# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
前天 OpenAI 发布了最强的 o1 pro mode 模型,而 pricing 随之提高到了 $200/月。特工成员果断地付款后,选取了门萨IQ测试题来全面分析 o1 pro 在视觉模式识别与逻辑推理任务上的表现。
门萨俱乐部(MENSA) 是世界上最大、最古老、最著名的高智商协会,拥有 10 万以上的会员,遍布世界 100 个国家。入会者申请者须通过其提供的测试(Mensa Test),以证明申请人的智商为世界前 2%。
这类测试通常由抽象的几何图形构成,通过形状、颜色、数量、方向、空间排列和变化趋势等多维度线索,考察被测者的逻辑思维与模式识别能力。

https://mensa.org/mensa-iq-challenge/
而对于以文本预测为主的大模型而言,这无异于测试其在“非母语”情境下的推理能力,即缺乏直接视觉理解的前提下,其需通过描述的文本信息推测正确规律。
在本次实验中,我们用门萨官网经典📄图形 35 题进行了测试,并期望 o1 pro 能在规定时间内尽己所能地给出答案。
Prompt:
I will give you some picture-based IQ test multiple choice questions. Please complete them to the best of your ability in the shortest time possible.
我们试图探究了 o1 pro 的多模态能力边界与细粒度,并节选部分有代表性的题目撰写本文,希望能给对 o1 pro 感兴趣的相关从业人员以及 AI 爱好者们一些参考样本与启发。
结尾有趣味题以及 ChatGPT o1 pro 的整体表现总结,附:o1 门萨实测全记录+原题标答&解析~
1. 形状特征的捕捉
o1 pro 对基本的几何形状(圆、方、三角等)识别有着较高的准确率,结合对多种形状进行分类与描述,它能够尝试推断这些形状在网格中的相对分布和排列组合。
经典案例:如在 Question 1 的推理中,模型能够准确识别出 3x3 网格下,单元格中黑色“⬛️”移动的水平规律,其捕捉到了黑块位置的横向递进(可惜多次实验下,在选项匹配时总会出现偏差)。
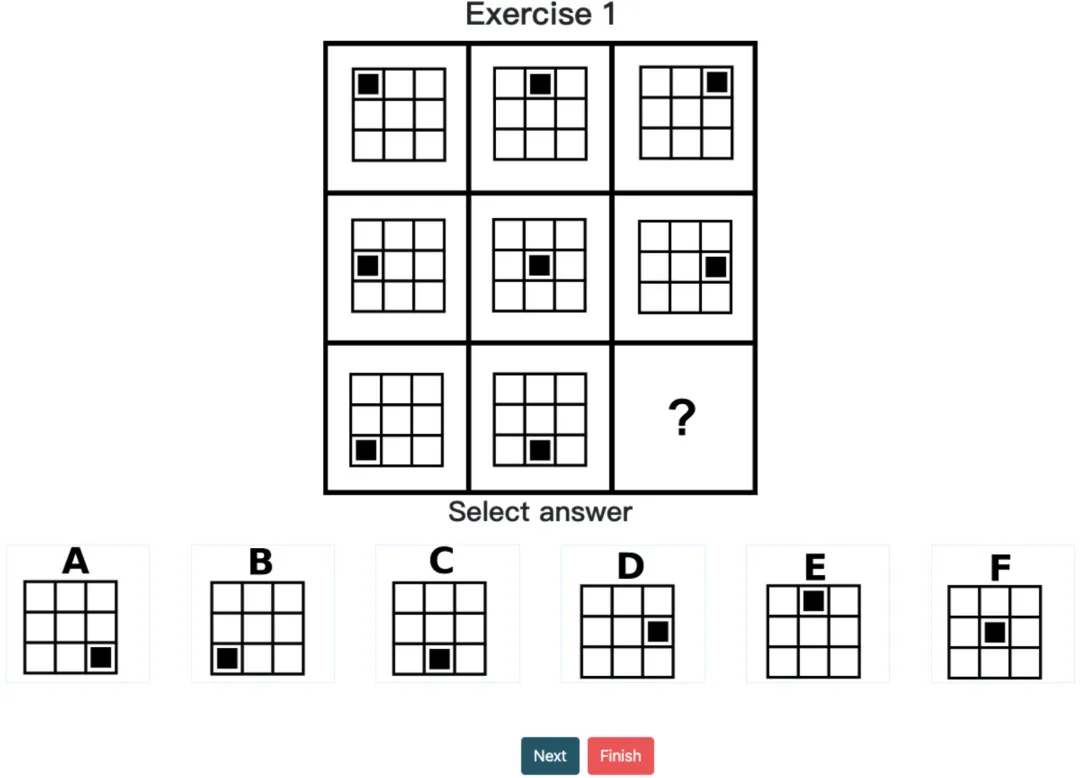
Question 1|思考 4m 9s


2. 数量统计的敏感性
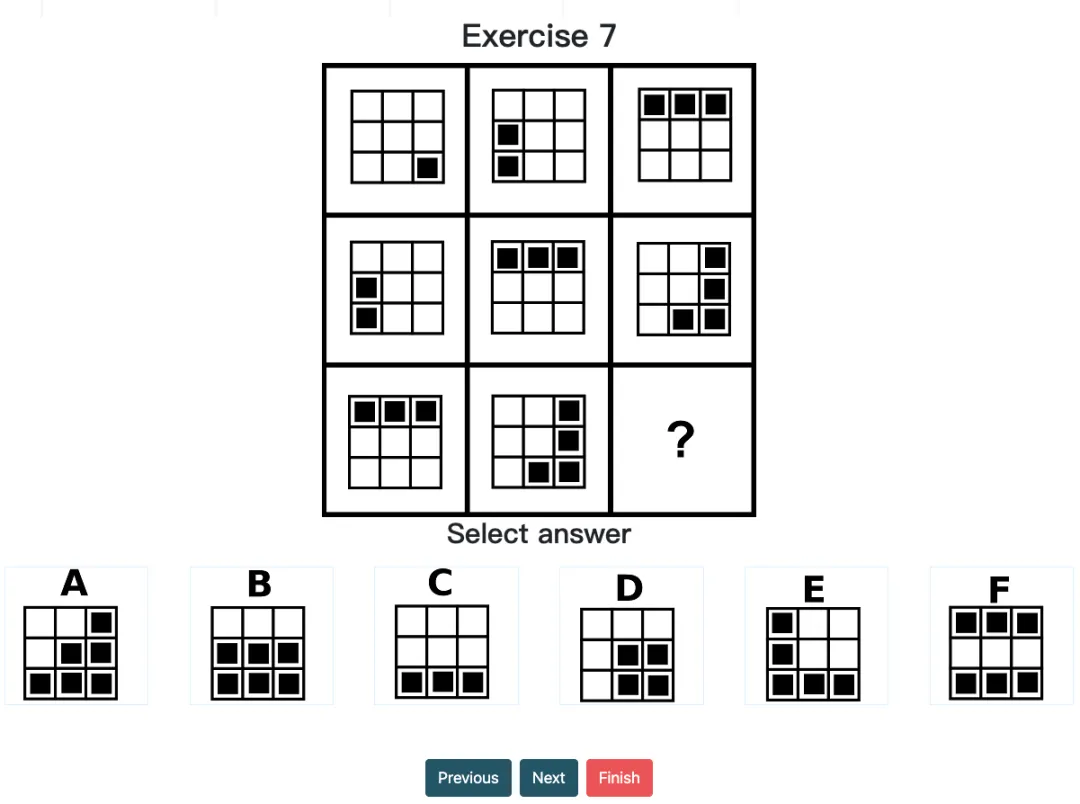
o1 pro 在数量识别(如黑色方块数、圆点数目、线段数量)方面也有着不错的敏感性。它习惯对数量进行归纳和类比,作为后续模式识别提供基础数据。当然这也是很多高手在做图形推理时常用的思维,因为大部分变化策略都不会改变题中关键元素的数量。
经典案例:在 Question 7 中,模型先识别出每个单元格中的黑色方块数量,再推理出递进关系以推断最终答案。虽然在描述中你会发现,它整体都把黑色方块“⬛️”识别多了一个,且忽视了黑块组合的旋转关系,但这些并没有影响推理且给出正确的答案。


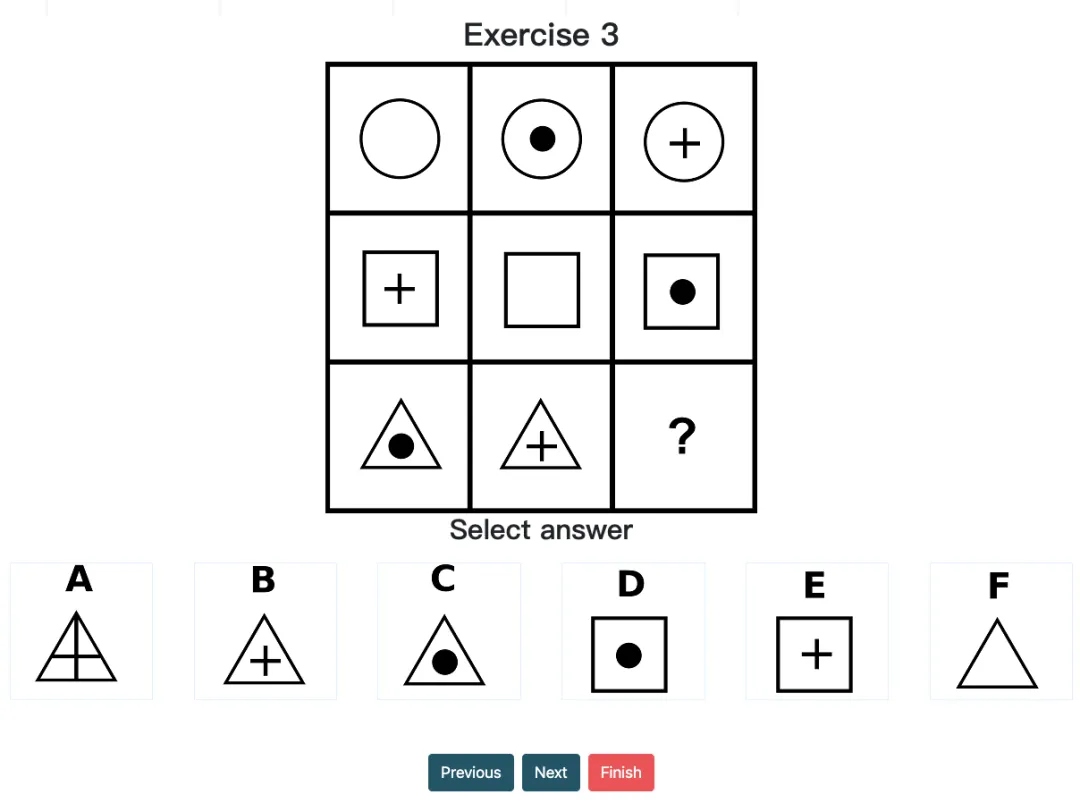
o1 pro 能较快地辨别出图形间的相对位置关系,如上下左右排列、局部结构的包含与被包含关系,以及沿行列方向的特征递进。在一定程度上,它已经具备了合理的“行列-模式”推断逻辑。
经典案例:如在 Question 3 中,模型对 3x3 网格中图形的行变化进行细致观察,得出了:第一行是“圆形+内部符号”,第二行是“方形+内部符号”,第三行是“三角形+内部符号”,再进而通过符号频率推断出三角形中应是“empty”,也就是 F 选项。

4. 变化规律的初步捕捉
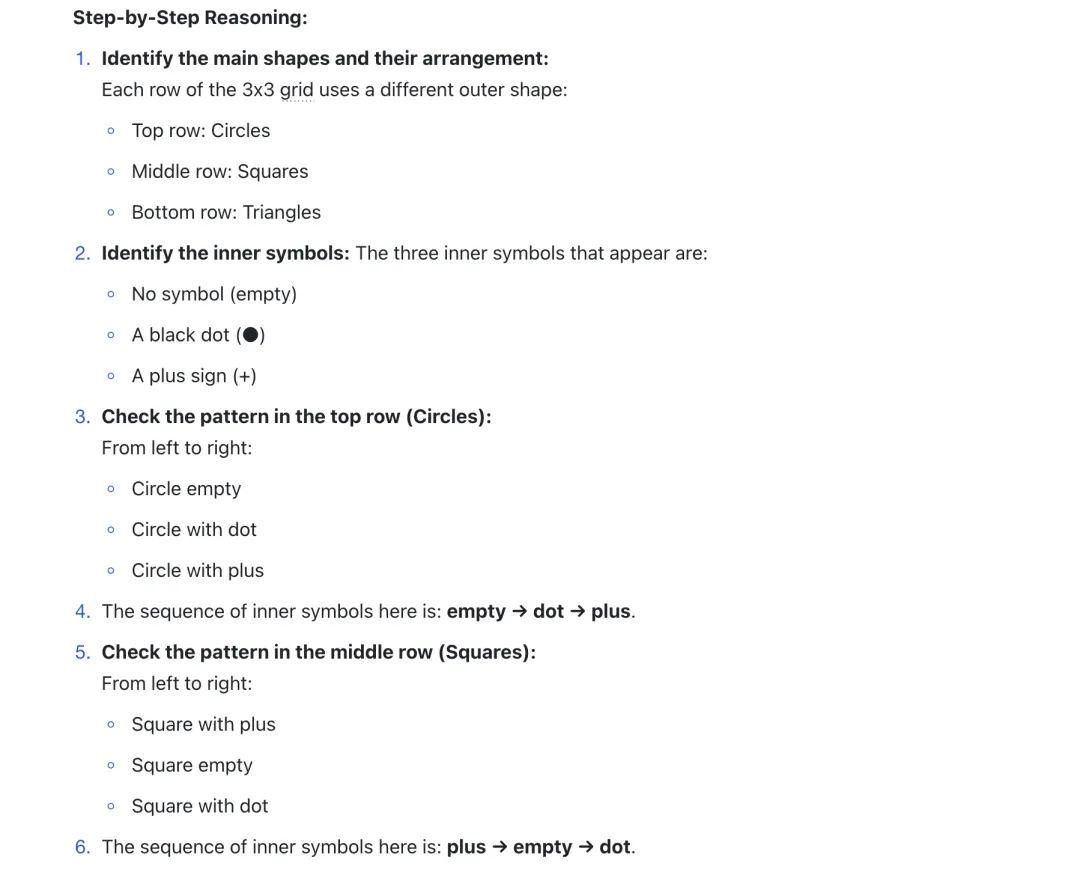
o1 能捕捉到一定的周期性变化或旋转对称等规律。例如,它会尝试对行列间的图形做的旋转猜测,以此找到缺失图案。
经典案例:在 Question 4 中,模型发现每一行的图案由一条线段和一个附加方块组成,且方块沿线段逐步移动,如第一行:水平线段 + 方块(左→中→右)。而在第三行,他能推理出竖直线段的方块也是依次从上→中→下移动的,模型基于这一规律,成功推断出了答案应是选项 F:竖直线段+方块位于底端。
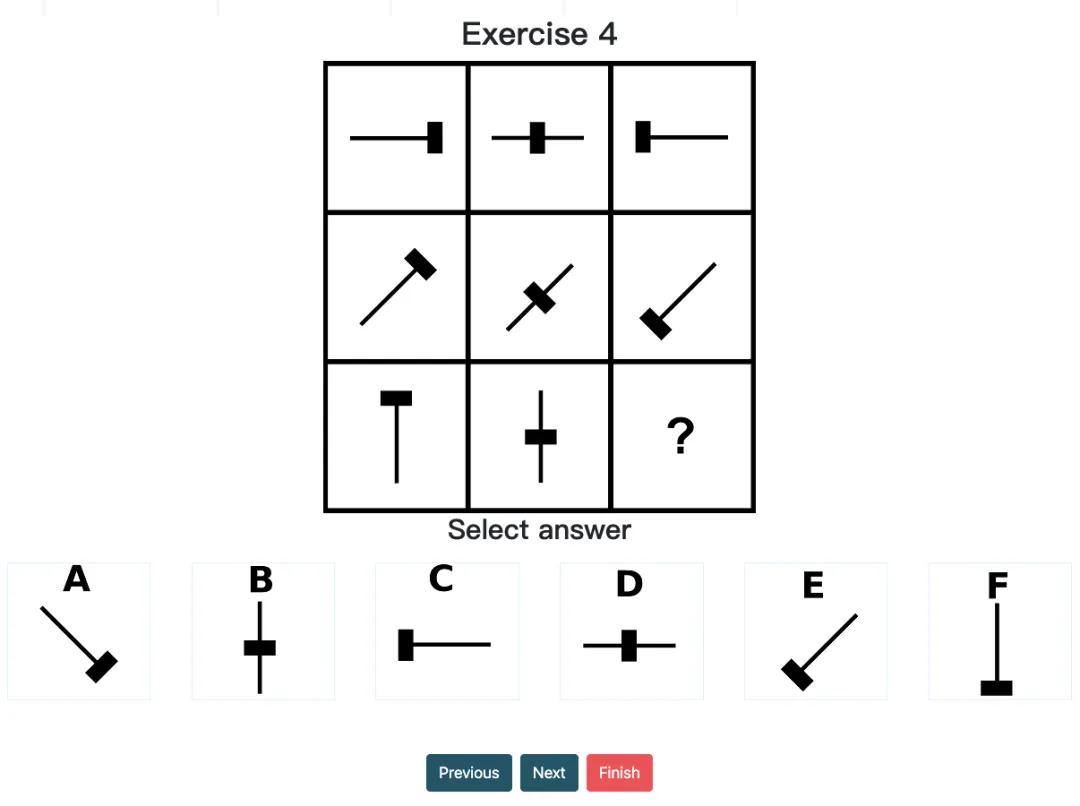


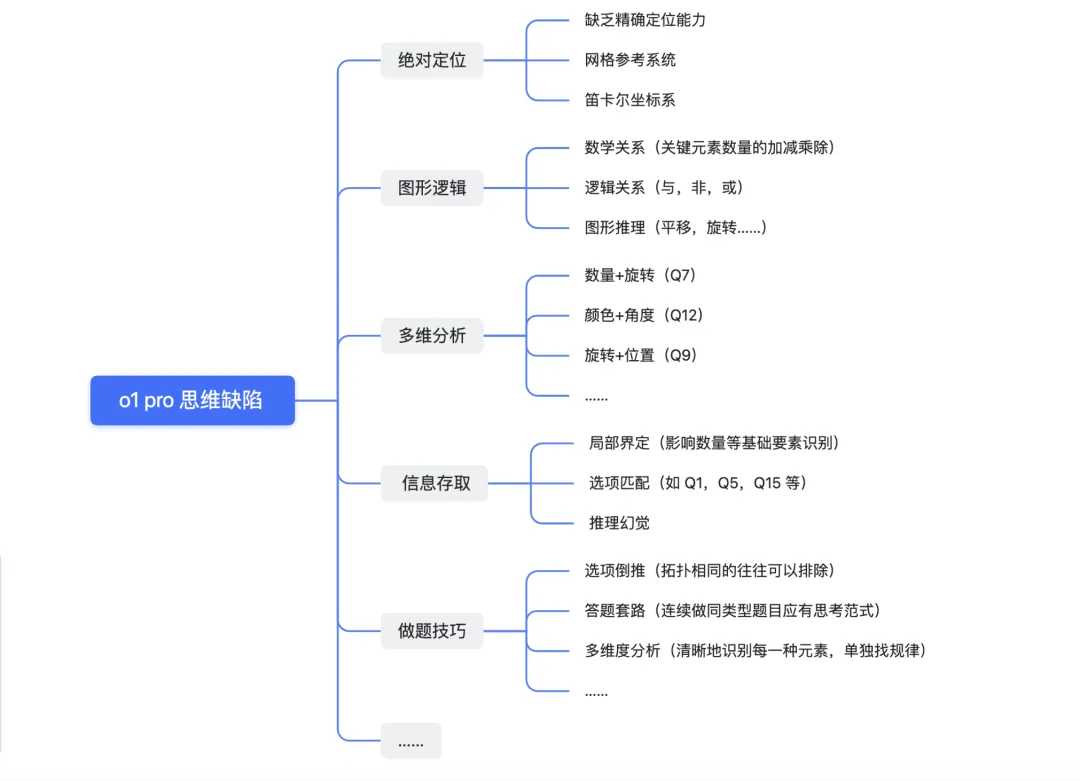
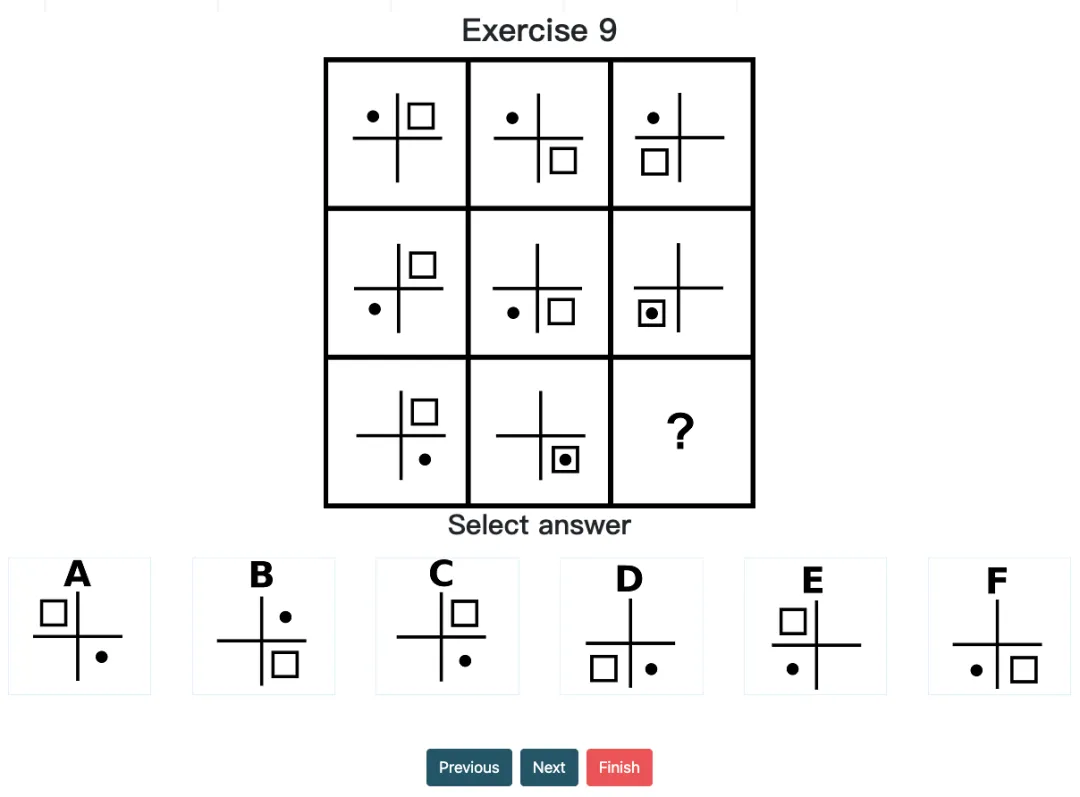
o1 pro 虽然能识别元素间的相对位置,但仍缺乏细粒度的视觉能力 / 严谨的坐标参考系统。例如,当题目需要严格基于坐标网格位置进行精准判断时,模型非常容易产生幻觉。
经典案例:在 Question 9 中,行间由上至下,黑球“●”和方块“□”分别围绕十字轴,在四个角按逆/顺时针规律旋转。而模型却只能用“上下左右”标记元素都位置信息,导致了最终的错误,可见其精确坐标定位仍有困难。



中阶的图形题往往需要挖掘图形间的数学(集合)逻辑,但这些人们能快速理解的抽象逻辑,o1 pro 仍然难以捕捉——模型仍然停留在直观的图案轮换和数量统计层面,却很难思考出对隐含在图形背后的集合论或函数映射规律。
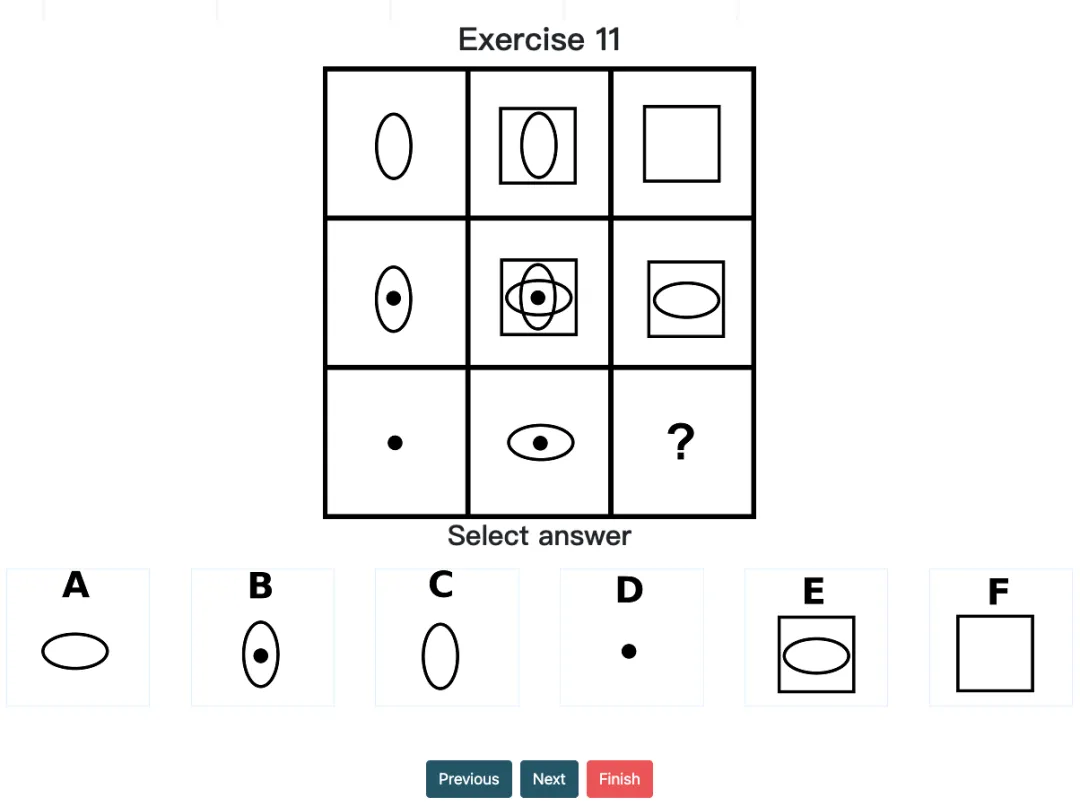
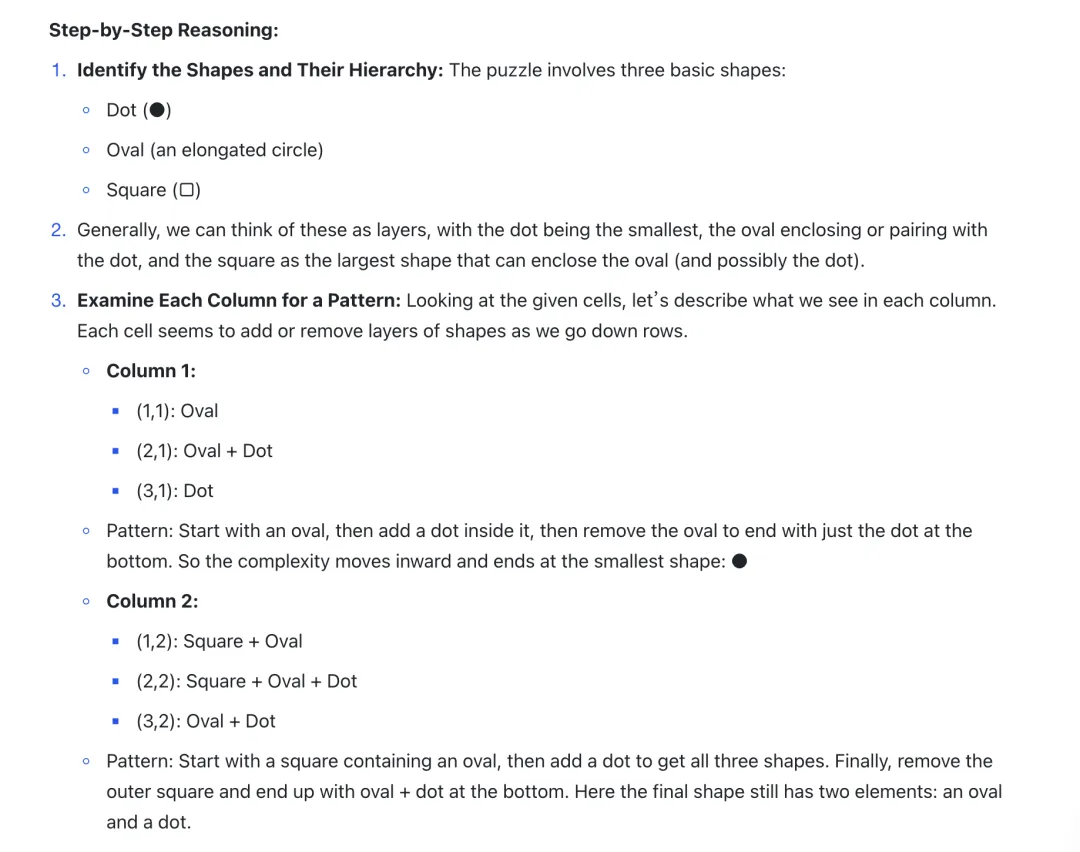
经典案例:在 Question 11 中,尽管 o1 pro 尝试以形状数量为依据进行推理,但此题的关键在于寻找不同列(列一&列二)之间的重叠部分,这导致了模型虽然选择了正确的形状,但形状的方向却是错误的——答案应是A(横着的椭圆)而不是 C(竖着的椭圆)。


而高阶的图形题,通常会叠加考察形状、颜色、方向、数量等多维度。但整体看下来,如今最强的 o1 pro mode 也只能侧重在某一维度(如数量或颜色)的分析,而忽视其他层面的信息。例如,当需要同时考虑颜色与方向、形状与数量、旋转与不变性时,模型基本无法应对。
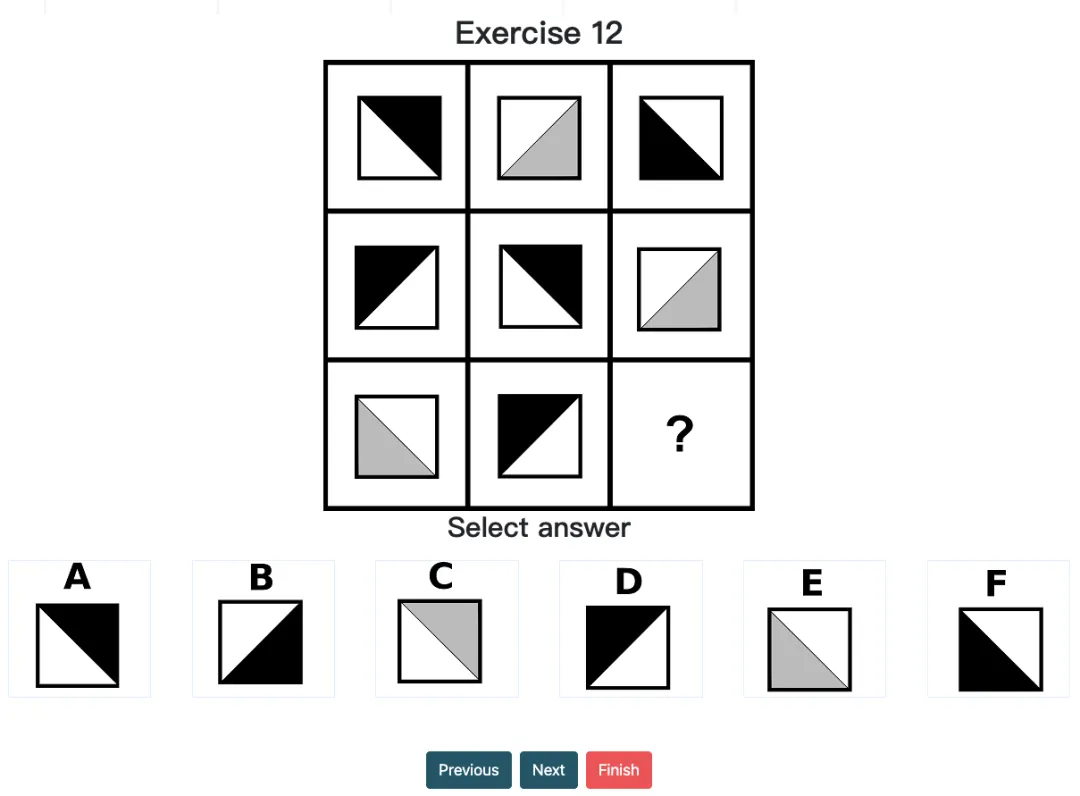
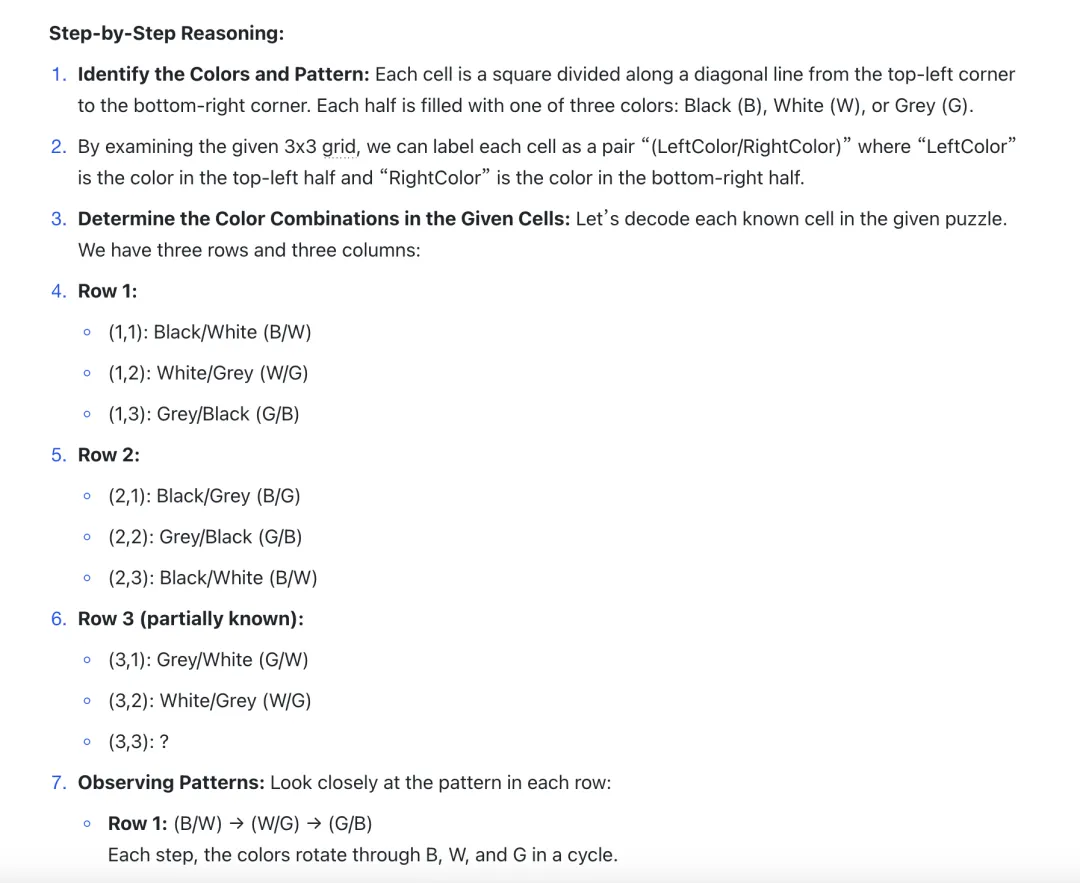
经典案例:在 Question 12 (对角线方向+颜色)等涉及多层信息叠加的题中,模型仅捕捉了颜色信息,却忽视了方块对角线的变化规律,属于是典型的思维盲区之一了。


大模型在处理图形测试题时,本质依然是分析提取成文本的信息去推断图形逻辑,而这缺乏直接视觉输入与空间直觉。而这种片段化的信息归纳,会疏漏关键信息的同时,导致模型在多轮推理中对关键线索失去注意力。
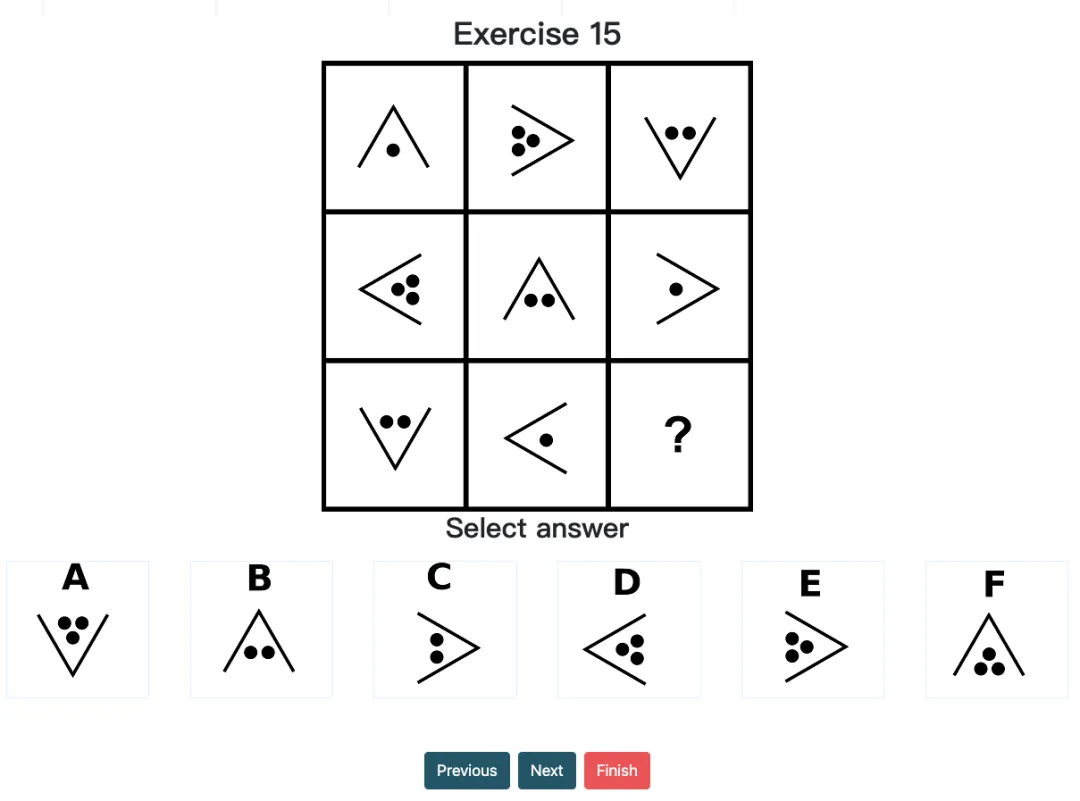
经典案例:在 Question 15 中,模型对方向与点数的周期变化有了很不错的完美推理(应为 ^ 且 3 个点),可却在最终选项对照时出错(应选 F 而选了 B)。可见其在信息提取过程中,仍存在微小但致命的偏差。这样的案例已在本次测试的多处发生。



Mensa IQ Chanllenge, Exercise 34
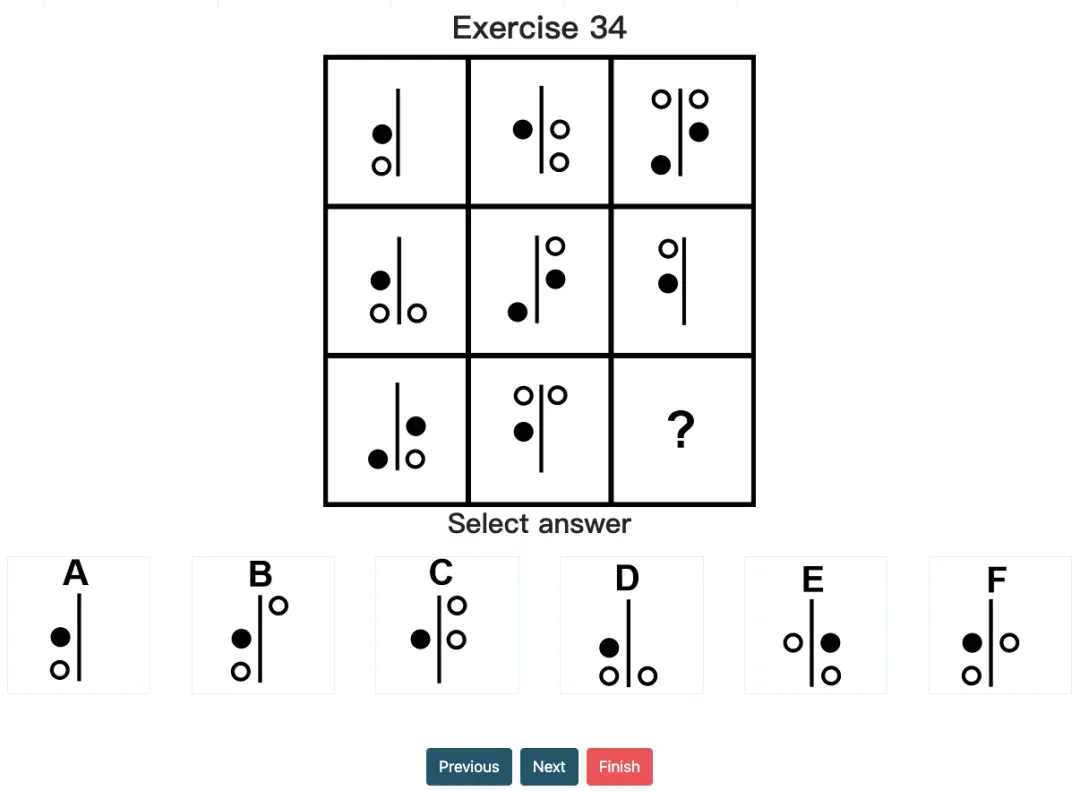
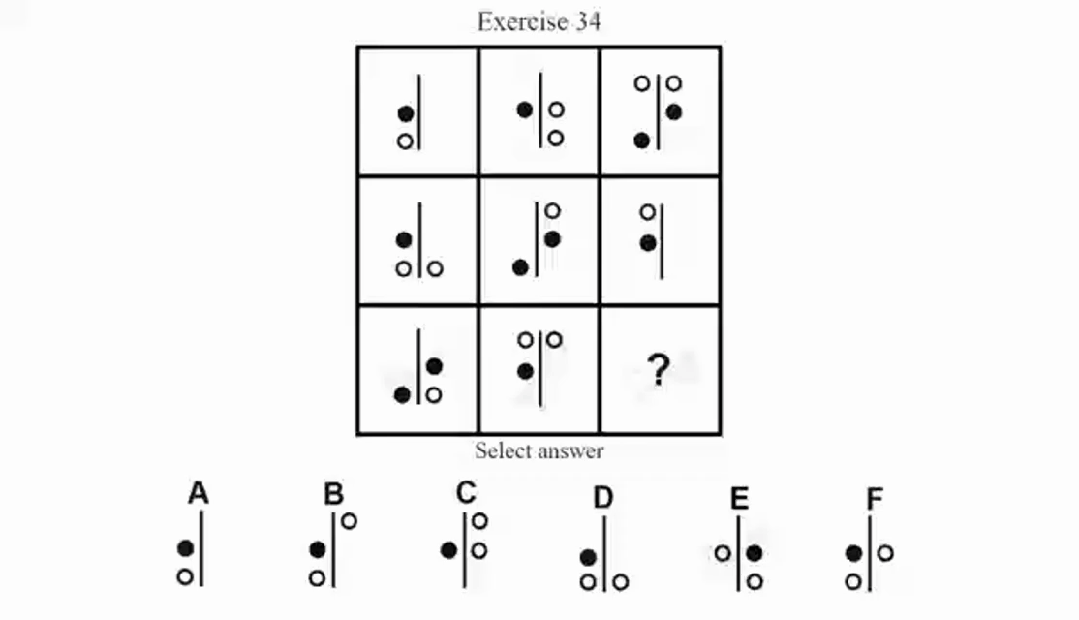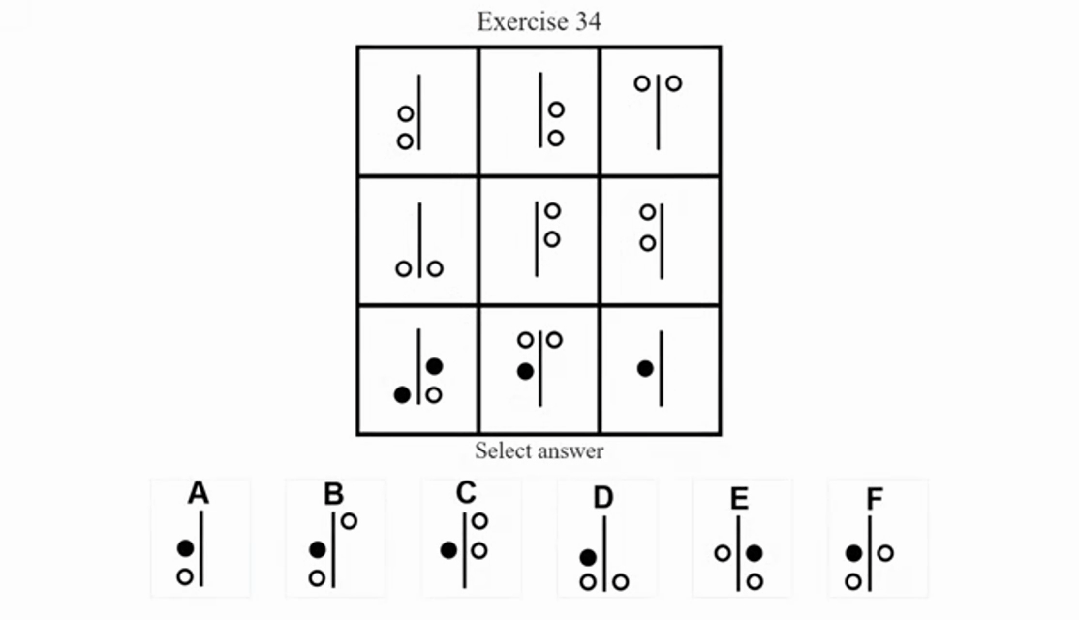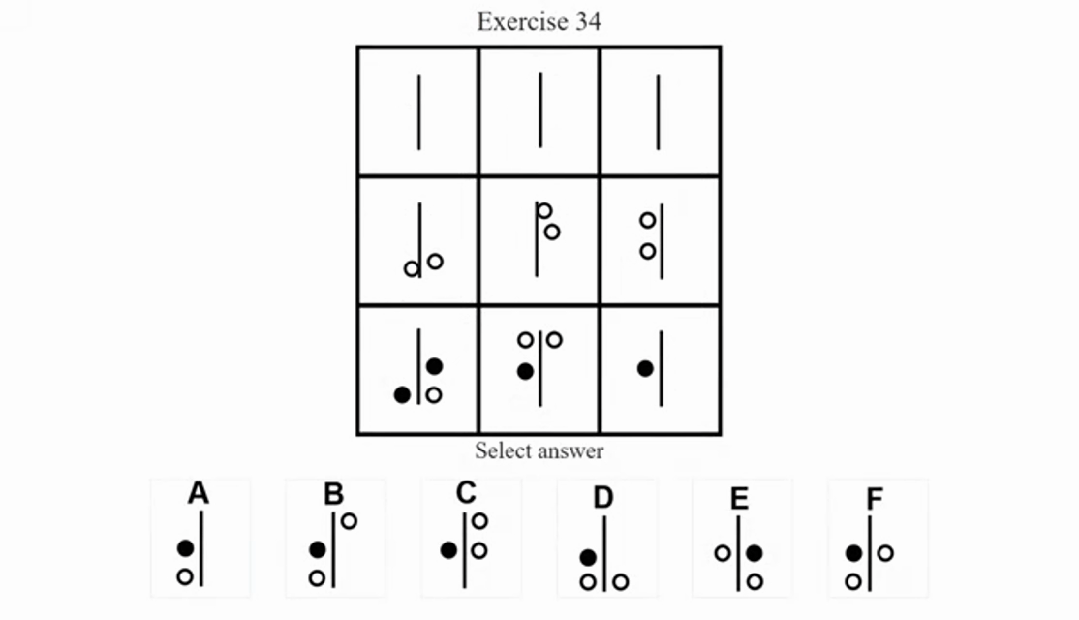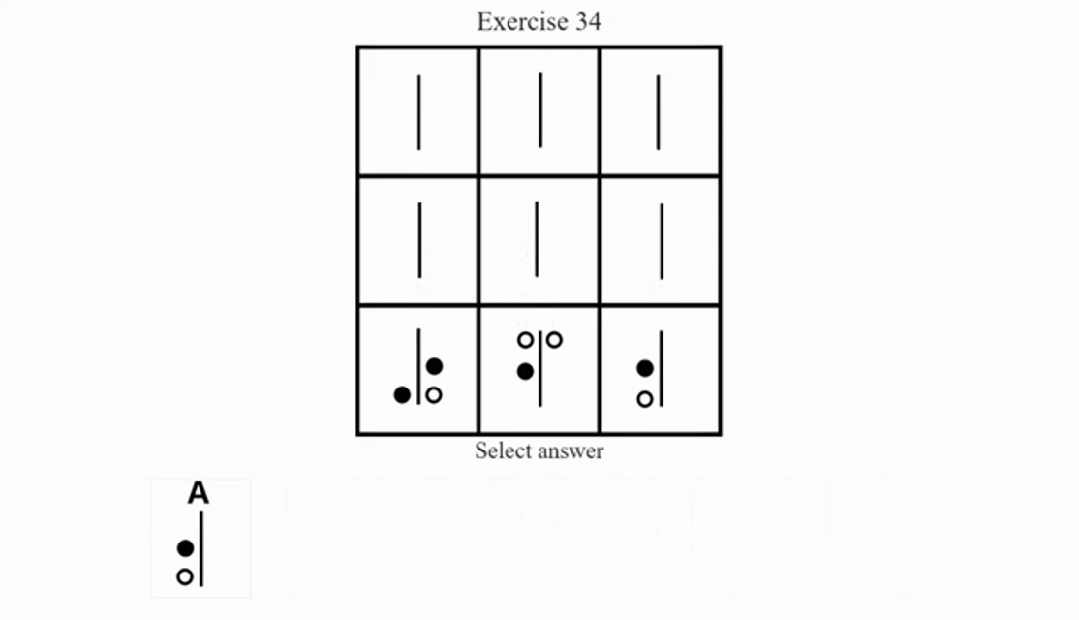
如果用网格参考系来观察,很多位置并没有元素,即“空白”——但其实“空白”本身也可能构成逻辑线索,甚至可以理解成一种单独的图层,与别的(元素)图层关联逻辑运算。而现在这般省事儿的“识别+提取”模式,也反之会疏漏掉很多关键线索。
因此,若未来能在模型内部训练/建立多图层分析框架:将节点、形状、颜色、角度、封闭空间、以及“空白”等信息要素,同时纳入逻辑推断范围,便有望大幅提升其在图形推理中的表现。
特工说:视觉的推理不能只依赖于目前“一维的”信息提取+“想当然的”文本推理,正如人类做图推用的是image token 而非 text token 一样,模型的视觉也应拥有自己独特的思考模式,或者也至少需要属于视觉的System 2 来尽可能减少上述的所有“盲区”。
过程记录已公开备份于飞书,链接
https://ri4tfva0tvq.feishu.cn/docx/OIWcddL87otD9wx1VjocYlhMnee?from=from_copylink
ps:(?)为推理正确但选错的;(✖)为整体识别或推理错误的。
尽管 ChatGPT o1 pro 模型在这种视觉推理的表现尚未达到人类平均水平,但正如 Day 1/12 of OpenAI 那天所演示的一样,多模态的推理能力很好地给我们带来了更多的想象空间。
通过本次门萨智商测试,我们不仅揭示了模型在抽象视觉逻辑与多维信息交叉中的短板,亦是给将来技术的优化与创新提供了不错的启示,比如在训练过程中引入更严格的图形语义标注与高层模式提炼……
可以预见,随着算法的持续改进和多模态学习机制的深度融合,AI 会逐步掌握更接近人类的认知逻辑,或将开启属于视觉推理的 AlphaGo 时刻。
展望未来,人工智能的发展蓝图充满了变革性的可能性。我们期待在不远的将来,AI 不仅能在复杂视觉信息的理解与逻辑推理中取得革命性突破,还将在医疗、教育、科学探索等现实问题中发挥更大的价值。
未来的 AI 系统将从“工具”转变为人类智慧的“伙伴”,通过全感知、多模态的能力扩展,与人类共同应对前所未有的挑战,推动人类文明进入智能共生的新纪元。
文章来自于“特工宇宙”,作者“特工阿尔法”。




【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
