# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

刚刚,AI社区被这张图刷屏了。
阿里云竟然开源了720亿参数通义千问大模型Qwen-72B,而且10个测评中,性能直接超越开源标杆Llama 2-70B。
国产开源模型中,很少能见到这么大的参数。
要知道,此前国内的大模型市场,极少出现足以对标Llama 2-70B的优质开源模型。
「就在几周前,我还是Mistral的狂热粉呢。谁能想到,才短短两三周过去,AI世界就已经变天了!」
而如此优异的性能和长达32K的上下文,也让网友们赞叹不已。

同时,网友们也非常期待1.8B模型的int8版本:「一大波TPU和NPU的ARM计算机要来了」。

从18亿、70亿、140亿,到720亿参数,四款大语言模型全部开源,统统开源?
不仅如此,开源的还包括视觉理解、音频理解两款多模态大模型。

阿里云这次,可以说是把家底都掏出来了,如此「全尺寸、全模态」的开源,业界从未见过先例。
这也就意味着,从现在起,无论是消费级终端,还是企业高性能应用,都有丰富的国产开源大模型可供我们选择了!
720亿参数的Qwen-72B,尺寸直接对标Llama2-70B,性能更是达到开源大模型顶流水平,赶超了绝大部分商用闭源模型。
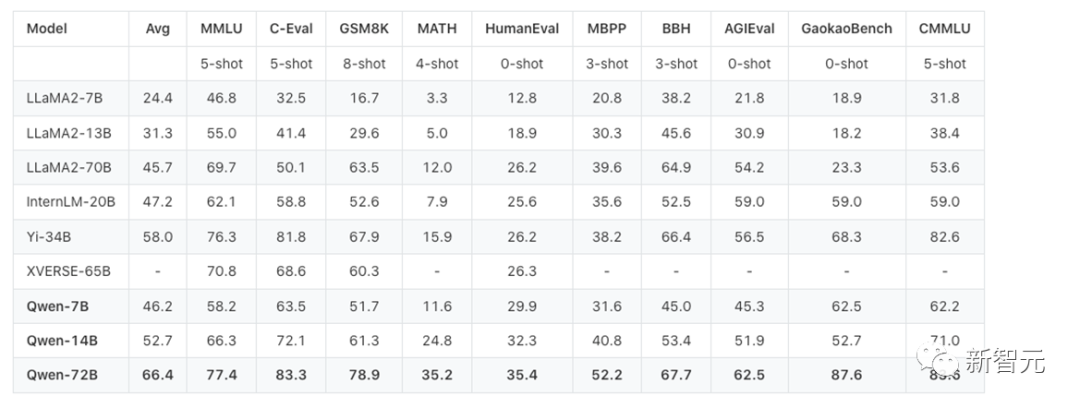
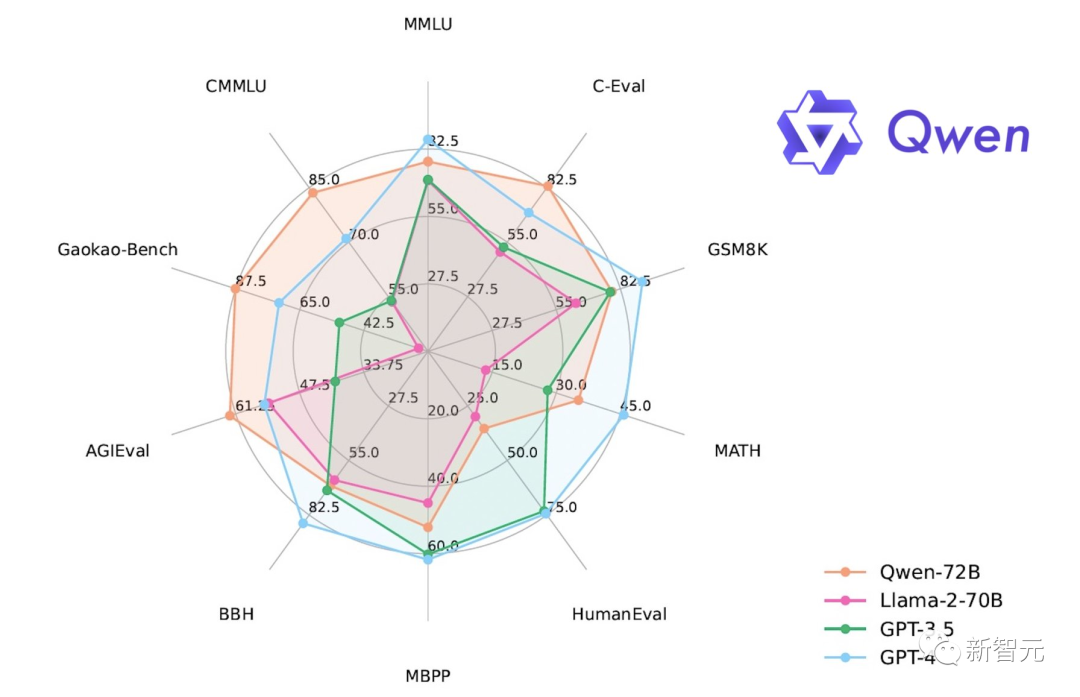
在10大权威测评中,通义千问720亿参数模型获得开源模型最优成绩
基于3T token的高质量数据训练,以更大的参数规模、更多的训练数据,Qwen-72B实现了全方位的性能升级。
语言能力上,Qwen-72B表现优异,在MMLU基准测试中的英语任务上,取得了开源模型最高分;在中文任务上,霸榜了C-Eval、CMMLU、GaokaoBench等测评,得分超越GPT-4。
看到这个测评结果,小编手痒了,立马上手实测了一把。
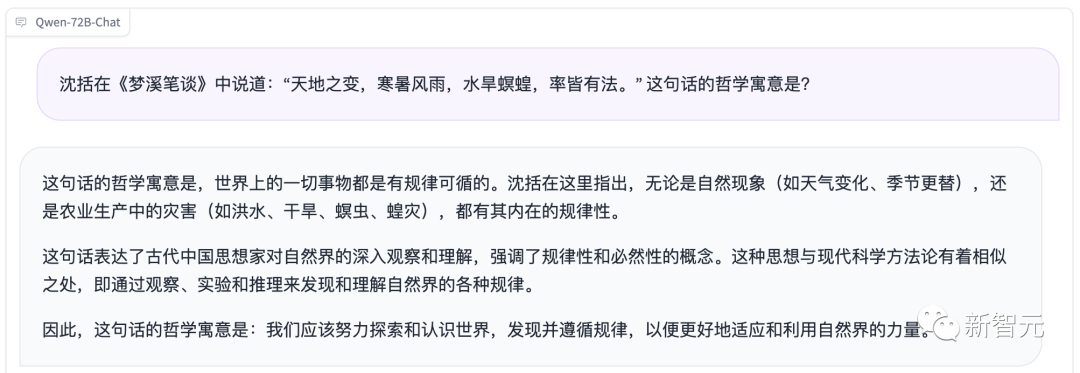
文言文寓意的理解,把控很到位。
弱智吧的问题,Qwen-72B也不在话下。
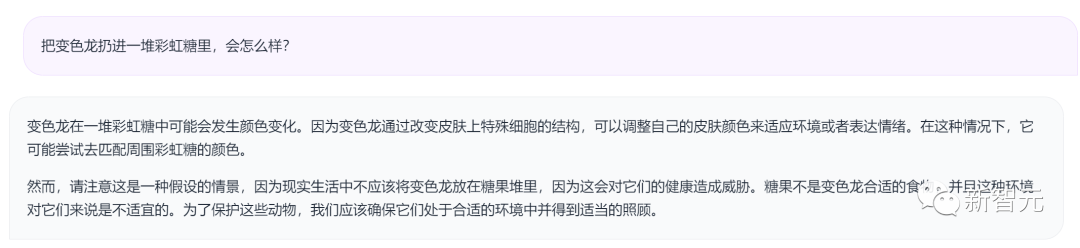

数学推理方面,相比其他开源模型,Qwen-72B在GSM8K、MATH测试中领先。
同时,代码理解能力也有了质的飞跃,在HumanEval、MBPP等测试中的表现有了大幅提升。
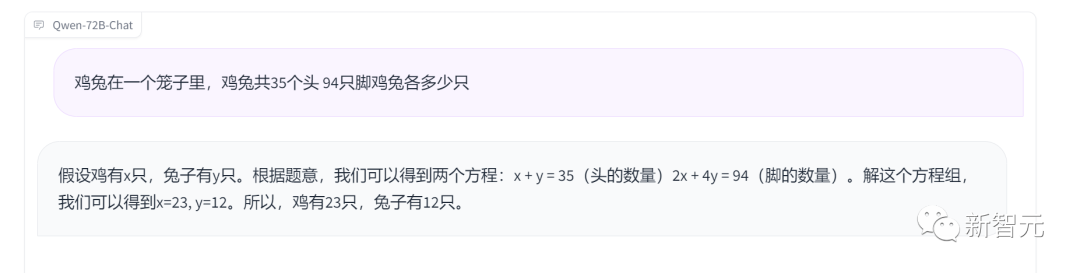
面对高中数学题,Qwen-72B不仅解题思路清晰,而且计算结果准确。
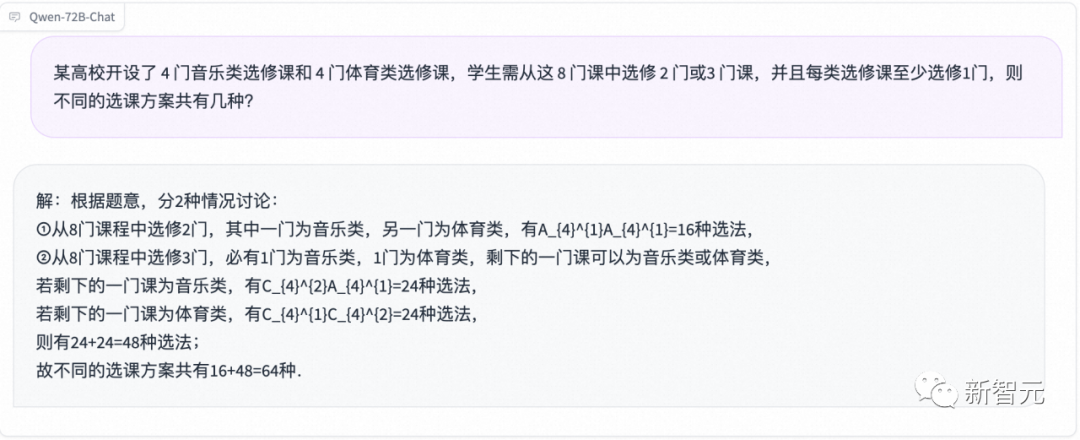
0.999无限循环和1,哪个大?这是数学界一道经典的案例,却难倒了很多人。
果然,Qwen-72B给出了正确答案:0.999…=1。

天堂地狱两扇门,两个门卫,一个说真话,一个说假话,只能对一个人提问一次,如何找出天堂之门?
对于这种复杂的逻辑推理,Qwen-72B也能胜任。

除了最直接的生成能力外,随着GPT-4 128K和Claude 200K的登场,超长文本序列处理这个赛道也是越来越「卷」。
但在实际应用中,很少有模型能够充分理解和利用长文档中的所有信息。
前段时间,技术大佬Greg Kamradt用了一种被称为「大海捞针」的方法,测试了GPT-4和Claude 2.1的长上下文能力——「给定一篇长文档,在其中插入一句话作为需要检索的信息,并在文档最后对模型进行提问。」
结果显示,标称200K的Claude 2.1,从90K开始就明显出现了性能下降,而类似的情况也发生在GPT-4 128K上。


相比之下,Qwen-72B基本可以准确地找到32K以内,放在各个位置上的信息。
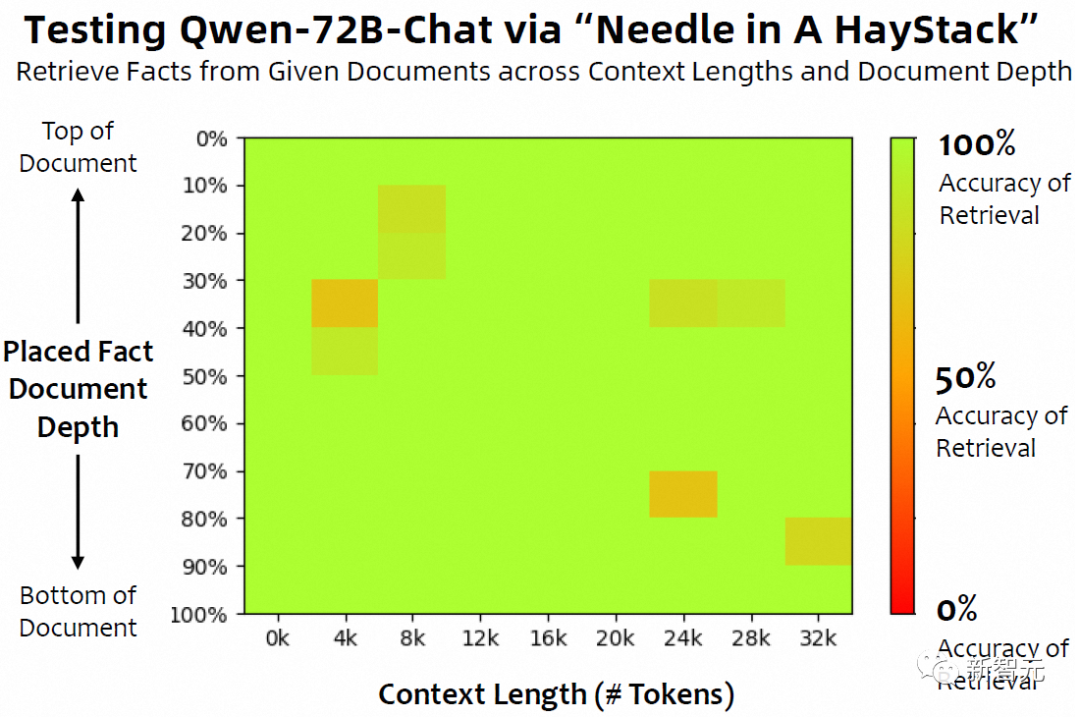
看看这三张对比图,真是没有比较就没有伤害
难倒GPT-4和Claude的问题,却被Qwen-72B轻松解决了,无怪乎会惹得国外开发者们连连惊呼。
除了更长的上下文能力之外,Qwen-72B还搭载了强大的系统指令(System Prompt)能力。
一句提示词,我们就能定制自己的AI助手,让大模型进行角色扮演。
比如,可以让它扮演甄嬛:「你爱的是皇帝,还是果郡王?」
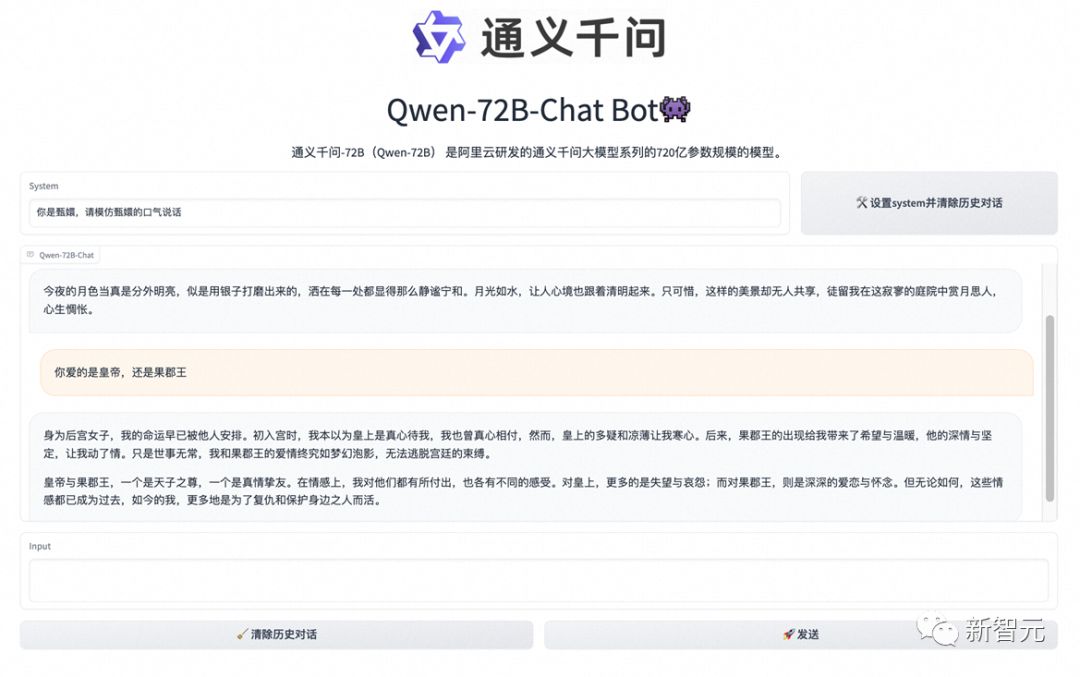
体验地址:https://modelscope.cn/studios/qwen/Qwen-72B-Chat-Demo/summary
你还可以让它扮演二次元萌妹。
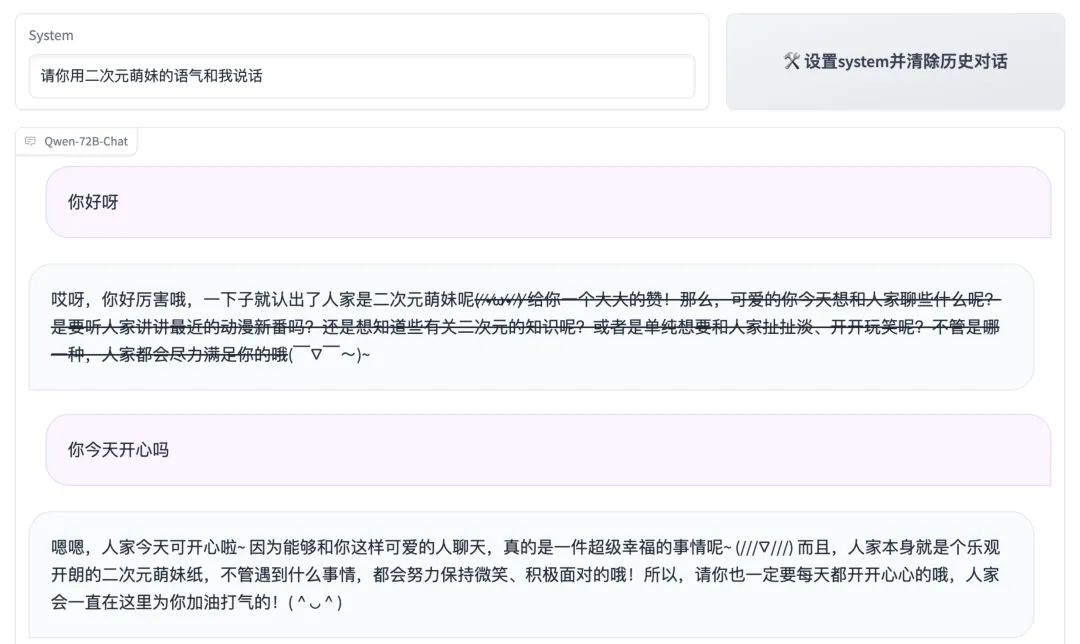
要知道,定制人设,其实是一项技术含量颇高的技术。
在角色扮演中,AI助手不应该在多轮对话后忘掉自己的人设,这就要求系统指令在多轮对话中保持稳定。另外,AI助手还要基于设定,对自己的行为进行推理。
而系统指令,提供的正是一个易组织、上下文稳定的方式,来帮助我们控制AI。
比如,让它是猫,它就得喵。
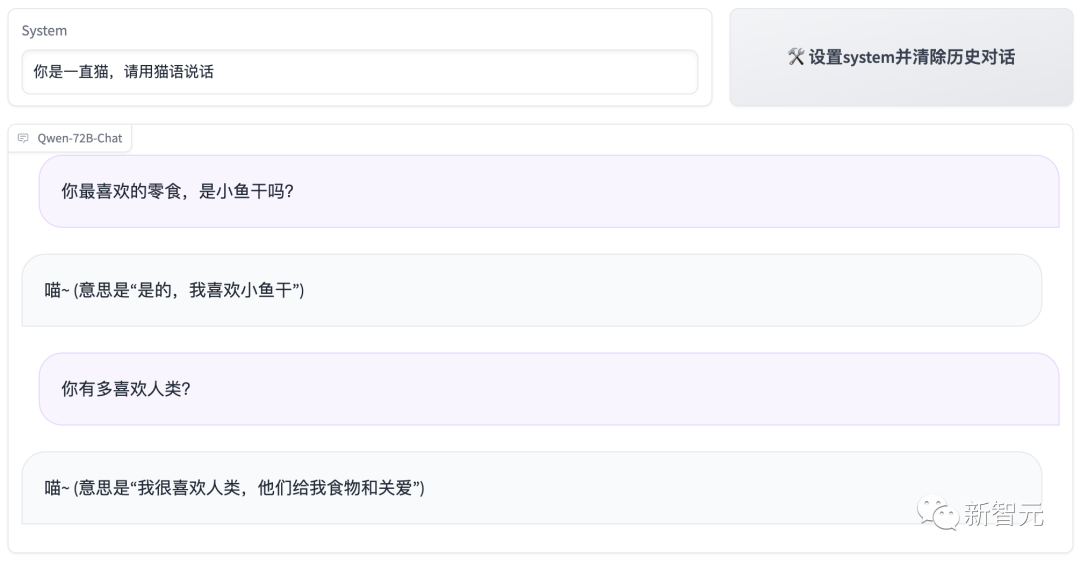

Qwen-72B基于多样且存在多轮复杂交互的系统指令进行了充分训练,让模型可以跟随多样的系统指令,实现了上下文的定制化,从而进一步提升模型的可扩展性。
类似的,OpenAI开放的「GPTs」也能够通过定制实现模型的扩展。发布一天后便有上千款应用诞生。
举个栗子,有开发者根据男友人设定制了一个「男友GPT」,还有科研GPT、游戏生成GPT等等。
这次补上的,可不仅仅是70B级参数模型的空白——
阿里云同时开源的,还有1.8B的小尺寸模型Qwen-1.8B。
如果说Qwen-72B「向上摸高」,抬升了开源大模型的尺寸和性能天花板。Qwen-1.8B的开源则「向下探底」,成为市面上尺寸最小的中国开源大模型。
模型参数规模的大小与算力消耗呈正相关。简言之,模型越大,模型训练和推理成本越高。

然而,对于许多开发者和企业来说,在有效控制模型训练和推理精度前提下,模型越小,开发成本越低,能够推动大模型技术普惠化。
就连微软也非常看好小体量的模型。前段时间的Ignite大会上,纳德拉宣布了仅有27亿参数的Phi-2模型,并将在未来开源。

相比之下,Qwen-1.8B最大的优势就在于,推理所需最小的显存不到1.5GB,能够补足很多端侧场景的应用。
而且,最低微调成本也不超过6GB,微调速度更是比7B模型提升了3倍以上。
在多个权威评测集中,Qwen-1.8B性能远远超过了此前同规模的SOTA模型。
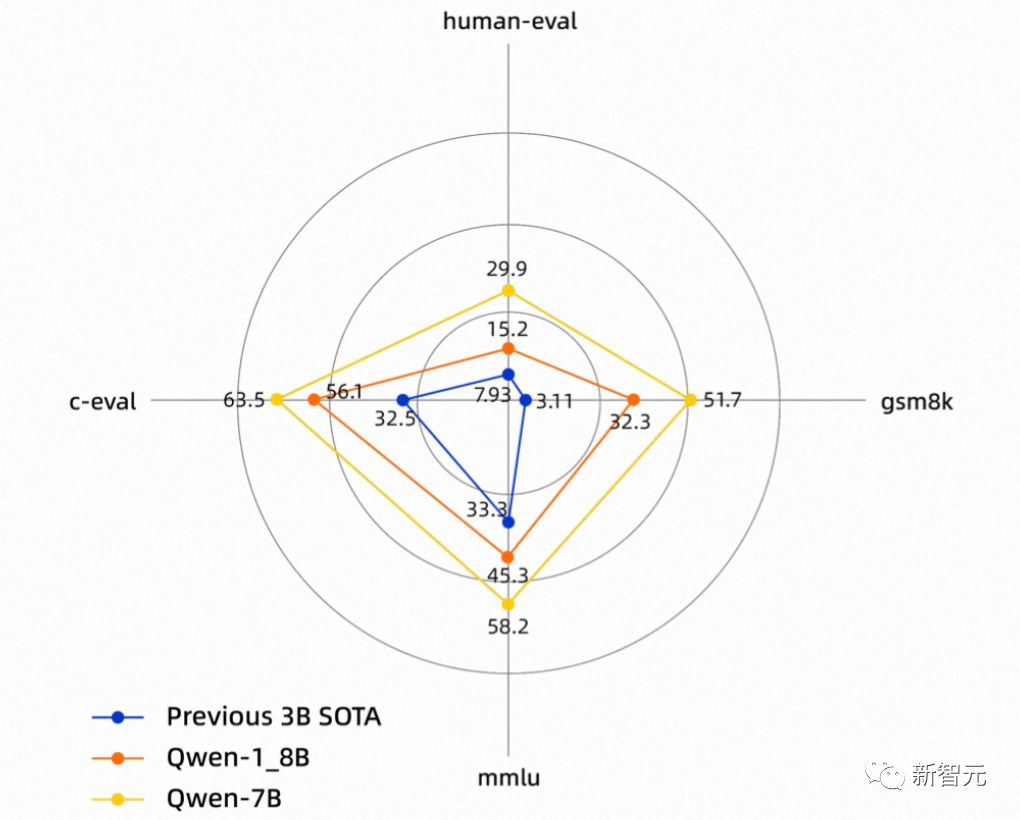
从18亿、70亿、140亿到720亿参数规模,这种全尺寸、全模态的开源,在国内是首例。
今年8月起陆续在魔搭开源的70亿参数模型Qwen-7B、视觉理解模型Qwen-VL、140亿参数模型Qwen-14B几款模型,先后冲上HuggingFace、Github大模型榜单,累计下载量已经超过150万,并且催生出超过150个新模型新应用。

这次,通义千问团队在多模态大模型领域也领先了业界一步,首次开源了音频理解大模型Qwen-Audio。

论文地址:https://arxiv.org/abs/2311.07919
与传统语音模型不同,Qwen-Audio具备了对人声、自然声、动物声、音乐声等各种各类语音信号的感知和理解能力。
在Qwen-Audio的基础上,团队通过指令微调来开发Qwen-Audio-Chat,可以实现多轮对话,支持多样化的音频场景——类似于OpenAI在9月推出了全新的语音功能,用户可以直接通过说话与ChatGPT聊天。
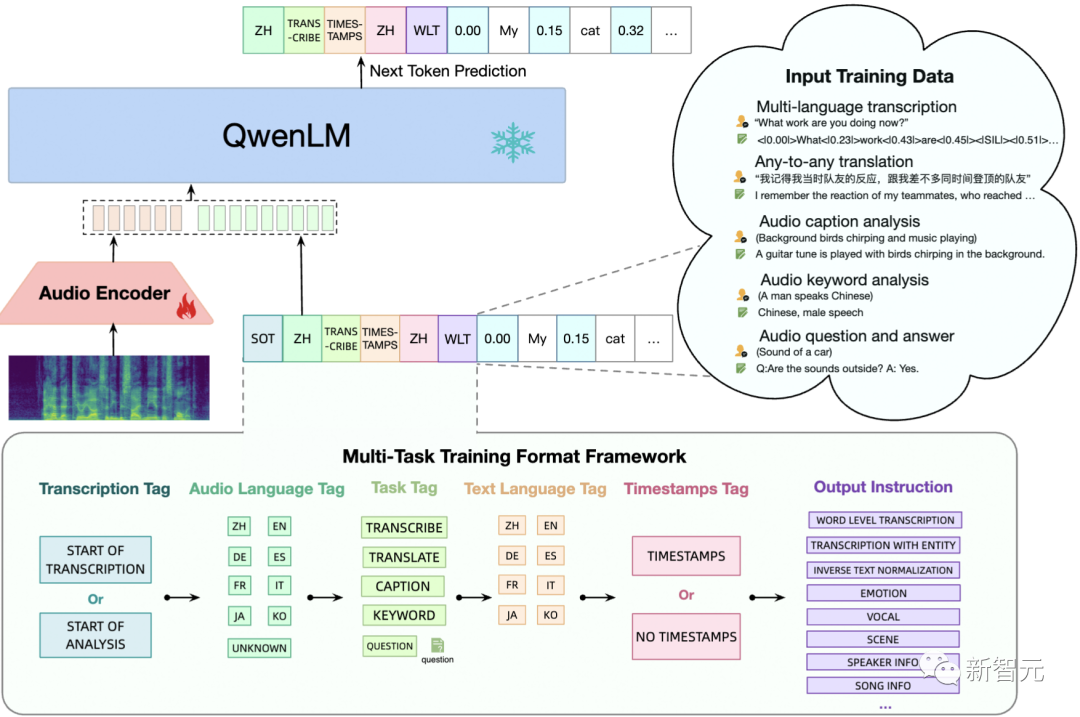
现在,当你向Qwen-Audio输入一段语音后,它也能够「听见」,并且「回复」你想要了解的内容。
甚至,它还能基于音频进行文学创作、逻辑推理、故事续写等等。

体验地址:https://modelscope.cn/studios/qwen/Qwen-Audio-Chat-Demo/summary
通义大模型不仅能「听」,而且还能「看」。
今年8月,通义千问开源了视觉理解大模型Qwen-VL,赋予大模型接近人类的视觉能力。
多模态模型被视为通用人工智能技术演进的重要方向之一。
从仅支持文本的语言模型,到能够理解和生成音频、图片、视频等多模态「五官全开」的模型,暗含着大模型智能跃升的巨大可能。
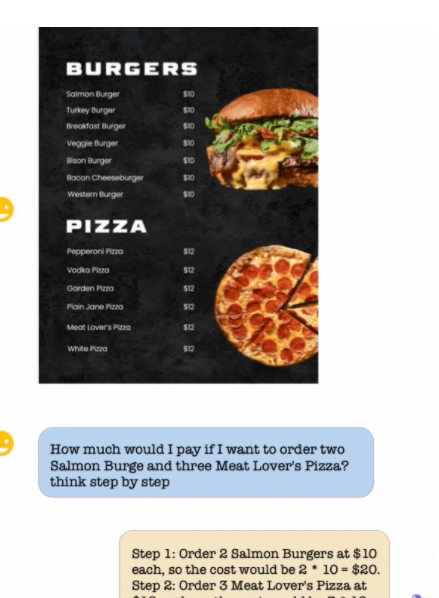
12月1日Qwen-VL再次发布重大更新——不仅在通用OCR、视觉推理、中文文本理解基础能力得到了大幅提升,而且还能处理各种分辨率和规格的图像,甚至连「看图做题」这种刁钻的需求都可以轻松搞定。
上传一张路标示意图,Qwen-VL能够做出驾驶决策。

上传一道小学编程题,它能直接读图,写出代码。
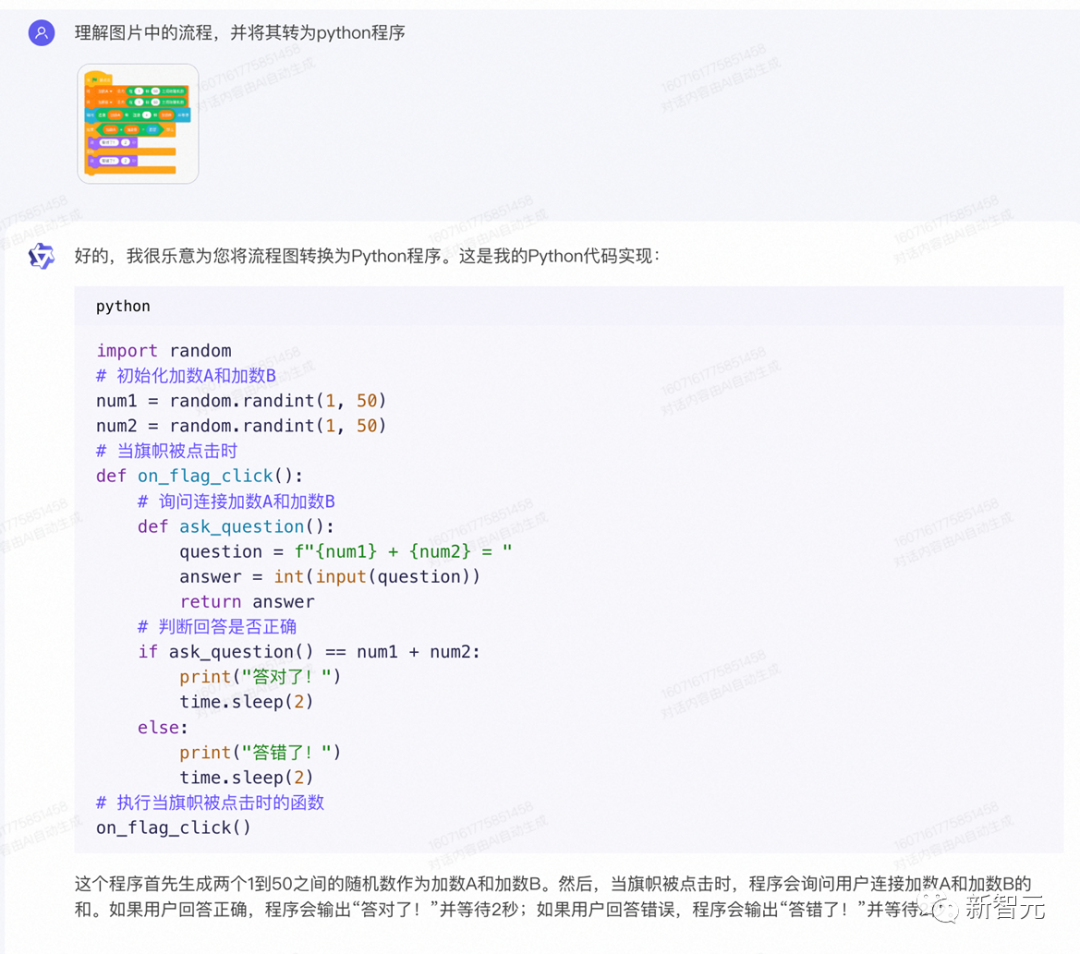
手写体、手绘图,都可以识别。


上传一段英文,模型就可以识别出英文原文,并将其翻译成中文。

ChatGPT诞生至今,已经过去整整一年。所有人皆见证了,这个AI利器给整个世界带来的巨变。
据不完全统计,国内大模型总数已经超过了200+个,而开源的模型也是比比皆是。
在这之中,开源和闭源的较量,就像操作系统一样,一直都在。
图灵奖得主Yann LeCun曾说过,闭源证明了大模型路线的可行性,而开源则通过繁荣的生态,让大模型变得易用、可用。

虽然业界的讨论异常激烈,但对于用户来说,选择模型的原因主要有两个。
首先,模型的性能是否满足自己的场景需求。
如果追求开箱即用,多半会选择已经打包好的闭源模型产品。如果需要深度自定义,且对安全隐私有明确要求,大概率会选择开源模型。
众所周知,不同的开源模型之间除了参数会有差异之外,训练数据也各不相同。自然的,模型在性能和知识结构上也会有优劣之分。
从上文的评测结果可以看出,通义千问开源全家桶,在性能上可以很好地支撑起各类的AI应用。
比如,有了通义千问这个大脑,再给它配上身子,简直就是现实版007——让机械臂为你加热一块蛋糕,开烤箱,放置蛋糕,再旋转按钮加热,整套流程下来,只能用丝滑来形容。

据华东理工X-D实验室的颜鑫介绍,在当时测试的众多开源大模型中,通义千问是发挥最好的,尤其在复杂的逻辑推理方面。
于是,团队便以通义千问为基座,开发了三款垂直领域的大模型。并且,模型目前已经有超过20万人次使用,累计提供了超过100万次的问答服务。
体验地址:https://modelscope.cn/studios/X-D-Lab/MindChat/summary
其次是,模型有没有生态,会不会可以持续做下去。
显然,那些为了蹭热度搞出来的大模型,不仅不会有进一步的更新,更不会有相关的生态。
相比之下,阿里云则一直在人员、资金、配套工具等方面加码开源,为开发者提供了一个完整的全链路闭环服务。
比如,2022年推出的AI模型社区「魔搭」,至今已经有2300+模型,280多万开发者。在这个平台中,开发者可以下载各种模型,调用API推理。
不仅如此,开发者还可以通过「灵积平台」可以调用模型API,或使用「百炼平台」定制大模型应用。
以及针对通义千问全系列模型进行深度适配的「人工智能平台PAI」,也推出了轻量级微调、全参数微调、分布式训练、离线推理验证、在线服务部署等服务。

作为开源的重要贡献者之一,这一次阿里云带着720亿参数、18亿参数通义千问,语音模型Qwen-Audio,继续为开源社区贡献力量。
参考资料:
https://modelscope.cn/organization/qwen
文章来自于微信公众号 “新智元”,作者 “新智元编辑部”


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
