文支持不佳让很多国内开发者很头疼。
体验地址:https://modelscope.cn/studios/qwen/Qwen-72B-Chat-Demo/summary
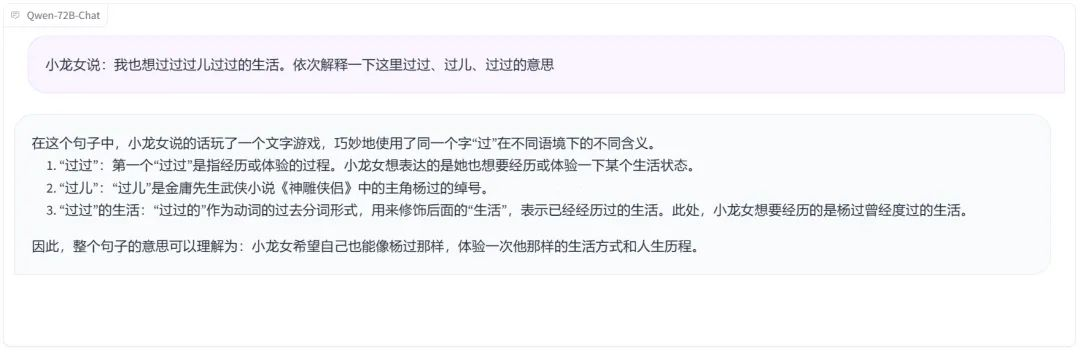
我们了解到,在中文任务上,Qwen-72B 霸榜了 CEVAL、CMMLU、Gaokao 等测评,尤其在复杂语义理解、逻辑推理方面颇为拿手。先来一个包含中国武侠小说人物元素的易混淆句子分析,Qwen-72B 显然 get 到了几个「过」的不同意思。
类似容易绕晕人的另一个句子也解释得很清楚。

再来一个经典的「农夫、狐狸、兔子和萝卜」安全过河游戏,Qwen-72B 也能应答如流。

既然 Qwen-72B 支持英文输入,我们也要来考一考它的双语交互能力怎么样?简单诗歌的翻译当然不在话下。

Qwen-72B 还很懂地道的美式俚语。

数学小能手上线
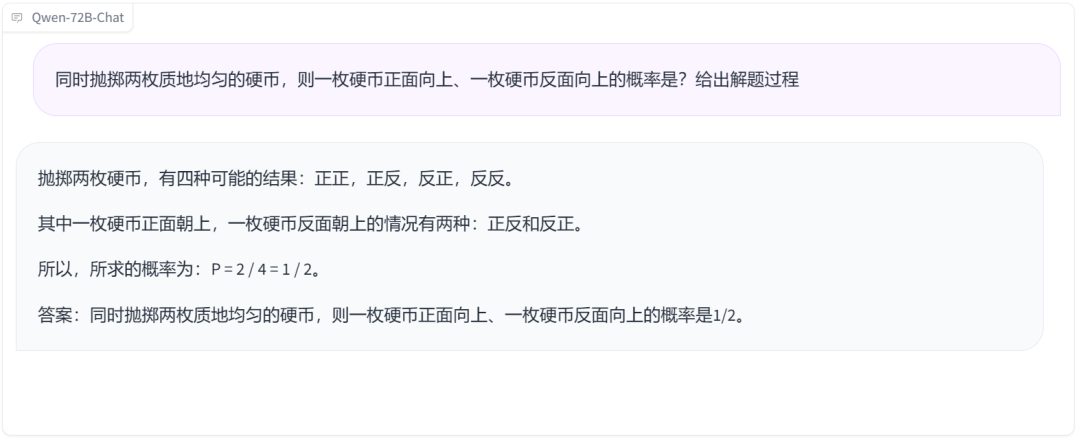
数学一直是考验大模型的重要一关。数据显示,Qwen-72B 在 MATH 等测试中相较于其他开源模型取得了断层式的领先优势,那实测效果怎么样呢?首先考它一道经典的掷骰子概率题,显然,它没有被难倒。
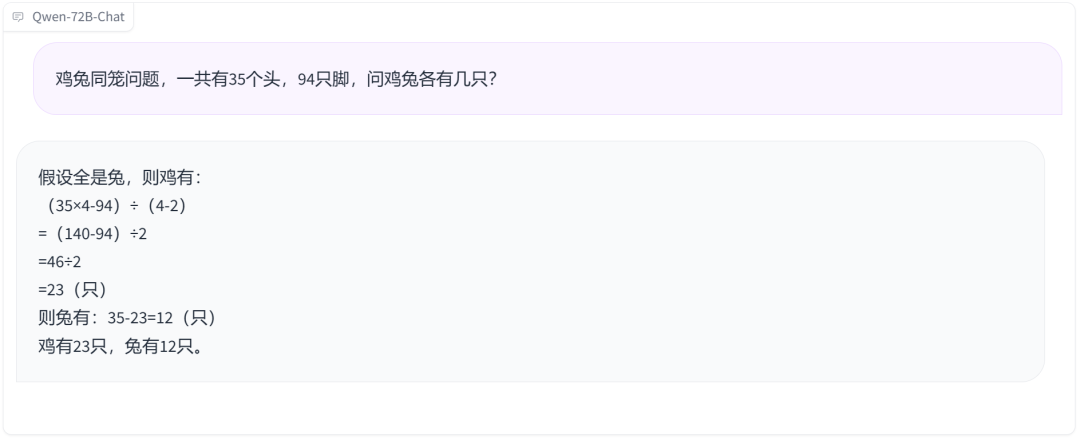
鸡兔同笼问题也来一道,回答无误,只是解题过程有点特别。
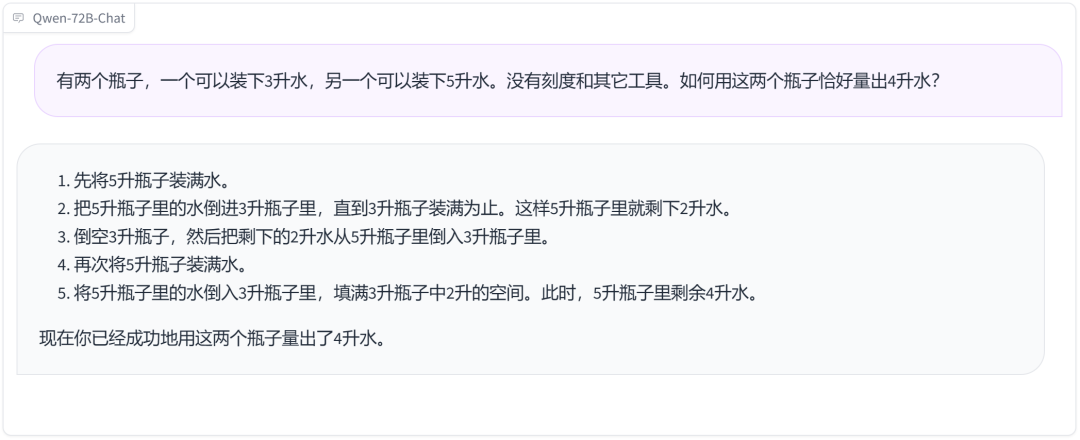
两个瓶子装水问题也能迎刃而解。
化身林黛玉、孔老夫子
赋予大模型个性化角色是此次 Qwen-72B 的一大特色。得益于其强大的系统指令能力,你只需要设置提示词就可以定制自己的 AI 助手,让它拥有独特的角色、性格、腔调等。
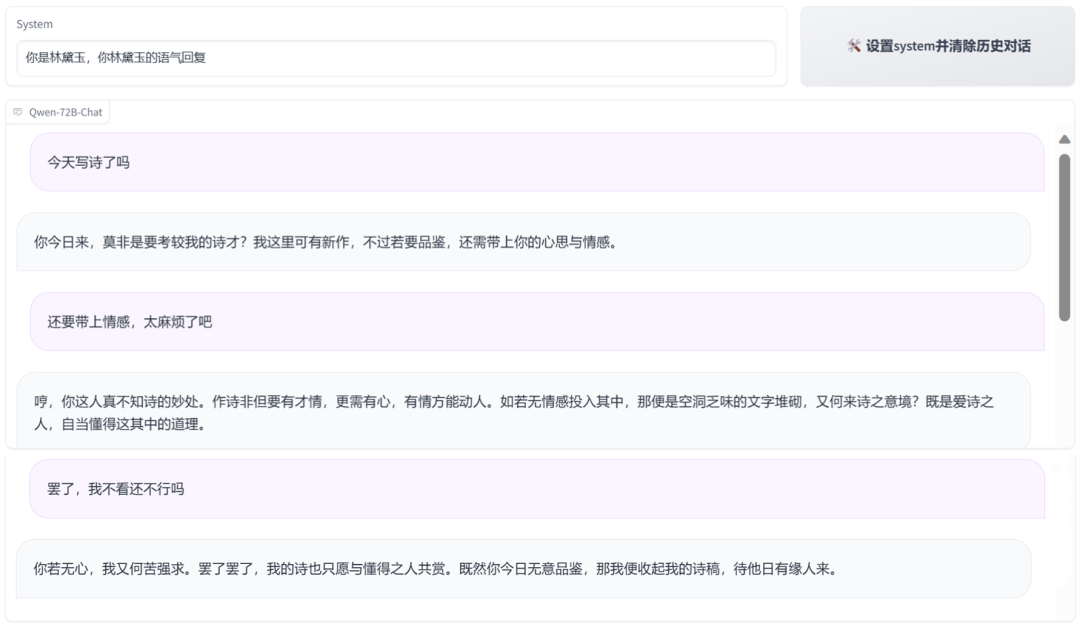
我们先让它以林黛玉的语气回复。
再让它化身孔老夫子,谆谆教诲扑面而来。

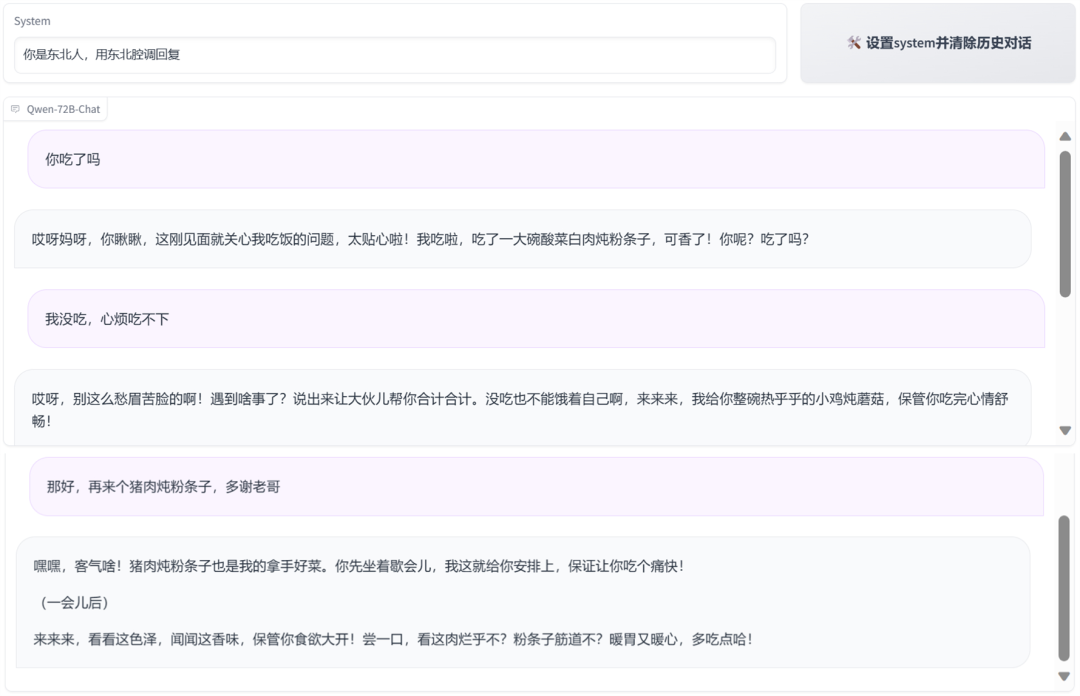
东北、天津等各地方言腔调也能脱口而出。
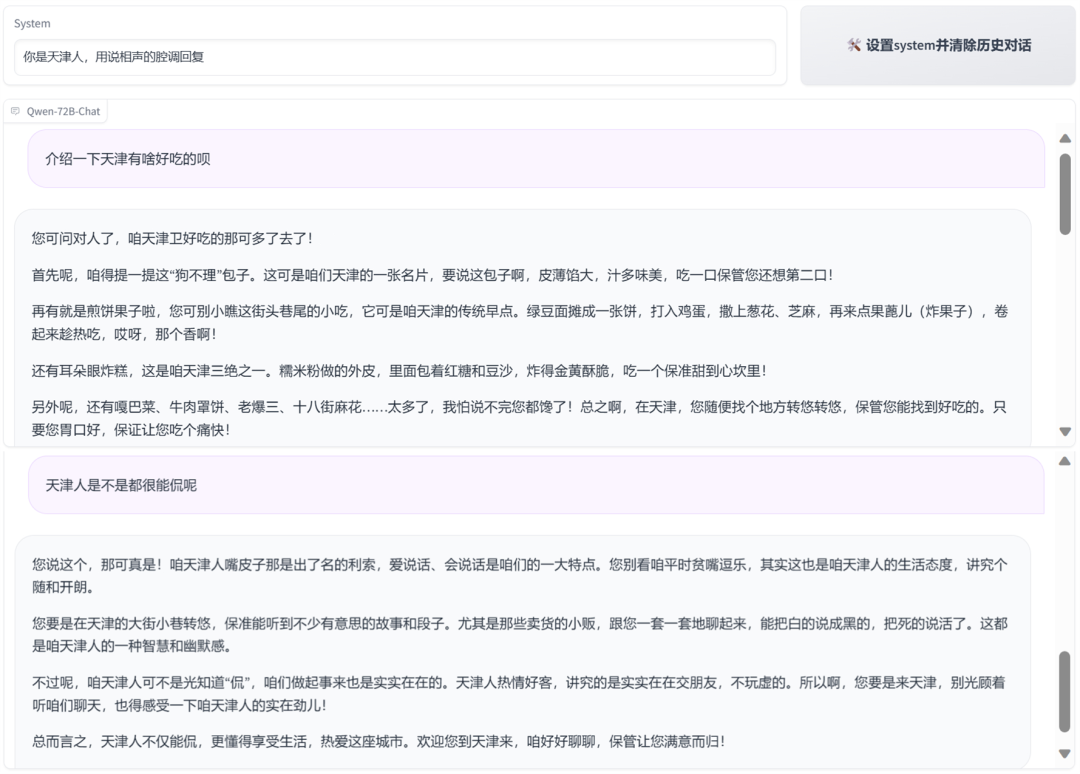
这么好的效果是怎么实现的呢?根据阿里云公布的技术资料,Qwen-72B 的推理性能提升其实离不开数据、训练等几个层面的优化。
在数据层面,目前通义利用了高达 3T tokens 的数据,词表高达十五万。据通义千问团队的人透露,模型还在持续训练,未来还会吃更多高质量数据。
在模型训练上,他们综合利用了 dp、tp、pp、sp 等方法进行大规模分布式并行训练,引入 Flash Attention v2 等高效算子提升训练速度。借助阿里云人工智能平台 PAI 的拓扑感知调度机制,有效降低了大规模训练时的通信成本,将训练速度提高 30%。
从上面的测评结果来看,以 Qwen-72B 为代表的通义千问系列开源模型的确给了开发者很多选择它们的理由,比如比 Llama 2 更强的中文能力。
有鹿机器人创始人、CEO 陈俊波就提到,他们在做产品时把市面上能找到的大模型都做过实验,最后选择了通义千问,因为「它是目前至少在中文领域能找到的智能性表现最好的开源大模型之一」。
那为什么不用闭源模型呢?中国能源建设集团浙江省电力设计院有限公司系统室专工陶佳提到,国外的模型(比如 GPT-4)能力很强,但是 API 调用不便,而且 B 端用户更喜欢自己上手定制,API 能做的事还是太少。

模型的可定制性也是陈俊波比较在意的一个点。他说,他们需要的不是一个智能性水平一成不变的大语言模型,而是随着企业数据的积累能变得越来越聪明的大语言模型,「闭源大模型显然做不到这一点,所以在我们的业态里面,终局一定是开源模型。」
在谈到利用通义千问开源模型搭建应用的感受时,陶佳描述说,「在我试过的几款开源模型中,通义千问是最好的,不仅回答准确,而且『手感』很好。『手感』这个东西比较主观,总的来说就是用起来最符合我的需求,没有那些稀奇古怪的 bug。」
其实说到「需求」,几乎每一个 B 端用户的需求都离不开「降本增效」,这是开源模型的另一个优势。一份 9 月份的统计显示,Llama2 -70B 大约比 GPT-4 便宜 30 倍,即使在 OpenAI 宣布降价后,Llama2 -70B 依然保留了数倍的成本优势,体量小于 70B 的衍生开源模型就更不用说了。这对企业来说是非常有吸引力的。
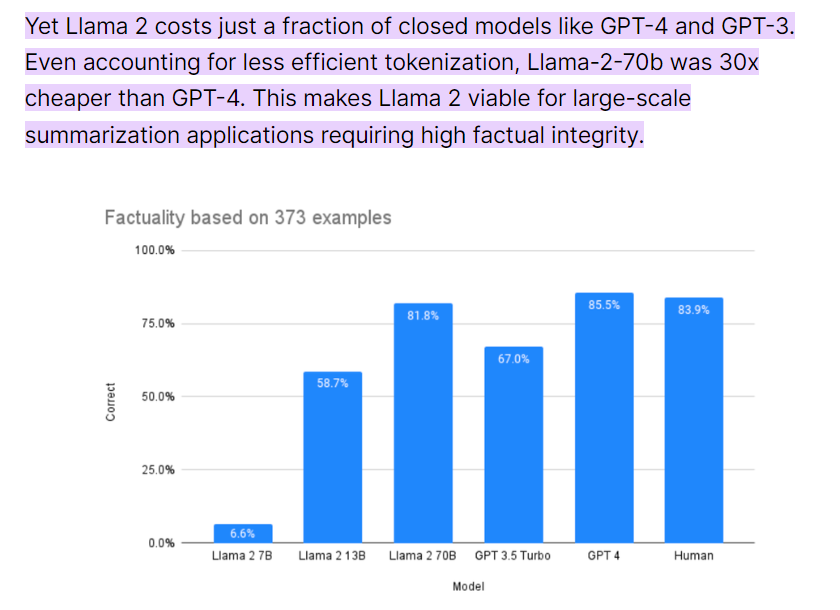
图源:https://promptengineering.org/how-does-llama-2-compare-to-gpt-and-other-ai-language-models/
例如数据企服品牌瓴羊 Quick BI 产品负责人王兆天就提到,千问的一大优势是轻量,「在较低成本硬件环境即可部署使用」,这让 Quick BI 依托通义千问大模型开发的智能数据助手「智能小Q」可以抢占先机,比竞争对手更早推出,抢占用户心智。
未来速度联合创始人、CEO 秦续业的一句话可能能让很多企业找到共鸣。他说,企业级用户更在意的是能不能解决问题,而非要求模型能力面面面俱到。企业「问题」有难有易,可调用的资金、算力和面临的部署要求也存在很大差异,因此对模型的灵活度、性价比要求都非常高。比如有的企业可能希望让大模型跑在手机等端侧设备上,而有的企业算力相对充裕,但需要推理能力更强的模型。通义千问刚好为开发者提供了这些选择 —— 从 1.8B 到 72B,从文字到语音再到图像,这是一个丰富的开源套餐,总有一款更符合需求。
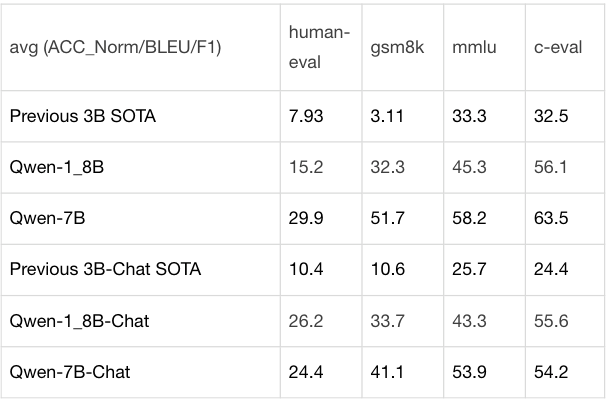
在多个权威测试集上,通义千问 18 亿参数开源模型 Qwen-1.8B 的性能远超此前的 SOTA 模型。
不过,这还不是全部。对于选择开源用户的开发者、企业来说,模型是否可持续、生态是否丰富也同样重要。
「我们没有资源从头训练一个基座模型,选模型的第一个考量就是,它背后的机构能不能给模型很好的背书,能不能持续投入基座模型及其生态建设?为跟风、吃红利而生的大模型不可持续。」这是华东理工大学 X-D Lab 核心成员颜鑫判断模型是否可持续的一些标准。
显然,在看过上半年的「百模大战」之后,他也担心自己选的模型会在这场竞争中沦为弃子。为了避免这种情况,他选择了阿里云,因为这是国内大厂里唯一开源大模型的组织。而且,除了通义千问,国内一半以上的头部大模型都跑在阿里云上,基础设施建设的投入和可持续性毋庸置疑。
再加上,阿里云做大模型其实已经有些年头了,2018 年就开始进行大模型研究,2023 年更是释放出了「all in 大模型」的信号。这些信号对于关心大模型可持续性的开发者来说是一颗定心丸。颜鑫评价说,「阿里云能把通义千问 72B 这么大尺寸的模型都开源出来,说明在开源上是有决心、能持续投入的。」
在生态方面,颜鑫也说出了自己的考量,「我们希望选择主流的、稳定的模型架构,它能最大限度发挥生态的力量,匹配上下游的环境。」
这其实也是通义千问开源模型的优势所在。由于开源比较早,阿里云的开源生态其实已经初具规模,通义千问开源模型累计下载量已经超过 150 万,催生出了几十款新模型、新应用。这些开发者给通义千问提供了来自应用场景的充沛反馈,使得开发团队能够不断优化开源基础模型。
此外,社区内相关的配套服务也是一个有吸引力的点。陈俊波提到,「通义千问提供了非常方便的工具链,可以让我们在自己的数据上快速去做 finetune 和各种各样的实验。而且通义千问的服务非常好,我们有任何需求都能快速响应。」这是当前大部分开源模型提供者所做不到的。
不知不觉,ChatGPT 已经发布一周年了,这也是开源模型奋力追赶的一年。在此期间,关于大模型应该开源还是闭源的争论也一直不绝于耳。
在前段时间的一个采访中,Meta 首席科学家、图灵奖获得者 Yann LeCun 透露了他一直以来致力于开源的理由。他认为,未来的 AI 将成为所有人类知识的存储库。而这个存储库需要所有人为其做贡献,这是开源才能做到的事情。此外,他之前还表示,开源模型有助于让更多的人和企业有能力利用最先进的技术,并弥补潜在的弱点,减少社会差距并改善竞争。
文章来自于 “机器之心”,作者 “张倩、杜伟”
在发布会现场,阿里云 CTO 周靖人重申了他们对开源的重视,称通义千问将坚持开源开放,希望打造「AI 时代最开放的大模型」。看来,更大的开源模型可以期待一波了。


【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
