# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在图像理解领域,多模态大模型已经充分展示了其卓越的性能。然而,对于工作中经常需要处理的图表理解与生成任务,现有的多模态模型仍有进步的空间。
尽管当前图表理解领域中的最先进模型在简单测试集上表现出色,但由于缺乏语言理解和输出能力,它们无法胜任更为复杂的问答任务。另一方面,基于大语言模型训练的多模态大模型的表现也不尽如人意,主要是由于它们缺乏针对图表的训练样本。这些问题严重制约了多模态模型在图表理解与生成任务上持续进步。
近期,腾讯联合南洋理工大学、东南大学提出了 ChartLlama。研究团队创建了一个高质量图表数据集,并训练了一个专注于图表理解和生成任务的多模态大型语言模型。ChartLlama 结合了语言处理与图表生成等多重性能,为科研工作者和相关专业人员提供了一个强大的研究工具。

论文地址:https://arxiv.org/abs/2311.16483
主页地址:https://tingxueronghua.github.io/ChartLlama/
ChartLlama 的团队构思出了一种巧妙的多元化数据收集策略,通过 GPT-4 生成特定主题、分布和趋势的数据,来确保数据集的多样性。研究团队综合开源的绘图库与 GPT-4 的编程能力,来编写图表代码,生成精确的图形化数据表示。此外,研究团队还运用 GPT-4 描述图表内容和生成问答对,为每个图表生成了丰富多样的训练样本,以确保经过训练的模型能够充分的理解图表。
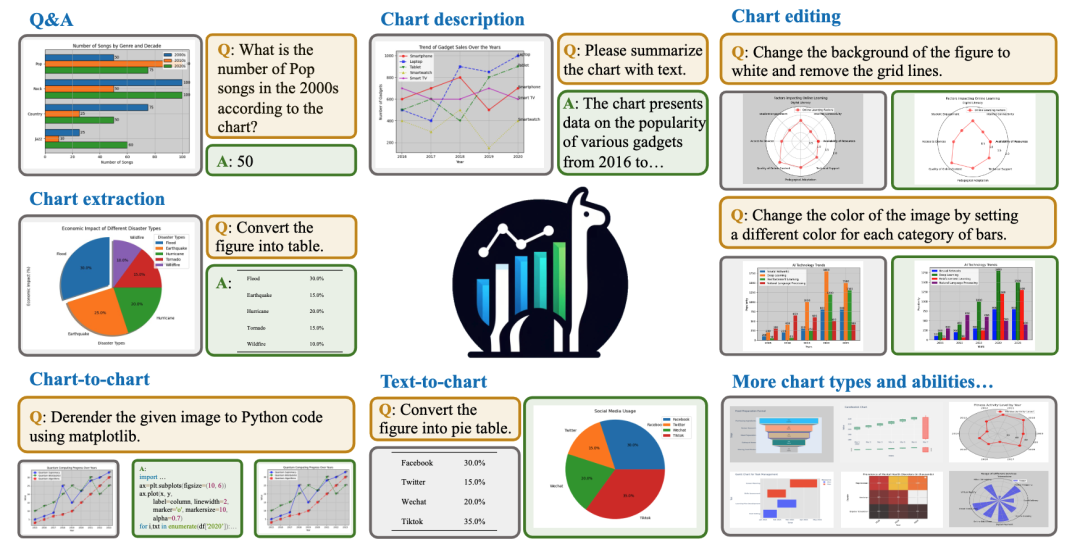
图表理解领域中,传统模型仅能实现诸如读取图表中的数字这种简单的 QA 任务,无法对较复杂的问题进行回答。具体来说,它们难以跟随较长的指令,在涉及数学运算的问答中,也经常出现运算错误,而 ChartLlama 可以有效的避免此类问题,具体对比如下所示:

在传统任务之外,研究团队也定义了若干新任务,其中有三个任务涉及到了图表生成,论文中给出了相关示例:
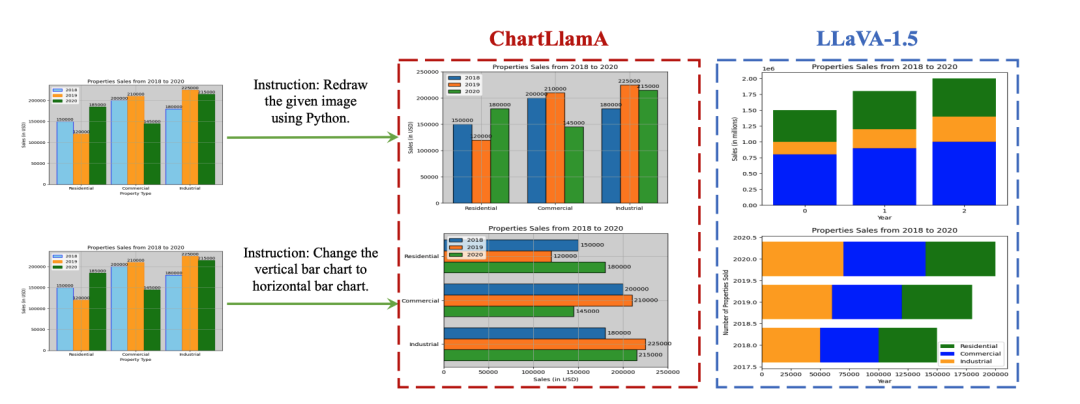
给定图表和指令,进行图表重建与图表编辑的示例
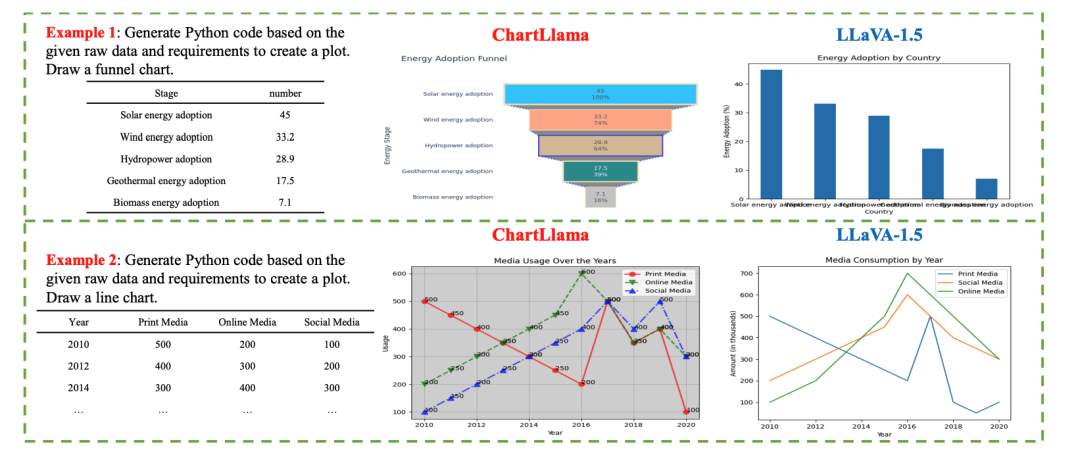
根据指令和原始数据,生成图表的示例
在各种基准数据集上,ChartLlama 都达到了 SOTA 水平,需要的训练数据量也更少。其灵活的数据生成与收集方法,极大地拓宽了图表理解与生成任务中图表和任务的种类,推动了该领域的发展。
ChartLlama 设计了一种灵活的数据收集方法,利用 GPT-4 的强大语言能力和编程能力,创建了丰富的多模态图表数据集。

ChartLlama 的数据收集包括三个主要阶段:
经过以上步骤,ChartLlama 创建了包含多种任务和多种图表类型的数据集。其中不同类型的任务、图表在总数据集中的占比如下所示:
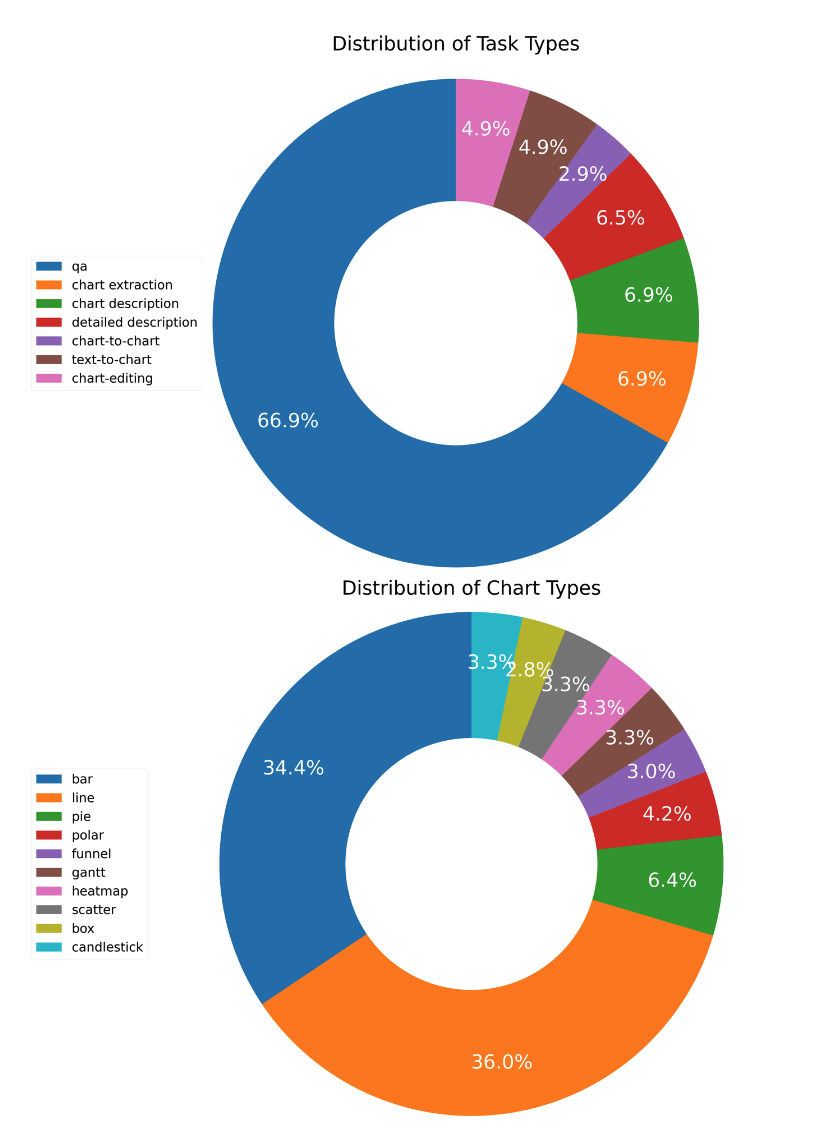
更详细的指令及其说明请参考论文原文。
无论是传统任务还是新的任务,ChartLlama 都展现了最优越的性能。传统任务包括图表问答、图表总结,以及图表的结构化数据提取。对比 ChartLlama 和此前最先进的模型,结果如下图所示:

研究人员也评估了 ChartLlama 所独有的任务能力,包括图表代码生成,图表总结和图表编辑,同时也构造了对应任务的测试集,并与当前最强的开源图文大模型 LLaVA-1.5 进行了对比,结果如下所示:

研究团队还在类型各异的图表中测试了 ChartLlama 的问答准确率,和之前的 SOTA 模型 Unichart 以及提出的基线模型进行了对比,结果如下:
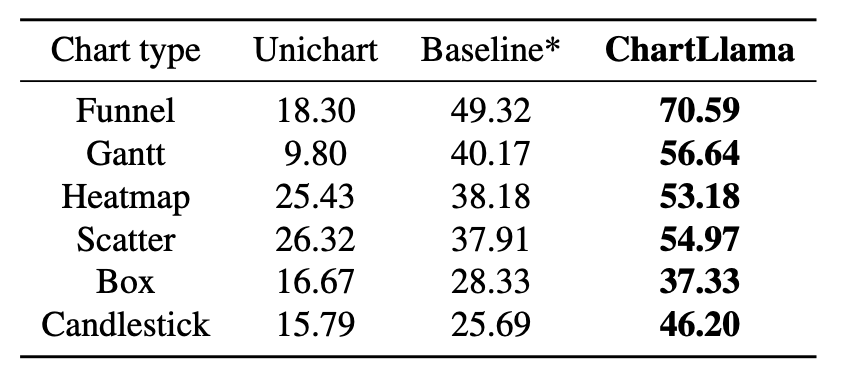
总的来说,ChartLlama 不仅推动了多模态学习的边界,也为图表的理解和生成提供了更精确和高效的工具。无论是在学术写作还是在企业演示中,ChartLlama 都将使图表的理解和创造变得更加直观和高效,在生成和解读复杂视觉数据方面迈出了重要的一步。
文章来自于 微信公众号“机器之心”,作者 “机器之心编辑部”



